Cursor Tab 是 Cursor 的核心功能之一,它通过分析开发者的编码行为,智能预测并推荐后续代码,开发者仅需按下 Tab 键即可采纳。

然而,它也面临着一个 AI 普遍存在的难题:「过度热情」。有时,它提出的建议不仅毫无用处,甚至会打断开发者的思路。
问题的关键,不只是让 AI 写出更优秀的代码,更是要教会它「察言观色」:在最恰当的时机提供帮助,在其他时候则保持安静。
基于此,Cursor 采用在线强化学习技术训练出一个全新的 Tab 模型。 该模型将每一次用户交互(接受/拒绝建议)都视为一个强化信号,直接用于模型的在线优化。 在每天超过 4 亿次请求的巨大流量驱动下,模型得以进行高频度的、基于真实世界反馈的持续学习。

Cursor 已将这个新的 Tab 模型设为默认版本。与旧模型相比, 新模型提供的建议数量减少了 21%,但所提供建议的接受率却提升了 28%。 此举旨在提升用户的编码体验,Cursor 也计划在未来继续深化这些方法的研究。
Cursor 的策略独特且高效:它每天多次向用户部署新模型(每隔 1.5-2 小时),利用实时数据进行快速训练和优化。
这与主流做法形成了鲜明对比。多数厂商仍在静态数据集上进行长周期训练,依赖人工标注,数月才发布一次新模型。Cursor 的模式则建立了一个超高频的实时反馈循环,是对传统模型开发流程的彻底颠覆。
这似乎又一次向我们证明了, 谁掌握了数据入口,谁就掌握了 AI 进化的主动权。
该功能在 AI 社区也得到了非常积极的反馈,有用户表示这是 Cursor 当前「护城河」,并愿意为 Cursor Tab 单独付费。

还有开发者认为,它能大幅提升了生产力,不像 agent 那样只有噱头,而是「比其他任何功能都更能改善工作流程」。

另外,一条被「强化学习之父」Richard Sutton 转发的评论表示,Cursor 的这个做法意义重大,它首次大规模证明了「实时在线学习」的巨大威力,并且指明了 AI 未来的一个重要发展方向,尽管目前还不够完美。

Cursor 通过一篇博客介绍了他们如何利用这些数据,通过在线强化学习技术来优化其 Tab 模型。
博客地址: https://cursor.com/cn/blog/tab-rl
「干扰性建议」的挑战
要实现高接受率,不仅需要提升模型本身的智能水平,更关键的是要判断何时应提供建议,何时应保持静默。在某些场景下,上下文信息不足以准确判断用户的意图。即便模型具备完美的知识和推理能力,也无法预知用户的确切操作。在这些情况下,不提供任何建议是更优的选择。
为提升建议的接受率,一种直接的思路是训练一个独立的分类模型来预测建议是否会被采纳。据 Parth Thakkar 在 2022 年披露,GitHub Copilot 便采用了此种策略。它通过一个逻辑回归模型计算「上下文过滤分数」,该模型接收 11 个特征作为输入,涵盖了编程语言、前次建议的采纳情况、光标前的字符序列等。尽管该模型的确切预测目标未知,但外界普遍猜测其旨在预测建议被用户接受的概率。当该分数低于 15% 时,系统便会跳过此次建议。
该方案虽然可行,但 Cursor 的团队希望寻求一种更通用的机制,以便能复用 Tab 模型自身学到的强大代码表征能力。他们希望从根源上让 Tab 模型避免生成质量不高的建议,而非仅仅在事后进行过滤。因此,他们最终选择了策略梯度方法。
策略梯度方法
策略梯度是一种通用的优化框架,其目标是调整「策略」(在此即 Tab 模型),以最大化「奖励」(Reward)。奖励是一个被赋予策略所执行的每一个动作的数值。通过策略梯度算法,可以持续更新策略,使其在未来能够获得更高的平均奖励。
该类算法的核心思想是:允许策略进行探索性的随机尝试,观察不同行为所带来的奖励高低,然后对获得高奖励的行为进行正向强化,对导致低奖励的行为进行负向强化。
为了运用策略梯度方法优化 Tab,团队定义了一个精巧的奖励函数:鼓励被采纳的建议,同时惩罚那些被展示但未被采纳的建议。
例如,假设目标是当建议的接受率不低于 25% 时才进行展示。那么,可以为被采纳的建议设定 0.75 的奖励,为被拒绝的建议设定 -0.25 的奖励,而未展示建议的情况奖励为 0。如果一个建议的真实接受概率为
p
,那么展示该建议的期望奖励就是
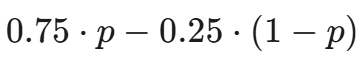
在实际应用中,Cursor 使用的奖励函数更为复杂,还考虑了建议的长度、代码跳转以及展示更多建议的可能性等因素。但其核心理念是一致的:并非直接对接受率进行建模,而是学习一个能够达成特定接受率目标的策略。
可以推断,模型在其内部表征中自发学习到了对接受概率的评估(或至少是评估其是否超过 25%),而这个过程完全交由优化器自行探索。
同策略(On-Policy)数据的重要性
为了计算策略的更新方向,该方法依赖于一个名为「策略梯度定理」的重要理论。该定理指出,如果一个由参数
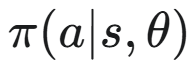
定义的策略
描述了在状态

的概率分布,并且总奖励为
下采取动作
,那么奖励函数关于参数
的梯度可以表示为:

这个定理的实用价值在于其右侧的期望值是可以通过采样来估计的。具体来说,可以通过记录用户实际看到的建议来获得状态-动作样本
;利用 PyTorch 等深度学习框架计算对数策略的梯度
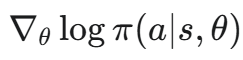
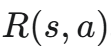
然而,该方法有一个关键前提:用于计算梯度的动作样本,必须来自于当前正在优化的策略。一旦策略被更新,旧的数据便不再是「同策略(On-Policy)」数据。
为了获取最新的有效样本,就必须将新模型部署给用户并收集其行为数据。这意味着需要一套高效的基础设施,以快速部署新的模型检查点,并缩短从用户产生数据到数据进入下一轮训练流程的时间。
目前,Cursor 推出一个检查点并收集所需数据需要 1.5 到 2 小时。尽管这在人工智能行业已属高效,但仍有进一步优化的空间。
Cursor 这次更新让你心动了吗?
]article_adlist–>
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

