
<p><span style="background-color:#ffffff; color:#4d4d4d">作者:来自 Elastic </span>Mridula Sivanandan</p> 通过实际示例探索 Elasticsearch 中的加权倒数排名融合 (RRF) 及其工作原理。
Elasticsearch 包含许多新功能,可帮助您为您的用例构建最佳搜索解决方案。在我们关于构建现代搜索 AI 体验的实践网络研讨会中,了解如何将其付诸实践。您还可以开始免费的云试用或立即在本地计算机上试用 Elastic。
想象一下:您正在构建一家餐厅搜索,需要平衡位置相关性与美食匹配。一些查询更关心“我附近的披萨”,而另一些查询则优先考虑“供应 cacio e pepe 的意大利餐厅”或“备受好评的意大利餐厅”。到目前为止,Elasticsearch 的倒数秩融合 (RRF) 将所有检索者视为平等,但您的搜索策略不应该。
这就是加权 RRF 的用武之地。您现在可以微调它们的影响力,从而创造更细致、更有效的搜索体验,而不是在搜索结果中为每个猎犬提供相同的声音。在本博客中,我们将探讨加权 RRF 的需求,并演示如何将其用于不同的搜索场景。
挑战:一刀切并不适用
RRF 非常适合将不同的检索策略(如关键字、语义和向量搜索)组合到单个排名结果集中。但是,当某些检索方法对特定查询类型更有价值时,平等对待所有检索器可能会限制您的搜索质量。
考虑一个餐厅搜索,其中不同的查询类型需要不同的排名策略:
- 以位置为中心的查询,比如 “pizza near me”,需要以城市、社区或距离等基于位置的信号在排序中占主导。
- 以菜品为中心的查询,比如 “Italian restaurants that serve cacio e pepe”,应当优先考虑菜单项匹配和菜系类型,而不是距离远近。
- 以质量为中心的查询,比如 “highly reviewed Italian restaurants”,应当把评分和评论置于所有其他因素之上。
在加权 RRF 之前,平衡信号的标准方法是分数的线性组合(分配固定权重并将它们相加)。虽然功能强大,但这种方法通常需要解决方法,例如多次搜索通道、自定义评分功能或手动后处理,所有这些都很难有效维护和调整。
加权 RRF 通过提供一个统一的框架来消除这些痛点,其中每个检索器都可以拥有自己的权重,并且 RRF 算法自动处理排名融合。
解决方案:通过加权实现精确
加权 RRF 提供了一种简单但强大的方法来为您的猎犬分配不同的重要性级别。每个检索器现在都接受一个权重参数,该参数会影响其对最终 RRF 分数的贡献。
这对您的搜索意味着什么
加权 RRF 使您可以灵活地创建更智能、更量身定制的搜索体验。
- 更智能的相关性调整:不再有一刀切的排名。为您的语义搜索检索器提供更高的概念查询权重(“查找具有舒适氛围的餐厅”),同时提高特定术语(“玛格丽特披萨”)的关键字匹配。
它在实践中是如何工作的
假设您正在构建餐厅搜索。以下是加权 RRF 如何针对不同的搜索方案转换查询策略:
场景 1:“Pizza near me” —— 以位置为中心的搜索
个用户在手机上搜索 “pizza near me”。在这种情况下,距离最重要。加权 RRF 让我们能够给予基于位置的信号(城市、社区、邮政编码)更多的影响力,而不是关键词 “pizza” 的匹配。
以下是该查询在 JSON 中的样子:
{
"retriever": {
"rrf": {
"retrievers": [
{
"retriever": {
"standard": {
"query": {
"multi_match": {
"query": "Vienna",
"fields": ["city", "neighborhood", "postal_code"]
}
}
}
},
"weight": 0.8
},
{
"retriever": {
"standard": {
"query": {
"match": {
"menu_items": "pizza"
}
}
}
},
"weight": 0.2
}
]
}
}
}
即使菜单文本匹配较弱,这种权重也有利于附近的餐厅。
场景 2:“Italian restaurants that serve cacio e pepe” —— 以菜系和菜品为中心的搜索
在这里,用户正在寻找特定的美食和菜肴。加权 RRF 强调美食和菜单匹配,同时仍然允许邻近发挥次要作用。
以下是该查询在 JSON 中的样子:
{
"retriever": {
"rrf": {
"retrievers": [
{
"retriever": {
"standard": {
"query": {
"match": {
"cuisine_type": "Italian"
}
}
}
},
"weight": 0.4
},
{
"retriever": {
"standard": {
"query": {
"match": {
"menu_items": "cacio e pepe"
}
}
}
},
"weight": 0.6
}
]
}
}
}
这种权重促进了明确提及菜肴和美食的餐厅,即使它们距离稍远。
场景 3:“Highly reviewed Italian restaurants” —— 以质量和菜系为中心的搜索
当质量是重中之重时,评级的权重最大。加权 RRF 允许评级阈值来指导排名,同时将美食类型作为支持因素。
以下是该查询在 JSON 中的样子:
{
"retriever": {
"rrf": {
"retrievers": [
{
"retriever": {
"standard": {
"query": {
"range": {
"rating": {"gte": 4.5}
}
}
}
},
"weight": 0.7
},
{
"retriever": {
"standard": {
"query": {
"match": {
"cuisine_type": "Italian"
}
}
}
},
"weight": 0.3
}
]
}
}
}这种加权方式会提升高评分的 Italian 餐厅,在保持菜系相关性的同时,让评分起主导作用。
加权 RRF 通过每个检索器的权重将这些偏好直接编码为排名,因此最终顺序反映了每个查询的重要内容。
底层原理
在计算最终分数时,标准的 RRF 公式被加上了权重:
示例:rank_constant = 60。每个检索器的贡献为:weight × 1 / (rank + rank_constant)。权重越高,影响力越大;排序从 1 开始。
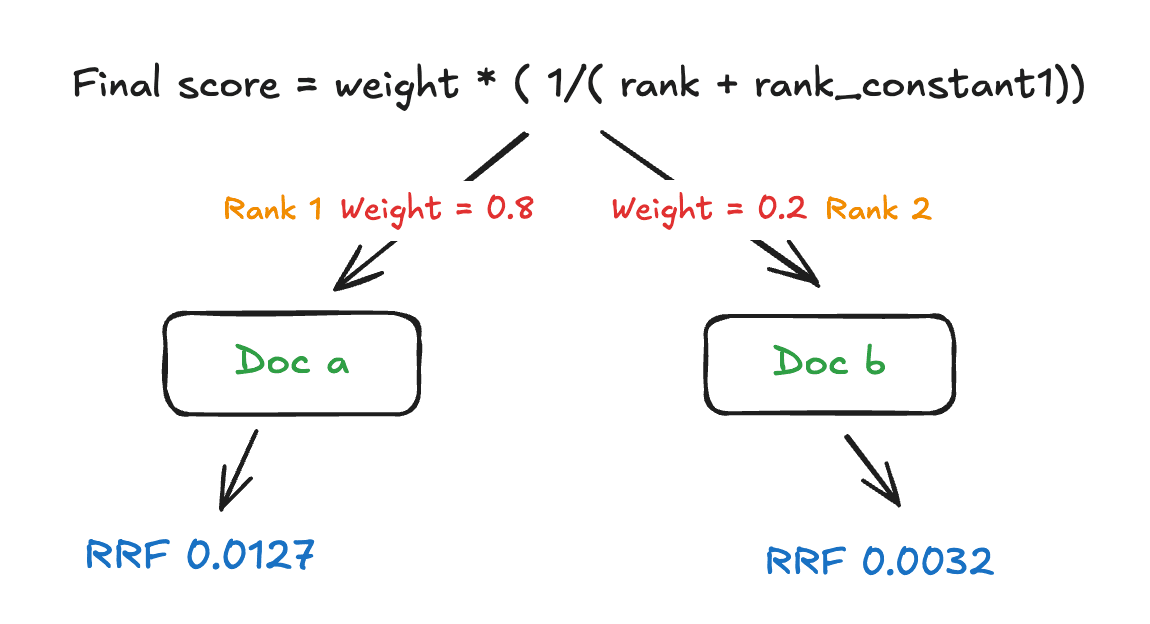
主要技术特点包括:
- 选择权重:在需要更精细控制时选择每个猎犬的权重,或者在只有某些猎犬需要权重时选择默认权重。
- 输入验证:权重必须为非负数。
有关高级自定义和混合评分(包括规范化),请参阅线性检索器 https://www.elastic.co/docs/reference/elasticsearch/rest-apis/retrievers/linear-retriever
下一步是什么?
加权 RRF 将 RRF 扩展到需要比标准 RRF 提供的更多控制的生产用例。需要对搜索相关性进行细粒度控制的团队现在可以使用 RRF 而不是构建自定义解决方案。无论您是在平衡餐厅的位置与美食、电子商务的品牌与类别,还是任何其他复杂的排名场景,加权 RRF 都能为您提供所需的精度。
我们迫不及待地想看看您将如何使用加权 RRF 来创建更智能、响应更灵敏的搜索体验。快乐搜索!
准备好深入了解了吗?在我们的官方文档中探索 Reciprocal Rank Fusion 和 Retriever API。
原文: https://www.elastic.co/search-labs/blog/weighted-reciprocal-rank-fusion-rrf
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


