
<blockquote> 为解决虚拟人长视频生成的质量退化问题,基础研发平台/计算和智能平台部/视觉智能团队推出 InfiniteTalk 技术,实现无限时长视频生成。该技术口型精准且动作流畅,支持”语音驱动图像”和”语音驱动视频”多种模式,已在 GitHub 开源并获 1.6K Stars, Hugging Face 月下载量 64.8K,受到了很多好评,能够应用到电商直播、教育、影视等领域。

项目开源信息
- 项目主页 :https://meigen-ai.github.io/InfiniteTalk/
- 开源代码 :https://github.com/MeiGen-AI/InfiniteTalk
- 技术报告 :https://arxiv.org/abs/2508.14033
应用场景
- 营销: 电商营销视频、商家数字人直播、虚拟人导购
- 培训:虚拟人讲师、虚拟人陪练、在线教育
- 娱乐:短视频创作、虚拟偶像、游戏
01 引言——video dubbing 的一个长期痛点
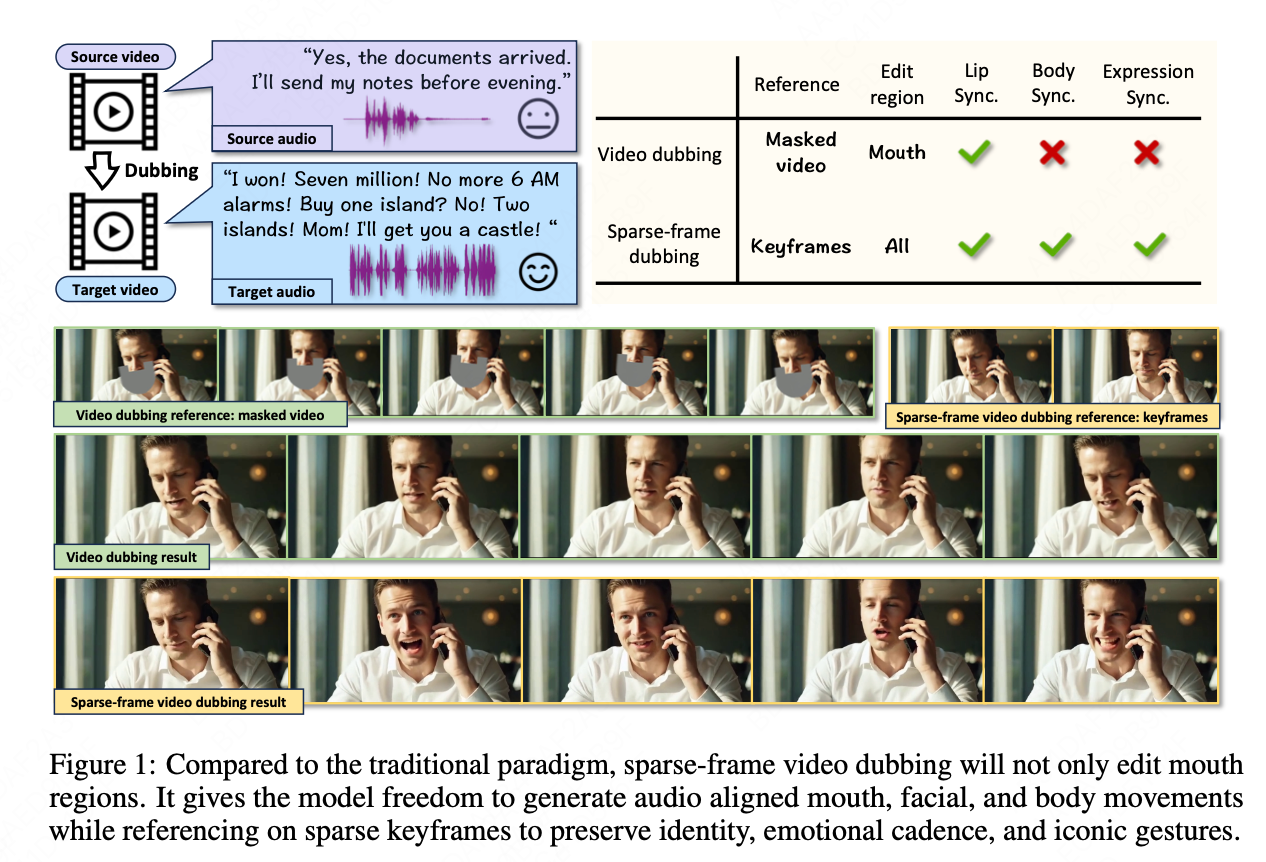
传统 video dubbing 技术长期受限于其固有的”口型僵局”,即仅能编辑嘴部区域,导致配音所传递的情感与人物的面部、肢体表达严重脱节,削弱了观众的沉浸感。现有新兴的音频驱动视频生成模型,在应对长视频序列时也暴露出身份漂移和片段过渡生硬等问题。为解决这些痛点,我们引入并提出了一种全新的技术范式——“稀疏帧 video dubbing”(sparse-frame video dubbing)。
这一新范式从根本上重新定义了 video dubbing,将其从简单的”嘴部区域修复”转变为”以稀疏关键帧为引导的全身视频生成”。基于此,我们推出了核心技术模型 InfiniteTalk。该模型不仅能够实现口型与配音的精准同步,更实现了面部表情、头部转动和肢体语言与音频所表达情感的自然对齐。InfiniteTalk 采用流式生成架构和独特的软条件控制策略,能够消除长视频生成中的累积误差和突兀过渡,为流媒体内容本地化和全球传播带来了巨大的提升。
1.1 传统 video dubbing 技术的”口型僵局”
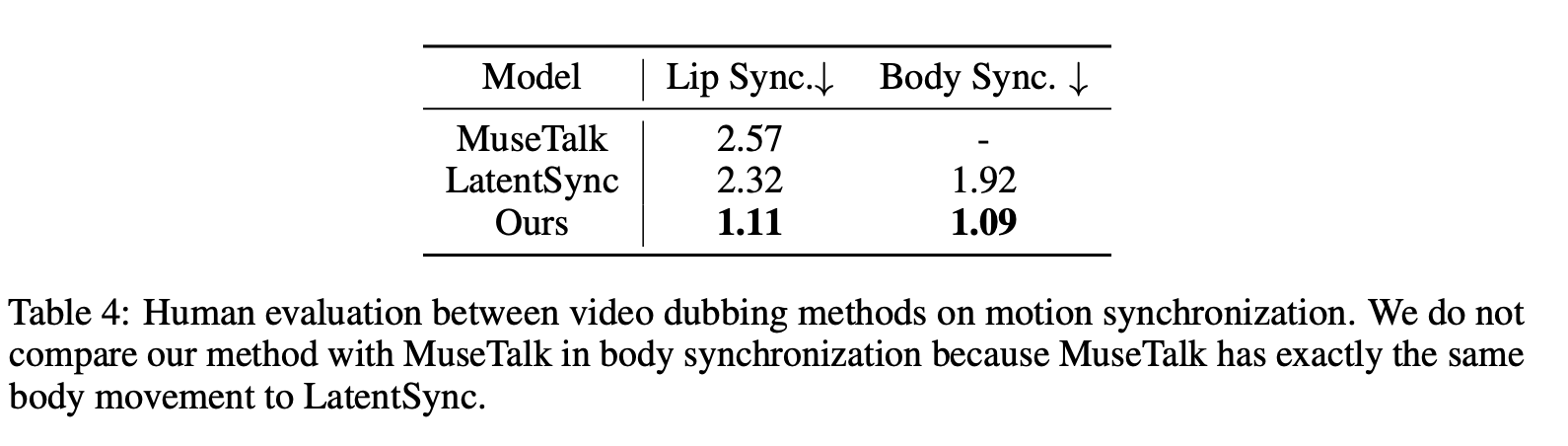
video dubbing 是内容全球化传播的关键环节,它通过将源视频的音频替换为新语言的配音,使内容能够触达更广阔的受众。然而,长期以来,这项技术一直面临一个核心的”僵局”——其编辑范围的局限性。传统的 video dubbing 技术,例如 MuseTalk 和 LatentSync,通常专注于对嘴部区域进行”修复式”编辑,以实现口型与新音频的同步。这种方法的主要局限在于,它几乎不触及人物的面部表情、头部转动和肢体动作。
这种”局部编辑”的策略导致了一个严重的矛盾:当配音表达出强烈的情感(例如激动、愤怒或喜悦)时,视频中人物的身体姿态却保持着僵硬或静止状态。例如,一段充满激情的对话,人物却只是面部肌肉轻微抽动,身体保持纹丝不动。这种视听信息的不一致性会严重破坏观众的沉浸感,使生成的视频显得不自然,缺乏说服力。这种矛盾感的存在,从根本上制约了配音视频的质量,并成为内容创作者亟待解决的难题。如下图 1 所示:
1.2 现有 AI 生成方案的缺陷:累积误差与过渡生硬
随着人工智能技术的发展,一些音频驱动的视频生成模型应运而生,试图解决这一问题。然而,直接将这些模型应用于长 video dubbing 任务,同样暴露出新的、且同样关键的挑战。
首先是基于图像转视频(Image-to-Video, I2V)的方法。这类模型通常以视频的首帧图像作为初始参考,然后根据音频生成后续的视频序列。虽然这种方法在理论上提供了更大的动作自由度,但它存在严重的”累积误差”问题,如图 2(左)。由于模型缺乏持续的原始关键帧作为锚定,在生成较长的视频序列时,人物的身份特征(如面部细节、发型等)会逐渐偏离源视频,甚至背景的色调也可能发生不可控的偏移,导致视频质量随时间推移而下降。
其次是基于首末帧转视频(First-Last-frame-to-Video, FL2V)的方法。该方法试图通过同时使用视频片段的起始帧和终止帧作为参考来解决累积误差。然而,这种策略带来了另一个问题:过渡生硬, 如图 2(右)。FL2V 模型生成过程缺乏从前一片段向后一片段传递的”动量信息”,不同视频片段之间的动作衔接会显得突兀和不自然,打破了视频流的连续性。与此同时,其过于严格地遵循固定的参考帧,强制生成的视频在片段(chunk)的边界上精确复制参考帧的姿态,即使这种姿态与新音频的情感或节奏相悖。
这两种主流 AI 方案的局限性揭示了一个核心矛盾:即”局部编辑的僵硬”与”全局生成的失控”。传统方法因编辑范围狭窄而僵硬,而新兴的 AI 生成模型则在长视频的连贯性上遭遇了挑战。这证明了长 video dubbing 任务需要一个全新的、能同时兼顾全局连贯性与局部动态表达的解决方案。

02 创新性范式:稀疏帧 video dubbing
2.1 核心理念:从”修复”到”生成”的范式转变
为了从根本上解决上述挑战,我们引入了一个全新的技术范式——“稀疏帧 video dubbing”。这一范式彻底改变了 video dubbing 的技术哲学:它不再将任务定义为对嘴部区域的”修复”(inpainting),而是将其重构为一场”以稀疏关键帧为引导的全身视频生成”。
其核心理念在于,不是逐帧地、僵硬地复制源视频,而是策略性地仅保留和利用源视频中的少数关键帧(sparse keyframes)作为核心参考。这些关键帧如同”视觉锚点”,在生成过程中发挥着至关重要的作用。
2.2 双重目标:身份锚定与全身自由表达
“稀疏帧 video dubbing”范式的技术哲学旨在同时实现两个看似矛盾但又相互补充的目标:
- 身份与风格锚定: 选定的少数关键帧用于锁定视频中人物的身份特征、面部情绪基调、标志性手势以及摄像机镜头的运动轨迹。这确保了无论生成的视频有多长,人物的身份和视频的整体风格都能保持高度一致性和真实感,从而从根本上解决了 I2V 模型中的”累积误差”问题。
- 全身自由表达: 这一范式的创新之处在于,在锚定关键信息的同时,它赋予了模型充分的”自由”去生成与新音频有机同步的全身动作。这意味着,模型不再被局限于嘴部区域,而是能够根据音频所表达的节奏、情绪和韵律,动态地生成相应的面部表情、自然的头部转动和流畅的肢体姿势。例如,当配音音频中的情感从平静转为激动时,模型能够生成相应的手部动作和更丰富的面部表情,从而使配音视频在更高维度上实现视听的和谐统一。
这种从”局部修复”到”全身生成”的范式转变,是 InfiniteTalk 模型能够实现后续所有技术突破的起点。它不仅解决了现有技术的根本性痛点,也为 video dubbing 技术未来的发展指明了新的方向。
03 InfiniteTalk 技术深度解读:三大核心技术
InfiniteTalk 是在”稀疏帧 video dubbing”范式下应运而生的核心模型。它通过独特的技术架构和策略,将这一前沿理念化为现实,并取得了显著的成果。
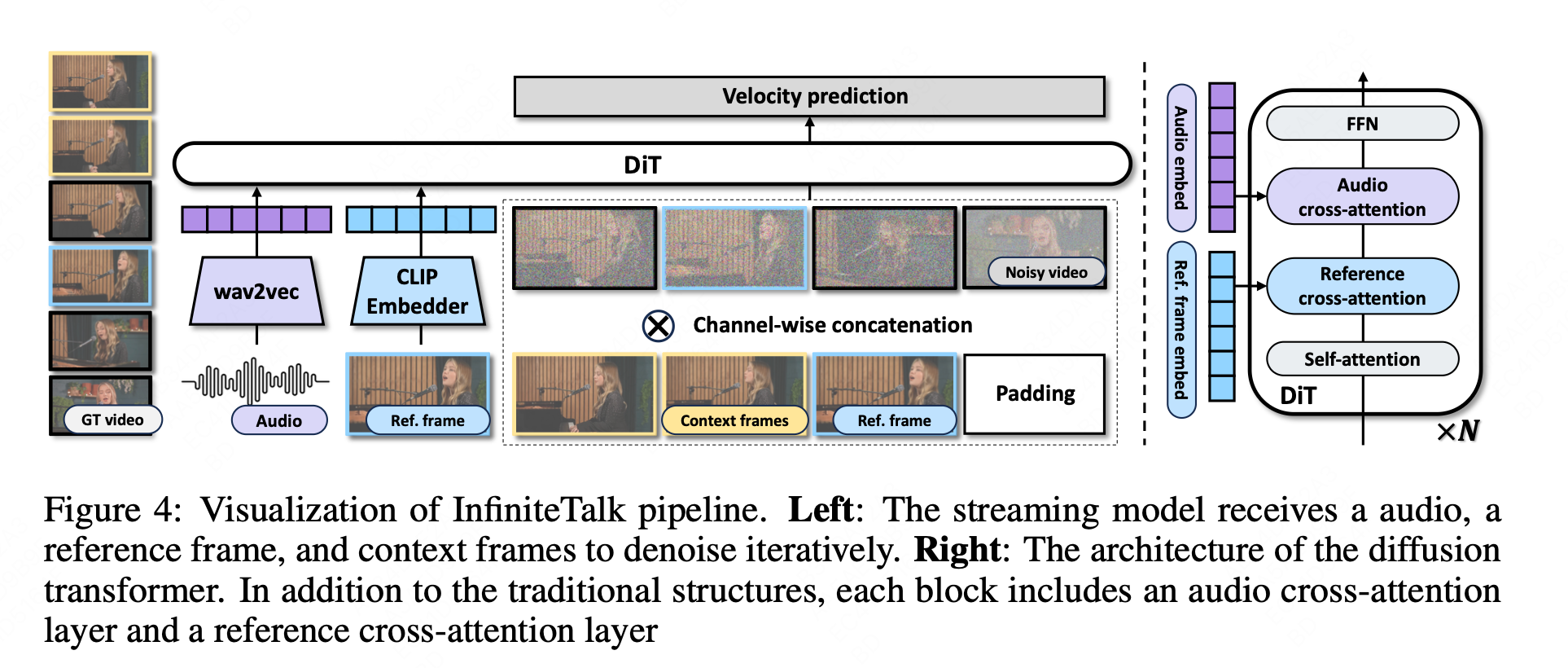
3.1 核心技术一:流式生成架构——长视频无缝衔接的秘密
为了应对无限长度的视频序列生成任务,InfiniteTalk 采用了流式(streaming)生成架构,整体网络框架如下图 4 所示。其工作原理是将一个超长视频分解为多个小的、可管理的视频片段(chunks),然后逐一进行生成。然而,与简单的分段生成不同,InfiniteTalk 的核心在于其精巧设计的”上下文帧”(context frames)机制。
当模型生成一个新片段时,它不仅仅依赖于源视频的参考帧,还会利用上一段已生成视频的末尾帧作为下一段生成的”动量信息”。这些上下文帧为新片段的生成提供了必要的”时间上下文”,使其能够承接前一片段的运动趋势和动态,确保动作的连续性和流畅性。这一机制如同接力赛中的接力棒,将前一棒的冲刺动量无缝传递给下一棒,从而彻底解决了传统 FL2V 模型中因缺乏动量信息而导致的片段间突兀过渡问题。通过流式架构和上下文帧机制的结合,InfiniteTalk 成功地将”片段生成”任务提升为”连续流生成”,这是其实现”无限长度”生成能力的技术基石。
3.2 核心技术二:软条件控制——让 AI 学会”自由”与”跟随”
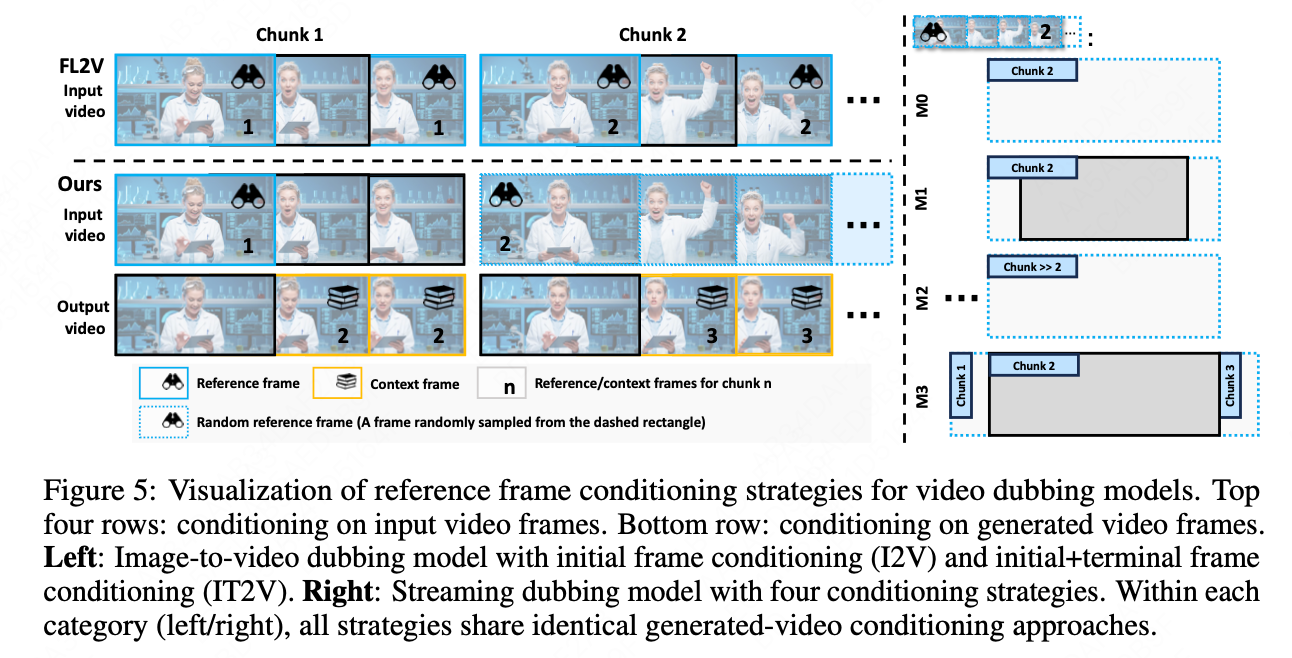
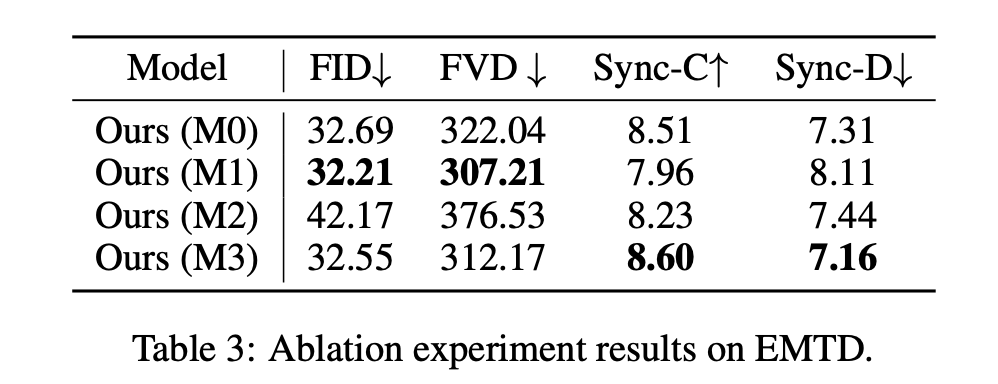
在”稀疏帧 video dubbing”范式下,一个关键的挑战是如何在”自由表达”与”跟随参考”之间找到微妙的平衡。过于严格地复制参考帧(如 M1 策略)会导致生成的动作僵硬,而如果控制过于松散(如 M2 策略),则又会面临身份和背景失真等问题。
InfiniteTalk 的核心策略是采用一种”软条件”(soft conditioning)控制机制 。该机制的核心发现是,模型的控制强度并非固定不变,而是由”视频上下文和参考图像的相似度”所决定 。基于这一发现,我们设计了一种独特的采样策略,通过”细粒度的参考帧定位”(fine-grained reference frame positioning)来动态调整控制强度,从而在动作自然度与参考帧的保真度之间取得平衡。

如表 3 所示,M0 策略因随机采样而控制强度过高,导致模型不恰当地复制参考动作,削弱了同步性。M1 策略虽然在视觉质量上表现尚可,但在同步性上表现较差,因为它过于严格地复制了边界帧。M2 策略因参考帧与上下文帧的时间距离过远,导致模型对身份和背景的控制力不足,最终在视觉质量(FID、FVD)上表现最差。
最终被采纳的 M3 策略,通过在训练中从邻近分块(adjacent chunks)中采样参考帧,找到了一个”最优平衡点”(optimal equilibrium)。这种策略既能确保模型在视觉上遵循源视频的风格,又能赋予模型根据音频动态生成全身动作的自由。这一核心创新证明了,模型能否成功生成自然动作,其关键在于将”控制强度”视为一个可调控的变量,而非固定不变的开关,从而实现了”软条件”这一创新式的突破。
3.3 核心技术三:全方位同步能力——从口型到全身动作的自然对齐
InfiniteTalk 成功地实现了对嘴部、面部表情、头部转动乃至全身动作的音频同步生成,这正是”稀疏帧配音”范式带来的终极能力。
此外,该模型还能通过集成 SDEdit 或 Uni3C 等插件,实现对源视频中微妙的镜头运动(Camera Movement)的精确保留。这一点至关重要,因为它确保了生成的视频不仅人物动作自然,连画面的构图和运镜都与源视频保持一致,进一步提升了视频的真实感和连贯性。
传统模型仅编辑嘴部,无法响应音频中的情感和节奏变化,因此观众会感到不自然。InfiniteTalk 的全方位同步能力则能够根据音频的韵律(Prosody)、情感(Emotional tone)和节奏(Rhythm)生成相应的面部和肢体动作。这种在更高维度上的视听统一与和谐,是其超越传统方法的关键。
04 实验数据与视觉实证
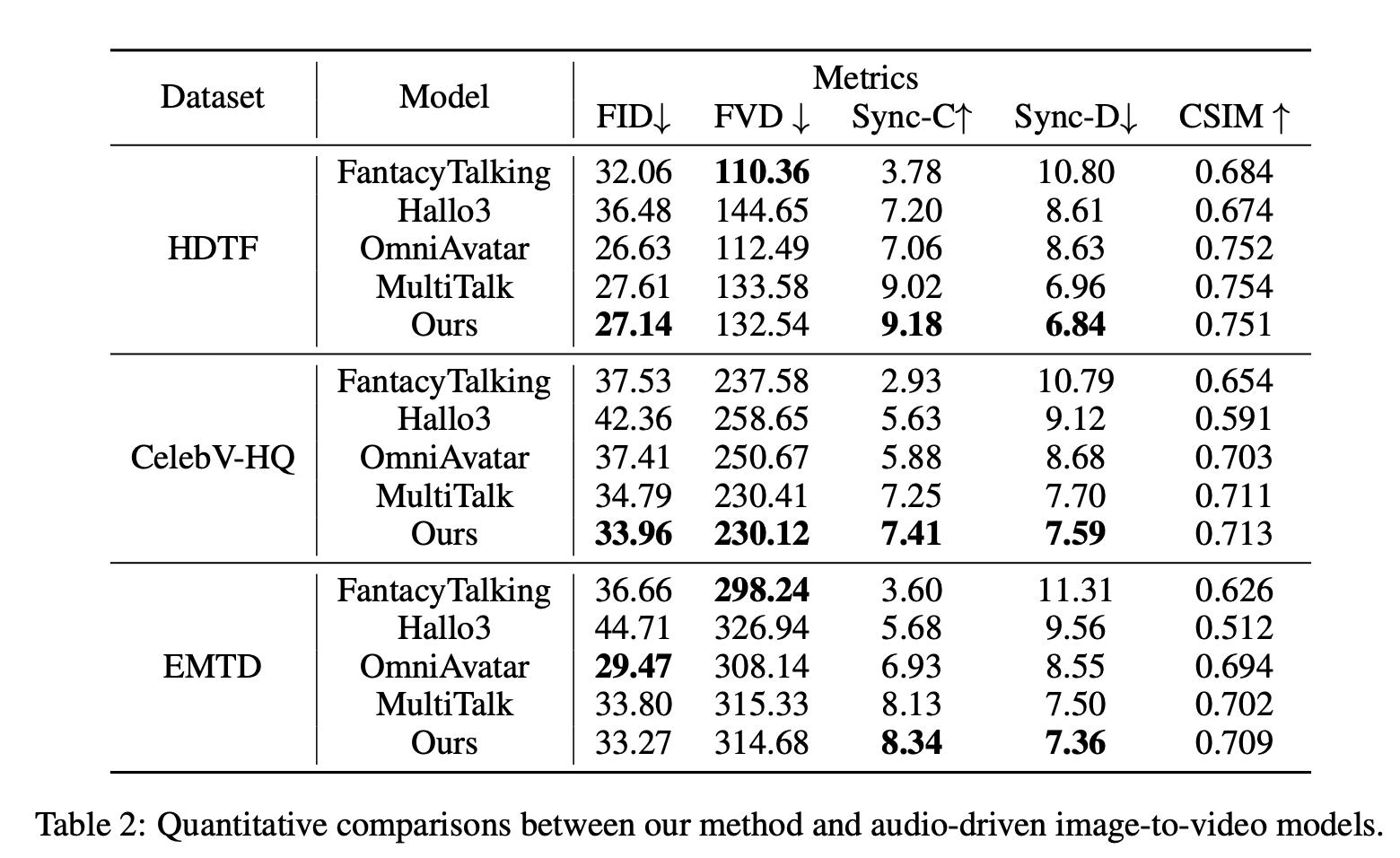
为了全面验证 InfiniteTalk 的性能,我们将其与传统 video dubbing 方法和新兴的音频驱动图像转视频模型进行了对比。
4.1 定量指标对比
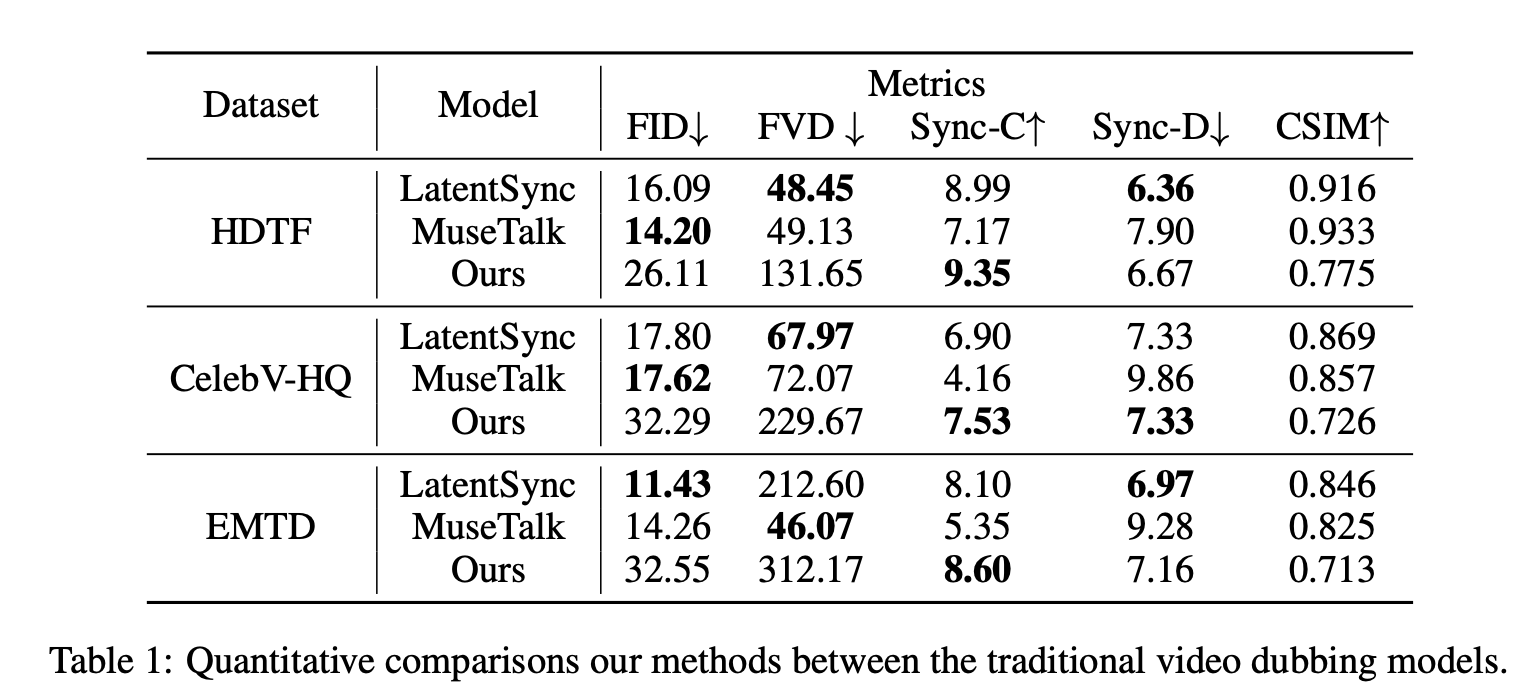
与传统 video dubbing 模型的对比:
与图像转视频模型的对比:
四种不同的参考帧消融实验对比:
4.2 人体评估结果
4.3 定性对比
与不同的 video dubbing 方法对比:

4.4 不同相机控制方法的对比

05 结语与展望:赋能全球媒体,定义内容创作新未来
InfiniteTalk 的诞生标志着 video dubbing 技术进入了一个全新的纪元。它通过提出并实践”稀疏帧 video dubbing”这一创新范式,成功解决了困扰行业已久的”僵硬”与”断裂”两大痛点。其核心技术——流式生成架构、软条件控制以及全方位同步能力,共同为高质量、长序列的视频内容生成提供了前所未有的解决方案。
这项技术所带来的价值远不止于此。它将在多个领域展现出巨大的应用潜力。在流媒体平台的内容本地化方面,InfiniteTalk 能够生成高度自然、情感同步的配音视频,极大地提升观众的观看体验,从而加速内容的全球传播。不仅电商营销视频、本地生活数字人直播、虚拟人导购、虚拟人讲师和陪练等领域,这项技术可以提供强大的生产工具; 而且在短视频创作、虚拟偶像、在线教育、沉浸式体验等领域,该技术以更低的成本、更高的效率生成富有表现力的动态内容,彻底打破现有制作流程的瓶颈。
InfiniteTalk 不仅仅是一项技术突破,更是对沉浸式、高质量视频内容生成的一次重新定义。它为全球媒体内容的本地化和传播开启了新的可能性,为内容创作者们定义了一个更具想象力和创造力的未来。
| 关注「美团技术团队」微信公众号,在公众号菜单栏对话框回复【2024年货】、【2023年货】、【2022年货】、【2021年货】、【2020年货】、【2019年货】、【2018年货】、【2017年货】等关键词,可查看美团技术团队历年技术文章合集。

| 本文系美团技术团队出品,著作权归属美团。欢迎出于分享和交流等非商业目的转载或使用本文内容,敬请注明”内容转载自美团技术团队”。本文未经许可,不得进行商业性转载或者使用。任何商用行为,请发送邮件至 tech@meituan.com 申请授权。
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


