迄今为止最大最好的开源模型,总参数达 1 万亿,屠榜多个基准测试,Kimi K2 Thinking 来了。
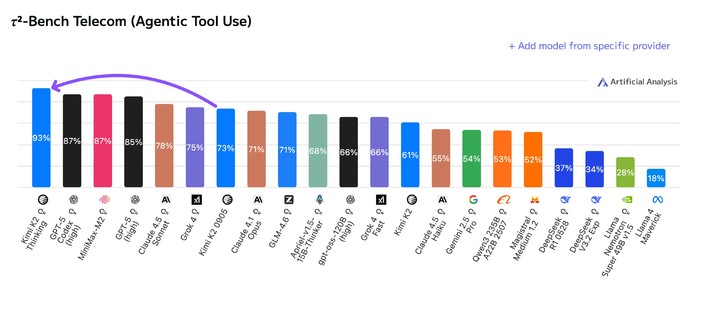
▲ Kimi K2 Thinking 在 TAU 榜单(智能体工具调用能力测试)上排名第一,超过 OpenAI 和 Anthropic 的旗舰模型
一登场就是斩获多个测试榜单的第一名,Kimi 也不玩开源只和开源比那一套,而是直接把 GPT-5、Claude 4.5 Sonnet 这样的闭源模型放一起,非常自信。
▲ 智谱、MiniMax 自然语言处理部门负责人、以及 HuggingFace 联合创始人纷纷在评论区留言祝贺
除了在工具使用的榜单上拿第一,人类最后考试(HLE)、BrowseComp、还有其他基准测试,Kimi K2 Thinking 基本上都占据了先进模型的前排位置。
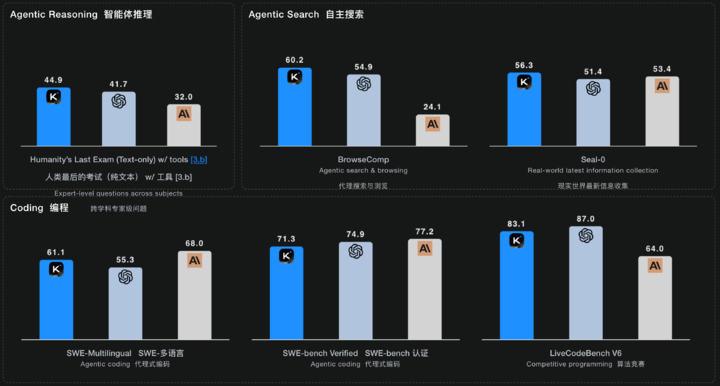
▲ 在跨学科专家级问题的 HLE 榜单、以及自主搜索的三个榜单上,排名第一;编程能力的三个榜单,得分也接近最好的 Claude 或 GPT 模型
无论是对智能体能力要求极高的编程任务、还是通用的推理写作、深度搜索等方面,Kimi K2 Thinking 的性能表现可以说是,目前最接近封闭模型的开源模型。
延续了 7 月份,发布 K2 时,将其定位为自主智能路线图的一部分,Kimi K2 Thinking 也是主打 Agentic Intelligence(智能体智能)。它是一个推理的混合专家(MoE)模型,总参数量 1T,激活参数 32B,上下文长度 256K。
K2 Thinking 能在智能体工具调用中交错思考,同时在保持任务目标的同时,持续进行 200 到 300 次顺序工具调用。尽管工具调用在类似的闭源模型上,已经成为某种程度上的标准,但 K2 Thinking 可能是第一个,具有如此多工具调用能力的开源模型。
对比 K2 0905,K2 Thinking 在具体的任务上的提升,我们总结了 Kimi 的技术博客,有这些亮点。
- 解决需要百步推理的复杂难题:它能将一个庞大的目标分解为数百个子任务,然后像一个项目经理一样逐一执行。官方举例称,它曾通过 23 个交错的推理和工具调用,成功解决了一个博士级的数学难题。
- 更准确的找到详细的信息:通过执行动态的思考 → 搜索 → 浏览器使用 → 思考 → 代码循环,K2 Thinkging 在面对模糊或冷门的搜索需求,能自己上网反复搜索、浏览网页、验证证据,直到找到精准答案。
- 直接把想法变成可用的产品:K2 Thinking 特别擅长前端代码(如 HTML、React),和其他 Vibe Coding 产品一样,能直接把我们的想法写成一个功能完善、响应迅速的网页或软件产品。
- 写出更有人味的文章:逻辑严谨的专业长文,想象力丰富的创意故事,甚至是需要同理心的情感建议,K2 Thinking 在聊天问答这些通用能力上,能做到更扎实、更细腻的推理写作。
目前,Kimi K2 Thinking 已经在 Kimi 官网的聊天模式上线。
但需要注意的是,Kimi 解释说为了保证用户能获得快速、轻量级的体验,当前的网页聊天版本有选择性地减少了部分工具的使用和调用次数。因此,直接在 kimi.com 上聊天,可能暂时无法完全复现上述基准测试中的极限分数。

▲测试中提醒「高峰算力不足,请耐心等待」
此外,能充分发挥 Kimi K2 Thinking 能力的完整智能体模式(Full Agentic Mode)将很快更新。开发者也可以通过 Kimi k2 thinking API 来体验。
我们也快速上手,实测了几个常见的项目,一起来看看实际的体验如何。
首先是编程任务,我们先让他做了一个技能五子棋的小游戏,要求是在普通的五子棋规则上,玩家可以使用技能。
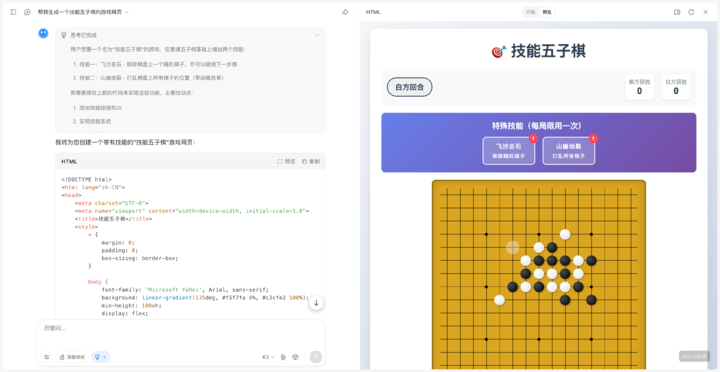
速度很快,出乎我的意料,一两分钟的时间,它就实现了全部的代码,并且真的可以使用这些技能。
然后是骑自行车的鹈鹕,这个经典的测试大模型编程能力的项目,检验它的 SVG 代码生成。
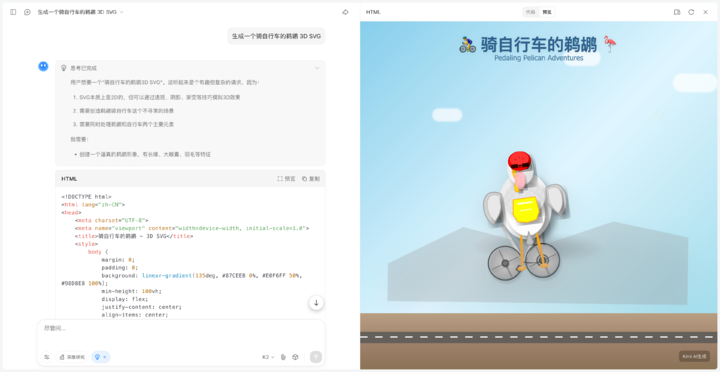
虽然 K2 Thinking 写着推理模型,但是它的推理速度非常快,这段动态的 SVG 代码生成也只花了 1 分钟不到。虽然这个鹈鹕好像有点不太对劲。
开启长思考,即 K2 Thinking 的同时,能启用网络搜索,当我们要它完成一个天气卡片时,能看到 Kimi 会一边自动检索网络上的公开资料,一边完成代码的实现。
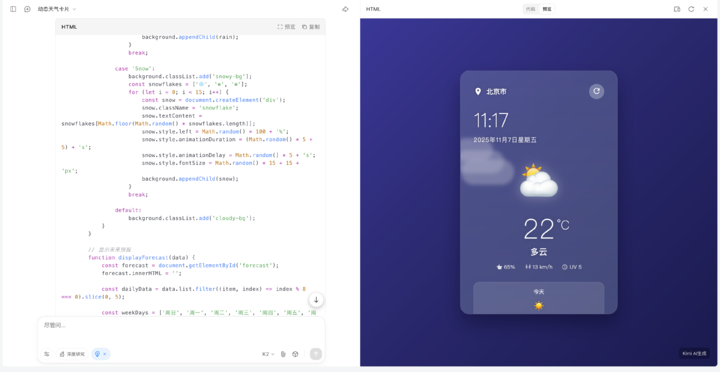
▲确实能调用浏览器的获取位置接口,但是在最后 Kimi 也提到,需要输入对应的地图 API 和 天气信息 API 等数据
现在已经是全民 vibe coding 的时代了,普通用户还是程序员,都能从 K2 Thinking 的编程能力里,更快速地实现自己的想法。
在智能体搜索这个任务上,我们问了他一些专业领域的问题,测试它如何分解复杂问题、主动搜索、并整合难找的网络信息的能力。
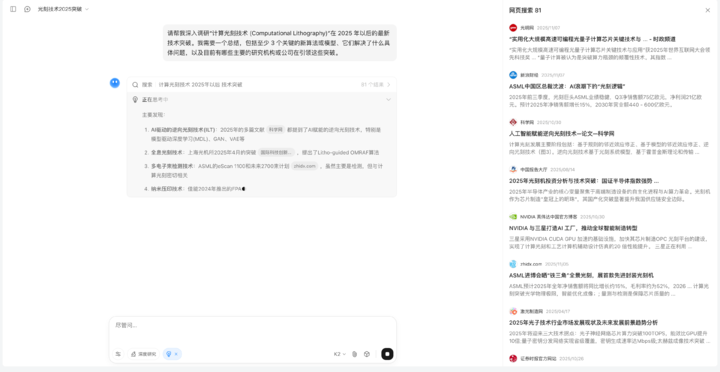
可以看到,Kimi 搜索的信息是比较全面的,当我规定了 2025 年以后,它网页搜索的资料,也大多集中在最近这段时间以来的报道。

最后它给出的报告,也详细的提到了三种 2025 的算法,以及主要的公司等内容。
其实工具调用,应该是 Kimi K2 Thinking 非常重要的能力,但是在我们的体验中,发现大多数时候,他只是调用网络搜索工具,而没有看到 200 多个工具流。
我们在输入一个物流逻辑问题时,很明显是可以调用 Python 等代码解释器来辅助计算,但是 Kimi 只是和其他深度思考的模型一样,一步步地推理。
关于 K2 Thinking 的写作能力,我们找了一个表面上看起来是两难的问题给它。

这个回答有够人性化吗。很明显不是空洞的套话,还提供了周到且具体的思考,也帮助我们平衡了原则和现实两个方面,还有可操作的后续步骤。
在 AI 模型军备竞赛的今天,单纯的问答,很明显已经无法满足,我们复杂的专业需求。像人类专家一样,通过一步一步的推理思考,主动使用各种工具,来解决极其复杂的难题,成了所有大模型的标配。
根据 Kimi 官方文档和技术分析的介绍,这次的思考能力突破关键在训练方式,即高效的量化技术(INT4 QAT),这也是一个值得关注的行业亮点。
K2 Thinking 在后训练阶段采用了量化感知训练 (QAT),让模型能以 INT4 精度本地运行,推理速度提升约 2 倍,同时保持最佳性能。
也就是说,它不是训练完再压缩,而是在训练过程中就贯穿低精度运算模型。这带来了两个巨大优势,一个是推理速度的提升,一个是长链条推理,不会因为量化而造成逻辑崩溃。
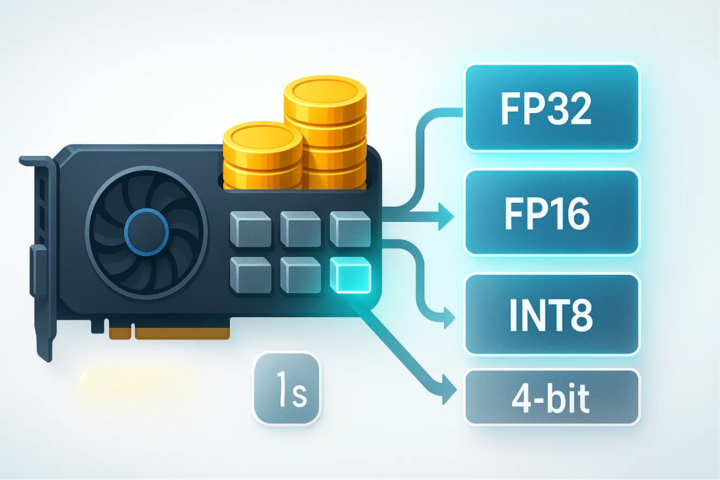
▲使用正确的量化技术,能节省 GPU 显存并加快推理速度
此外,它的所有基准测试成绩都是在 INT4 精度下报告的。说白了,这是一种「所见即所得」的性能,而不是实验室精心调制的数据,K2 Thinking 生来就能跑得动。
我们的实测也能看到,Kimi K2 Thinking 确实不仅仅是一个营销噱头,工具调用、量化技术、以及超长规划,让它在智能体方向上,推理速度上,都有不错的表现。
虽然在某些方面,例如稳定的结果输出、以及对提示词更宽松的要求,还是比不上闭源模型。但是开源能做到这样,我的心里只有两个字,佩服。

过去两年,国产模型的竞争大概是从 Qwen、百度这些模型,对 ChatGPT 的疯狂追赶;到横空出世的 DeepSeek 把推理成本降低的同时,还做到了和 o3 等推理模型,相媲美的表现。
让国产 AI 开始走上了,完全不同于国外闭源模型的路线。OpenAI 发布一个 GPT-5 预热了大半年,Anthropic 的 Claude 系列模型发布周期也在长达几个月。
而 Kimi 在今年七月发布了 K2,九月发布了 K2 Instruct,十一月就迎来了 K2 Thinking;更不用说还有智谱、MiniMax、以及前段时间模型七连发的 Qwen。就连还在期待中的 DeepSeek R2,也更新 V3.2、OCR 等广受好评的模型。
并且,这些模型全部开源。在海外社交媒体平台上,一年前大家可能只知道中国有 DeepSeek,而现在,Qwen 已经是 Hugging Face 上模型下载榜单的 Top 10,Kimi 和智谱(Z.ai)的 GLM 系列模型、以及 MiniMax 都成了大多数用户青睐的模型。
K2 Thinking 的发布,我想是一个新的转折点,就是当我们的开源模型,也能拿到和闭源模型一样的基准分数时,闭源模型还可以讲什么样的故事来营销自己呢。
Gemini 3 据说在今年年底前将发布,而 OpenAI 似乎也害怕再像当时的 nano banana 一样,抢走他的市场,计划推出 GPT-5.1。
军备竞赛还在继续,而国产开源的力量,开始让我们看到,一个好用的 AI,不是屠榜多少测试,是在具有真实用户需求的领域,能真正地提供某些东西,并且惠及所有人。
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

