
<p>过去两周,我们对开源之夏活动中表现优异的开发者们进行了简单的采访,初步粗略地了解了一下他们的开发过程和心得体会。今天,我们将通过同学们的完整结项报告,深入了解项目的开发技术细节,希望能够帮助大家更好地了解 Apache SeaTunnel 项目的最新进展。</p> 接下来是关于在 Flink 引擎上对 Schema Evolution 功能的支持这一项目的完整报告:
一. 已完成工作
根据原定方案(https://ycn2sw1zdz0c.feishu.cn/wiki/QTxYwPcytiG4bxku0vQcrvtlnlb)和时间规 划,已完成在 Flink 引擎上对 Schema Evolution 功能的支持,目前 Sink 端已支持在 Flink 引擎 上进行流式变更的有: JdbcSinkWriter , JdbcExactlyOnceSinkWriter , ConsoleSinkWriter ,已 经测试完毕,目前没有发现在 Schema Evolution 流程中有明显 bug。
✅在 source 和 transform 之间动态插入算子,如果检测到实现了 SupportSchemaEvolution 的类, 并且开启了 schema evolution 的配置,则插入SchemaOperator。 ✅实现 SchemaCoordiantor 协调器,接收 sink 端上报的刷写信息,同时接收 SchemaOperator 上 报的 Schema 变更请求。 ✅扩展 SchemaChangeEvent子类,支持 FlushEvent 事件流转。 ✅扩展 SupportSchemaEvolutionSinkWriter 方法,支持上报刷写成功信息,处理 FlushEvent。 ✅实现 SchemaOperator 算子,检测被 source 端发出的变更事件并处理,支持变更事件透传到下 游。 ✅重写 SupportSchemaEvolutionSinkWriter 关于 Schema evolution方法,目前支持 JdbcSinkWriter,JdbcExactlyOnceSinkWriter ,ConsoleSinkWriter,测试完毕,符合预期。 ✅扩展 FlinkRowCollector 的 collect 方法,支持变更事件的收集。 ✅扩展 FlinkSinkWriter 方法,支持检测变更事件并处理。 ✅扩展 SchemaEvolution 错误码和异常体系,变更出现异常时支持详细异常信息上报。 ✅变更任务出现异常后,自动抛出异常,交给重试机制处理。
二. 遇到的问题及解决方案
1. 事件流转问题
在 source 端和 transform 中间插入一个 operator时,需要在内部判断流转过来的元素是否是事 件,如果是事件,就阻塞,等待刷写变更之后再次流转;否则就继续向下流转,有两种方案:
- 和 Zeta 引擎保持一致,创建类似 Record 的类 StreamElement ,但是从 source 到 transform 到 sink 端的所有链路,关于 SeatunnelRow 的都要修改为 StreamElement,入侵性极高,且非常危 险,影响面大。
- 在 SeatunnelRow 中添加特殊标记,比如在 options 里面添加一个选项,如果遇到事件,存储到额 外信息里面,这样对链路入侵性不高,但是违反单一设计原则,按理来说 SeatunnelRow 不应该关 心事件,只负责数据流转,之后如果架构升级可以重构,目前以实现功能为主,减小风险。
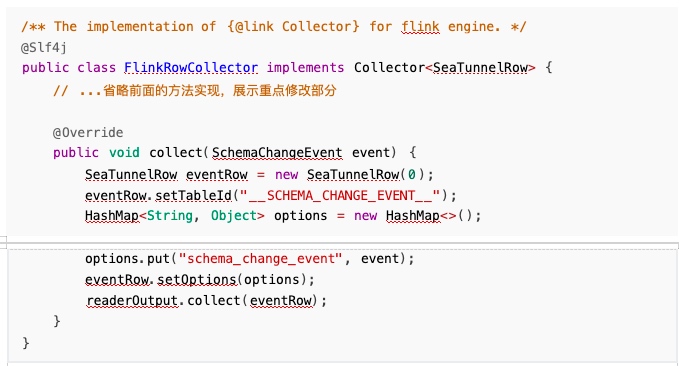
之后就可以在 SchemaOperator 算子里面检测到这个标记了:


但是这样同样会带来一个问题,就是我们 new 了一个空行,会导致 sink 端的写入报错,所以需要 在 sink 端检测:



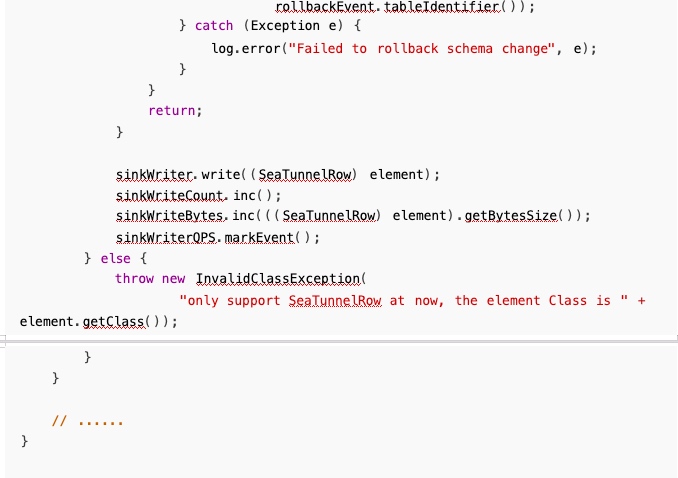
这样就能解决事件透传的问题。
2. 多并行度问题
实际上在 Flink CDC 的实现中,增量快照阶段,按照用户定义并行度开启任务,读取快照数据;进 入增量阶段后,为了保证顺序,只会保留一个任务来读取,所以我们不需要给协调器多么复杂的实现, 让它正常接收 sink 端响应即可,也不用考虑多个分区重复上报以及顺序问题: 







关于 source 端明明是一个任务,但是 sink 可能是多个任务的问题,看了下 flink cdc 相关源码, CDC source 确实是由一个任务来读取 binlog,但之后数据通过 KeyGroupStreamPartitioner 按主键 hash分发,不同的 key 被发送到不同的 sink 任务,每个 sink 任务处理分配给它的 key 范围的数据:
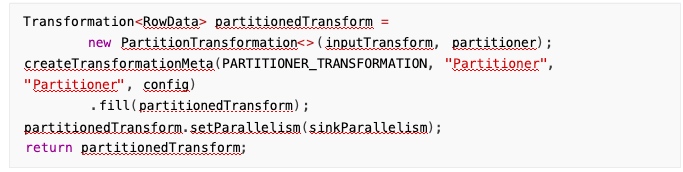
具体实现里面,会先检查 sink 端和 input 的并行度是否相同,如果不同,会采取 primary key shuffle 的手段: 
sink 配置了自定义并行度且不等于输入并行度时, Flink 会进行特殊处理: 
如果 sink 并行度与 input 并行度不同,会通过 primary key 进行 shuffle:

Flink 自己应该支持这种 sink 端的多并行度,但是我有几个考虑的点:
- 如果真要实现这种机制, Shuffle 的实现对我来说有难度。
- 如果多个并行度同时收到变更命令,对于幂等性的数据库来说,变更可能不受影响,但是像 StarRocks 这种 OLAP 数据库没有幂等性,所以有困难,当然这种也有解决办法,就是收到几个分 区的刷写完成响应之后,协调器收到 ack,让协调器来变更,同样也很麻烦,不如让 source 和 sink 使用相同并行度,在一条算子链里面,也不用 shuffle,但是还有一个点是,数据量大的情况下可能 影响性能。
所以,我目前检测到 cdc 变更之后强制指定 sink 端并行度就是1,这样也不会有上面的问题,之后 可以进行迭代来支持 sink 端的需求:


3. 刷写与请求的执行顺序问题
之前在 SchemaOperator 算子里面处理变更事件的时候,我先发送了刷写事件,之后才请求协调器 进行变更,这样会有一个问题,协调器内部的 SchemaChangeState 还没有进行初始化,所以之后协调 器迟迟获取不到 State,先一步到的 FluEvent 也没有被成功接收, 一直阻塞,之后任务超过了我设定的 超时时间,任务就失败了。 分析日志后发现:
- 12:33:36,597 – FlushEvent 被处理, Sink 立即上报了 flush 成功
- 12:33:36,597 – 协调器警告: “No schema change state found”
- 12:33:36,598 – 协调器才创建 schema change state
再次查看我写的代码:

所以问题就比较明显, Sink 的 flush 通知比协调器的 requestSchemaChange 更早到达,导致通知 被丢弃,我们只需要修改执行顺序即可解决此问题:


4. FlushData 和 变更问题
之前我在实现的时候, FlushEvent 内部包裹着 SchemaChangeEvent,在 FlushData 的同时就把表 变更了,这样有一个问题就是职责不清晰,比较混乱,之后就把职责分开,刷写数据就只刷写数据,之 后上报协调器,再次发送变更事件,真正进行变更: 
5. 默认实现与接口职责问题
目前为了向前兼容,SupportSchemaEvolutionSinkWriter 中新增方法均被标记为 default,之后再 进行迭代。迭代完毕之后,即可取消 default 关键字: 

6. 变更失败后标记失败 or 回滚问题
有一个问题是,假设说因为网络问题或者其他问题,作业失败了,那么应该直接标记作业失败,让 Flink 自己从检查点拉起作业,还是让其直接回滚?
Flink CDC 的实现是直接标记失败,之后从检查点恢复,目前我采用的是标记失败的策略,考虑的点 是,主动回滚开发相当麻烦,可能还需要 flink ck 进行适配,直接让 schema 变更失败时抛出异常,让现 有的重试机制处理就行,而且也观察到 SeaTunnel 这边做了重试相关的机制, Flink自己有全局重试策略,no ,fixed-delay ,failure-rate(已实现,已测试)。
因为要抛出异常,直接抛出 RuntimeException 对开发者定位问题和用户都不是很友好,所以增强 了异常机制,实现了自己的异常类,错误码和异常方法。 异常处理示例:


三. 测试用例与结果
关于 MySQLCDC to MySQL 场景测试报告如下: ✅add column 场景测试报告:https://ycn2sw1zdz0c.feishu.cn/wiki/XYotwQ7QeiJqsikiTEscBXwcn ✅drop column 场景测试报告: https://ycn2sw1zdz0c.feishu.cn/wiki/QU73wXqTpirfZmk6NDCc1i 1wnDf ✅modify column 场景测试报告: https://ycn2sw1zdz0c.feishu.cn/wiki/NXVwwTLf8iWUiFk6nGgcv GJGnmd ✅change column 场景测试报告: https://ycn2sw1zdz0c.feishu.cn/wiki/UoIvwdUcJiutXSkyvm1ceb LcnUh
四. 后续工作计划
- 目前并不是所有支持 schema evolution 的 sink 端均实现了,后续支持SupportSchemaEvolutionSinkWriter 相关子类的实现。
- 测试不同数据源之间的流转情况,修复可能的小 bug。
- 测试大量数据情况下是否会出现严重阻塞问题。
- 测试高并发情况下是否有不一致性问题。
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


