
<h2>前言:一个新选择的出现</h2> 2025年金秋,数据库领域迎来了一个引人注目的时刻——天翼云 OpenTeleDB 正式宣布开源。这一消息对于众多数据库从业者、架构师以及开发者而言,无疑是在技术选型的版图上点亮了一颗新星。在当前数据驱动的时代,企业面临着日益复杂的业务场景:既要处理高并发的在线交易(OLTP),又要对海量数据进行实时分析(OLAP)以获取业务洞察。传统架构通常采用”交易型数据库 + ETL + 分析型数据库”的组合,这种模式虽然成熟,但其固有的数据延迟(T+1)、架构复杂性以及高昂的维护成本,正成为制约业务敏捷性的瓶颈。
混合事务/分析处理(HTAP)数据库的出现,正是为了解决这一痛点。它旨在打破OLTP和OLAP之间的壁垒,实现”一份数据,两种负载”的理想状态。OpenTeleDB正是这样一款定位为分布式HTAP的数据库。它的开源,意味着一个集强大分析性能与稳定事务处理能力于一身的数据库解决方案,向整个技术社区敞开了大怀抱。
本文将完整记录一次从零开始的OpenTeleDB深度体验之旅。这趟旅程不仅包括了详细的安装部署过程、遇到的挑战及解决方案,更重要的是,通过实践去验证其核心价值,并最终回答一个关键问题:在众多特性之中,OpenTeleDB最打动人的一点究竟是什么?它又为实际工作带来了哪些具体的便利?
一、初识OpenTeleDB:理论基础与核心价值
在动手实践之前,建立对OpenTeleDB的正确认知是至关重要的第一步。
- OpenTeleDB 数据库开源社区 :https://openteledb.ctyun.cn/open/index
- OpenTeleDB 代码仓 :https://gitee.com/teledb/openteledb
从官方资料可以了解到,OpenTeleDB是一款构建在PostgreSQL内核之上的分布式HTAP数据库。这个定义包含了两个关键点:
-
分布式HTAP架构:这是其核心能力。意味着OpenTeleDB不仅能够像传统关系型数据库一样高效地处理增、删、改、查等高并发短事务,还能在同一份数据上执行复杂的分析查询,无需进行耗时的数据迁移和转换。其分布式特性则保证了系统可以通过水平扩展节点来应对数据量和并发量的增长,具备高可用性和高可扩展性。
-
基于PostgreSQL内核:这是其生态优势。PostgreSQL被誉为”世界上最先进的开源关系数据库”,以其稳定性、功能的全面性、强大的扩展能力以及严格的SQL标准符合度而闻名。OpenTeleDB选择基于PostgreSQL,是一种非常明智的技术决策。这意味着它天然继承了PostgreSQL成熟的SQL引擎、丰富的数据类型、强大的事务管理机制以及庞大而活跃的社区生态。
这种技术选型直接指向了OpenTeleDB的核心价值主张:在提供现代化HTAP能力的同时,最大化地降低用户的学习、迁移和使用成本。 这也正是本次体验想要深入验证的重点。
二、环境搭建:从零到一的实践之路
理论的认知需要通过实践来检验。接下来,将详细记录在Ubuntu环境下,通过源码编译方式安装OpenTeleDB的全过程。
2.1 硬件与软件环境要求
官方文档给出了明确的环境要求,这是部署工作的起点。
硬件环境要求
表1:硬件环境要求
|项目 |配置描述| |—|—| |内存|功能调试建议8GB以上。性能调试或商业部署建议16GB以上。复杂的查询对内存的需求量比较高,在高并发场景下,可能出现内存不足。此时建议使用大内存的机器,或使用负载管理限制系统的并发。| |CPU|功能调试最小1核,建议x86架构,2.0GHz。性能调试和商业部署建议16核以上。个人开发者最低配置2核4G, 推荐配置4核8G。| |硬盘|用于安装TeleDB的硬盘需满足如下要求:建议至少10GB硬盘空间,具体需求取决于数据库的大小和增长预期。|
解读:这些要求是相当标准的。内存对于数据库性能至关重要,特别是对于需要进行复杂分析的HTAP场景,更大的内存可以容纳更多的数据缓存和中间计算结果,显著提升查询速度。CPU核心数则直接影响并发处理能力。对于初次体验和功能验证,遵循个人开发者的推荐配置(4核8G)是比较合适的。
软件环境要求
表2:软件环境要求
|软件类型 |配置描述| |—|—| |Linux操作系统|Linux 各主流发行版(CentOS, RedHat, Ubuntu, Debian)等。|
解读:对主流Linux发行版的广泛支持,体现了其良好的平台兼容性。本次实践选择的操作系统是Ubuntu。
软件依赖要求
软件依赖是源码编译安装中最容易出现问题的环节。
表3:软件依赖要求
|所属软件 |建议版本| |—|—| |gcc|4.8 及以上| |gcc-c++|4.8 及以上| |make|3.82 及以上| |bison|3.0 及以上| |flex|2.5.31 及以上| |readline-devel|6.0 及以上| |zstd-devel|1.4.0 及以上| |lz4-devel|1.8.0 及以上| |openssl-devel|1.1.1 及以上|
解读:这些依赖项都是构建C/C++项目时的标准工具链和库。
gcc/gcc-c++是C/C++编译器。make是一个自动化构建工具,用于根据Makefile文件编译和链接程序。bison和flex是用于生成语法分析器和词法分析器的工具,对于解析SQL语言至关重要。readline-devel提供了命令行编辑功能,让psql等客户端工具更好用。zstd-devel,lz4-devel是压缩库,可能用于数据压缩功能。openssl-devel提供加密和安全连接功能。
2.2 源码编译安装实录
步骤一:获取源代码
官方提供了两种方式:下载安装包或使用Git。对于开发者而言,使用Git克隆源代码是更灵活的方式,便于后续查看源码或跟进版本更新。
执行git clone命令从Gitee代码仓拉取源代码。
git clone https://gitee.com/teledb/openteledb.git
 上图展示了
上图展示了git clone命令的执行过程,它将远程仓库的完整代码下载到本地一个名为openteledb的目录中。
进入该目录,可以看到项目的完整结构。  这张图确认了我们已经成功进入了源代码的根目录,
这张图确认了我们已经成功进入了源代码的根目录,ls命令列出了项目顶层的文件和文件夹,其中包含了后续编译所需的configure脚本等关键文件。
 这张图进一步展示了更详细的文件列表,让我们对项目结构有了初步的认识。
这张图进一步展示了更详细的文件列表,让我们对项目结构有了初步的认识。
步骤二:安装依赖与”第一个坑”
官方安装指南中提供了一条yum命令来安装所有依赖。
yum install -y curl-devel libicu-devel pam-devel krb5-devel openldap-devel systemd-devel readline readline-devel zlib zlib-devel gettext gettext-devel openssl openssl-devel pam pam-devel libxml2 libxml2-devel libxslt libxslt-devel perl perl-devel tcl-devel uuid-devel gcc gcc-c++ make flex bison perl-ExtUtils* libcurl-devel asciidoc xmlto opensp mariadb-devel libtool libuuid-devel gflags-devel lcov libyaml-devel boost boost-devel libgsasl-devel cmake3 golang
【遇到的坑点 1】 :包管理器不匹配。 yum是CentOS、RedHat等基于RPM的Linux发行版的包管理工具。而本次实践使用的系统是Ubuntu,其包管理器是apt。直接执行yum命令会失败。
解决方案 :这是一个常见问题,解决方法是将yum命令及其包名转换为等效的apt命令和包名。这是一个细致的工作,需要将-devel后缀的开发包名转换为Ubuntu中对应的-dev后缀。
首先,养成良好习惯,更新系统包列表:
sudo apt update
然后,执行转换后的apt命令安装所有依赖:
sudo apt install -y build-essential libcurl4-openssl-dev libicu-dev libpam0g-dev libkrb5-dev libldap2-dev libsystemd-dev libreadline-dev zlib1g-dev gettext libssl-dev libxml2-dev libxslt1-dev libperl-dev tcl-dev uuid-dev flex bison libtool libuuid1 g-wrap libgflags-dev lcov libyaml-dev libboost-dev libgsasl-dev cmake golang
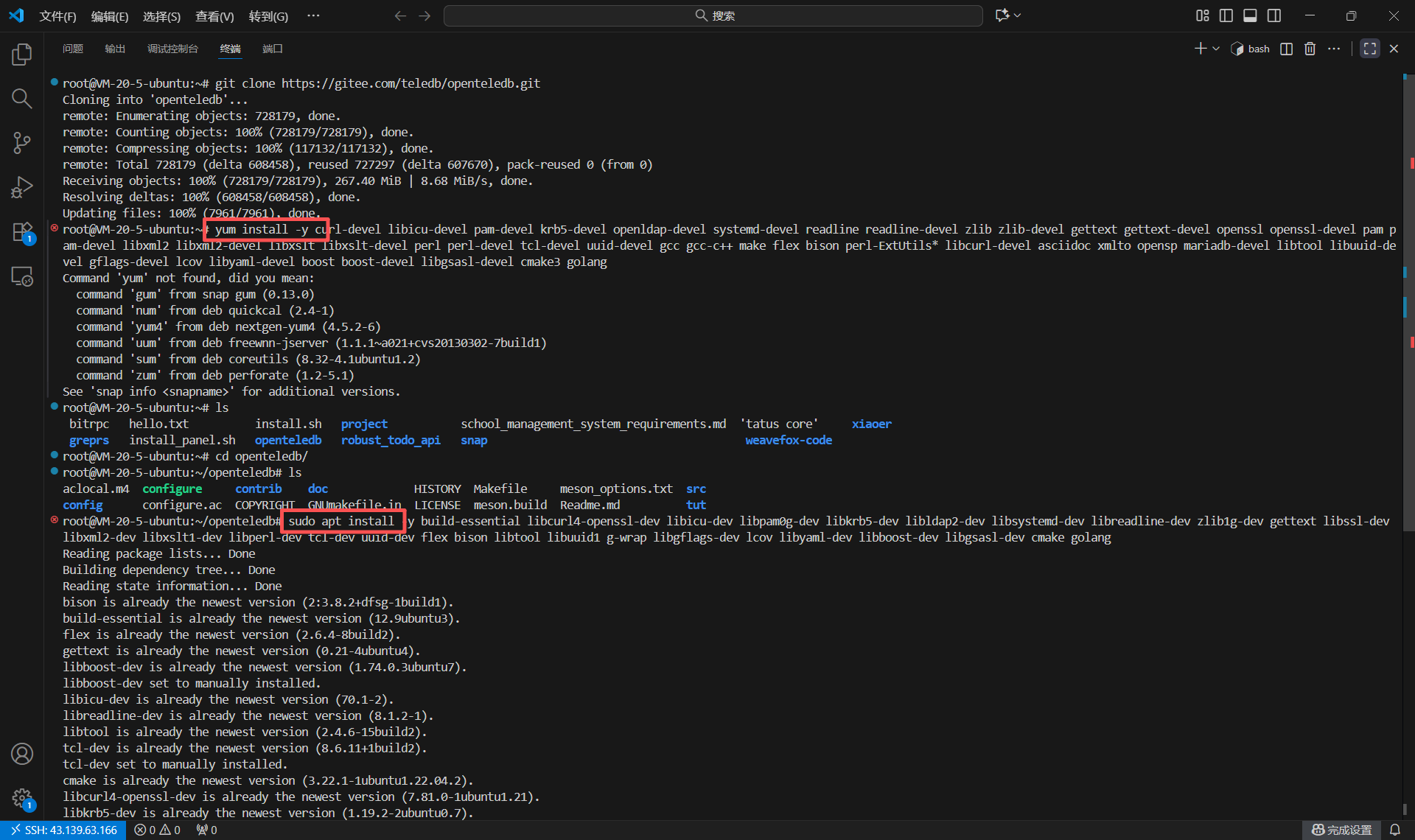 上图清晰地记录了
上图清晰地记录了apt install命令的执行过程。终端输出了正在获取和安装的大量软件包,这表明依赖安装正在顺利进行。这个过程的成功,是后续编译工作能够开始的前提。
步骤三:编译前的准备 – 环境变量与”第二个坑”
编译安装通常分为三步:configure(配置)、make(编译)、make install(安装)。
首先,设置环境变量来指定源码目录和最终的安装目录。这样做可以使后续命令更简洁,也便于管理路径。
# 设置源码目录路径 (当前所在目录)
export codes_dir=$(pwd)
# 设置 OpenTeleDB 的安装路径
export pg_install_dir=~/openteledb_install
 这张图展示了环境变量的设置。
这张图展示了环境变量的设置。$(pwd)是一个非常实用的命令,它会自动获取当前工作目录的绝对路径。pg_install_dir则指定了编译完成后,程序文件将被安装到用户主目录下的openteledb_install文件夹。
接下来,运行configure脚本。这个脚本会检查系统环境,确认所有必需的依赖库是否都已安装,并根据指定的参数生成后续make命令所需的Makefile文件。
./configure --prefix=${pg_install_dir} --with-libxml --with-uuid=ossp --with-openssl --with-xstore
【遇到的坑点 2】 :命令执行路径错误。 执行上述命令后,系统返回错误:bash: ./configure: No such file or directory。  上图准确地复现了这个错误。这个错误提示信息非常明确:”没有那个文件或目录”。
上图准确地复现了这个错误。这个错误提示信息非常明确:”没有那个文件或目录”。
原因分析 :这是初学者常犯的错误,混淆了源码目录 和安装目录。
- 源码目录 (
~/openteledb) :通过git clone下载的,包含所有源代码和configure脚本的地方。 - 安装目录 (
~/openteledb_install) :通过--prefix参数指定的,用于存放最终编译产物的目标位置。在make install执行前,这个目录通常是空的。
./configure命令必须在源码目录中执行。
解决方案:确保当前工作目录是源码目录。
-
进入正确的源码目录 :
cd ~/openteledb -
重新执行配置、编译和安装命令 :
# 再次确认安装目录环境变量 export pg_install_dir=~/openteledb_install # 运行 configure ./configure --prefix=${pg_install_dir} --with-libxml --with-uuid=ossp --with-openssl --with-xstore # 编译和安装 (这一步需要较长时间) make && sudo make install
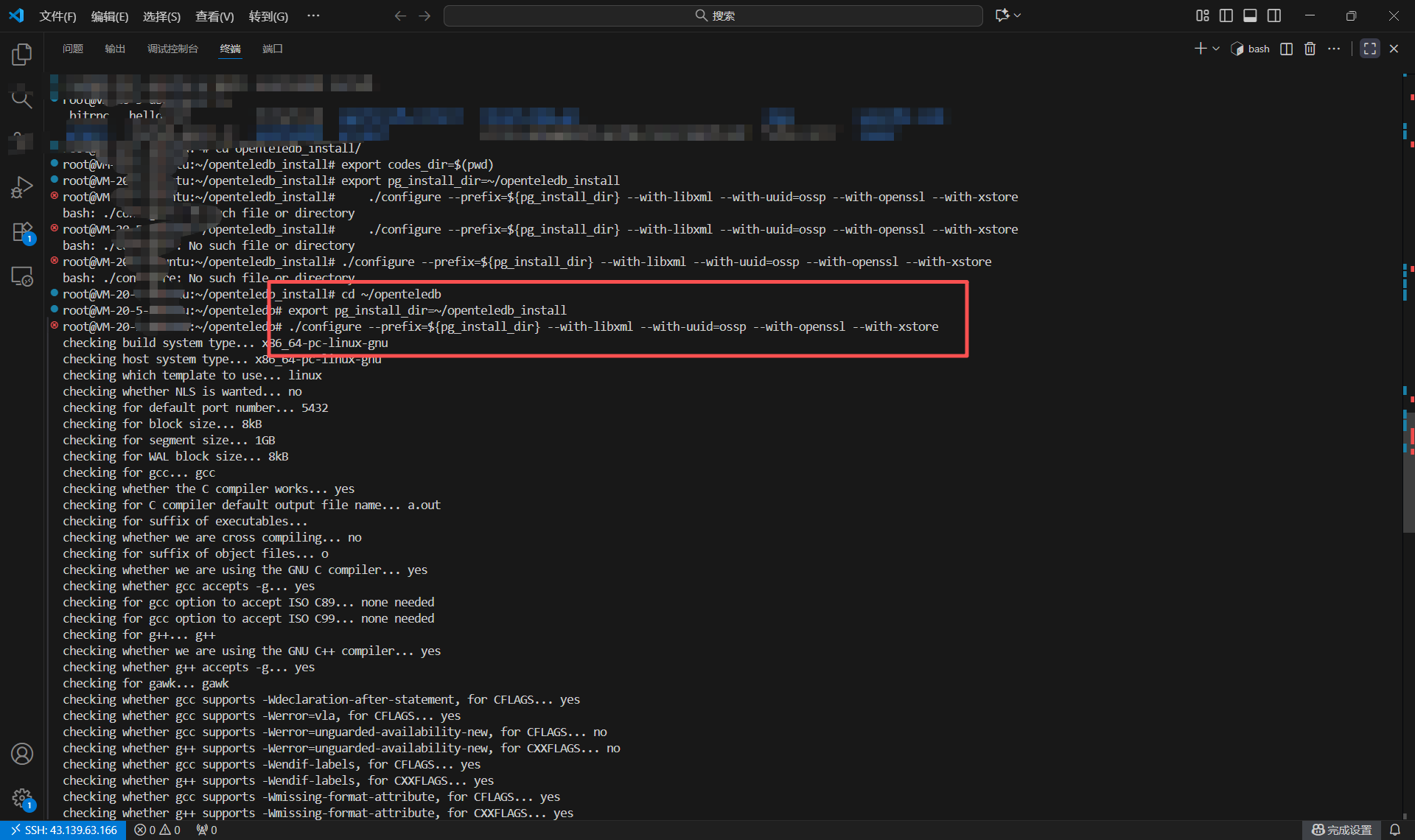 这张图展示了在正确的源码目录下成功执行
这张图展示了在正确的源码目录下成功执行./configure命令后的输出。终端显示 “checking for…” 的信息流,这表明配置脚本正在检测系统环境。这是编译过程走上正轨的标志。
步骤四:编译与安装 – 攻克”第三个坑”
在执行make命令进行编译时,遇到了新的问题。
【遇到的坑点 3】 :缺少 ossp-uuid 开发库。 编译过程中,链接器报错,提示找不到与UUID相关的函数。 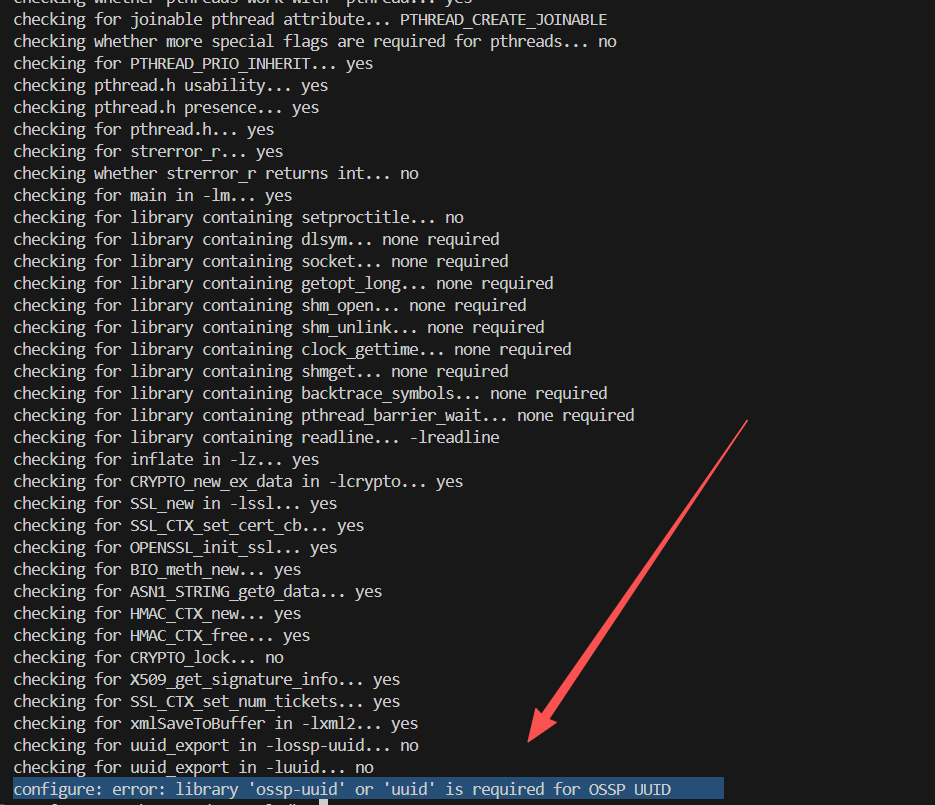 上图是
上图是make命令执行过程中的错误截图。错误信息中明确提到了 “uuid.c” 和 “undefined reference to uuid_create'" 等关键信息,直接指向了UUID库的缺失。configure脚本中的–with-uuid=ossp`参数指定了使用OSSP UUID库,但系统中可能只安装了运行时库,而没有安装编译所需的头文件和静态链接库,也就是开发包。
解决方案 :安装对应的开发包 ossp-uuid-dev。
sudo apt-get install -y ossp-uuid-dev
在尝试安装时,又遇到了一个衍生问题:系统提示在标准软件源中找不到这个包。这通常是因为该软件包位于一个默认未启用的软件仓库(如 universe)中。
最终解决:
-
启用 universe 仓库:
sudo add-apt-repository universe -
刷新软件源列表并安装:
sudo apt update sudo apt-get install -y ossp-uuid-dev
在解决了所有依赖问题后,重新执行./configure, make, sudo make install。然而,在本次实践中,由于本地虚拟机磁盘空间不足,导致编译过程最终失败。为了顺利完成体验,切换到了资源更充裕的云端”算力平台”上,重复了上述所有正确的步骤。
步骤五:在云端平台完成安装与初始化
在新的云环境中,编译和安装过程非常顺利。make && sudo make install命令成功执行完毕。 
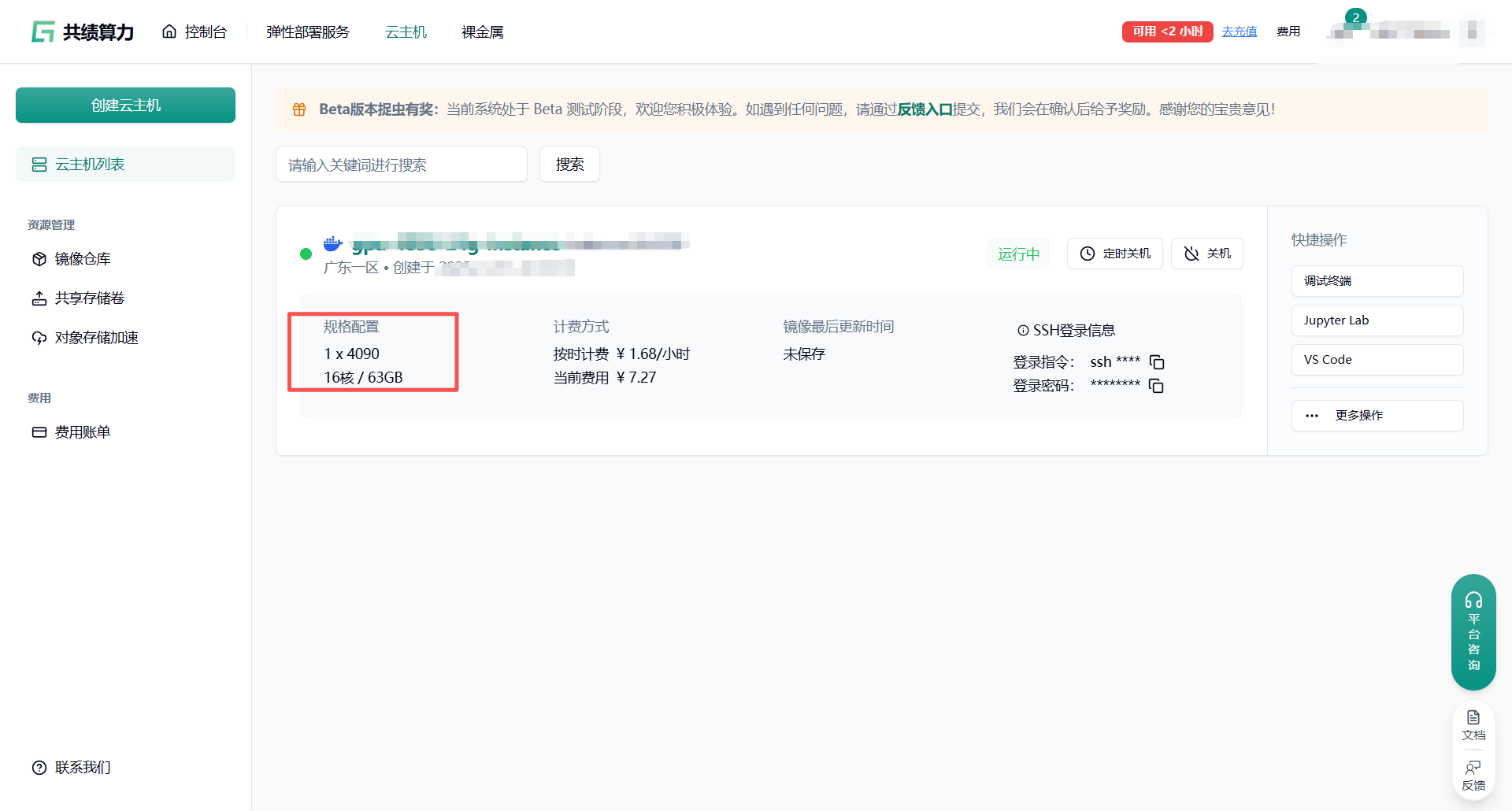
安装完成后,需要进行数据库的初始化和启动。这通常涉及以下步骤:
-
创建数据目录和用户 :出于安全考虑,不推荐使用root用户运行数据库。创建一个专门的普通用户(例如
openteledb)来管理数据库。# 切换到安装目录 cd ~/openteledb_install # 创建数据存储目录 mkdir data # 创建用户并授权 useradd openteledb chown -R openteledb:openteledb ~/openteledb_install

-
切换到新用户并初始化数据库:
su - openteledb # 将openteledb的bin目录加入PATH,方便后续操作 echo 'export PATH=~/openteledb_install/bin:$PATH' >> ~/.bash_profile source ~/.bash_profile # 初始化数据库集群 initdb -D ~/openteledb_install/datainitdb命令成功执行后的输出。它创建了数据库运行所需的所有子目录和配置文件,并提示了如何启动数据库服务。这是数据库首次”诞生”的时刻。这里需要我们进行临时环境变量的配置。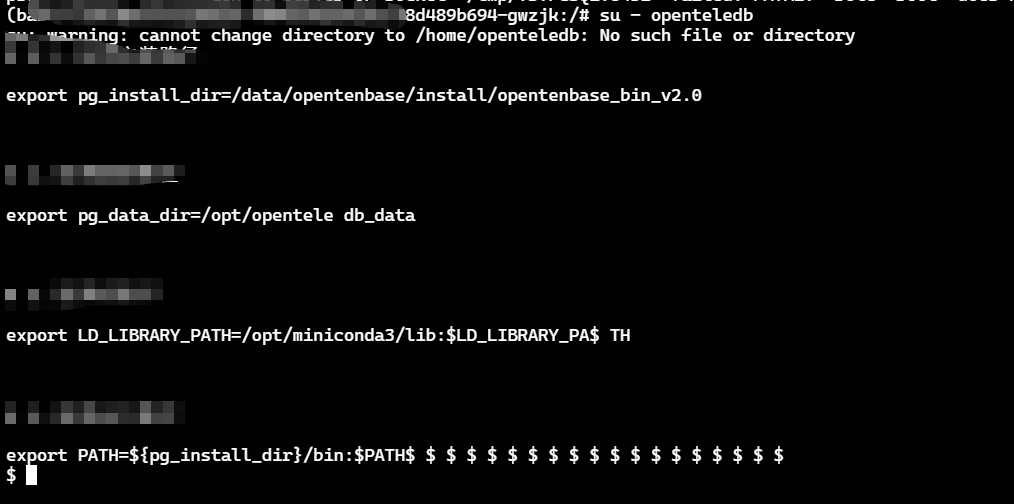
-
启动数据库服务:
pg_ctl -D ~/openteledb_install/data -l logfile start数据库启动命令的执行,并提示 “server started”。此时,OpenTeleDB数据库已经在后台成功运行。
-
连接数据库 :使用
psql客户端工具连接到数据库。psql -d postgres这张图展示了
psql成功连接到默认的postgres数据库。命令行提示符变为postgres=#,这表明我们已经进入了数据库的交互式环境。
 这张图是最终成功登录数据库客户端的界面,一个功能完备的OpenTeleDB实例已经准备就绪,可以开始进行功能和性能的探索。
这张图是最终成功登录数据库客户端的界面,一个功能完备的OpenTeleDB实例已经准备就绪,可以开始进行功能和性能的探索。
安装过程小结 :源码编译安装虽然步骤繁琐,且容易因环境差异遇到各种问题,但它提供了最高的定制性和灵活性。整个过程完整地体验了从无到有的构建,加深了对系统依赖和结构的理解。遇到的三个”坑点”都非常典型,分别是:包管理器差异、命令执行路径错误、编译依赖缺失。这些都是开源软件部署中常见的挑战,解决它们的过程本身就是宝贵的经验积累。
三、小试牛刀:体验无缝兼容的PostgreSQL生态
数据库安装完成后,最直接的验证方式就是进行基础的CRUD(创建、读取、更新、删除)操作。这个环节的目标是检验OpenTeleDB对标准SQL的兼容性,特别是与PostgreSQL的兼容性。
1. 创建一个新数据库
为接下来的测试创建一个专门的数据库mydemo。
CREATE DATABASE mydemo;
2. 连接到新数据库
使用psql的元命令\c切换到新创建的数据库。
\c mydemo
 上图显示了成功切换数据库后的
上图显示了成功切换数据库后的psql界面。连接信息提示已连接到数据库mydemo,命令行提示符也相应地变为mydemo=#。
3. 创建一张经典的行存表(用户表)
这是一张典型的OLTP业务场景表,用于存储用户信息。
CREATE TABLE users (
id SERIAL PRIMARY KEY,
username VARCHAR(50) NOT NULL UNIQUE,
email VARCHAR(100),
registration_date TIMESTAMP WITH TIME ZONE DEFAULT NOW()
);
该CREATE TABLE语句使用了SERIAL(自增整数)、PRIMARY KEY(主键)、VARCHAR、TIMESTAMP WITH TIME ZONE等PostgreSQL中非常标准的数据类型和约束。
4. 插入 (Create) 数据
向users表中插入三条记录。
INSERT INTO users (username, email) VALUES
('alice', 'alice@example.com'),
('bob', 'bob@example.com'),
('charlie', 'charlie@example.com');
5. 查询 (Read) 数据
使用SELECT语句验证数据是否已成功插入。
SELECT * FROM users;
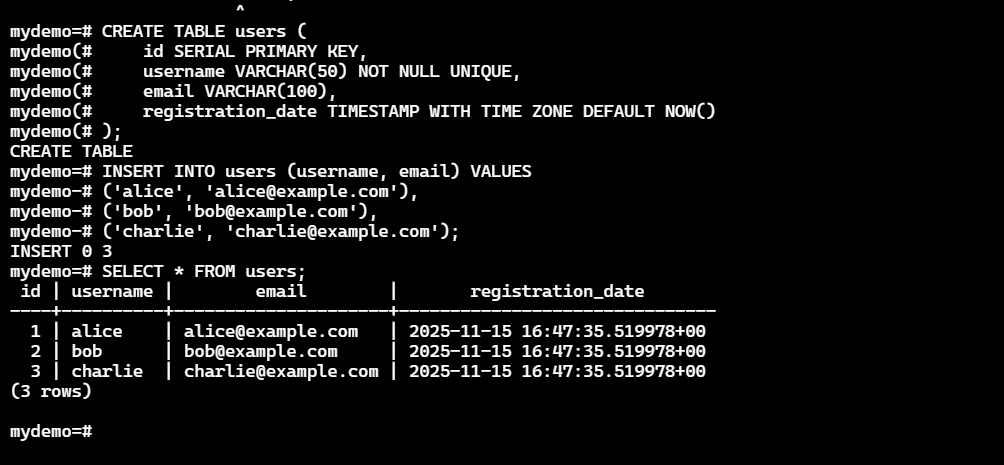 上图是
上图是SELECT查询的结果。它准确地返回了刚才插入的三条记录,id字段也按预期自动递增,registration_date字段填充了默认的当前时间。这证明了INSERT和SELECT操作完全符合预期。
6. 更新 (Update) 数据
修改bob用户的邮箱地址。
UPDATE users SET email="bob_new@example.com" WHERE username="bob";
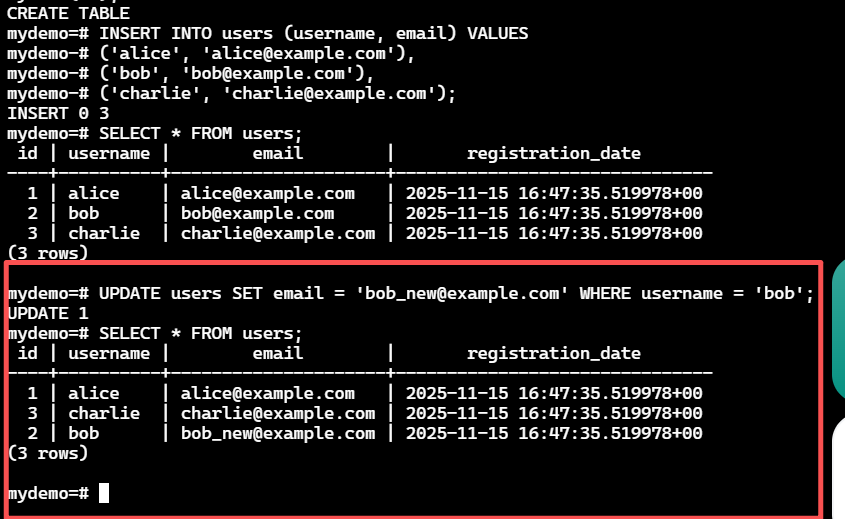 这张图展示了
这张图展示了UPDATE操作后再次查询的结果。可以看到,bob用户的email字段已经被成功更新,验证了UPDATE操作的正确性。
7. 删除 (Delete) 数据
删除charlie用户。
DELETE FROM users WHERE username="charlie";
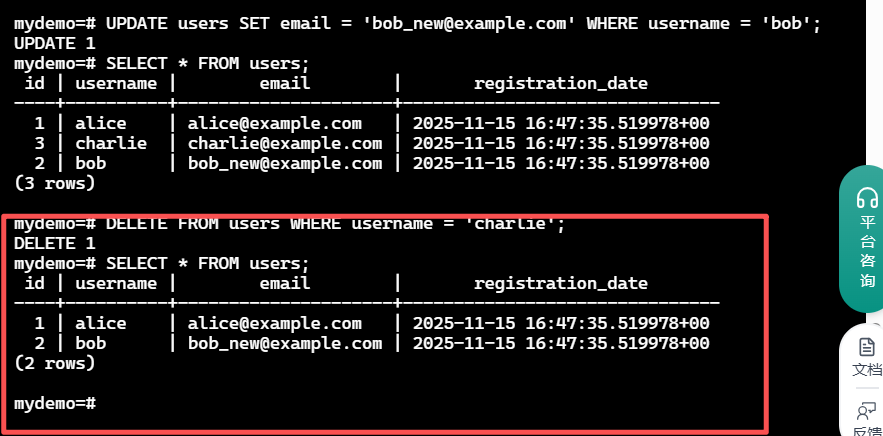 这张图是执行
这张图是执行DELETE操作后最终的查询结果。charlie用户的记录已经消失,表中只剩下两条记录,验证了DELETE操作的正确性。
在结束实操后,记得关闭云端资源,避免不必要的费用。 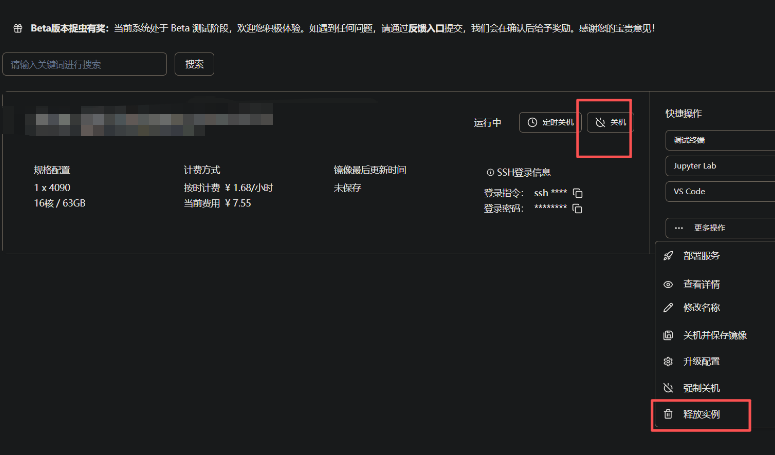 这张图提醒了在云平台进行实验后及时关机的重要性。
这张图提醒了在云平台进行实验后及时关机的重要性。
CRUD操作体验小结 : 在整个基础操作过程中,所有的SQL语法、psql客户端的交互方式,都与原生PostgreSQL完全一致。无论是CREATE DATABASE、CREATE TABLE,还是INSERT、SELECT、UPDATE、DELETE,都没有任何需要特殊学习或适应的地方。这完美地印证了OpenTeleDB的核心价值主张之一:学习成本几乎为零,现有的PostgreSQL技能和工具可以完全复用。
四、深度思考:哪一个特性最打动人心?
经过了从零到一的安装部署和基础的功能验证,是时候回归到那个核心问题了:”OpenTeleDB 的哪一个特性最打动我?具体为我提供了哪些便利?”
在体验之前,预期可能会被其HTAP架构下的某个具体技术亮点所吸引,比如它的列存引擎、MPP(大规模并行处理)查询执行器,或是其分布式事务的一致性模型。这些无疑都是OpenTeleDB作为一款HTAP数据库的技术基石,是其”强劲性能”的来源。
然而,在整个亲手实践的过程中,最令人印象深刻、最打动人的特性,并非某一个孤立的技术指标,而是 其HTAP核心能力与PostgreSQL成熟生态的战略性融合。
这并非一个单一的功能点,而是一个系统性的、架构层面的优势。它所带来的便利是多维度、深层次的,并且贯穿了从选型、开发、运维到最终业务价值实现的全过程。
具体来说,这种融合提供了以下几个关键的便利:
便利一:极低的迁移与学习成本,消除技术引入壁垒
这是在CRUD操作体验中最直观的感受。对于一个拥有PostgreSQL使用经验的开发者或DBA来说,上手OpenTeleDB几乎是”无感的”。 
- 熟悉的SQL方言:不需要学习新的、带有特定厂商烙印的SQL语法。所有符合ANSI SQL标准以及PostgreSQL扩展的SQL语句都可以直接运行。这意味着已有的应用代码,特别是数据访问层的代码,几乎不需要修改就可以迁移。
- 熟悉的工具链 :
psql命令行工具、pg_dump备份工具、pgAdmin图形化管理工具,以及数以万计的第三方数据库客户端(如DBeaver, DataGrip),都可以无缝连接和使用OpenTeleDB。这避免了为新数据库寻找、学习和适配全新工具集的痛苦过程。 - 熟悉的编程接口:所有主流编程语言(Java, Python, Go, Node.js, Rust等)的PostgreSQL数据库驱动程序(如JDBC, psycopg2, pgx)都可以直接用于连接OpenTeleDB。开发者无需更换或学习新的数据库驱动,保证了开发效率和代码的稳定性。
这种便利的现实意义是巨大的。它极大地降低了企业引入一项新技术(HTAP)的门槛和风险。团队不需要进行大规模的技能培训,项目也不需要承担因技术栈切换带来的不确定性。OpenTeleDB不是要求团队去适应一个全新的世界,而是将强大的HTAP能力,以一种极为友好的方式,”注入”到了团队已经熟悉的世界中。
便利二:简化的数据架构,释放实时数据价值
HTAP的核心价值在于简化架构。传统的”OLTP + ETL + OLAP”架构虽然解决了功能问题,但带来了新的问题: 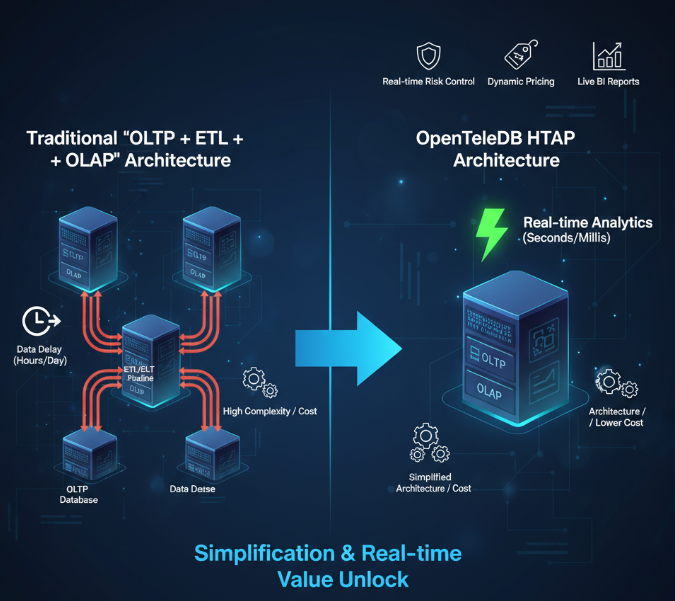
- 架构复杂:需要维护至少两套异构的数据库系统,以及一个ETL/ELT数据同步管道。每个组件都有其自身的运维复杂性。
- 数据延迟:ETL过程通常是周期性(如每小时或每天)执行的,这意味着分析系统看到的数据永远是”过去时”,无法基于最新鲜的交易数据进行决策。
- 成本高昂:硬件资源、软件许可(如果使用商业产品)以及人力维护成本都是双倍甚至多倍的。
OpenTeleDB通过其HTAP能力,直接将这种复杂架构”压平”为单一的数据库系统。
- 单一数据源:交易数据和分析数据存储在同一个系统中。这消除了数据冗余和不一致性的风险。
- 实时分析:分析查询可以直接在最新的交易数据上运行,将数据延迟从小时级、天级(T+1)降低到秒级甚至毫秒级。
- 运维简化:只需要维护一套数据库系统,大大降低了运维团队的工作负担和出错概率。
这种架构上的便利,直接转化为业务上的巨大价值。例如:
- 实时风控:在金融交易发生的同时,立即对其进行复杂的关联分析,判断是否存在欺诈风险。
- 动态定价:电商平台可以根据实时的用户浏览、加购行为和库存变化,动态调整商品价格。
- 实时BI报表:企业管理者可以随时查看反映当前业务状况的最新报表,而不是等待第二天的统计结果。
OpenTeleDB提供的便利,是让企业能够用更简单的架构、更低的成本,去解锁过去难以企及的实时数据分析能力。
便利三:丰富的生态扩展,拥有无限的可能性
与PostgreSQL的融合,还意味着OpenTeleDB继承了PostgreSQL最引以为傲的特性之一:无与伦比的扩展性。
PostgreSQL拥有一个庞大且活跃的扩展生态系统,涵盖了从地理空间数据处理(PostGIS)、时间序列数据(TimescaleDB)到全文搜索等各种功能。
虽然并非所有PostgreSQL扩展都能100%直接在分布式的OpenTeleDB上运行,但这种设计哲学和接口兼容性为其未来发展提供了巨大的想象空间。
- 功能继承:许多PostgreSQL的内置函数、高级特性(如窗口函数、CTE、JSONB支持)都被OpenTeleDB继承下来,开发者可以直接使用这些强大的工具进行复杂的数据处理。
- 社区智慧:当遇到问题时,可以从浩如烟海的PostgreSQL社区文档、博客、问答中寻求解决方案。绝大多数关于SQL优化、数据建模、连接管理的知识都同样适用于OpenTeleDB。
- 未来潜力:OpenTeleDB可以有选择地将其生态中受欢迎的、与分布式架构兼容的扩展进行适配和集成,从而快速丰富自身的功能集。
这种生态上的便利,让OpenTeleDB不是一个孤立的新产品,而是站在了一个”巨人”的肩膀上。它为用户提供的不仅仅是数据库本身,更是接入了一个经过数十年发展和沉淀的、充满活力的技术生态系统。
结论
本次从零到一的OpenTeleDB深度体验,是一次充满挑战与收获的旅程。从源码编译安装过程中解决的一个个”坑”,到最终在熟悉的psql界面中敲下流畅的SQL命令,每一步都加深了对这款产品的理解。
回到最终的问题,OpenTeleDB最打动人的特性,是它在技术创新和工程实用性之间取得的精妙平衡。它没有选择另起炉灶,创造一个全新的、孤立的体系,而是聪明地将前沿的HTAP分布式架构,与世界上最成熟、最受开发者喜爱的开源关系型数据库PostgreSQL进行了深度融合。
这种融合,就像是为一辆性能可靠、广受欢迎的经典汽车,换上了一颗蕴含未来科技的强劲引擎。驾驶者无需重新学习驾驶,就能享受到前所未有的速度与激情。
因此,最打动人的,正是这种 “熟悉之上的革新” 。它所提供的最大便利,就是让用户能够 以最低的成本、最小的风险,去拥抱数据处理领域的未来——实时、融合的HTAP架构,从而在激烈的市场竞争中,更快地洞察先机,创造价值。 OpenTeleDB的开源,无疑为广大追求数据驱动和架构简化的企业与开发者,提供了一个极具吸引力的新选择。
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


