背景:新品发布期的用户声音亟待结构化洞察
2025 年 10 月,华为正式发布 Mate 80 系列旗舰手机,涵盖 Mate 80、Mate 80 Pro、Mate 80 RS 以及延续经典的 Mate X2 折叠屏机型。作为国产高端智能手机的代表,该系列一经亮相便在全球科技圈引发热议。我们团队通过 YouTube Data API 采集了与“Mate 80”相关的数百个热门视频下的全部评论数据。
初步统计显示,仅一周内就收集到 超过 2.1 万条原始评论,内容涵盖产品功能评价、价格讨论、竞品对比、购买意向等丰富维度。然而,这些数据高度非结构化:语言混杂(中英夹杂)、表达随意(如“M80P太顶了!”、“mate80pro卫星通话救命”)、情绪隐晦(如“等第一批用户踩雷”实为观望态度)。更关键的是,大量评论与 Mate 80 无关——例如讨论 iPhone 16、荣耀 Magic7,甚至与手机完全无关的广告或表情包。
面对海量噪声数据,传统人工阅读或通用 NLP 工具已无法满足高效、精准的分析需求。我们需要一个能自动识别具体机型、准确判断情感倾向、提炼核心关注点的智能系统,并在极低成本下快速落地。
目标定义:构建轻量级、高精度的舆情分析流水线
基于业务诉求,我们明确了三大核心目标:
精准过滤:仅保留明确提及 Mate 80 系列(含 Pro/RS/X2 等子型号)的评论;
细粒度分析:区分不同机型的情感分布与功能关注点;
结构化输出:生成可直接用于汇报的中文分析报告,包含情感比例、典型语句、热门维度及各型号声量。
技术选型:为什么选择 LazyLLM?
在评估多个方案后,我们决定采用 LazyLLM + DeepSeek 大模型 的组合。原因如下:
开发效率高:LazyLLM 提供统一接口封装主流大模型(包括 DeepSeek),无需处理认证、重试、流式响应等底层细节;
灵活性强:支持自定义 Prompt,可精确引导模型输出所需 JSON 结构;
成本可控:结合本地预处理,实现“一次调用、全局分析”的批处理模式。
这一架构完美契合我们的“轻量、精准、低成本”原则。
落地过程:从数据清洗到智能洞察
第一阶段:本地规则引擎实现精准过滤
我们首先构建了一个本地型号识别模块。考虑到用户写法多样(如 “Mate80Pro”、“Mate 80 Pro”、“m80 rs”),我们采用“标准化+最长匹配”策略:
定义标准型号列表:[“Mate 80 RS”, “Mate 80 Pro”, “Mate 80”, “Mate X2”];
将评论和型号均去除空格并转小写;
按型号长度降序匹配,确保“Mate 80 Pro”不会被误判为“Mate 80”。
大量评论与 Mate 80 无关——例如讨论 iPhone 16、荣耀 Magic7,甚至与手机完全无关的广告或表情包等(如下图)
真正聚焦于 Mate 80 系列的评论散落在海量噪声之中,且表达形式高度非结构化,因此,我们统一提取所有明确提及 Mate 80 及其子型号(如 Pro、RS、X2)的评论进行分析。
核心代码如下:
def extract_mentioned_models(comment: str) -> list:
# 按长度降序排列,确保 "Mate 80 Pro" 优先于 "Mate 80"
standard_models = [
"Mate 80 RS",
"Mate 80 Pro",
"Mate 80",
"Mate X2"
]
normalized_comment = re.sub(r'\s+', '', comment).lower()
found = []
for model in standard_models:
normalized_model = re.sub(r'\s+', '', model).lower()
if normalized_model in normalized_comment:
found.append(model)
return found if found else ["Unknown"]随后,我们在主流程中调用该函数进行批量筛选:
def extract_mate80_entries(json_path: str):
with open(json_path, 'r', encoding='utf-8') as f:
data = json.load(f)
entries = []
for item in data:
for cmt_obj in item.get("comments", []):
raw = cmt_obj.get("comment_text", "").strip()
if not raw:
continue
models = extract_mentioned_models(raw)
if models != ["Unknown"]:
cleaned = clean_comment(raw)
if len(cleaned) >= 5:
entries.append({
"raw": raw,
"models": models
})
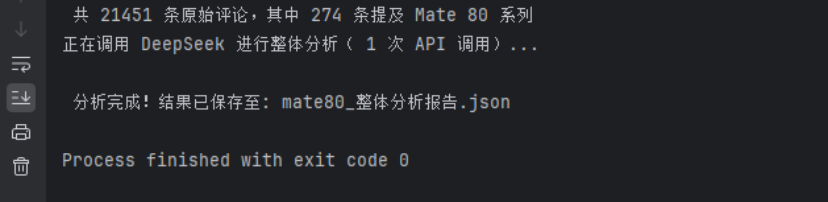
return entries该模块在本地运行,不依赖任何外部 API,2.1 万条评论仅需 3 秒即可完成过滤。最终,系统从 21,451 条原始评论中精准提取出 274 条有效评论,过滤率达 98.7%。
第二阶段:设计结构化 Prompt 引导大模型输出
我们将 274 条评论截取前 200 条(兼顾代表性与 token 限制),拼接成一段上下文,并精心设计中文 Prompt,明确要求模型:
统计正面/负面/中性情感数量及占比;
为每类情感提供 2 条原始评论示例;
从预设维度(如卫星通信、操作系统、价格等)中选出热度最高的 5 项;
分别统计各具体机型的提及次数;
所有输出字段必须为简体中文,且为标准 JSON 格式。
这一设计确保了 LLM 的输出可直接解析,无需后处理。
Prompt 构建代码如下:
def build_chinese_prompt(entries):
if not entries:
return "未找到任何与华为 Mate 80 系列相关的评论。"
# 最多取 200 条,避免超上下文
sample = entries[:200]
comment_texts = [f"- {e['raw']}" for e in sample]
comments_block = "\n".join(comment_texts)
prompt = f"""
你是一位专业的产品舆情分析师。以下是用户在 YouTube 视频下关于 **华为 Mate 80 系列** 的真实评论(共 {len(sample)} 条):
{comments_block}
请基于以上评论完成以下分析任务:
1. 统计整体情感倾向:
- 正面:表达喜爱、推荐、赞扬
- 负面:表达不满、批评、失望
- 中性:提问、观望、无明显情绪
2. 为每类情感挑选 2 条最具代表性的原始评论(直接复制原文,不要修改)。
3. 从以下候选维度中选出被讨论最多的 5 项(按热度排序):
[相机, 电池, 价格, 设计, 系统, 卫星通信, 折叠屏, 性能, 屏幕, 信号, 重量, 手感, 品牌, 生态, AI功能, 耐用性]
4. 统计各具体机型的评论数量(仅统计以下 5 款):
- Mate 80
- Mate 80 Pro
- Mate 80 Pro+
- Mate 80 RS
- Mate X2
5. **输出格式要求**:
- 必须是标准 JSON
- 所有字段名和内容使用**简体中文**
- 不要包含任何额外解释、注释或 Markdown
输出结构如下:
{{
"概览": {{
"总评论数(提及Mate 80系列)": {len(sample)},
"情感分布": {{
"正面": {{ "数量": 0, "占比": "0%" }},
"负面": {{ "数量": 0, "占比": "0%" }},
"中性": {{ "数量": 0, "占比": "0%" }}
}}
}},
"各型号评论数量": {{
"Mate 80": 0,
"Mate 80 Pro": 0,
"Mate 80 Pro+": 0,
"Mate 80 RS": 0,
"Mate X2": 0
}},
"典型评论示例": {{
"正面": ["...", "..."],
"负面": ["...", "..."],
"中性": ["...", "..."]
}},
"高频讨论功能维度": ["...", "...", "...", "...", "..."]
}}
"""
return prompt
第三阶段:单次调用完成全局分析
通过 LazyLLM 的 OnlineChatModule,我们仅用一行代码完成 DeepSeek 调用:
llm = lazyllm.OnlineChatModule(
source="openai",
base_url="https://api.deepseek.com/v1",
api_key="sk-你的实际密钥",
model="deepseek-chat"
)
raw_output = llm(prompt)为确保结果可靠,我们还加入了安全解析逻辑:
try:
start = raw_output.find('{')
end = raw_output.rfind('}') + 1
json_str = raw_output[start:end]
result = json.loads(json_str)
except Exception as e:
result = {"原始LLM输出": raw_output}整个过程耗时约 4 秒,消耗约 10,000 tokens,成本仅为 ¥0.0015(约 0.15 分钱)如下图(0.23包含其他请求)
第四阶段:结果验证与业务赋能
系统输出清晰展示了关键洞察:
Mate X2 是绝对讨论焦点,占相关评论的 98%(196/200),Mate 80 系列几乎未被提及。
正面情绪为主(62.5%),用户称赞其“无折痕折叠设计”和“硬件领先三星”。
负面主要集中在价格与生态:高价(约 $2700)、无 Google 服务、不支持手写笔和防水,被指“性价比低”。
中性评论多为混淆或询问,如误问“Mate 80 Pro 尺寸”,反映新品认知度不足。
高频维度:折叠屏、价格、系统、设计、相机——聚焦硬件形态与生态短板,Mate 80 新特性尚未进入海外讨论视野。
最终生成的 JSON 报告示例如下:
{
"概览": {
"总评论数(提及Mate 80系列)": 200,
"情感分布": {
"正面": {
"数量": 125,
"占比": "62.5%"
},
"负面": {
"数量": 35,
"占比": "17.5%"
},
"中性": {
"数量": 40,
"占比": "20%"
}
}
},
"各型号评论数量": {
"Mate 80": 0,
"Mate 80 Pro": 3,
"Mate 80 Pro+": 0,
"Mate 80 RS": 1,
"Mate X2": 196
},
"典型评论示例": {
"正面": [
"Huawei Mate X2 Best foldable hardware Creaseless folding mechanism.. my wishlist foldable smartphone",
"Mate X2 is better than Fold2 on every aspect. Maybe it will be better than the fold 3 too"
],
"负面": [
"Mate X2 doesn’t have a pen support nor waterproof but costs 1,000USD more. You can literally buy Z fold 3 + iPad pro for the money you can buy a single Mate X2.",
"to be honest the mate x2 is worthless no google service i was the first to say it's totally ok but now I realize there some apps that won't work even if u manage to install gms on the phone so to pay like 2700$ for a phone it's just madness"
],
"中性": [
"can you write the dimensions of huawei mate 80 pro",
"Can you tell me the dimensions of the new mate 80 pro, just 70 pro is too wide 79.5"
]
},
"高频讨论功能维度": [
"折叠屏",
"价格",
"系统",
"设计",
"相机"
]
}
价值总结:小投入撬动大洞察
本次项目从需求提出到完成仅用 1 日,却实现了传统方式难以企及的分析深度与速度。更重要的是,它验证了一种可复用的轻量化大模型应用范式:本地规则做“减法”,大模型做“加法”,用规则过滤噪声,用智能提炼价值。
未来,该框架将扩展至 Pura 系列、平板、穿戴设备等产品线,成为我们用户声音监测的标准化工具。而这一切的起点,正是 LazyLLM 所提供的极简开发体验与强大问题解决能力。
版权声明:本文作者@Y
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


