在前面的课程中,我们利用所学的 RAG 知识,搭建了一个基于论文的问答系统。但是当论文数量比较多时,针对一些统计信息,比如某个方向的论文数量、某个会议的论文数量等,如果只通过传统的 RAG 是没办法对这些信息进行检索的。
对此,本章将先简单回顾之前内容,并在此基础上再做升级,完成一个集统计分析和知识问答功能于一体的智能问答系统。
一、上节回顾
为了更好地理解本章内容,我们先简要回顾前两章的关键内容。
第14讲介绍了论文问答系统的构建过程,依次讲解了核心组件,如解析器、retriever、reranker 等,并展示了如何逐步搭建一个完整的 RAG 系统。同时,我们也探讨了一些进阶技巧,以提升系统的性能与灵活性。
不过,这一系统仍属于传统 RAG 架构。在第15讲中,我们进一步指出了传统 RAG 在处理统计类问题时的局限性,并提出了应对思路,如结合 SQL 数据库、Text2SQL 技术及 sql_tool 工具。然而,前章仅提出了理论方案,尚未给出完整的实践示例。
因此,本章将在此基础上,结合实际案例,构建一个更完整、 更具实用性的统计问答系统,进一步拓展 RAG 在结构化数据处理方面的能力。
二、本节概览
在本讲中,我们将在已有的论文问答系统基础上进一步拓展其功能,使系统不仅能够进行知识问答,还具备处理统计分析任务的能力。为此,我们需要对传统的 RAG 架构进行调整,增强其在统计场景下的适应性。
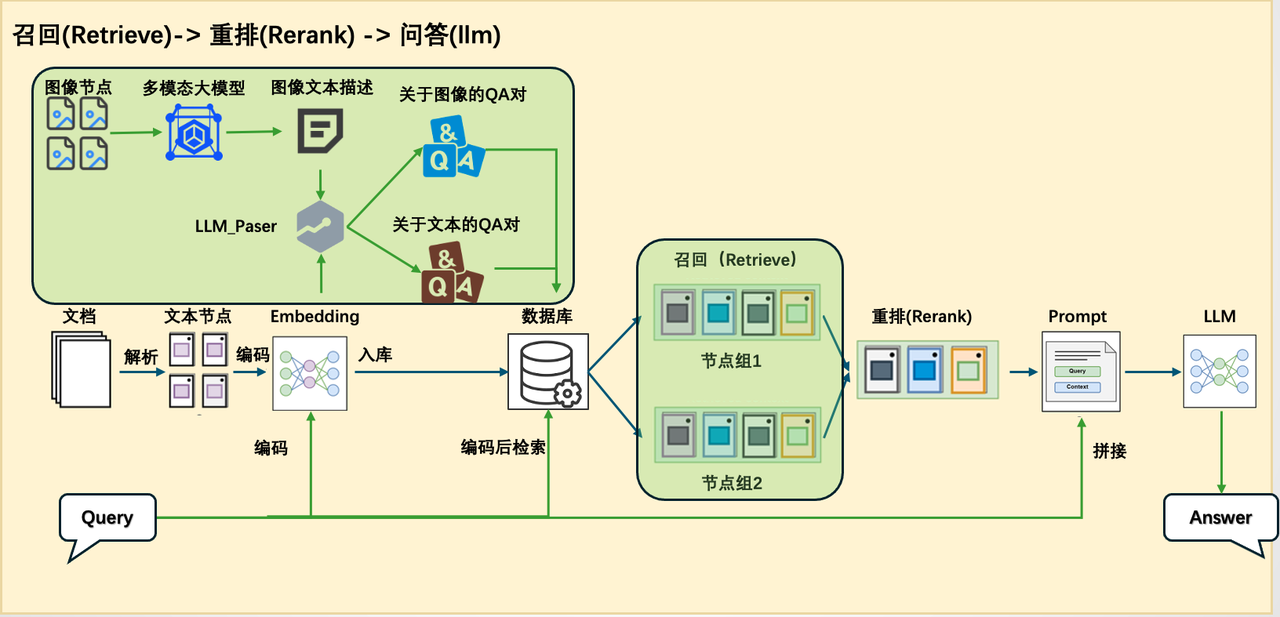
由于知识问答与统计问答在处理逻辑和所依赖的信息类型上存在显著差异,采用统一的 pipeline 来应对两种需求在实践中存在较大困难。因此,我们在原有 RAG pipeline 的基础上新增了一条专门处理统计任务的 pipeline,实现从【图1】到【图2】的系统结构变化。
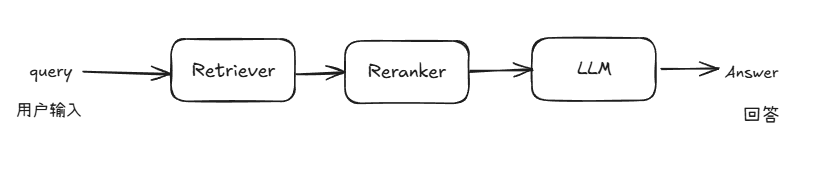
图1 原论文系统架构图
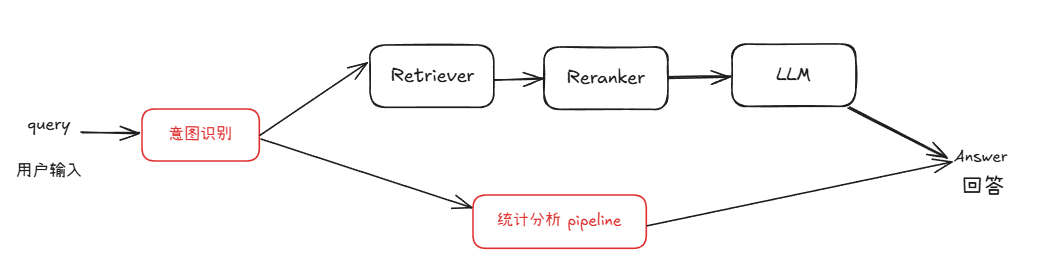
图2 具备统计能力的问答系统架构图
在复用现有模块的基础上,我们新增了用于数据库查询、统计分析和图表生成的统计分析 pipeline。该 pipeline 与 RAG pipeline 并行运行,并通过一个意图识别模块进行统一调度。该模块负责判断用户查询属于知识问答还是统计分析,从而引导请求进入合适的处理流程。
为实现这一增强系统,我们还需要引入若干关键的技术模块。接下来将在完成数据准备后逐一介绍这些新增模块及其在系统中的作用。
三、数据准备
这里我们以 ArXivQA(https://github.com/taesiri/ArXivQA)数据集为例,从 Papers-2024.md 中抽取了前面100篇来演示,在执行代码之前您需要先下载Papers-2024.md,可以离线下载或者以下命令进行下载。该文件包含了论文信息和下载链接。
wget https://raw.githubusercontent.com/taesiri/ArXivQA/main/Papers-2024.md -O 2024.md
我们需要从两方面去准备数据:
-
知识库(下载论文文件到指定目录下) ,用于知识问答;
-
数据库(构建论文信息的表格存入本地数据库),用于统计问答,论文信息如title、author等。
以下脚本可以同时实现将论文下载到指定文件夹同时构建论文信息的数据库。
(代码块GitHub链接🔗:https://github.com/LazyAGI/Tutorial/blob/7abc91dbb82a007a78731845dd8c360ac0cc1e75/rag/codes/chapter16/CreateDataBase.py#L1)
import re
import requests
import time
import json
from tqdm import tqdm
from bs4 import BeautifulSoup
# 下载文件的函数
def spider(url, save_dir="./rag_data/papers"):
response = requests.get(url)
# 检查请求是否成功
res = {}
if response.status_code == 200:
# 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
elements = soup.find_all(class_='title mathjax')
for ele in elements:
res['title'] = ele.get_text().replace("Title:", '')
elements = soup.find_all(class_='authors')
authors = []
for ele in elements:
links = ele.find_all('a')
for link in links:
authors.append(link.get_text())
res['author'] = ';'.join(authors)
elements = soup.find_all(class_='tablecell subjects')
for ele in elements:
res['subject'] = ele.get_text()
# 保存论文
file_path = os.path.join(save_dir, res['title'] + '.pdf')
with open(file_path, 'wb') as f:
f.write(response.content)
print(f"已保存 PDF 到 {file_path}")
return res
else:
print(f"网页加载失败,状态码:{response.status_code}")
def get_information():
with open('2024.md')as f:
texts = f.readlines()[2:102]
reses = []
for text in tqdm(texts):
abs_url = re.findall(r'\[.*?\]\((https?://arxiv.*?)\)', text)
if len(abs_url) > 0:
res = spider(abs_url[0])
reses.append(res)
time.sleep(5)
with open('test.txt', 'w')as f:
json.dump({"data": reses}, f)
上面这是一个获取文档信息脚本,负责解析 2024.md 中的数据,并取100篇为例,然后解析对应的 url ,然后通过获取每个 url 对应的论文标题、作者和主题的信息,并记录下来。
(代码块GitHub链接🔗:https://github.com/LazyAGI/Tutorial/blob/7abc91dbb82a007a78731845dd8c360ac0cc1e75/rag/codes/chapter16/CreateDataBase.py#L52)
import sqlite3
import json
def write_into_table():
with open('test.txt', 'r')as f:
data = json.load(f)
data = data['data']
# 连接到 SQLite 数据库(如果数据库不存在,它会被创建)
conn = sqlite3.connect('papers.db')
cursor = conn.cursor()
# 创建表格
cursor.execute('''
CREATE TABLE IF NOT EXISTS papers (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT,
author TEXT,
subject TEXT
)
''')
# 插入数据
for paper in data:
cursor.execute('''
INSERT INTO papers (title, author, subject)
VALUES (?, ?, ?)
''', (paper['title'], paper['author'], paper['subject']))
# 提交并关闭连接
conn.commit()
conn.close()
上面的代码是根据获取的信息,创建对应的数据库信息,并把记录信息写入,用于 SQL Call 的查询。
现在完成数据准备,我们得到了固定目录下已经下载好的论文:

以及数据库文件papers.db 。
四、依赖模块详解
为了构建支持统计分析的问答系统,我们需要掌握几个核心模块的原理和实现方式,分别包括意图识别、SQL 调用、统计分析及图表生成。
(一)意图识别
首先是意图识别模块。该模块的主要职责是分析用户的输入内容,判断其意图属于传统的知识问答,还是涉及到结构化数据处理的统计问答。
LazyLLM内置了用于对意图进行分析的 IntentClassifier 类,具体介绍如下:
IntentClassifier是一个基于语言模型的意图识别器,用于根据用户提供的输入文本及对话上下文识别预定义的意图,并通过预处理和后处理步骤确保准确识别意图。
对于 IntentClassifier ,我们提供了以下参数:
llm: 用于意图识别的语言模型对象,OnlineChatModule或TrainableModule类型
intent_list (list): 包含所有可能意图的字符串列表。可以包含中文或英文的意图。
prompt (str): 用户附加的提示词。
constrain (str): 用户附加的限制。
examples (list[list]): 额外的示例,格式为 [[query, intent], [query, intent], …]。
return_trace (bool, 可选): 如果设置为 True,则将结果记录在trace中。默认为 False。
ch_prompt_classifier_template = """
## role:意图分类器
你是一个意图分类引擎,负责根据对话信息分析用户输入文本并确定唯一的意图类别。{user_prompt}
## 限制:
你只需要回复意图的名字即可,不要额外输出其他字段,也不要进行翻译。{user_constrains}
## 注意:
{attention}
## 文本格式
输入文本为JSON格式,"human_input"中内容为用户的原始输入,"intent_list"为所有意图名列表
## 示例
User: {{"human_input": "北京明天天气怎么样?", "intent_list": ["查看天气", "搜索引擎检索", "查看监控", "周报总结", "聊天"]}}
Assistant: 查看天气
{user_examples}
## 历史对话
人类和助手之间的聊天记录存储在下面的 <histories></histories> XML 标记中。
<histories>
{history_info}
</histories>
输入文本如下:
""" # noqa E501
在 IntentClassifier 内,内置了如上所示的模板,用于将上述参数传入给大模型。IntentClassifier 的调用非常简单,下面就是两个完整调用的例子:
(代码块GitHub链接🔗:https://github.com/LazyAGI/Tutorial/blob/7abc91dbb82a007a78731845dd8c360ac0cc1e75/rag/codes/chapter16/intent_classifier.py#L1)
import lazyllm
from lazyllm.tools import IntentClassifier
classifier_llm = lazyllm.OnlineChatModule()
chatflow_intent_list = ["翻译服务", "天气查询", "内容推荐", "金融行情查询"]
classifier = IntentClassifier(classifier_llm, intent_list=chatflow_intent_list)
while True:
query = input("输入您的问题:\n")
print(f"\n识别到的意图是:\n {classifier(query)}\n" + "-"*40)
# 今天天气怎么样 ➔ 天气查询
# A股行情怎么样 ➔ 金融行情查询
# 给我推荐一部科幻电影 ➔ 内容推荐
# 帮我把这边论文译为中文 ➔ 翻译服务
1.意图识别-高级用法
通过with语法,使得意图识别模块能够直接跟随具体的指令。
base = TrainableModule('internlm2-chat-7b')
with IntentClassifier(base) as ic:
ic.case['聊天', base]
ic.case['语⾳识别', TrainableModule('SenseVoiceSmall')]
ic.case['图⽚问答', TrainableModule('Mini-InternVL-Chat-2B-V1-5').deploy_method(deploy.LMDeploy)]
ic.case['画图', pipeline(base.share().prompt(painter_prompt),
TrainableModule('stable-diffusion-3-medium'))]
ic.case['⽣成⾳乐', pipeline(base.share().prompt(musician_prompt), TrainableModule('musicgen-small'))]
ic.case['⽂字转语⾳', TrainableModule('ChatTTS')]
WebModule(ic, history=[base], audio=True, port=8847).start().wait()
使用方式有case[a, b],case[a: b]和case[a::b]三种,可以根据个人习惯选择使用三者无区别:
with IntentClassifier(base) as ic:
ic.case['聊天', base]
ic.case['语⾳识别': TrainableModule('SenseVoiceSmall')]
ic.case['图⽚问答'::TrainableModule('Mini-InternVL-Chat-2B-V1-5').deploy_method(deploy.LMDeploy)]
(二)Sql Manager
接下来,我们解决统计问答流程中的第一环节:数据库查询与数据获取。
在之前的学习内容中,虽然我们以 SQLite 为例讲解了数据库的基本使用流程,但在真实的生产环境里,使用的数据库种类远不止 SQLite。
常见的关系型数据库还包括 MySQL、PostgreSQL、SQL Server、Oracle 等,而在云端,诸如阿里云 RDS、腾讯云 CynosDB、AWS RDS 这样的数据库服务也被广泛使用。
为了方便地连接和操作不同类型的数据库,我们可以使用 Python 中非常流行的 ORM 框架——SQLAlchemy。
SQLAlchemy 提供了统一的数据库操作接口,不仅支持本地数据库,也支持各种主流云数据库,极大地提升了数据库交互的灵活性和可扩展性。
以下为通过SQLAlchemy连接本地和远程数据库的代码。
from sqlalchemy import create_engine
# 创建 SQLite 本地数据库连接
engine = create_engine('sqlite:///local_database.db')
# 创建远程 MySQL 数据库连接
# 格式:mysql+pymysql://用户名:密码@服务器地址:端口/数据库名
engine = create_engine('mysql+pymysql://user:password@host:3306/database_name')
# 测试连接
with engine.connect() as connection:
result = connection.execute("SELECT 1")
print(result.fetchone())
在 lazyllm 框架中,也对这一功能进行了封装,提供了内置的 SQLManager 模块。通过 SQLManager,用户可以非常简单地连接本地或云上的数据库,统一调用 SQL 查询、执行 SQL-call 相关操作,无需关心底层连接的复杂细节。只需在配置中指定数据库地址、账号密码等信息,就可以一键启动数据库交互能力,为后续的结构化问答打下坚实基础。
(代码块GitHub链接🔗:https://github.com/LazyAGI/Tutorial/blob/7abc91dbb82a007a78731845dd8c360ac0cc1e75/rag/codes/chapter16/sql_manager.py#L1)
from lazyllm.tools import SqlManager
# 连接本地数据库
sql_manager = SqlManager("sqlite", None, None, None, None, db_name="papers.db", tables_info_dict=table_info)
# 连接远程数据库
# sql_manager = SqlManager(type="PostgreSQL", user="", password="", host="",port="", name="",)
# 查询所有论文数量
res = sql_manager.execute_query("select count(*) as total_papser from papers;")
>>> [{"total_papser": 100}]
# 查询带有 LLM 的论文标题
res = sql_manager.execute_query("select title from papers where title like '%LLM%'")
>>> [{"title": "AmpleGCG: Learning a Universal and Transferable Generative Model of Adversarial Suffixes for Jailbreaking Both Open and Closed LLMs"}, {"title": "Learning to Localize Objects Improves Spatial Reasoning in Visual-LLMs"}, {"title": "LLMs in Biomedicine: A study on clinical Named Entity Recognition"}, {"title": "VLLMs Provide Better Context for Emotion Understanding Through Common Sense Reasoning"}]
注意,db_name 参数需要传入构建好的数据库文件路径,tables_info_dict 参数需传入数据库基本信息字典(表名、列名等),我们以论文数据库为例,基本信息的定义如下。
table_info = {
"tables": [{
"name": "papers",
"comment": "论文数据",
"columns": [
{
"name": "id",
"data_type": "Integer",
"comment": "序号",
"is_primary_key": True,
},
{"name": "title", "data_type": "String", "comment": "标题"},
{"name": "author", "data_type": "String", "comment": "作者"},
{"name": "subject", "data_type": "String", "comment": "领域"},
],
}]
}
(三)Sql Call
SQL Call 模块依赖于Sql Manager,它能够根据用户问题生成符合语义意图的 SQL 查询语句,并对接后端数据库获取原始数据。这一模块不仅是统计分析的入口,也是确保结果准确性的关键。
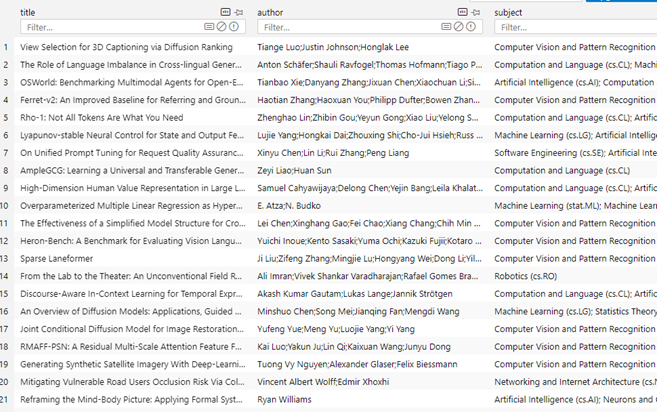
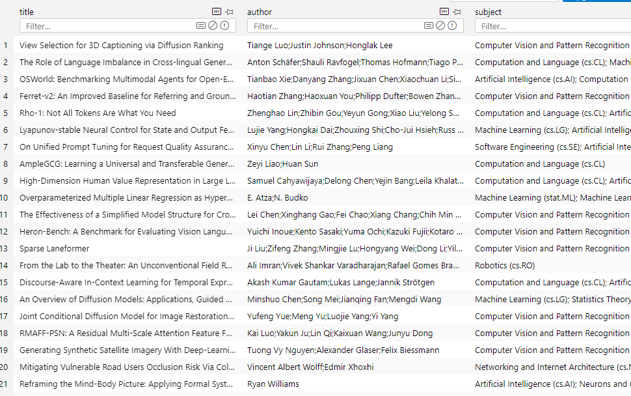
我们先来看一下数据准备阶段我们已经构建的数据库文件 papers.db 的内容,该库中只有一张表,包含文章的title、author 和 subject 信息:
接下来开始定义 sql call:
-
通过指定数据库名称和数据表信息创建 sql_manager,同时实例化一个大模型用于实现text2sql。
-
将二者传入以构建一个 SQL Call 工作流
该工作流支持将自然语言查询转化为 SQL 语句并执行查询,最终返回结果。
(代码块GitHub链接🔗:https://github.com/LazyAGI/Tutorial/blob/7abc91dbb82a007a78731845dd8c360ac0cc1e75/rag/codes/chapter16/sql_call.py#L1)
from lazyllm.tools import SqlManager, SqlCall
sql_manager = SqlManager("sqlite", None, None, None, None, db_name="papers.db", tables_info_dict=table_info)
sql_llm = lazyllm.OnlineChatModule()
sql_call = SqlCall(sql_llm, sql_manager,
use_llm_for_sql_result=False)
query = "库中一共多少篇文章"
print(sql_call(query))
>>> [{"total_papers": 200}]
while True:
query = input("请输入您的问题:")
print("answer:")
print(sql_call(query))
# 库中一共多少篇论文
# 库中最多的三个subject是什么
# 查询数据库并返回 subject 包含Computer Vision的论文题目的结果
(四)统计分析agent
获取数据的问题解决后,我们将进入统计分析的核心流程。本模块基于sql call实现整条统计分析pipeline,可以看作一个面向统计任务的智能agent,能够根据用户问题自动完成 数据库查询 → 数据分析 → 图表生成 → 结果汇总 的完整闭环流程。为用户提供图文并茂的答案。
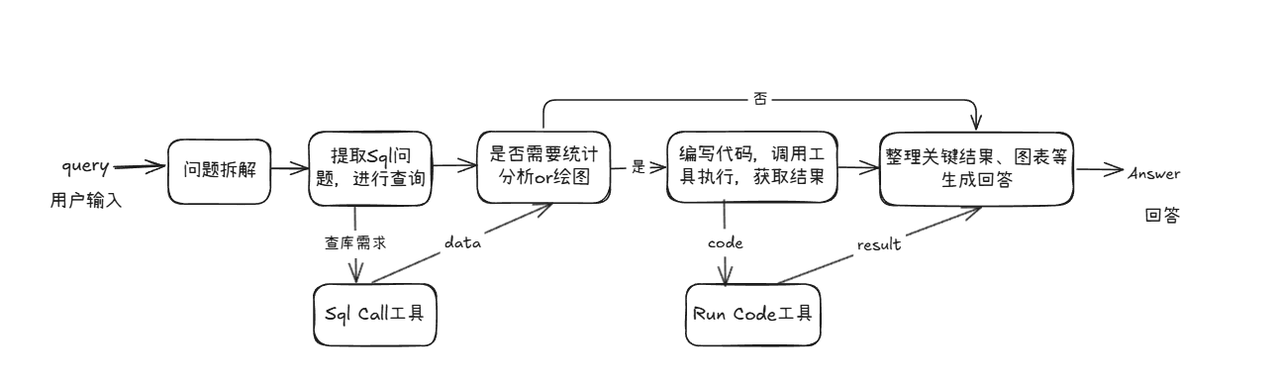
1. 代码编写
我们首先定义两个工具(Tool),分别用于 SQL 查询 和 代码执行,并将它们作为可选工具提供给 Agent,支持其在执行任务过程中完成数据库查询和统计分析。
-
run_sql_query 方法基于上一节构建的 SQL Call 工作流封装而成,Agent 可在从用户查询中解析出 SQL 相关需求后调用该方法,获取结构化查询结果。
-
run_code 方法用于接收并执行大模型生成的统计分析代码。该方法会返回关键结果或报错信息,为大模型下一步的决策和行动提供反馈依据。
这两个工具配合使用,使 Agent 能够动态完成从数据获取到分析执行的全流程任务。
@fc_register("tool")
def run_sql_query(query):
"""
Automatically generates and executes an SQL query based on a natural language request.
Given a natural language query describing a data retrieval task, this function generates the corresponding SQL
statement, executes it against the database, and returns the result.
Args:
query (str): A natural language description of the desired database query.
Returns:
list[dict]: A list of records returned from the SQL query, where each record is represented as a dictionary.
"""
sql_manager = SqlManager("sqlite", None, None, None, None, db_name="papers.db", tables_info_dict=table_info)
sql_llm = lazyllm.OnlineChatModule(source="sensenova")
sql_call = SqlCall(sql_llm, sql_manager, use_llm_for_sql_result=False)
return sql_call(query)
@fc_register("tool")
def run_code(code: str):
"""
Run the given code in a separate thread and return the result.
Args:
code (str): code to run.
Returns:
dict: {
"text": str,
"error": str or None,
}
"""
result = {
"text": "",
"error": None,
}
def code_thread():
nonlocal result
stdout = io.StringIO()
try:
with contextlib.redirect_stdout(stdout):
exec_globals = {}
exec(code, exec_globals)
except Exception:
result["error"] = traceback.format_exc()
result["text"] = stdout.getvalue()
thread = threading.Thread(target=code_thread)
thread.start()
thread.join(timeout=10)
if thread.is_alive():
result["error"] = "Execution timed out."
thread.join()
return result
注意!在撰写函数时,一定要在函数下方加上注释,格式如下:
def myfunction(arg1: str, arg2: Dict[str, Any], arg3: Literal["aaa", "bbb", "ccc"]="aaa"):
'''
Function description ...
Args:
arg1 (str): arg1 description.
arg2 (Dict[str, Any]): arg2 description
arg3 (Literal["aaa", "bbb", "ccc"]): arg3 description
'''
在大模型调用该函数时,将通过函数的描述,以及参数的表述,决定何时调用以及传入参数。
接下来我们实现agent定义,这里我们使用lazyllm内置的ReactAgent工具,将前文中定义的两个工具传入tools参数,即可实现模型自动调用。
ReactAgent是按照 Thought->Action->Observation->Thought…->Finish 的流程,一步一步的通过LLM和工具调用来显示解决用户问题的步骤,最后输出最终答案。
from lazyllm.tools.agent import ReactAgent
agent = ReactAgent(
llm=lazyllm.OnlineChatModule(stream=False),
tools=['run_code', 'run_sql_query'],
return_trace=True,
max_retries=3,
)
然后基于上述agent,我们定义prompt,并搭建支持统计问题的sql问答流程:
sql_prompt = """
你是一位资深数据科学家,需要基于给定的问题进行必要的统计分析和绘图,来回答用户提出的统计问题。
你的工作流程如下:
1. 理解问题并进行数据查询
- 拆解问题中需要查询数据库的部分,调用相应工具进行数据获取。
2. 判断根据数据是否可直接得出统计问题的答案
- 如果数据可以直接回答统计问题,则直接输出结果,必要时补充绘制图表。
- 如果不足以回答,则先进行必要的数据分析,再根据需要绘制图表。
3. 通过编写代码并执行并获取结果的方式实现数据分析和绘图
- 编写完整可执行的 Python 代码,包含所有必要的 import、数据加载、分析逻辑、绘图代码、结果输出。
- 使用常见数据科学工具包(如 pandas、numpy、scikit-learn 等)进行数据分析。
- 使用可视化工具(如 matplotlib、seaborn)进行图表绘制。
4. 图像保存
- 所有生成的图像必须保存到以下路径:
{image_path}
- 保存成功后,使用以下格式将图片展示在最终回答中(Answer部分)(image_name为保存的文件名,image_path为完整路径):

5. 错误处理
- 如果代码执行失败,请根据报错信息自动修改代码并重新执行,直到成功。
问题:
{query}
"""
with pipeline() as sql_ppl:
sql_ppl.formarter = lambda query: sql_prompt.format(query=query, image_path=IMAGE_PATH)
sql_ppl.agent = ReactAgent(
llm=lazyllm.OnlineChatModule(stream=False),
tools=['run_code', 'run_sql_query'],
return_trace=True,
max_retries=3,
)
sql_ppl.clean_output = lazyllm.ifs(lambda x: "Answer:" in x, lambda x: x.split("Answer:")[-1], lambda x:x)
if __name__ == '__main__':
lazyllm.WebModule(sql_ppl, port=23456, static_paths=image_save_path).start().wait()
五、构建支持统计分析的论文问答系统
在掌握了系统所依赖的各项关键技术之后,我们便可以开始动手构建一个实际可用的系统,以支持统计分析与知识问答的融合能力。
整个系统的架构如下:

代码实现
我们来看怎么利用上文已经给出的结构搭建完整的多功能问答工作流。整体思路如下:
我们首先分别定义两个子工作流:
-
chat_ppl:用于处理基于 RAG(Retrieval-Augmented Generation)的通用问答任务;
-
sql_ppl:用于处理与统计分析相关的 SQL 问答任务。
随后,在主工作流中引入一个意图识别模块,用于解析用户的查询意图,并据此在 chat_ppl 与 sql_ppl 两条子工作流中选择适合的路径进行处理。通过这样的结构设计,系统能够根据用户问题的类型自动匹配合适的工作流,实现对自然语言问答和统计分析任务的统一调度与处理。
注意,在第9、10行,我们通过模块导入的方式导入在第14讲介绍的rag pipeline(build_paper_rag())和上文定义的 sql pipeline(build_statistical_agent()),在此不在重复编码。
import lazyllm
from lazyllm import OnlineChatModule, pipeline, _0
from lazyllm.tools import IntentClassifier
from statistical_agent import build_statistical_agent
from paper_rag import build_paper_rag
# 构建 rag 工作流和统计分析工作流
rag_ppl = build_paper_rag()
sql_ppl = build_statistical_agent()
# 搭建具备知识问答和统计问答能力的主工作流
def build_paper_assistant():
llm = OnlineChatModule(source="qwen", stream=False)
intent_list = [
"论文问答",
"统计问答",
]
with pipeline() as ppl:
ppl.classifier = IntentClassifier(llm, intent_list=intent_list)
with lazyllm.switch(judge_on_full_input=False).bind(_0, ppl.input) as ppl.sw:
ppl.sw.case[intent_list[0], rag_ppl]
ppl.sw.case[intent_list[1], sql_ppl]
return ppl
if __name__ == "__main__":
main_ppl = build_paper_assistant()
lazyllm.WebModule(main_ppl, port=23459, static_paths="./images").start().wait()
然后我们就可以启动这个工作流了。我们使用WebModule来启动服务,通过 WebModule 把上面定义的工作流创建成一个 web 服务,这里需要注意,启动 WebModule 时,需要传入图片的保存路径,这样就可以把该目录设置为静态目录,gradio 就可以直接访问该目录下的图片文件了。
当 web 服务启动成功后,则根据启动后的 ip 和 port,我们就可以在浏览器中体验使用了。
(一)简单统计问题(不需要画图)

处理流程分析:
-
用户输入query “库中一共有多少篇论文“
-
大模型提取数据查询问题”库中一共多少篇论文” 调用SqlCall:
input:
"库中一共多少篇论文"
text2sql:
select count(*) as total_papser from papers;
output:
[{"total_papers": 100}]
3. 模型判断该结果已经可以回答query的问题,直接输出回答”库中一共有100篇论文“。
【附:执行日志】

(二)简单统计问题(需要画图)

处理流程分析:
1. 用户输入query “根据数据库里的数据,告诉我最多的三个subject是什么,并绘制柱状图“
2. 大模型将对传入的query进行分析,判定需要调用run_sql_query工具获取数据,其会调用lazyllm内置的Sql调度工具SqlCall,它可以自动执行相应的sql查询语句,从数据库中获得相应的结果,结果如下。
input:
"找出数据库中数量最多的三个subject及其数量"
text2sql:
select subject, count(*) as count
from papsers
group by count desc
limit 3;
output:
[{"subject": "\nComputer Vision and Pattern Recognition (cs.CV)", "count": 25}, {"subject": "\nRobotics (cs.RO)", "count": 6}, {"subject": "\nComputation and Language (cs.CL)", "count": 5}]
3. 模型判断该结果已经可以回答query的问题,不需要进一步进行统计分析,但是query中包含作图需求,因此其编写仅用于作图的python代码并调用run_code工具执行,以下为大模型编写的代码。
import matplotlib.pyplot as plt
import numpy as np
# 数据
labels = ['Computer Vision and Pattern Recognition (cs.CV)', 'Robotics (cs.RO)', 'Computation and Language (cs.CL)']
counts = [25, 6, 5]
# 创建柱状图
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots()
rects = ax.bar(x, counts, width)
# 添加标签、标题和刻度
ax.set_ylabel('Count')
ax.set_title('Top Three Subjects')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45)
# 显示图表
plt.tight_layout()
image_path="./images/top_three_subjects.png"
plt.savefig(image_path)
4. 作图完成后大模型根据图片路径并整合之前的结果为用户生成最终的图文并茂的回答。
【附:执行日志】

(三)复杂统计问题(需要画图)

处理流程分析:
1. 用户输入query “查询数据库中所有论文的题目,基于题目内容将论文聚类为5类,每类分别列举几个文章,并用柱状图展示每类的论文数量“
2. 大模型提取数据查询问题”库中一共多少篇论文” 调用SqlCall:
input:
"查询库中所有论文题目"
text2sql:
select title from papers;
output:
["View Selection for 3D Captioning via Diffusion Ranking", "The Role of Language Imbalance in Cross-lingual Generalisation: Insights from Cloned Language Experiments", "OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments", "Ferret-v2: An Improved Baseline for Referring and Grounding with Large Language Models", "Rho-1: Not All Tokens Are What You Need", "Lyapunov-stable Neural Control for State and Output Feedback: A Novel Formulation", "On Unified Prompt Tuning for Request Quality Assurance in Public Code Review", "AmpleGCG: Learning a Universal and Transferable Generative Model of Adversarial Suffixes for Jailbreaking Both Open and Closed LLMs", "High-Dimension Human Value Representation in Large Language Models", "Overparameterized Multiple Linear Regression as Hyper-Curve Fitting", ...]
3. 模型编写程序进一步进行统计分析任务,并调用 run code 工具执行。
(完整代码GitHub链接🔗:https://github.com/LazyAGI/Tutorial/blob/7abc91dbb82a007a78731845dd8c360ac0cc1e75/rag/codes/chapter16/chat_sql_qa.py#L1)
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import os
# Load data
data = ["View Selection for 3D Captioning via Diffusion Ranking", "The Role of Language Imbalance in Cross-lingual Generalisation: Insights from Cloned Language Experiments", "OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments", "Ferret-v2: An Improved Baseline for Referring and Grounding with Large Language Models", "Rho-1: Not All Tokens Are What You Need", "Lyapunov-stable Neural Control for State and Out..."]
# Create DataFrame
df = pd.DataFrame(data, columns=['title'])
# Vectorize titles
tfidf = TfidfVectorizer(stop_words="english")
X = tfidf.fit_transform(df['title'])
# Perform K-means clustering
kmeans = KMeans(n_clusters=5, random_state=42)
df['cluster'] = kmeans.fit_predict(X)
# Count papers per cluster
cluster_counts = df['cluster'].value_counts().sort_index()
# Plot cluster counts
plt.figure(figsize=(10, 6))
cluster_counts.plot(kind='bar', color="skyblue")
plt.title('Number of Papers per Cluster')
plt.xlabel('Cluster')
plt.ylabel('Count')
plt.xticks(rotation=0)
# Save plot
os.makedirs('./images', exist_ok=True)
image_path="./images/cluster_counts.png"
plt.savefig(image_path)
plt.close()
# Print cluster counts and example titles
print("Cluster Counts:")
print(cluster_counts)
print("\nExample Titles per Cluster:")
for cluster in range(5):
print(f"\nCluster {cluster}:")
print(df[df['cluster'] == cluster]['title'].head(3).to_string(index=False))
print(f"\nImage saved at: {image_path}")
4. 执行完毕后大模型接收到图片路径和每类的结果,为用户生成图文并茂的回答。
【附:运行日志】


(四)知识问答

至此,我们构建了一个同时具备知识库问答与统计分析能力的智能问答系统。该系统不仅支持用户围绕文献内容进行语义提问,还能够针对数据库中的结构化信息执行统计分析与图表绘制,从而支持全局的数据观察需求。
六、RAG论文系统综合多模态方案

主要代码实现:
# 构建 rag 工作流和统计分析工作流
rag_ppl = build_paper_rag()
sql_ppl = build_statistical_agent()
# 搭建具备知识问答和统计问答能力的主工作流
def build_paper_assistant():
llm = OnlineChatModule(source="qwen", stream=False)
vqa = lazyllm.OnlineChatModule(source="sensenova",\
model="SenseNova-V6-Turbo").prompt(lazyllm.ChatPrompter(gen_prompt))
with pipeline() as ppl:
ppl.ifvqa = lazyllm.ifs(
lambda x: x.startswith('<lazyllm-query>'),
lambda x: vqa(x), lambda x:x)
with IntentClassifier(llm) as ppl.ic:
ppl.ic.case["论文问答", rag_ppl]
ppl.ic.case["统计问答", sql_ppl]
return ppl
if __name__ == "__main__":
main_ppl = build_paper_assistant()
lazyllm.WebModule(main_ppl, port=23459, static_paths="./images", encode_files=True).start().wait()
扩展阅读:从知识库构建数据库
代码实现:
import lazyllm
from lazyllm.tools import SqlManager
# 创建SQL管理器
sql_manager = SqlManager(db_type="SQLite", user=None,
password=None, host=None, port=None, db_name="doc.db")
# 创建知识库
documents = lazyllm.Document(dataset_path="/path/to/kb", create_ui=False)
# 配置提取字段
refined_schema = [
{"key": "document_title", "desc": "The title of the paper.", "type": "text"},
{"key": "author_name", "desc": "The names of the author of the paper.", "type": "text"},
{"key": "keywords", "desc": "Key terms or themes discussed in the paer.", "type": "text"},
{"key": "content_summary", "desc": "A brief summary of the paper's main content", "type": "text"},
]
# 知识库连接到SQL并设置待提取字段
documents.connect_sql_manager(
sql_manager=sql_manager,
schma=refined_schema,
force_refresh=True,
)
# 开始提取知识库到数据集
documents.update_database(llm=lazyllm.OnlineChatModule(source="qwen"))
# 展示提取到的内容:
str_result = sql_manager.execute_query(f"select * from {documents._doc_to_db_processor.doc_table_name}")
print(f"str_result: {str_result}")
效果展示:

[
{
"lazyllm_uuid": "2c42c181-bc26-43ca-a822-505b22f5d19e",
"lazyllm_created_at": "2025-05-16 19:10:12.014368",
"lazyllm_doc_path": "/path/to/pdfs/DeepSeek_R1.pdf",
"document_title": "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning",
"author_name": "DeepSeek-AI",
"keywords": "DeepSeek-R1-Zero, DeepSeek-R1, reinforcement learning, reasoning models, multi-stage training, open-source, dense models, distilled models, Qwen, Llama",
"content_summary": "The paper introduces the first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero is trained using large-scale reinforcement learning without supervised fine-tuning and demonstrates strong reasoning capabilities but faces challenges such as poor readability and language mixing. To improve upon this, DeepSeek-R1 incorporates multi-stage training and cold-start data before reinforcement learning, achieving performance comparable to OpenAI-o1-1217 on reasoning tasks. The research community is supported by the open-sourcing of DeepSeek-R1-Zero, DeepSeek-R1, and six dense models distilled from DeepSeek-R1 based on Qwen and Llama."
}
]
更多技术内容,欢迎移步 “LazyLLM” 讨论!
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


