Amazon Aurora DSQL是亚马逊云科技于2024年12月推出的分布式SQL数据库,专为构建扩展性无限、高可用且免基础设施管理的应用程序设计,具有可用性高、无服务器模式架构、兼容性强、容错能力和安全级别高等特点。
由于Aurora DSQL的认证机制与IAM集成, 访问Aurora DSQL数据库需要通过IAM的身份来生成token 进行访问,而token 默认只有15分钟有效期,因此目前一些主流的数据同步工具暂不支持将其他数据库的数据迁移到Aurora DSQL。
基于这种情况,本文作者基于数据同步工具Apache SeaTunnel开发了一个专门针对Aurora DSQL的sink Connector,以满足从其他数据库迁移数据到Aurora DSQL需求。
SeaTunnel 介绍
SeaTunnel是一个非常易用、多模态、超高性能的分布式数据集成平台,专注于数据集成和数据同步,主要旨在解决数据集成领域的常见问题。
SeaTunnel 相关特性
- 丰富且可扩展的Connector: 目前,SeaTunnel 支持超过 190 个Connector且数量还在增加,像主流数据库MySQL 、Oracle、SQLServer、PostgreSQL等都已经提供了Connector支持。插件式设计让用户可以轻松开发自己的Connector并将其集成到SeaTunnel项目中。
- 批流集成:基于SeaTunnel Connector API开发的Connector完美兼容离线同步、实时同步、全量同步、增量同步等场景。 它们大大降低了管理数据集成任务的难度。
- 分布式快照:支持分布式快照算法,保证数据一致性。
- 多引擎支持:SeaTunnel默认使用SeaTunnel引擎(Zeta)进行数据同步。 SeaTunnel还支持使用Flink或Spark作为Connector的执行引擎,以适应企业现有的技术组件。 SeaTunnel 支持 Spark 和 Flink 的多个版本。
- JDBC复用、数据库日志多表解析:SeaTunnel支持多表或全库同步,解决了过度JDBC连接的问题; 支持多表或全库日志读取解析,解决了CDC多表同步场景下需要处理日志重复读取解析的问题。
- 高吞吐量、低延迟:SeaTunnel支持并行读写,提供稳定可靠、高吞吐量、低延迟的数据同步能力。
- 完善的实时监控:SeaTunnel支持数据同步过程中每一步的详细监控信息,让用户轻松了解同步任务读写的数据数量、数据大小、QPS等信息。
SeaTunnel 工作流程
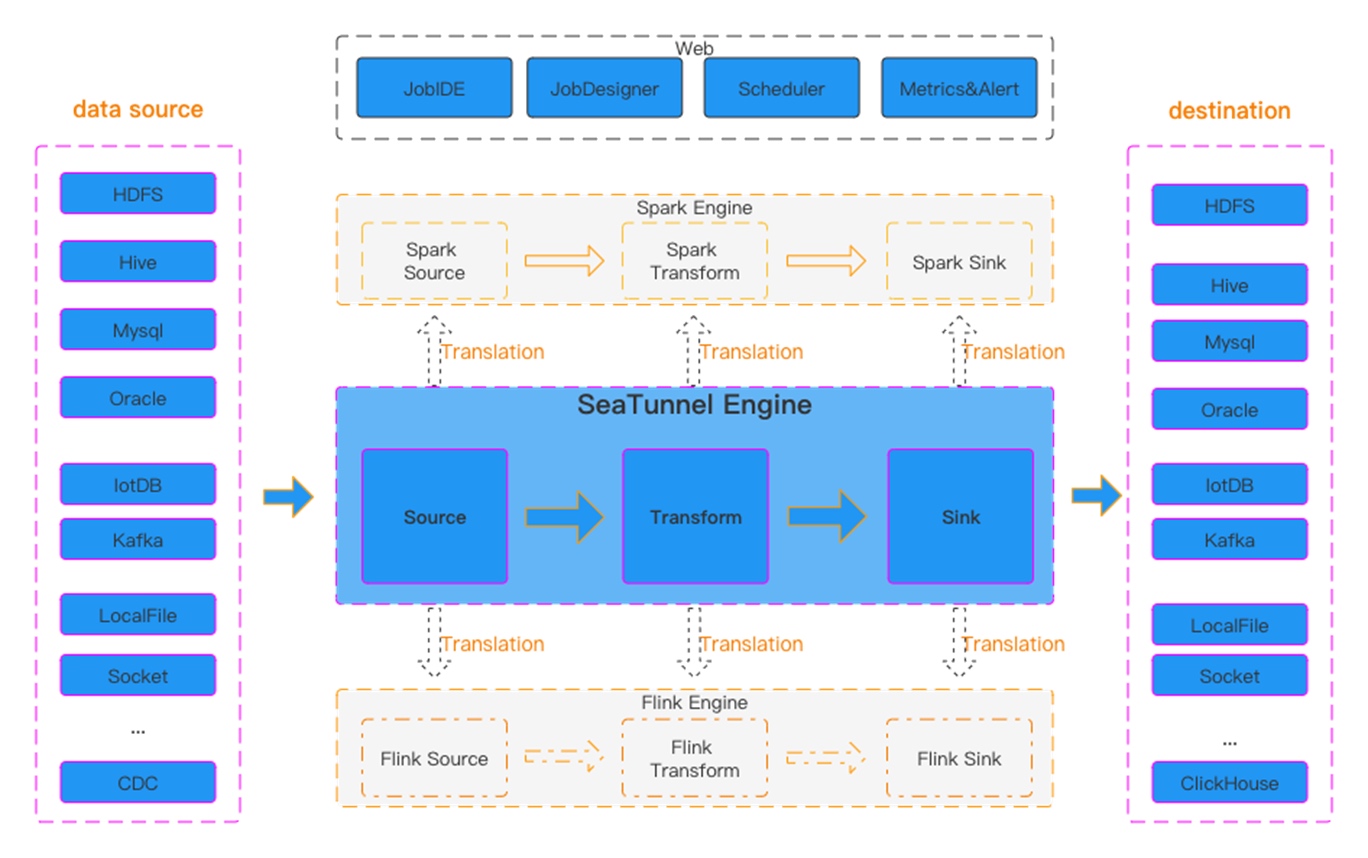 图一 Seatunnel工作流图
图一 Seatunnel工作流图
SeaTunnel的工作流程如上图所示,用户配置作业信息并选择提交作业的执行引擎。Source Connector负责并行读取源端数据并将数据发送到下游Transform或直接发送到Sink,Sink将数据写入目的地。
从源码构建SeaTunnel
git clone https://github.com/apache/seatunnel.git
cd seatunnel
sh ./mvnw clean install -DskipTests -Dskip.spotless=true
cp seatunnel-dist/target/apache-seatunnel-${version}-bin.tar.gz /The-Path-You-Want-To-Copy
cd /The-Path-You-Want-To-Copy
tar -xzvf "apache-seatunnel-${version}-bin.tar.gz"
从源码构建成功后,所有的Connector插件和一些必要的依赖(例如:mysql驱动)都包含在二进制包中。您可以直接使用Connector插件,而无需单独安装它们。
使用Seatunnel同步MySQL数据到Aurora DSQL 配置示例
env {
parallelism = 1
job.mode = "STREAMING"
checkpoint.interval = 6000
checkpoint.timeout = 1200000
}
source {
MySQL-CDC {
username = "user name"
password = "password"
table-names = ["db.table1"]
url = "jdbc:mysql://dbhost:3306/db?useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=UTC&connectTimeout=120000&socketTimeout=120000&autoReconnect=true&failOverReadOnly=false&maxReconnects=10"
table-names-config = [
{
table = "db.table1"
primaryKeys = ["id"]
}
]
}
}
transform {
}
sink {
Jdbc {
url="jdbc:postgresql://<dsql_endpoint>:5432/postgres"
dialect="dsql"
driver = "org.postgresql.Driver"
username = "admin"
access_key_id = "ACCESSKEYIDEXAMPLE"
secret_access_key = "SECRETACCESSKEYEXAMPLE"
region = "us-east-1"
database = "postgres"
generate_sink_sql = true
primary_keys = ["id"]
max_retries="3"
batch_size =1000
}
}
运行数据同步任务
将上面的配置保存为mysql-to-dsql.conf 文件(请注意需要将示例中的值替换为真实的参数),存放在apache-seatunnel-${version} 的config 目录下,执行以下命令:
cd "apache-seatunnel-${version}"
./bin/seatunnel.sh --config ./config/mysql-to-dsql.conf -m local
 图二 数据同步日志信息
图二 数据同步日志信息
命令执行成功后,您可以通过新产生的日志观察任务执行情况,如果出现错误,也可以根据异常信息进行定位,比如数据库连接超时、表不存在情况。而正常情况下,数据会成功写入目标 Aurora DSQL,如上图所示。
总结
Aurora DSQL是一款高度安全、易扩展、无服务器基础设施的分布式数据库,它的认证方式与IAM身份结合,因此目前缺少合适的工具可以将数据同步到Aurora DSQL中,尤其是在实时数据同步方面。SeaTunnel 是一款非常优秀数据集成和数据同步工具,目前支持多种数据源的数据同步,并且基于SeaTunnel 也可以非常灵活地实现自定义的数据同步需求,比如全量同步/增量实时同步。基于这种灵活性,本文作者开发了一种专门针对于Aurora DSQL 的Sink Connector, 以满足对于Aurora DSQL 数据同步需求。
参考文档
-
SeaTunnel 部署:https://seatunnel.apache.org/zh-CN/docs/start-v2/locally/deployment
-
开发新的SeaTunnel Connector:
-
https://github.com/apache/seatunnel/blob/dev/seatunnel-connectors-v2/README.zh.md
-
在Aurora DSQL 中生成身份验证令牌:https://docs.aws.amazon.com/aurora-dsql/latest/userguide/SECTION_authentication-token.html
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者

谭志强,亚马逊云科技迁移解决方案架构师,主要负责企业级客户的上云或跨云迁移工作,具有十几年 IT 专业服务经验,历任程序设计师、项目经理、技术顾问、解决方案架构师。
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


