坏消息,开源模型和闭源模型的差距越来越大了。
好消息,DeepSeek 又出手了。
12 月 1 日,DeepSeek 发布了两款新模型 —— DeepSeek V3.2 和 DeepSeek-V3.2-Speciale。
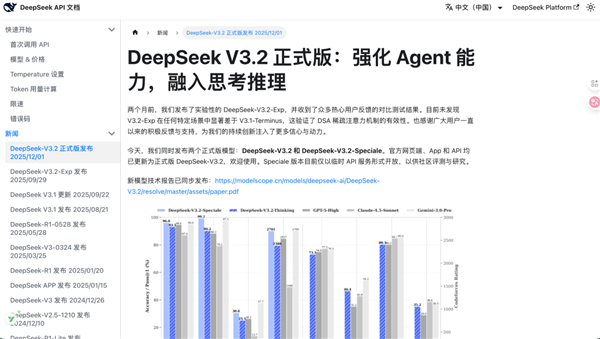
前者和 GPT-5 能打的有来有回,后面的高性能版更是直接把 GPT 爆了,开始和闭源模型天花板 —— Gemini 打了个五五开。
还在IMO 2025(国际数学奥林匹克)、CMO 2025(中国数学奥林匹克)等一系列比赛中拿下金牌。

这是这家公司今年第九次发布模型,虽然大家期待的 R2 还没有来。
所以,DeepSeek 是怎么用更小的数据,更少的显卡,做出能和国际巨头来抗衡的模型?
我们翻开了他们的论文,想把这件事给大家讲清楚。
为了做到这个目标,DeepSeek 又整了不少新招:
先是把咱们的老朋友 DSA —— 稀疏注意力给转正了。

这东西在之前的 V3.2-EXP 版本里出现过,当时只是测了一下 DSA 会不会影响模型的性能,现在是真的把这玩意给放到了主力模型上。

大家平时和大模型聊天的时候会发现,你在一个对话框里聊的越多,模型就越容易胡言乱语。
甚至聊的太多了,还会直接不让你聊了。

这是因为大模型原生的注意力机制导致的问题,在这套老逻辑的影响下,每个 token 出来,都要和前面的每一个 token 互相算在一起做一次计算。

这就导致了句子增长一倍,模型的计算量就得增加到原来的四倍,如果边长到原来的三倍,计算量就变成了原来的九倍,非常麻烦。
DeepSeek 想这样不行啊,于是就给大模型里加了固定页数的目录(稀疏注意力),相当于帮模型划重点了。
而在有了目录之后,以后每次只需要计算这个 token 和这些目录的关系就行了,相当于就是看书先读目录,看完目录,对哪一章感兴趣,再去仔细看这章的内容就好。
这样一来,就能让大模型读长文的能力变的更强。
在下面这张图里可以看到,随着句子越来越长,传统的 V3.1 的推理成本是越来越高。
但是用上了稀疏注意力的 3.2 则没什么变化。。。
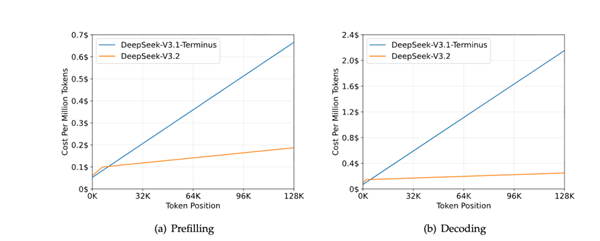
属于是超级省钱冠军了。
另一方面,DeepSeek 开始重视起了开源模型的后训练工作。
大模型这一套从预训练开始,到考试打分的过程,其实有点像是我们人类从小学开始,一路读书读到高考的过程。
前面的大规模预训练,相当于从小学到高二,把所有课本、练习册、卷子全过一遍,这一步大家都差不多,不管是闭源模型,还是开源模型,都在老老实实的念书。
但到了高考冲刺阶段就不一样了,在模型的后训练阶段,闭源模型一般都会请名师,猛刷题,开始搞起各种强化学习,最后让模型来考一个不错的成果。
但开源模型在这块花的心思就比较少了,按照 DeepSeek 的说法,过去的开源模型在训练后阶段计算投入普遍偏低。
这就导致这些模型可能基础能力是已经到位的了,但就是难题刷少了,结果导致考出来的成绩不太好。
于是,DeepSeek 决定这次自己也要上名师辅导班,设计了一套新的强化学习协议,在预训练结束后,花了超过总训练算力的 10% 来给模型开小灶,把之前缺的这块给补上。
同时还推出了个能思考超长时间的特殊版本 —— DeepSeek V3.2 Speciale。
这玩意的思路是这样的:
过去的大模型因为上下文长度有限制,所以在训练的时候都会做一些标注惩罚的工作,如果模型深度思考的内容太长了,那就会扣分。
而到了 DeepSeek V3.2 Speciale 这儿,所以 DeepSeek 干脆取消掉了这个扣分项,反而鼓励模型想思考多久就思考多久,想怎么思考就怎么思考。
最终,让这个全新的 DeepSeek V3.2 Speciale 成功的和前几天爆火的 Gemini 3 打的有来有回。
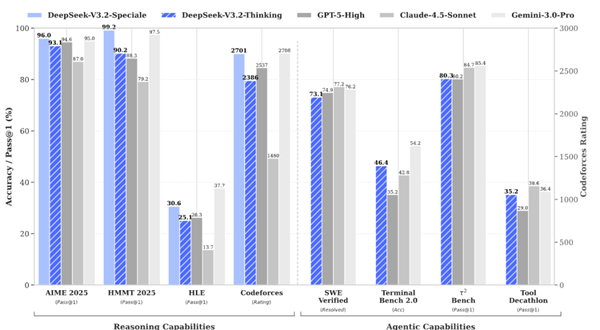
此外DeepSeek 还很重视模型在智能体方面能力。
一方面,为了提高模型的基础能力,DeepSeek 构建了一个虚拟环境,合成了成千上万条数据来辅助训练。
DeepSeek-V3.2 用 24667 个真实代码环境任务、50275 个真实搜索任务、4417 个合成通用 agent 场景、5908 个真实的代码解释任务做后训练。

另一方面,DeepSeek 还优化了模型使用各种工具的流程。
以前几代 DeepSeek 的一个典型毛病是:会把思考和用工具给分开。
模型一旦去调用外部工具,前面那段思考基本就算写完收工了,等工具查完结果再回来,它往往又要重新铺一遍思路。
这就导致一种很蠢的体验——哪怕只是去查一下“今天几月几号” 这种小事,模型也会从头开始重建整套推理链,非常浪费时间。。。
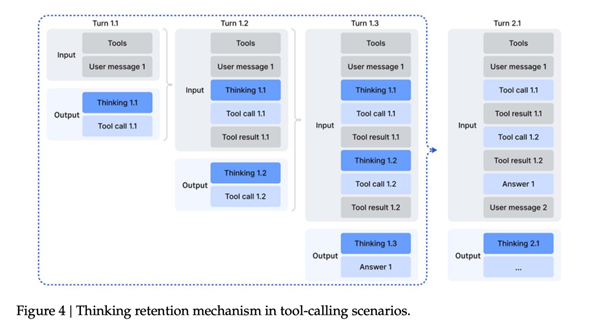
在 V3.2 这里,DeepSeek 忍不了了,直接把这套逻辑推翻重做。
现在的规则变成:在一整串工具调用的过程中,模型的“思考过程”会一直保留下来,只有当用户发来一条新的提问时,才会重置这一轮推理;而工具的调用记录和结果,会像聊天记录一样一直留在上下文里。
通过这修改模型架构,重视后训练,强化 Agent 能力的三板斧,DeepSeek 才终于让自己的新模型,有了能和世界顶尖开源模型再次一战的能力。
当然,即使做了这么多改进,DeepSeek 的表现也算不上完美。
但托尼最喜欢 DeepSeek 的一点,就是他们愿意承认自己的不足。
而且还会直接在论文里写出来。
比如这次论文就提到了,这次的 DeepSeek V3.2 Speciale 虽然能和谷歌的 Gemini 3 Pro 来打的五五开。

但是要回答相同的问题,DeepSeek 需要花费更多的 token。
我自己也测试了一下,从“人类的最终考试” 的题库里随便抽了道题目,同时丢给 Gemini 3 Pro 和 DeepSeek V3.2 Speciale 这两个模型。
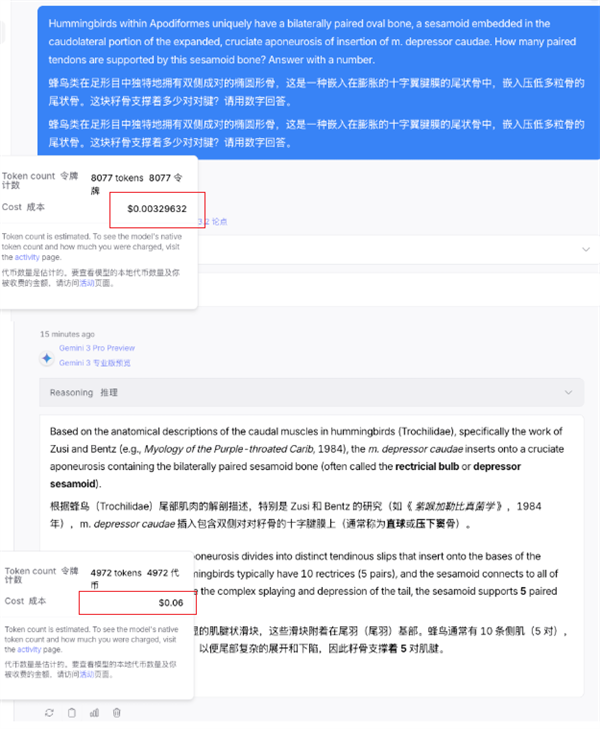
题目是:
蜂鸟类在足形目中独特地拥有双侧成对的椭圆形骨,这是一种嵌入在膨胀的十字翼腱膜的尾状骨中,嵌入压低多粒骨的尾状骨。这块籽骨支撑着多少对对腱?请用数字回答。
结果发现 Gemini 只要 4972 个 Tokens 就能把问题给答出来。

而到了 DeepSeek 这边,则用了 8077 个 Tokens 才把问题给搞明白。

光看用量的话,DeepSeek 的的 Tokens 消耗量高了快六成,确实是有不小的差距。
但是话又说回来了。
DeepSeek 虽然消耗的 token 多,但是人家价格便宜啊。。。
还是刚才那个问题,我回头仔细看了眼账单。
DeepSeek 8000 多个 tokens,花了我 0.0032 美元。
但谷歌这边,5000 个 tokens 不到,给我干掉了 0.06 刀?这块要比 DeepSeek 高了有 20 倍了。
从这个角度上来看,怎么感觉还是 DeepSeek 更香一些。。。
最后,让我们回到论文的开头。
正如 DeepSeek 所言,最近半年来,开源模型和闭源模型的差距正在不断加大。

但他们还是用自己的方式,在不断追赶这份差距。
而 DeepSeek 的各种节省算力,节约数据的操作,其实让我想到了上个月,一场关于 Ilya Sutskever 的访谈。

这位 OpenAI 曾经的灵魂人物认为,只靠一味的给模型堆参数,是没有未来的。
AlexNet只用了两块GPU。Transformer刚出现时的实验规模,大多在8~64块GPU范围内。按今天的标准看,那甚至相当于几块GPU的规模,ResNet也一样。没有哪篇论文靠庞大的集群才能完成。
比起算力的堆砌,对算法的研究也一样重要。
这正是 DeepSeek 在做的事情。
从 V2 的 MoE,到 V3 的多头潜在注意力(MLA),再到如今 DeepSeek Math V2 的自验证机制,V3.2 的稀疏注意力(DSA)。
DeepSeek 展现给我们进步,从来都不是单一的,依靠堆砌参数规模所带来的提升。
而是在想办法,如何用有限的数据,来堆积出更多的智能。
巧妇狂作无米之炊
所以,R2 什么时候来呢?
文章内容举报
]article_adlist–>
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

