
<p><img src="https://oscimg.oschina.net/oscnet/up-36f40e745ed7f6d40ba1e89615ee02dfb44.jpg" alt=""></p> 在大模型全面走向工程落地的当下,LazyLLM 正式与硅基流动(SiliconFlow) 达成深度合作,共同打造面向开发者的下一代智能应用底座。借助LazyLLM的一键接入线上模型API能力,硅基流动的大语言模型、多模态模型、向量与Embedding模型、文生图模型等已经完整接入,同一套接口即可覆盖从文本到图像、从检索到生成的全链路需求。
这次合作带来的不仅是更强大的RAG选型 ,还进一步放大了Agent能力:在LazyLLM中,开发者可以基于统一的模型接入层,灵活编排工具调用与工作流,结合对MCP等协议的支持,将检索、调用外部系统、多模型路由、长程记忆等能力封装为可协作的智能体网络。
对于开发者而言,底层模型与算力的复杂度被彻底”藏”在LazyLLM+硅基流动这套组合之下——你只需聚焦业务逻辑,就能搭出既有强RAG能力、又有高扩展Agent能力的AI应用,从原型验证一路平滑升级到生产级部署。
LazyLLM
LazyLLM是由商汤LazyAGI团队开发的一款开源低代码大模型应用开发工具,提供从应用搭建、数据准备、模型部署、微调到评测的一站式工具支持,以极低的成本快速构建AI应用,持续迭代优化效果。
一、API申请和环境配置
(一)账号注册
-
注册硅基流动账号
-
进入控制台,获取APIkey
(二)环境配置
参考网页:快速开始-LazyLLM。
(https://docs.lazyllm.ai/zh-cn/stable/)
二、API使用测试
(一)设置环境变量
可以使用以下命令设置对应的环境变量。或从代码中显示给入:
export LAZYLLM_SILICONFLOW_API_KEY=<申请到的api key>
(二)实现对话和图片识别
1. 文本问答演示
填好api_key后,运行下面代码可以迅速调用模型并生成一个问答形式的前端界面:
import lazyllm
from lazyllm import OnlineChatModule,WebModule
api_key = 'sk-' #替换成申请的api
# # 测试chat模块
llm = OnlineChatModule(source="siliconflow", api_key=api_key, stream=False)
w = WebModule(llm, port=8846, title="siliconflow")
w.start().wait()
我们询问”什么是LazyLLM”,运行结果如下:
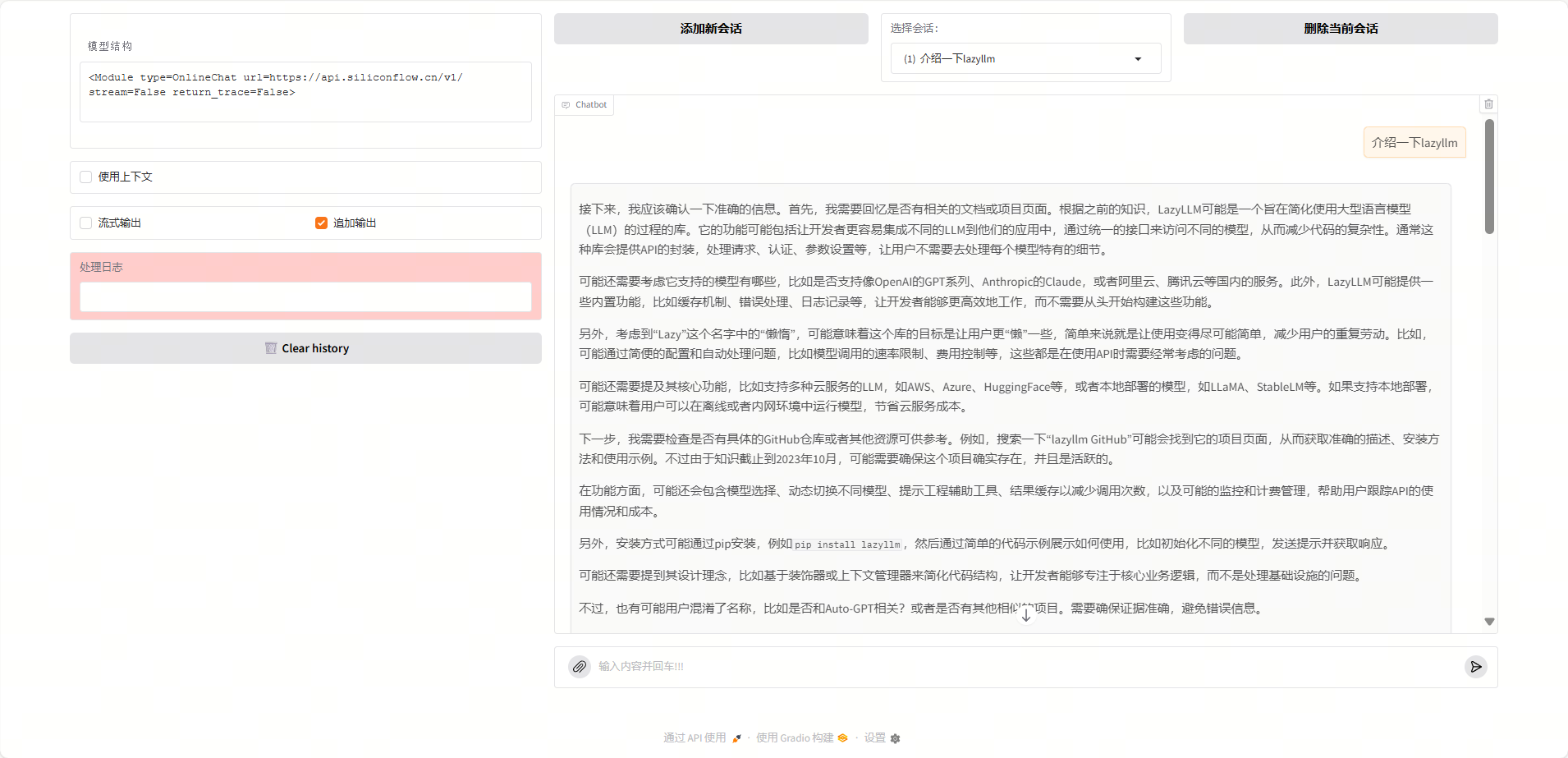
2. 多模态问答演示
在输入中通过lazyllm_files参数传入一张图片,并询问图片的内容,就可以实现多模态的问答。
import lazyllm
from lazyllm import OnlineChatModule
api_key = 'sk-' #替换成申请的api
llm = OnlineChatModule(source="siliconflow", api_key=api_key, model="Qwen/Qwen2.5-VL-72B-Instruct")
print(llm('你好,这是什么?', lazyllm_files=['your_picture.png']))
这里我们使用这个图片测试多模态问答

命令行中输出结果:
你好!这是一只小猫。它看起来非常可爱,毛茸茸的,眼睛大大的,背景是模糊的色彩,突出了小猫的细节。这样的图像通常能让人们感到温暖和愉快。你想了解更多关于小猫的信息吗?
(lazyllm)→LazyLLMgit:(main)

(三)实现文生图和文生语音
使用OnlineMultiModalModule进行文生图和文生语音,运行后会输出生成的文件路径
import lazyllm
from lazyllm import OnlineMultiModalModule
api_key = 'sk-xxx'
# 测试文生图 fuction=text2image
llm = OnlineMultiModalModule(source="siliconflow", api_key=api_key, function='text2image')
print(llm("生成一个可爱的小狗"))
# 测试文生语音 function=tts
llm = OnlineMultiModalModule(source="siliconflow", api_key=api_key, function='tts')
print(llm("你好,你叫什么名字", voice="fnlp/MOSS-TTSD-v0.5:anna"))
运行结果:

生成的语音如下:
| tmpck44zfds.mp3 | 55.13KB | 2025-10-2723:13 |
(语音链接:https://ones.ainewera.com/wiki/#/team/JNwe8qUX/share/7fy5a6mk/page/FUcz8wKs/)
(四)10+行代码实现知识库问答
1. 实现Eembed和Rerank功能
运行下面代码,使用OnlineEmbeddingModule进行向量化嵌入;设置type=”rerank”调用重排序模型。
import lazyllm
from lazyllm import OnlineEmbeddingModule
api_key = 'sk-'
#测试embed模块
llm = OnlineEmbeddingModule(source="siliconflow", api_key=api_key)
print(llm("苹果"))
#测试rerank模块
llm = OnlineEmbeddingModule(source="siliconflow", api_key=api_key, type="rerank")
print(llm(["苹果", ['苹果','香蕉','橘子']]))
向量化的结果如下:
[-0.0024823144, -0.0075530247, -0.013154144, -0.031351723, -0.024489744, 0.009692847, 0.008086464, -0.037946977, 0.013251133, -0.046675995, -0.011390155, -0.011111312, 0.016779112, 0.054168403, 0.04849454, 0.014742341, 0.02341074, -0.015542501, 0.059939254, -0.024223024, 0.0065467632, -0.041244607, -0.022925794, -0.024804957, 0.006752865, -0.047548898, -0.03685585, 0.0513557....,-0.070656545, -0.01997975, 0.023398615, 0.008735079]
词相似性分数如下:
[{'index': 0, 'relevance_score': 0.9946065545082092}, {'index': 2, 'relevance_score': 0.014802767895162106}, {'index': 1, 'relevance_score': 0.0004139931406825781}]
2. 知识库导入
我们使用中国古典文籍作为示例知识库,下载后放在database文件夹。
(示例数据集下载链接:https://huggingface.co/datasets/LazyAGI/Chinese_Classics_Articles/tree/main)
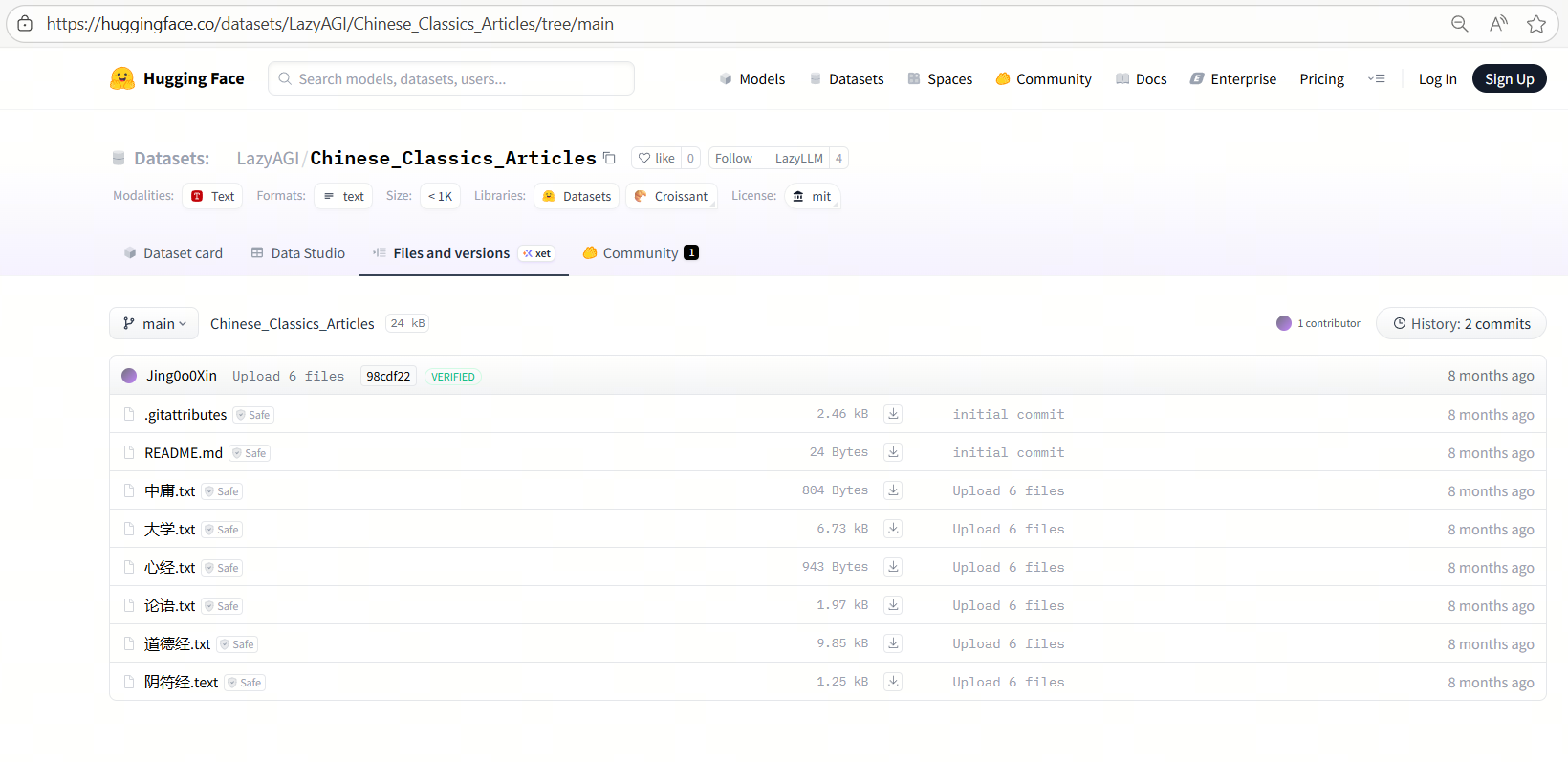
首先定义embed模型,然后使用LazyLLM的Document组件创建文档管理模块,以实现知识库的导入。
import lazyllm
api_key='sk-'
embed_model = lazyllm.OnlineEmbeddingModule(source="siliconflow", api_key=api_key)
documents = lazyllm.Document(dataset_path="database", embed=embed_model)
3. 知识库检索
现在有了外部知识库,LazyLLM中使用Retriever组件可以实现检索知识库并召回相关内容。使用示例:
import lazyllm
from lazyllm.tools import Retriever, Document, SentenceSplitter
api_key='sk-'
embed_model = lazyllm.OnlineEmbeddingModule(source="siliconflow", api_key=api_key)
documents = Document(dataset_path="database", embed=embed_model, manager=False)
rm = Retriever(documents, group_name="CoarseChunk", similarity='bm25', similarity_cut_off=0.01, topk=6)
rm.start()
print(rm("user query"))
4. 知识库问答
结合上述模型、文档管理和检索模块,搭配LazyLLM内置的Flow组件进行完整的数据流搭建,完整代码如下:
import lazyllm
from lazyllm import (
OnlineEmbeddingModule, OnlineChatModule, Document, SentenceSplitter,
Retriever, Reranker, ChatPrompter, pipeline
)
# 初始化api key和提示词
api_key = 'sk-'
prompt = """
You will play the role of an AI Q&A assistant and complete a dialogue task.
In this task, you need to provide your answer based on the given context and question.
"""
# 初始化模型
embed_model = OnlineEmbeddingModule(source="siliconflow", api_key=api_key)
rerank_model = OnlineEmbeddingModule(source="siliconflow", api_key=api_key, type="rerank")
llm = OnlineChatModule(source="siliconflow", api_key=api_key)
# 定义文档管理模块,并创建节点组
doc = Document(dataset_path="/home/xxx/database", manager=False, embed=embed_model)
doc.create_node_group(name="block", transform=SentenceSplitter, chunk_size=1024, chunk_overlap=100)
doc.create_node_group(name="line", transform=SentenceSplitter, chunk_size=128, chunk_overlap=20, parent="block")
# 构建RAG pipeline(多路召回--重排--提示词拼接--大模型回答)
with pipeline() as ppl:
with lazyllm.parallel().sum as ppl.prl:
prl.r1 = Retriever(doc, group_name="line", similarity="cosine", topk=6, target="block")
prl.r2 = Retriever(doc, group_name="block", similarity="cosine", topk=6)
ppl.reranker = Reranker('ModuleReranker', model=rerank_model, output_format="content",
join=True) | bind(query=ppl.input)
ppl.formatter = (lambda context, query: dict(context_str=str(context), query=query)) | bind(query=ppl.input)
ppl.llm = llm.prompt(lazyllm.ChatPrompter(prompt, extra_keys=["context_str"]))
ppl.start()
query = "何为天道"
print(ppl(query))
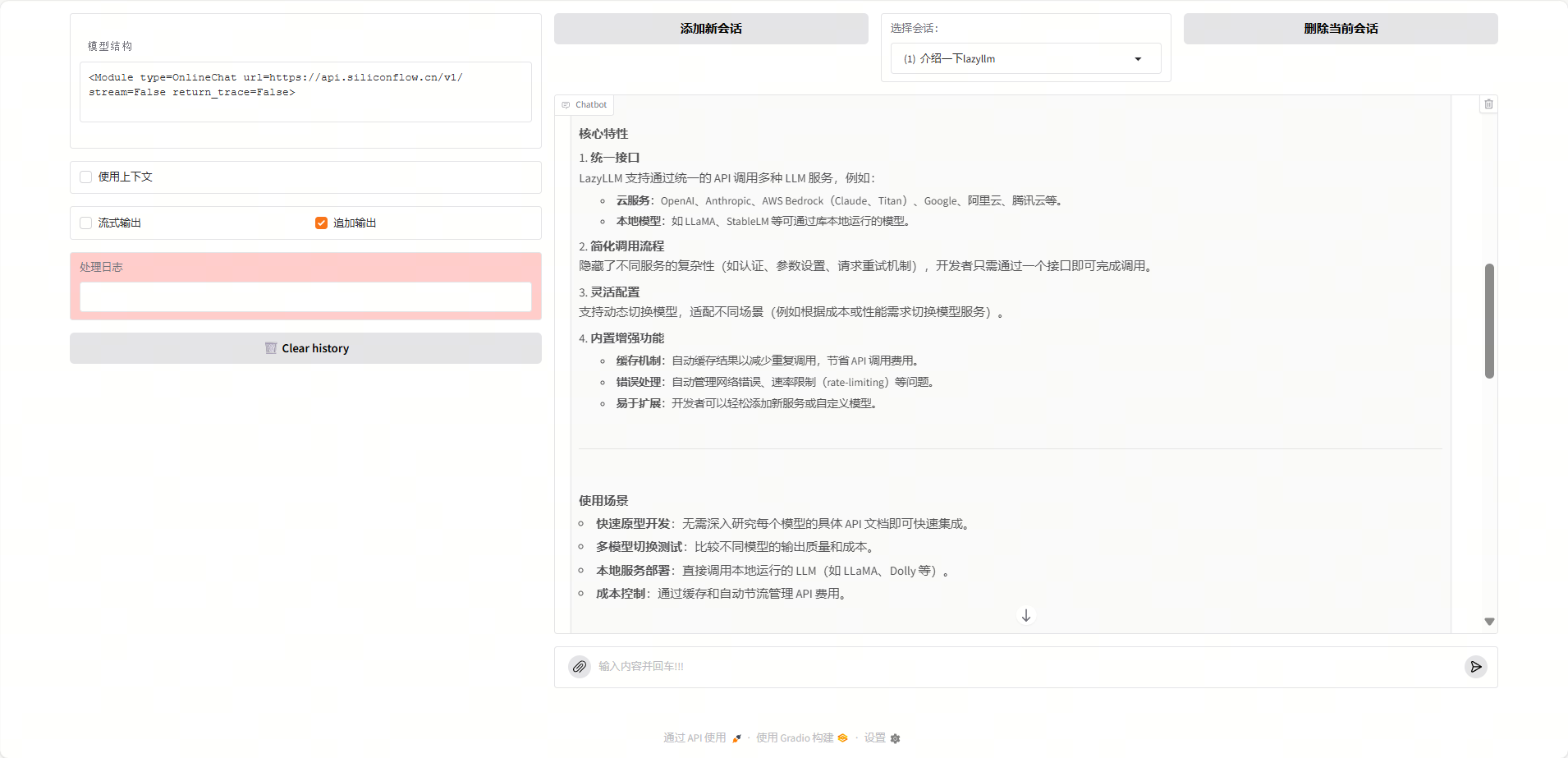
可以看到RAG很好地从《道德经》等中取回了有关天道的内容,并传给大模型进行回答。
更多技术内容,欢迎移步 “LazyLLM” 讨论!
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


