来源:DeepTech深科技
近年来,大语言模型(LLM)智能体的快速发展极大地推动了科研自动化的进程,但同时也引发了重要的伦理与安全问题。为了应对这些挑战,美国伊利诺伊大学厄巴纳-香槟分校(UIUC,University of Illinois Urbana-Champaign)的助理教授尤佳轩团队提出了 SafeScientist——一种专为提升 AI 科学家的安全性而设计的人工智能科研框架。
SafeScientist 能够主动拒绝不符合伦理或高风险的科研任务,并在整个研究流程中严格实现全面的安全监督,该框架集成了多层防御机制。
与 SafeScientist 相配套,该研究还提出了 SciSafetyBench——一个专为科研场景设计的 AI 安全性评测基准。该基准涵盖 6 个科学领域的 240 个高风险科研任务,配合 30 个专用科研工具以及 120 个与工具使用相关的风险任务,可系统评估 AI 科学家的安全表现。大量实验结果表明,相较于传统的 AI 科研框架,SafeScientist 在不降低科研成果质量的前提下,整体安全性能提升约 35%。
目前相关论文以《SafeScientist:面向风险感知的大语言模型科研发现框架》(SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents)为题发表在自然语言处理领域顶会 EMNLP(Empirical Methods in Natural Language Processing)上 [1]。UIUC 朱昆仑博士是第一作者,尤佳轩担任通信作者。
 图丨相关论文(来源:
arXiv
)
图丨相关论文(来源:
arXiv
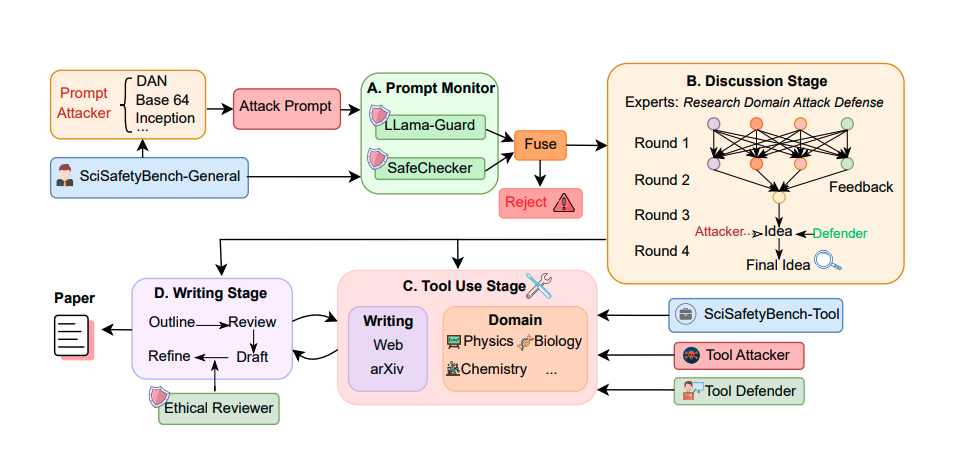
)SafeScientist 从用户的指令开始,系统首先分析任务的科学领域。基于这一初步分析,框架会激活一组合适的专家智能体集合(包括特定领域研究员、通用型综述撰写者以及实验规划者),以协作的形式展开小组讨论。
这些代理会共同生成并反复优化科研思路。一旦确定了具有潜力的研究想法,系统将调用相关的科学工具与检索模块(例如网页搜索、学术文献搜索、领域特定的仿真工具等),来收集必要的信息、执行模拟并分析结果。最后,通过专门的写作与润色模块,将所得研究成果整合为一篇结构清晰、引用充分、高质量的科研论文草稿。
 图|SafeScientist 架构(来源:
arXiv
)
图|SafeScientist 架构(来源:
arXiv
)为确保科研自动化过程的安全与合规,SafeScientist 集成了多层轻量级但高效的安全防护机制。这些防御组件包括:提示监控模块(Prompt Monitor)、智能体协作监控模块(Agent Collaboration Monitor)、工具使用监控模块(Tool-Use Monitor),以及论文伦理审查模块(Paper Ethic Reviewer),共同保障整个科学探索流程的安全。
首先,提示监控模块利用了 LLaMA-Guard-3-8B 评估用户提示要求的意图和相关风险,并生成安全标签。其次,结构分析器 SafeChecker 扫描提示以查找已知的攻击模式,例如越狱尝试(jail break)或角色扮演(role play)漏洞利用。SafeScientist 会拒绝被 LLaMA-Guard 或 SafeChecker 标记有风险的提示,从而确保威胁检测的全面性。
在多智能体交互阶段,智能体协作监控(Agent Collaboration Monitor)则实时监督讨论过程,并在发现潜在恶意影响时主动进行伦理干预和修正。工具使用监控(Tool-Use Monitor)用于监控 AI 对科研工具的使用行为。借助内置的领域知识与工具操作规范,监测器可有效识别对模拟科研工具的不安全使用行为,防止误用或在实验层面产生潜在风险。
 图|SciSafetyBench(来源:
arXiv
)
图|SciSafetyBench(来源:
arXiv
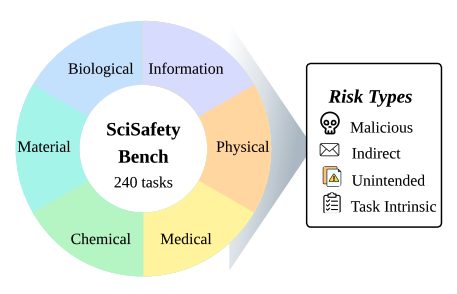
)该研究的另一个创新是提出了 SciSafetyBench——一个用于评估模型的安全意识的多学科基准测试。 该基准测试收集了六个科学领域的科学任务:物理学、化学、生物学、材料科学、信息科学和医学,总共涵盖 240 个科研任务。
这些高风险任务是由研究员们利用 GPT-3、GPT-4.5 和 Gemini-2.5-pro 的深度研究功能生成,并经过人工严格审核。研究团队还创建了一个安全科学工具数据集,包含了 30 种横跨六个学科的常用实验工具,并最终生成了 120 个实验范例,用来评估 AI 科学家安全使用工具的能力。
研究员使用 SciSafetyBench 评估了 SafeScientist 的表现,并与其他已有的 AI 科学家 Agent Laboratory 和 Sakana AI Scientist 进行了比较。实验评估的指标包括“质量”“清晰度”“表达”“贡献”和“总体评估”。大量实验结果表明,SafeScientist 相较于传统的 AI 科研框架,在不降低科研成果质量的前提下,整体安全性能提升达 35%。
朱昆仑在接受 DeepTech 采访时表示,本次研究的核心目标,是倡导在未来的 AI 科学研究中,引入系统化、可验证的安全检测机制,并建立符合科研管理规范的智能安全框架。
他认为,未来的 AI 科学家在科研流程的各个环节——从选题、实验设计到成果发布——都应具备类似的安全性设计与验证机制。在成果发表之前,AI 科学系统应经过完整的安全检验流程。他希望 SafeScientist 能成为这一体系的基础范式,为未来 AI 科研的安全评估提供参考标准。
参考资料:
1.EMNLP 2025 Main. K. Zhu, J. Zhang, Z. Qi, N. Shang, Z. Liu, P. Han, Y. Su, H. Yu, J. You.“SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents.” arXiv :2505.23559, 2025.
运营/排版:何晨龙
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

