
<blockquote> 编者按: 当大模型的算力需求呈指数级增长,GPU 还是唯一答案吗?在 AI 硬件军备竞赛愈演愈烈的今天,是否存在更高效、更专精、甚至更具颠覆性的替代方案?
我们今天为大家带来的文章,作者的核心观点是:AI 硬件生态正在迅速多元化,除了广为人知的 CPU、GPU 和 TPU 之外,一系列新兴架构 —— 如 ASIC、NPU、IPU、FPGA 乃至存内计算与神经形态芯片,正从不同维度重塑 AI 的算力未来。
文章系统梳理了三大经典处理单元(CPU、GPU、TPU)的原理与局限,并深入剖析了包括 Cerebras 晶圆级引擎、AWS Trainium/Inferentia、AMD APU、NPU 在内的专用芯片设计思路;进而拓展至 IPU、RPU、FPGA 等前沿架构,揭示它们如何针对稀疏计算、图神经网络、边缘推理或存算一体等特定场景提供突破性性能。
作者 | Ksenia Se and Alyona Vert
编译 | 岳扬
目录
01 CPU、GPU、TPU — 三种核心硬件架构
1.1 中央处理单元(Central Processing Unit, CPU)
1.2 图形处理单元(Graphics Processing Unit, GPU)
1.3 张量处理单元(Tensor Processing Unit, TPU)
02 专用集成电路(Application-Specific Integrated Circuits, ASICs)
2.1 Cerebras 晶圆级引擎(Wafer-Scale Engine, WSE)
2.2 AWS Trainium 与 AWS Inferentia
2.3 加速处理单元(Accelerated Processing Unit, APU)
2.4 神经网络处理单元(Neural Processing Unit, NPU)
03 其他有前景的替代架构
3.1 智能处理单元(Intelligence Processing Unit, IPU)
3.2 阻变处理单元(Resistive Processing Unit, RPU)
3.3 现场可编程门阵列(Field-Programmable Gate Arrays, FPGAs)
04 新兴架构(Emerging Architectures)
4.1 量子处理器(Quantum Processors)
4.2 存内计算(Processing-in-Memory, PIM)与基于 MRAM 的芯片
4.3 神经形态芯片(Neuromorphic Chips)
05 结语(Conclusion)
如今连小孩子都知道 GPU(图形处理单元)是什么了 —— 这得归功于 AI,也归功于英伟达(Nvidia),它始终在不遗余力地推进自家芯片的发展。当然,硬件既是绊脚石,也是推动模型运行及其技术栈的引擎。但为什么人们讨论的焦点只集中在 GPU 上呢?难道没有其他竞争者可能塑造 AI 硬件的未来吗?CPU 和 TPU 当然算 —— 但仅此而已吗?
今天,让我们跳出 GPU 的思维茧房,将视线拓展到 GPU、CPU、TPU 这”老三样”之外。全球开发者一直在探索各类替代设计方案,每一种都承诺带来可观的效率提升和全新的创新路径。
我们希望能各位读者打造一份完整的 AI 硬件指南,因此先从这三大巨头讲起,再转向那些虽不主流却内有乾坤的方案:例如 Cerebras WSE 和 AWS 自研的定制 ASIC;还有 APU、NPU、IPU、RPU 以及 FPGA。我们会帮你厘清这些术语,让你全面掌握 AI 硬件的完整图景。这篇文章必将让你收获满满!
01 CPU、GPU、TPU — 三种核心硬件架构
在探讨其他替代方案之前,先来剖析一下这些我们耳熟能详的 CPU、GPU 和 TPU 到底是什么。
这三大巨头都属于处理单元(Processing Units,简称 PUs) —— 即专门用于执行软件程序指令、进行计算的电子电路。许多人称它们为计算机系统的”大脑”。PUs 执行各类算术、逻辑、控制以及输入/输出操作,将原始数据处理成有用的信息。
不同类型的 PU 针对不同的工作负载进行了优化 →
1.1 中央处理单元(Central Processing Unit, CPU)
中央处理单元(CPU)专为通用计算和顺序任务执行而设计。
CPU 是三者中最古老的。其前身的故事始于 1945 年 —— 约翰·莫奇利(John Mauchly)与 J. 普雷斯珀·埃克特(J. Presper Eckert Jr.)推出了 ENIAC(Electronic Numerical Integrator and Computer)。这是世界上第一台可编程、电子式、通用型的数字计算机,能通过重新编程解决多种数值问题,使用了约 18,000 个真空管。
同年,约翰·冯·诺依曼(John von Neumann)发表了《First Draft of a Report on the EDVAC》,提出将数据和指令存储在同一内存中。这一”存储程序”模型成为现代 CPU 的设计蓝本。
到了 1950 年代中期,真空管被晶体管取代。从那时起,处理器开始由大量基于晶体管的元件组成,并安装在电路板上,使计算机变得更小、更快、更省电。
1960 年代,集成电路(ICs)出现,将多个晶体管集成到单块硅片上。最终在 1971 年,英特尔(Intel)推出了 4004 —— 全球首款商用微处理器,即一颗集成在单一芯片上的 4 位 CPU。这标志着现代 CPU 的真正诞生。
Intel 8086 是如今 x86 CPU 架构的始祖,而目前提升效率的主流方案则是多核处理器 —— 将多个 CPU 核心集成在单一芯片上。
那么,现代 CPU 内部究竟包含什么?它们又是如何工作的?
CPU 的核心是控制单元(control unit),它包含复杂的电路,通过发出电信号来控制整台计算机,并将数据和指令引导至正确的位置。算术逻辑单元(ALU)负责执行数学与逻辑运算,而寄存器(registers)和高速缓存(cache)则提供了极小但极快的存储空间,用于存放处理器频繁需要的数据。
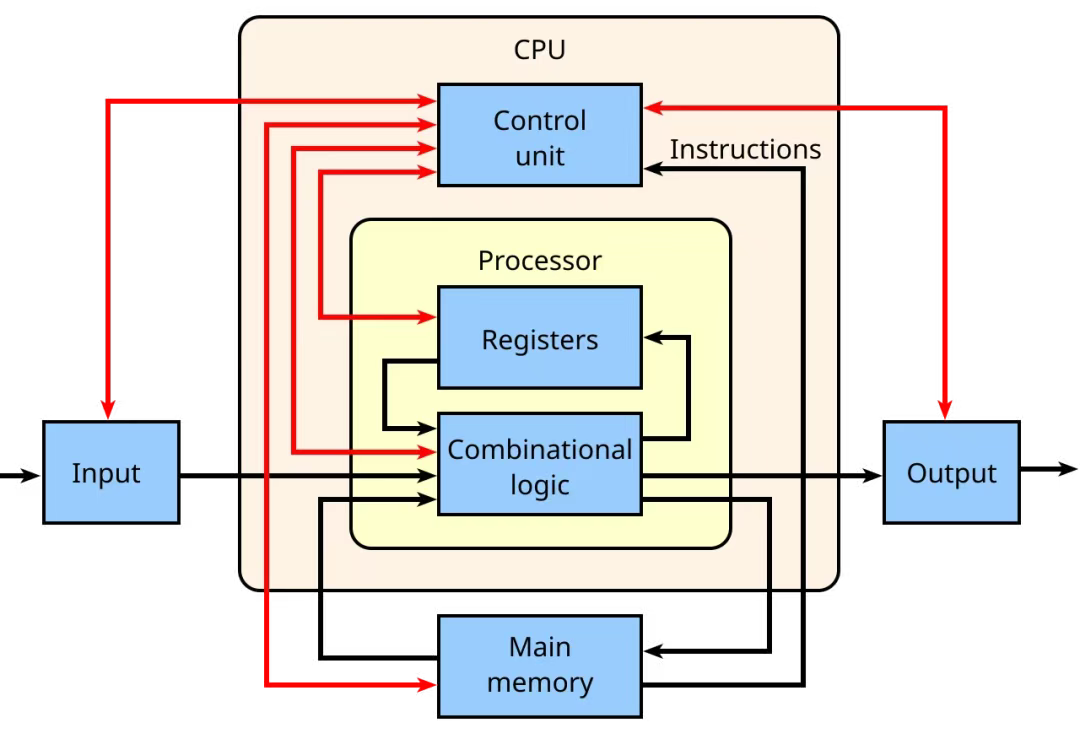
Image Credit: Wikipedia
CPU 还包含核心(cores) —— 即 CPU 内部的处理单元,每个核心都能独立处理指令;以及线程(threads),允许一个核心同时处理多条指令流。这些组件都按照时钟信号(clock)的节拍运行,时钟提供了同步整个系统所需的节拍。此外,还有总线(buses,用于数据传输)、指令寄存器(instruction register)和指令指针(instruction pointer,用于追踪下一步要执行的内容)等辅助组件,将整个系统紧密连接,使指令能顺畅地从一个步骤流转到下一个。
CPU 的工作遵循一个简单却强大的循环:取指(fetch)→ 译码(decode)→ 执行(execute) 。
- 它从内存中取指数据或指令,
- 将它们译码为硬件能理解的信号,
- 然后执行所需的操作(例如计算、数值比较,或将数据发送到其他地方)。
在现代处理器中,这一过程每秒可发生数十亿次,多个核心与线程并行工作提升性能,使 CPU 如同一个高度协同的组件团队。CPU 核心数量较少(例如 1 到 2 个)时,通常更注重能效(即单位功耗下完成更多有效工作),适合轻量或日常任务,而核心数量较多的 CPU 则用于支撑高性能、高负载的任务。
如今的 CPU 主要来自以下厂商:
- Intel,产品包括 Core 系列(消费级)、Xeon(服务器/工作站)、Pentium 和 Celeron(入门级)芯片;
- AMD,提供 Ryzen(消费级/高性能)和 EPYC(服务器)处理器,以及 APU(Accelerated Processing Unit),它将 CPU 和 GPU 集成在同一颗芯片上(我们稍后会详细讨论)。
CPU 用于 AI 时面临的主要问题是:它针对的是顺序执行的通用任务,而非大规模并行的矩阵运算,因此在速度和能效上远逊于 GPU 或专用芯片。
接下来,让我们转向介绍第二款芯片 —— 著名的 GPU。
1.2 图形处理单元(Graphics Processing Unit, GPU)
图形处理单元(GPU)专为高吞吐量的大规模并行数据处理而优化。GPU 最初被发明用于加速图像和视频中的计算机图形渲染,但后来人们发现它在非图形计算任务中同样大有用武之地。如今,GPU 被广泛应用于可并行化的工作负载,例如处理数据密集型任务和训练 AI 模型。
如今,GPU 是推动 AI 性能提升的核心力量,也是衡量 AI 计算能力的一项关键指标。
“图形处理单元”(GPU)这一术语由 NVIDIA 于 1999 年正式提出,随 GeForce 256 显卡一同发布。NVIDIA 称其为全球首款 GPU,其官方定义为:”集成变换、光照、三角形设置/裁剪及渲染引擎的单芯片处理器。”
那么,这款传奇的 GPU 究竟是如何工作的?→
GPU 内部是一块硅芯片,上面蚀刻着数十亿个微型晶体管,被组织成数千个轻量级处理核心。这些核心通过复杂的布线相互连接,并由高带宽内存和缓存提供支持,使数据能在核心之间高速流动。整个芯片被封装在保护材料中,并配有散热系统来维持稳定运行。
(了解芯片历史的最佳读物之一是克里斯·米勒(Chris Miller)所著的《芯片战争:世界最关键技术的争夺战》(Chip War: The Fight for the World’s Most Critical Technology),强烈推荐。)
与 CPU 不同,GPU 专为并行计算而生 —— 它会将一项大型任务拆分成成千上万个更小、彼此独立的子任务,并将它们分发到各个核心上同步计算。正因如此,GPU 非常适合训练和运行 AI 模型,因为这些模型涉及对海量数据集进行重复的矩阵与张量运算。得益于 GPU 的并行架构,原本需要数月的训练如今几天就能完成,推理速度也足以支撑实时应用 —— 比如聊天机器人。
全球 GPU 生产的领军者是 NVIDIA,它打造了完整的并行计算平台 CUDA(Compute Unified Device Architecture),将 GPU 硬件能力释放到通用计算领域,大幅降低了 GPU 编程的门槛。
NVIDIA 面向 AI 基础设施和行业应用的主要 GPU 产品包括:
- V100(Volta 架构) — 专为深度学习加速而设计,首次引入 Tensor Core(张量核心) —— 专用于加速 AI 训练中矩阵运算的硬件单元。
- A100(Ampere 架构) — 拥有更多 Tensor Core、更高内存带宽,并支持多实例 GPU(MIG)技术,可将一块物理 GPU 划分为多个逻辑 GPU,提升资源利用效率。
- H100、H200(Hopper 架构) — 当前 AI 领域的行业标准。H 系列支持 Transformer Engine、超大内存带宽,以及极致的训练与推理速度。
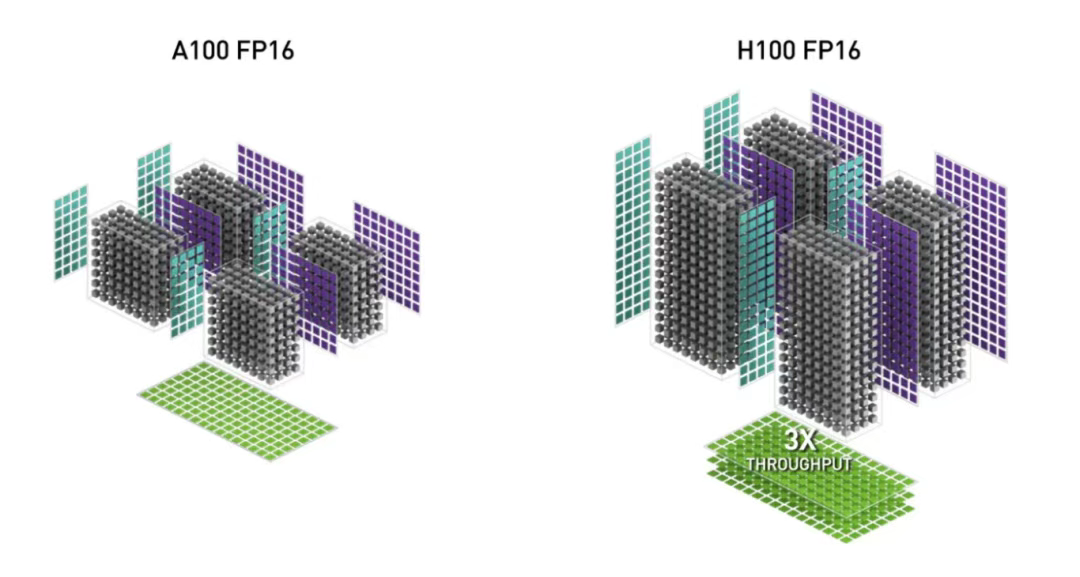
图片来源:NVIDIA H100 NVL GPU 产品文档
- Blackwell(例如 B200 和 GB200 Grace-Blackwell “超级芯片”) 专为下一代拥有数万亿甚至十万亿级参数的 AI 模型而设计。作为 Hopper 架构的继任者,它引入了 FP4 精度,并在推理吞吐量上实现了大幅提升,尤其针对超大规模 Transformer 工作负载。
随着行业对 AI 专用处理器的需求日益增长,第三类核心硬件 —— TPU 应运而生。
1.3 张量处理单元(Tensor Processing Unit, TPU)
张量处理单元(TPU)是由 Google 专为加速神经网络运算(尤其是矩阵乘法与机器学习工作流)定制的芯片。它最初在 2016 年 Google I/O 大会上亮相,属于 ASIC(Application-Specific Integrated Circuits,专用集成电路)类别。TPU 的基本架构如下:
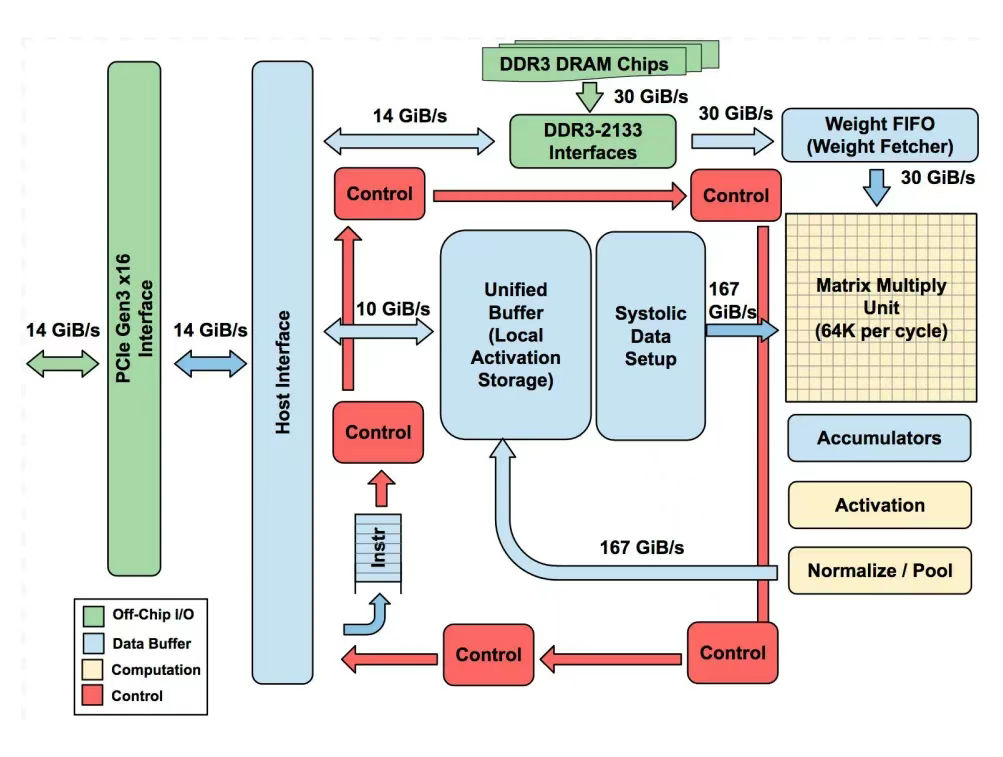
图片来源:论文《In-Datacenter Performance Analysis of a Tensor Processing Unit》
- 其核心组件是矩阵乘法单元(Matrix Multiply Unit) —— 一个巨大的 256×256 乘加单元(MAC)阵列,采用脉动阵列(systolic array)结构,数据以”波”的形式在网格中流动。
- TPU 还配备了大容量片上存储器:
-
- 统一缓冲区(Unified Buffer,24 MB):用于存放中间激活值;
- 权重存储器/ FIFO(Weight Memory/FIFOs):用于存储神经网络权重;
- 累加器(Accumulators,4 MB):用于收集求和结果。
- 控制逻辑、PCIe 接口和激活单元(用于 ReLU、sigmoid 等函数)为矩阵引擎提供支持,但芯片的大部分面积都用于原始计算和高速数据传输。
相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


