
<p>作者 | 梁尧博</p> 最近在使用SeaTunnel CDC去尝试同步Oracle MySQL SQLserver到其他关系型数据库的实时场景,通过翻看和改造SeaTunnel和debezium源码,我对SeaTunnel CDC Source端的实现有了初步的掌握。趁着熟悉,赶紧把一些问题整理出来,解决大家的一些疑问。我尽可能说得通俗一点,当然都是自己的一些个人理解,如有错误,还望指正:
- CDC的各个阶段:快照、回填、增量
- CDC的
startup.mode的timestamp底层是怎样实现的? - SeaTunnel的Checkpoint机制与CDC任务是如何联动的
- Checkpoint又超时啦!
1.CDC的各个阶段:快照、回填、增量
首先,整个CDC数据读取分为快照(全量)-》回填-》增量:
- 快照:顾名思义,就是对数据库当前的数据打一份快照,全部读过来,目前SeaTunnel的实现就是纯jdbc读取,但是在读取的时候会记录一下当前的binlog位点,比如mysql,会执行
SHOW MASTER STATUS;拿到如下信息:
File |Position |Binlog_Do_DB|Binlog_Ignore_DB|Executed_Gtid_Set|
-------------+----------+------------+----------------+-----------------+
binlog.000011|1001373553| | | |
此时把这两个信息存储下来保存为低水位线, 注意这个并不只执行一次,因为SeaTunnel为了提高性能,自主设计了切分逻辑,这块可以参考我得另一篇文章SeaTunnel 如何给 MySQL 表做“精准切片”?一篇读懂 CDC 分片黑科技: 假设全局并行度是10,那么SeaTunnel会初始化10个通道来划分任务执行,SeaTunnel第一步会先分析表的数量 然后按照主键的最大最小值去切分,默认切分行是8096,那么一个表数据量大的情况下会切分100多个块随机分布到这10个通道里(此时数据读取任务还没执行,只是一个query语句按照where条件去切分好然后存下来),所有表切分后,每个块并行执行:
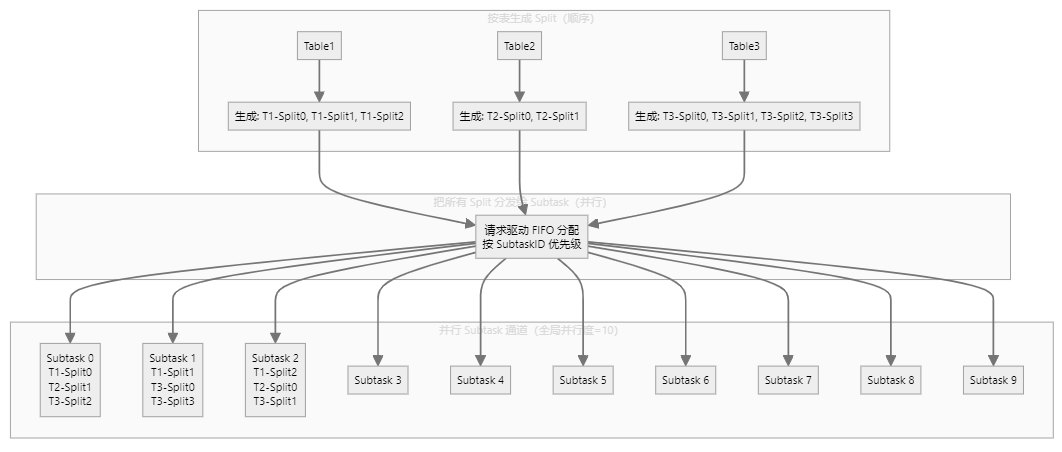
当每个块(SELECT \* FROM user\_orders WHERE order\_id \>\= 1 AND order\_id \< 10001;)开始执行的时候,会记录当前的binlog位点,当做这个块的低水位线,然后等这个块读取完了,再次执行SHOW MASTER STATUS,记录当前的位点为该块的高水位线,一个块执行完了 下个块随即执行,代码如下:
// MySqlSnapshotSplitReadTask.doExecute()
protected SnapshotResult doExecute(...) {
// ① 记录低水位线
BinlogOffset lowWatermark = currentBinlogOffset(jdbcConnection);
dispatcher.dispatchWatermarkEvent(..., lowWatermark, WatermarkKind.LOW);
// ② 读取快照数据
createDataEvents(ctx, snapshotSplit.getTableId());
// ③ 记录高水位线
BinlogOffset highWatermark = currentBinlogOffset(jdbcConnection);
dispatcher.dispatchWatermarkEvent(..., highWatermark, WatermarkKind.HIGH);
}
注意事项:尽可能把split_size设置大一点,比如10w,因为根据实践证明,切的块并不是越多越好

- 回填阶段:该阶段有两种形态,对应参数exactly_once这个参数
-
Exactly-Once = false (默认)
如果不开启,那么等所有块读完后,会对比所有块的水位线,然后拿到最小的水位线信息,开始读取数据,此时就不是jdbc读取了,而是cdc读取,比如mysql是读取binglog文件,Oracle是分析redo log文件,提取数据,根据数据类型去执行对应insert 、update、delete语句,这时候发送的每一条数据都会自带Position或者scn属性,也就是offset,每来一条 就会 和高水位线的位置信息对比,如果超过高水位线了,那么就说明要进入纯增量阶段了

-
Exactly-Once = true
如果设置exactly_once=true,对于每个块,源端不会立刻写入,而是缓存起来,同时SeaTunnel会启动一个binlog读取任务 但是设置成了有界流,开头是每个块的低水位线,结束是每个块的高水位线,把这期间从日志解析出来的数据全部缓存下来 然后每个块的数据也有缓存,根据主键进行对比,比如在快照阶段有insert,在增量阶段有update,那么对比下来只拿update后的数据就行,然后再插入到目的端,这样来保证精确一次语义,当然也比较耗内存!
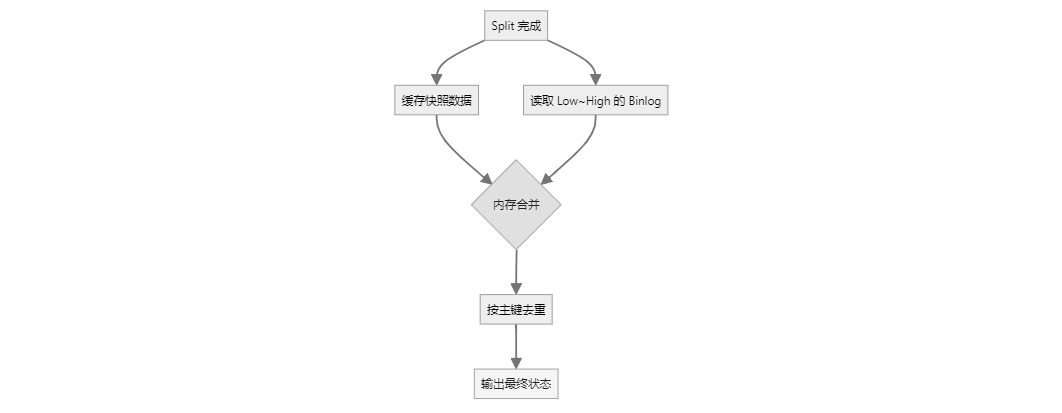
-
增量阶段: 纯日志读取
如果开启了exactly_once,那么SeaTunnel会再次启动一个无界流也就是 从高水位线开始读取数据,如果不开启的话,会直接顺着回填阶段往下走,可以说此时的回填和增量是一体的,区别就在于一个从低水位线读,一个从高水位线读
总结:
1. 两种形态
开启 exactly_once (精确一次)

-
快照:读低水位线时刻的全量数据
-
回填:补齐
[低水位线, 高水位线] 期间的变更 -
增量:高水位线之后的实时流
-
代价是:
- 需要维护更多状态(内存压力大,特别是块多/表多时)。
- 对于 Oracle 这类用 LogMiner 的源端,如果每块都要维护独立流,对业务库侵入性和延迟都显著增加。
相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


