
<p><img src="https://openwrite-whaleops.oss-cn-zhangjiakou.aliyuncs.com/2025/12/23/17664577086882.jpg" alt=""></p> 《新兴数据湖仓设计与实践手册:数据湖仓与 DataOps 开发规范(2025)》是一份面向数据工程师、数据架构师与企业数据团队的系统性实践指南,全面总结了当下湖仓一体架构在企业落地过程中的关键设计方法、开发规范与工程经验。本手册不仅覆盖项目规划、权限体系、工作流编排、ETL 与实时/离线融合开发模式,同时结合 WhaleStudio 与 Apache DolphinScheduler 的实际能力,为读者提供可在真实生产环境中直接复用的架构与流程参考。
本文为手册第三部分,重点讲解 数据湖仓工作流开发规范上,涵盖调度任务开发规范、逻辑任务开发规范、工作流配置参数、SQL脚本开发规范等,为工作流开发提供详细指南。
3.1 工作流开发规范
工作流是承载着一系列有组织的任务作业流程。它代表着一组完整的业务逻辑,每个特定的业务拆分成至少一个或多个存在依赖关系的工作流。同时,工作流也是执行调度的基本单位,工作流中的任务将通过工作流的手动执行或定时调度批量实例化。进行工作流开发时,应遵循以下规范标准:
-
工作流名称:工作流的命名应为项目下唯一,将作为导入更新或依赖引用的唯一标识。工作流的命名规范详见上一章节的介绍。
-
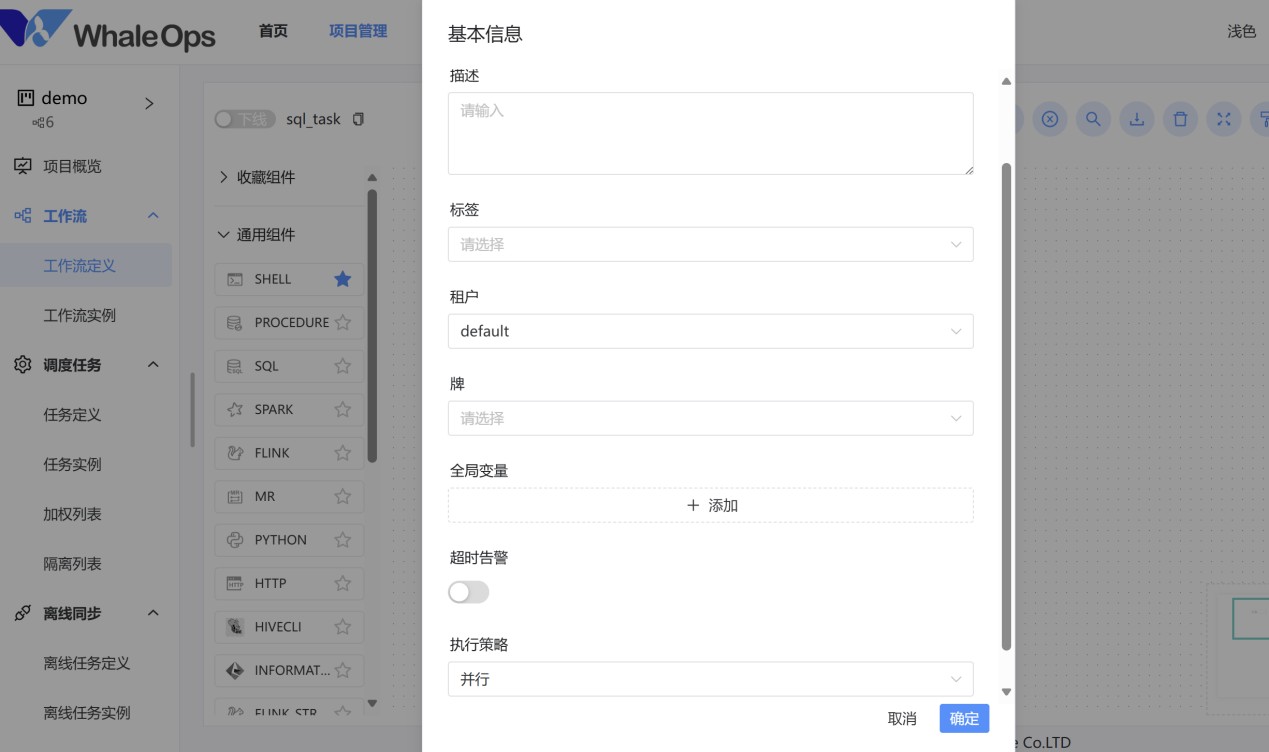
工作流的基本配置: 工作流配置一般都会点击设置,来设置标签、并行策略,超时告警等:
-
业务标签:在业务流程较为复杂的情况下,通常会拆分成多条工作流调度执行。可以通过标签或文件夹的形式进行分类标识管理。
-
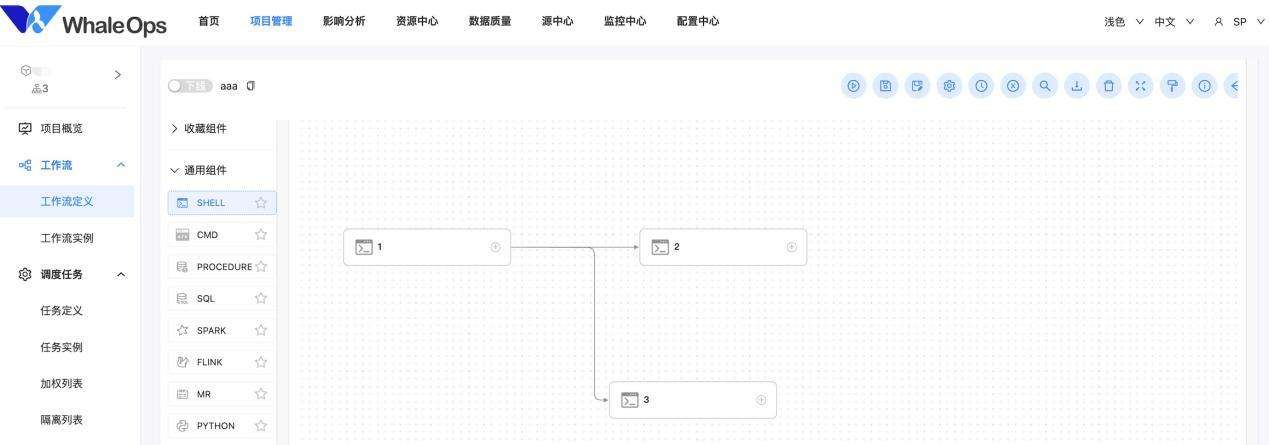
流程开发:进入工作流画布后,从左侧的任务组件栏拖拽任务至画布中以创建任务。工作流是DAG有向无环图,从起始节点根据连线按顺序向后执行,请避免节点反向连接成环。双击节点进入任务的开发,详见下一小节的介绍。
-
工作流
-
保存提交:每次完成编辑后请手动点击工作流画布右上方的保存按钮进行保存。完成开发后请使用旁边的保存并提交版本信息,在变更描述中填写详细的变更信息,尽量避免多人同时开发提交版本。
-
版本记录:工作流提交版本后可在”版本信息”的历史版本列表中切换回滚。
3.2 调度任务开发规范
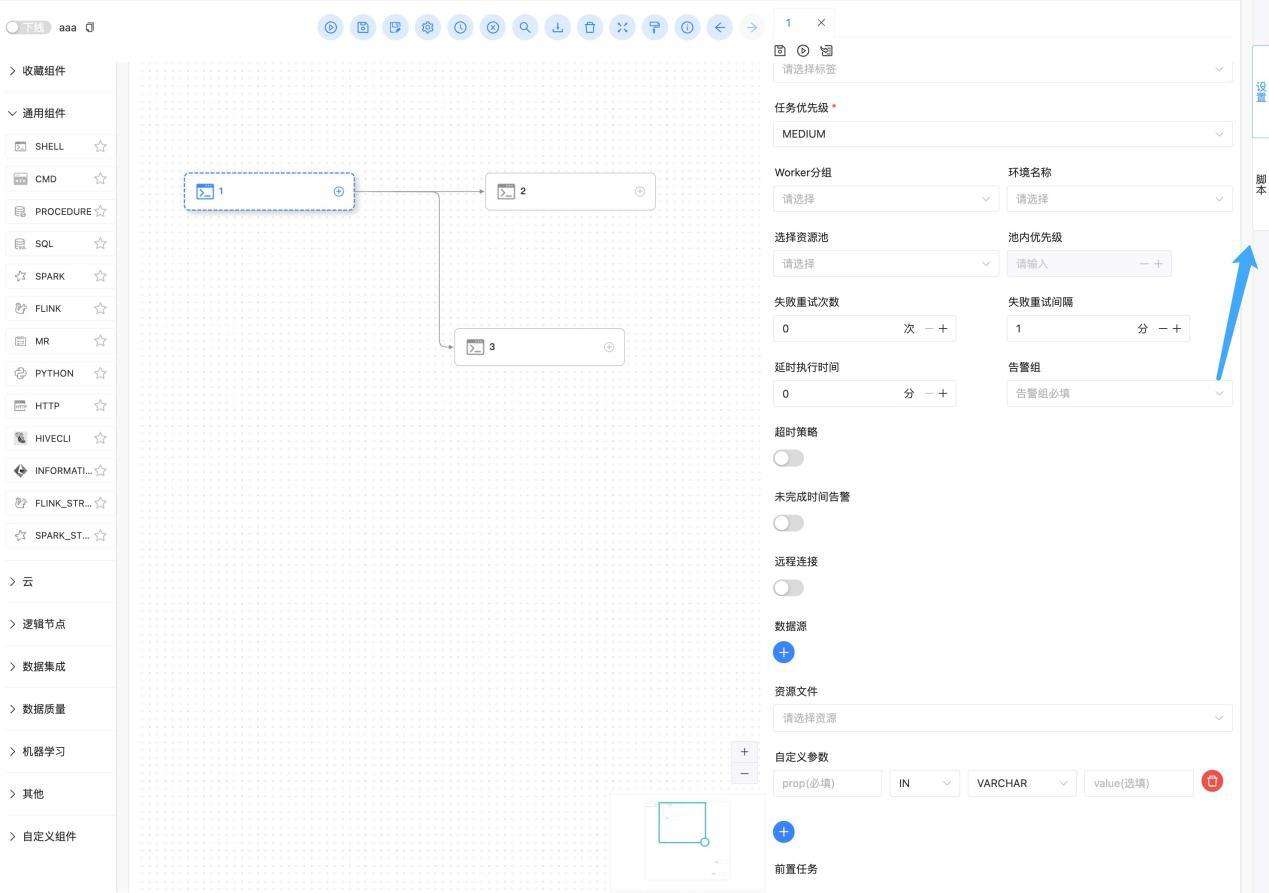
WhaleStudio 工作流中可供使用的任务组件包括Shell, Cmd, Python, Procedure, SQL, Spark, Flink, Http, Hivecli, Informatica, MR, 数据质量, DataX, Sqoop, SeaTunnel, MLflow等数十种。这些任务之间可以通过编排工作流流程前后依赖执行和变量传递。在创建任务组件时,需要对每个组件配置调度参数以及执行脚本:
-
任务名称:任务的命名应为工作流下唯一,将作为导入更新或依赖引用的唯一标识。
-
运行标志:通常情况下选择正常。当不希望当前任务节点执行失败阻断执行后续节点时,选择失败继续;当进行流程调试时无需执行当前节点可选择禁止执行,将跳过当前节点执行流程。
-
描述:描述当前任务的处理业务。
-
任务优先级:通常情况下选择优先级中。若当前任务比较重要,需要优先获得资源执行时可调整优先级为高,在流程中的前置任务已经执行完成的情况下,当前任务将会被优先派发执行。
-
Worker分组: 通常情况可以不填,默认使用工作流调度的worker分组。当前任务执行需要指定执行机器时选择,指定后任务将分配给worker组的机器机执行。需要事先在配置中心设置worker分组并授权当前项目。
-
环境:通常情况不填写。在当前任务的运行脚本需要指定特殊环境执行时设置,需要先在配置中心下的环境管理中创建环境设置,并授权给当前项目使用。
-
资源池:通常情况不设置。若业务系统对访问执行有上限要求,则需要在资源中心下的资源池管理中创建资源池,设置允许任务实例并发的最大数量,并将当前任务选择添加至该资源池中。
-
超时告警:用于监控任务执行所花费的时长是否超出预期。开启后需要设置超时的时间长度以及出现超时时的处理策略。
-
未完成时间告警:用于监控任务是否在某个具体的时间点前完成执行。当任务逾期完成时将发送告警。与超时告警不同的是,未完成时间告警是绝对时间告警,可以指定比如任务必须在调度后的当天下午17:00前完成的监控。
-
延时执行时间:通常情况无需设置。设置后,当流程执行到当前任务时,将会延时开始执行。
-
资源文件:通常可以留空,若需要在脚本中引用外部文件或脚本时设置。使用时需要事先将文件脚本在资源中心进行上传,或远程引用git仓库中的脚本文件并授权当前项目使用。
-
自定义参数:脚本中需要使用参数变量时设置,声明变量的KEY和Value。在当前任务脚本中使用变量选择IN。若需要将变量传递给后续节点选择OUT,详情请参阅使用文档中的相关章节。
至此,用户已经完成了任务的基本调度参数配置。不同的任务组件有各自专属的配置。点击右侧边栏中的脚本,进入当前任务的IDE编辑器继续设置任务脚本。
-
调试任务: 在开发的过程中,需要对任务脚本进行运行调试时,请使用任务设置顶部的调试按钮。
-
调试流程: 对流程进行调试时,可以完整调试运行整个工作流或选中局部流程调试运行,在启动参数的弹窗中运行方式配置选择调试运行。调试的实例将不会进行依赖判断和告警监控判断。
3.3 逻辑任务开发规范
工作流中提供逻辑任务组件处理依赖判断、条件检查、状态检查、嵌套流程、动态生成等流程逻辑。在调度执行中可根据其判断结果实现切换执行分支、自动暂停流程执行、循环执行流程等效果。
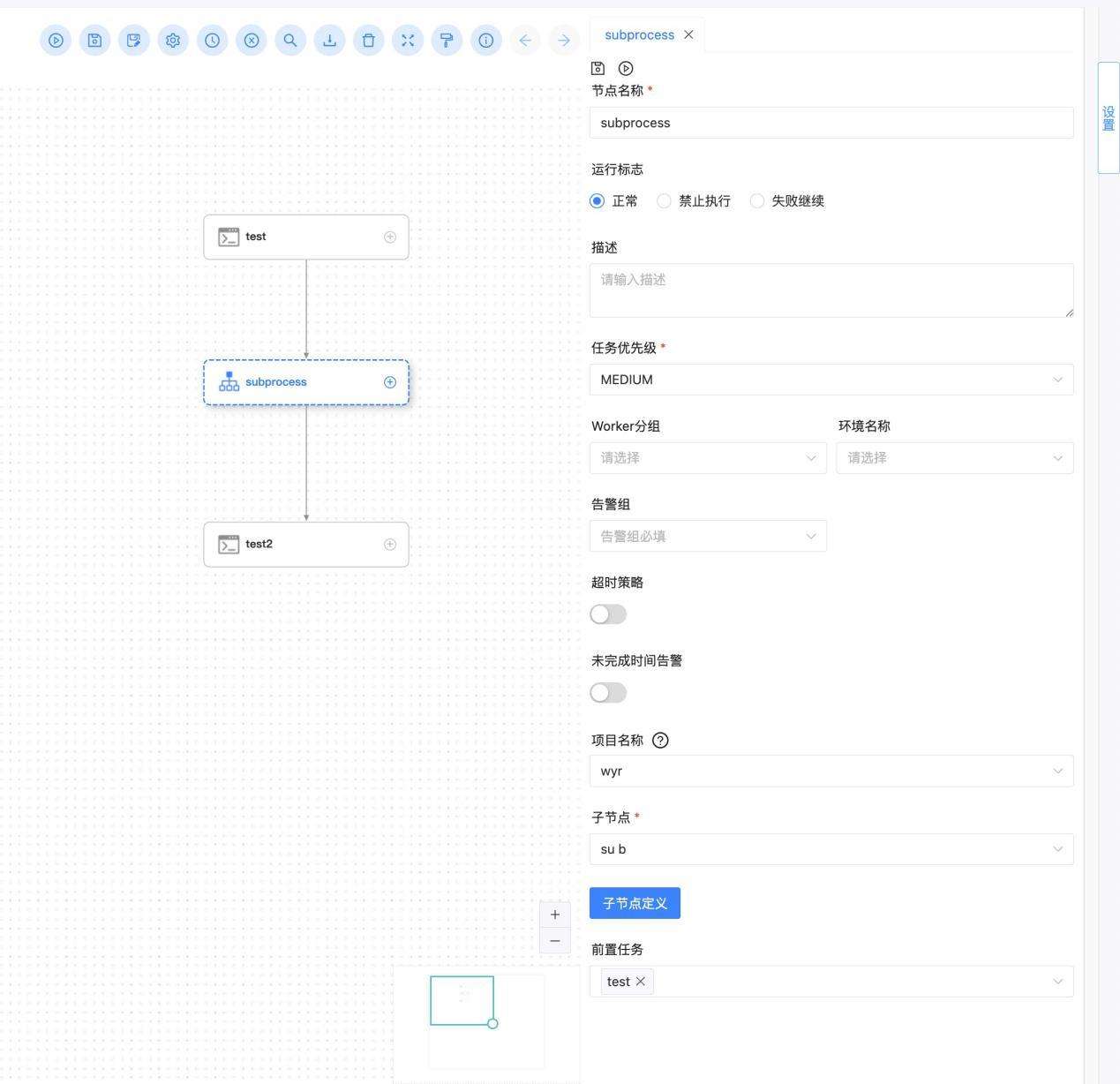
嵌套子流程
在流程中添加SUBPROCESS任务可实现当流程执行至该节点时,另外触发关联的工作流调度执行,在关联的工作流完成执行后,返回原工作流继续向后执行的效果。子流程可以选择本项目或跨项目下的任一工作流定义。子流程内允许再次嵌套子流程,将按照同样的运行逻辑执行。
依赖工作流、任务
DEPENDENT依赖任务用于检查业务上存在依赖关系的其他工作流或任务是否完成执行。在流程中添加依赖任务,当执行至该节点时就会对执行的工作流或者任务进行依赖检查,当检查到依赖对象已经完成执行后,DEPENDENT就会判断成功继续向后执行流程。在设置依赖的时候需要选择:
- 项目名称: 选择需要依赖的工作流或任务所在的项目。
- 工作流名称: 选择需要依赖的工作流或任务所在的工作流。
- 依赖全部节点: 关闭时表示是任务级依赖,可以选择指定工作流下的具体的任务进行依赖;开启时表示是工作流级依赖,依赖的工作流整体执行成功才会判断依赖成功。
- 任务名称: 任务级别依赖时,可以选择该工作流下的具体需要进行依赖的任务。
- 自然日/牌日期: 依赖的时间周期类型。自然日表示以当前工作流的执行时间为基准时间,向前查找对应的自然时间,若依赖对象有开始时间或调度时间在该时间范围内的成功实例,则判断依赖成功;牌日期表示以当前工作流的牌值(与自然日不同的业务日期)为基准时间,向前在业务日历上查找对应的日期,可以跳过如节假日的自然日,若依赖对象有在该业务日期下的成功实例,则判断依赖成功。牌属于进阶功能,关于牌的使用说明请查阅使用手册。初次使用可尝试选择自然日,时间周期选择当天或昨天熟悉功能。
- 时间周期:提供小时、日、周、月维度的周期维度。今天表示T-0;昨天表示T-1;上周表示T所在的周-1的上周全部7天;上月末表示T所在的月份-1的最后一天;更多时间周期的说明可以查阅使用手册。
- ‘与、或’组合: 支持设置 {A&B OR B&C} OR D&E的多组之间的依赖条件组合模式。
事件监控触发
TRIGGER任务监听文件、消息、数据是否到达,当监听对象到达时触发后续流程执行。监听文件时填写具体的文件路径,开启切换租户后选择远程连接可以监听远程服务器的文件,需要在源中心先配置SSH连接远程服务器并授权当前项目;监听KAFKA消息时填写消息服务器和TOPIC相关信息;监听数据时需要配置对,象所在的数据库表以及SQL脚本,也需要在源中心先配置数据源的连接实例。
自动暂停流程(进阶功能)
当流程中的部分业务执行需要进行外部审批时,可以在流程中穿插BREAKING任务节点。当流程执行至该节点时将自动暂停工作流,并发送中断流程的告警通知。
状态条件判断(进阶功能)
CONDITION任务用于针对流程中的任务,根据其运行状态判断切换不同的下游分支执行。
-
设置前置检查条件:选择用于检查的任务和其预期状态。可以设置’与、或’组合条件,如 任务1(成功)&任务2(成功)或任务3(成功)&任务4(成功),当任务1和任务2成功时,或者任务3和任务4成功时,将判断成功,走成功分支。
-
分支流转:判断成功或失败时执行的下游分支任务。
条件判断(进阶功能)
SWITCH任务用于执行判断条件脚本,根据当次的条件脚本执行结果判断切换不同的下游分支执行,若没有条件符合时,则会运行默认分支。请使用javax.script.ScriptEngine.eval 执行表达式填写判断条件。
动态生成实例(进阶功能)
如果您需要循环执行某个任务或某一段业务流程,每次循环需要传入不同的参数变量,那么可以使用DYNAMIC动态任务组件。Dynamic动态节点支持通过输入一组或多组的数值、数组、上游传递的参数,根据设置好的任务脚本,动态的生成”一个” 或 “多个task的组合”实例。
- 取值参数:每次循环取值传入的参数,可以设置多组。每次循环时将从多组取值参数中分别取值传入,直至将所有的变量组合传入循环流程中。
- 过滤条件:可以留空,设置后当取值的变量值命中过滤条件时,该次将不会生成循环实例。
- 并行度:同时可以运行多少个动态循环实例。
- 循环上限:最多可以运行多少个动态循环实例。
翻牌更换业务日期(进阶功能)
NEXT LOOP任务的效果是将指定的牌值(业务时间)翻至下一个牌值(业务时间),即翻牌节点执行后,会触发调度的业务日期的变更。关于牌的更多使用说明,可以参阅查询使用手册。
3.4 工作流配置参数
完成任务开发后,您可以通过直接运行、调度运行和API触发的方式实例化工作流。一个工作流定义可以同时生成多个工作流实例而工作流实例之间互不影响,可以单独进行运行维护和修改。WhaleScheduler的工作流版本管理,允许用户随时回退任一版本执行作业。
手动执行
在开发完成工作流和任务后,用户可以点击画布上或工作流定义列表中的立即运行工作流。在进行手动执行时,一般需要进行设置:
- 运行方式: 选择直接运行。正式运行请选择直接运行。调试请选择调试运行。
- 失败策略: 默认为失败继续,即当流程中出现失败任务时其他分支的任务继续执行;选择结束表示出现失败任务时工作流立即结束运行。
- 通知策略: 当工作流和任务执行成功或失败是否发送告警。
- 告警组: 指定通知发送的告警组,需要事先在配置中心先创建告警实例并将其添加至告警组。使用前请先将告警组授权给当前项目。
- Worker分组: 可以直接使用默认分组。也可以为当次执行指定一个Worker机器组。
- 流程优先级: 通常使用默认优先级中。修改工作流优先级为高后,当 master 线程数不足时,级别高的流程在执行队列中会优先执行,相同优先级的流程按照先进先出的顺序执行。
- 环境: 一般可以留空。当工作流中任务需要在特殊环境上执行时需要配置。需要事先在配置中心的环境管理下配置环境策略,授权当前项目使用。
- 是否补数: 本次执行是否进行补数据,直接运行时请忽略此项。
- 启动参数: 一般无需修改。本次启动的全局参数的计算值,可以手动修改。
- 是否空跑: 一般选择否。选择是后,所有的任务都不会真正执行。
- 忽略依赖: 一般选择关闭。开启后,工作流中所有的依赖节点都不会真正进行依赖判断。
定时调度
为工作流设置定时调度,需要先进行定时的参数配置,再将定时策略与工作流进行绑定。完成绑定定时策略操作后,请将工作流进行上线。工作流上线后将在指定时间进行自动调度。请跟随以下操作步骤进行设置:
第一步:设置定时日历
在配置中心的日历管理中创建用于定时的调度工作日历:
- 日历类型: 选择默认执行即可。选择执行表示仅在所选日期内执行,其余日期不执行;选择不执行表示在所选日期内不执行,其余日期则执行。
- 日历名称:为日历指定名称作为唯一标识符。
- 日历描述: 一般填写日历的业务说明。
- 选择日期: 在日历上勾选调度日期。
完成日历配置后,需要将该日历授权给当前项目。
第二步:设置定时策略
同样在配置中心的定时管理中,使用刚才的定时日历创建定时策略。若为每天定时调度,可以不创建日历。
-
定时名称: 为定时策略指定一个名称,作为唯一标识符。
-
起止时间: 请选择一个时间范围,表示定时策略的生效的开始结束时间。超出生效时间时定时不会自动调度。
-
日历: 选择刚才创建的定时日历。
-
日切时间: 一般不需要设置。可以更换每日自然切日时间从00:00修改为另一个指定的时间点。
-
定时设置: 设置定时的Cron表达式。定时的设置维度分为秒、分、时、天、月、年维度。以每天23:00:00的调度作业为例,年设置每年,月设置每月,天维度设置每天,时维度设置具体小时数23,分维度设置具体分钟数0,秒维度设置具体秒数0。
完成配置后,可预览查看定时的效果是否符合预期。同样需要将该定时授权给当前项目。
第三步:为工作流绑定定时
完成定时的策略配置后,返回项目管理下的工作流定义,为完成开发的工作流绑定定时策略。
-
打开定时设置: 在工作流定义列表中,点击定时,为当前工作流指定刚才的定时调度策略。
-
失败策略: 默认为失败继续,即当流程中出现失败任务时其他分支的任务继续执行;选择结束表示出现失败任务时工作流立即结束运行。
-
通知策略: 当工作流和任务执行成功或失败是否发送告警。
-
告警组: 指定通知发送的告警组,需要事先在配置中心先创建告警实例并将其添加至告警组。使用前请先将告警组授权给当前项目。
-
Worker分组: 可以直接使用默认分组。也可以为当前工作流中的任务执行指定一个执行的Worker机器组。
-
流程优先级: 通常使用默认优先级中。修改工作流优先级为高后,当 master 线程数不足时,级别高的流程在执行队列中会优先执行,相同优先级的流程按照先进先出的顺序执行。
-
环境: 一般可以留空。当工作流中任务需要在特殊环境上执行时需要配置。需要事先在配置中心的环境管理下配置环境策略,授权当前项目使用。
-
定时: 选择刚才设置的定时策略。
-
未完成时间告警:用于监控工作流是否在某个具体的时间点前完成执行。当工作流逾期完成时将发送告警。如隔天1:00:00前必须完成指定的工作流可以设置跨1天1:00:00。
第四步:上线工作流等待调度
完成定时配置后,将当前工作流进行上线。工作流上线后将会在指定时间进行自动调度。
补数运行
补数执行可以高效的进行大批量的数据回填作业。在立即运行的参数配置页面,勾选补数开启补数模式。工作流将根据补数策略生成对应的调度实例进行数据回填。您可以灵活的控制补数的并发量,通过补数策略中的串行补数或并行补数模式,在短时间完成多天的回填任务。
-
开始补数: 在工作流定义或者定义画布中的运行按钮,在启动运行弹窗中勾选补数。
-
执行方式: 默认串行执行,表示将根据数据日期从前往后依次生成多条补数实例;选择并行表示可以同时生成多条实例。
-
并行度: 选择并行执行时需要设置。
-
数据日期: 选择需要进行补数的数据日期。
完成设置后将根据所选的数据日期从开始到结束依次生成补数实例。
3.5 SQL脚本开发规范
在选择SQL任务的时候,首先应该配置资源池,避免高并发对数据仓库有不必要的压力,然后再选择合适的数据连接,如果是多条SQL,有注释的情况,可以勾选相关选择。建议清空表的操作可以在前置SQL中使用,这样重试的时候不会清空表,如果需要每次重试都清空表,那么就在SQL中书写。如果需要把SQL的结果以邮件形式发出来,可以选择发送邮件。
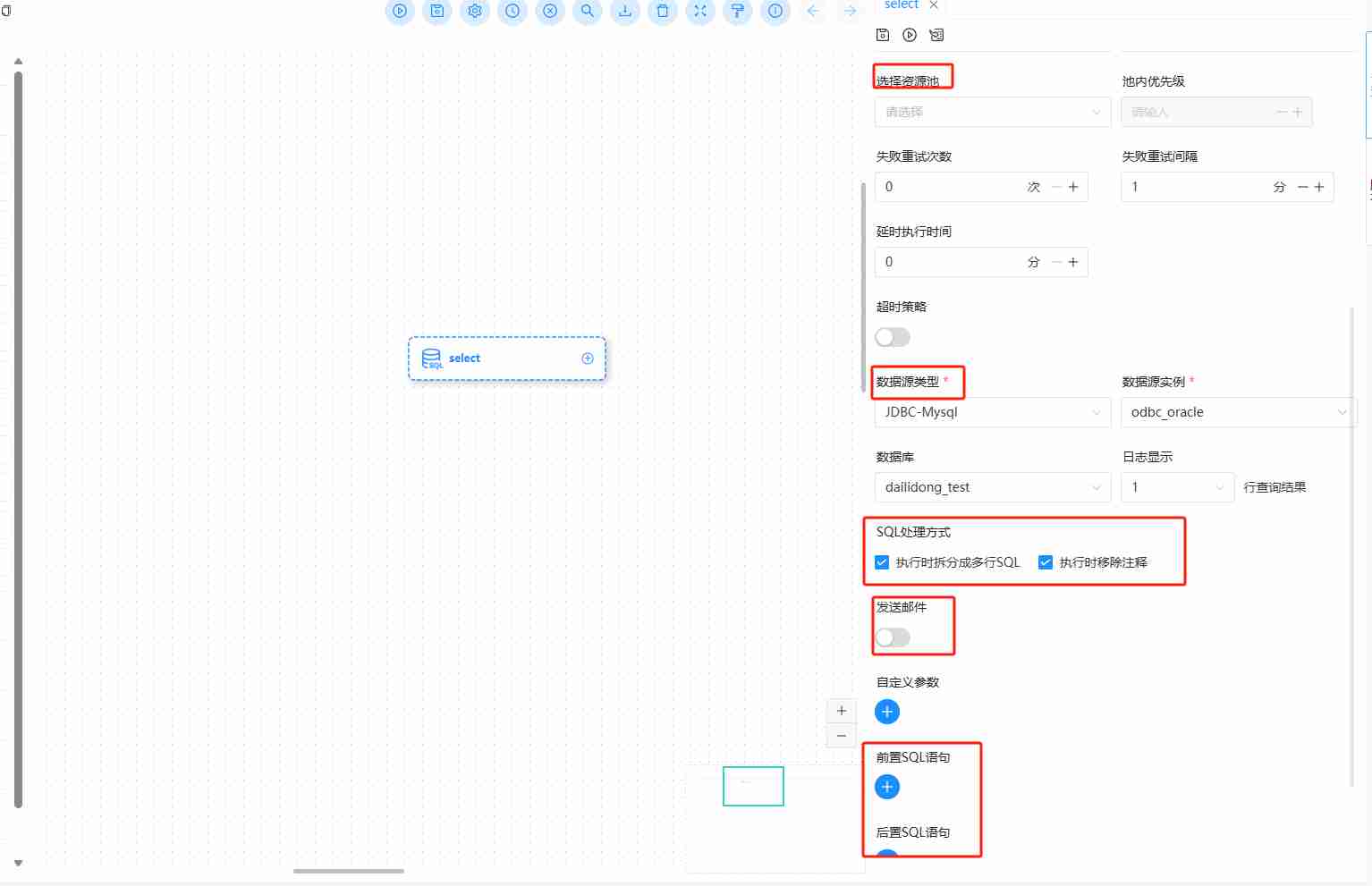
具体SQL脚本规范如下:
1. 注释规范
-
文件头部注释
-
脚本名称
-
创建日期
-
作者姓名
-
数据处理目的
-
来源表及目标表
-
运行环境(如MySQL版本)
-
修改历史
-
-
脚本内注释
-
重要逻辑和复杂SQL段落需添加行内注释
-
每个步骤前须说明其功能
-
参数化配置部分需清晰描述用途
-
2. 命名规范
-
表别名
-
简洁明了,使用表名的前几个字母。
-
避免单字母(如 a、b),除非特殊情况。
-
-
列别名
- 清晰表达列含义,尽量避免重名。
-
变量与参数
- 使用全小写字母,单词之间用下划线分隔(如 start_date)。
3. 脚本书写规范
-
语法规范
-
关键字全部大写(如 SELECT、FROM)。
-
保持缩进整齐,嵌套查询需每层缩进。
-
-
安全性规范
-
使用事务控制(START TRANSACTION / COMMIT)。
-
禁止直接删除数据表(如 DROP TABLE)。
-
涉及删除或更新数据时,应先备份。
-
-
性能优化
-
避免使用 SELECT *,明确指定需要的字段。
-
优化索引使用,避免全表扫描。
-
例如如下案例,这样未来识别SQL的来源和目标会更加清晰:
\-- 脚本名称: monthly_sales_summary.sql
\-- 创建日期: 2024-11-24
\-- 作者: 张三
\-- 数据处理目标: 汇总月度销售数据,包括订单数量和总金额。
\-- 来源表: sales_order, product_info, customer_info
\-- 目标表: monthly_sales_summary
\-- 运行环境: MySQL 8.0
\-- 修改历史:
\-- 2024-11-24: 初始版本
\-- 开始事务
START TRANSACTION;
\-- Step 1: 删除目标表中当月数据,避免重复插入
\--来源表:monthly_sales_summary
DELETE FROM monthly_sales_summary
WHERE sales_month = DATE_FORMAT(CURDATE(), \'%Y-%m\');
\-- Step 2: 汇总销售数据并插入到目标表
\--来源表:sales_order, product_info, customer_info
INSERT INTO monthly_sales_summary (
sales_month,
product_category,
customer_region,
total_sales,
total_revenue
)
SELECT
DATE_FORMAT(o.order_date, \'%Y-%m\') AS sales_month, \-- 订单月份
p.product_category, \-- 产品分类
c.customer_region, \-- 客户区域
COUNT(o.order_id) AS total_sales, \-- 销售数量
SUM(o.order_amount) AS total_revenue \-- 销售收入
FROM
sales_order o \--来源表:订单信息
JOIN
product_info p ON o.product_id = p.product_id \--来源表:产品信息
JOIN
customer_info c ON o.customer_id = c.customer_id \--来源表:客户信息
WHERE
o.order_status = \'COMPLETED\' \-- 只统计已完成订单
AND o.order_date \>= DATE_FORMAT(CURDATE(), \'%Y-%m-01\') \-- 本月起始
AND o.order_date \< LAST_DAY(CURDATE()) + INTERVAL 1 DAY \-- 本月结束
GROUP BY
p.product_category, c.customer_region;
\-- 提交事务
COMMIT;
下篇预告:数据集成任务开发规范
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


