编辑|Panda
刚刚,OpenAI CEO 山姆・奥特曼发了一条推文:「从下周开始的接下来一个月,我们将会发布很多与 Codex 相关的激动人心的东西。」他尤其强调了网络安全这个主题。

当然,和奥特曼的很多推文一样,这条推文也收获了网友的各式各样的评论:

似乎是响应奥特曼的 Codex 发布预告,OpenAI 官方也发布了一篇技术博客,以「 揭秘 Codex 智能体 循环 」为题,深入揭秘了 Codex CLI 的核心架构 —— 智能体循环(Agent Loop)。

博客地址:https://openai.com/index/unrolling-the-codex-agent-loop/
具体来说,其中详细介绍了它如何通过 Responses API 协调用户指令、模型推理与本地工具执行(如 Shell 命令),并重点阐述了通过保持「提示词前缀一致」来触发缓存优化性能,以及利用自动压缩技术管理上下文窗口,从而在保证数据隐私(ZDR)的前提下,实现安全、高效的自动化软件开发。
下面我们就来详细看看这篇博客的内容。
揭秘 Codex 智能体循环
Codex CLI 是 OpenAI 的跨平台本地软件智能体,可以生成相当高质量的软件变更。
OpenAI 表示:「自今年 4 月首次发布 CLI 以来,我们在构建世界级软件智能体方面积累了大量经验。」
为了分享这些见解,OpenAI 推出了这个系列博客,本文即是第一篇。
在这个系列中,OpenAI 将探讨 Codex 的工作原理以及那些来之不易的教训。(如果您想更深入地了解 Codex CLI 的构建细节,请查看 OpenAI 的开源仓库:。OpenAI 的许多设计决策细节都记录在 GitHub 的 Issue 和 Pull Request 中。
仓库地址:https://github.com/openai/codex
第一篇,OpenAI 将聚焦于 智能体循环(Agent Loop) 。
这是 Codex CLI 的核心逻辑,负责协调用户、模型以及模型为执行软件任务而调用的工具之间的交互。
OpenAI 表示:「我们希望这篇文章能让您清晰地看到 OpenAI 的智能体(harness)在利用 LLM 时所扮演的角色。
在开始之前,先简要说明一下术语:在 OpenAI,「Codex」涵盖了一系列软件智能体产品,包括 Codex CLI、Codex Cloud 和 Codex VS Code 扩展。本文重点讨论 Codex Harness,它提供了支持所有 Codex 体验的核心智能体循环和执行逻辑,并通过 Codex CLI 呈现。为了方便起见,下文中将交替使用「Codex」和「Codex CLI」。
智能体循环
每个 AI 智能体的核心都是所谓的「智能体循环」。智能体循环的简化图示如下:
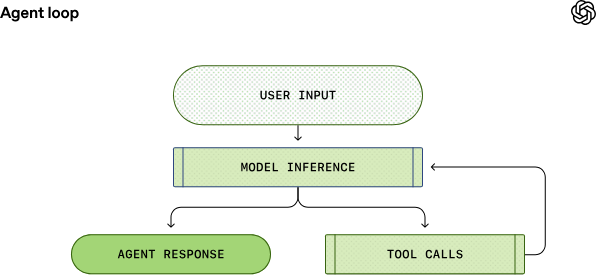
输入 :智能体获取用户的输入,并将其整合到为模型准备的一组文本指令中,这被称为提示词。
推理(Inference) :下一步是查询模型。OpenAI 将指令发送给模型并请求其生成回复。在推理过程中,文本提示词首先被转化为一系列输入 Token(映射到模型词汇表的整数)。这些 Token 被用来对模型进行采样,生成新的输出 Token 序列。
解码 :输出 Token 被转换回文本,成为模型的回复。由于 Token 是增量生成的,这种转换可以随着模型的运行同步进行,这就是为什么许多 LLM 应用会显示流式输出。在实践中,推理通常被封装在处理文本的 API 之后,隐藏了 Token 化的细节。
决策 :作为推理步骤的结果,模型要么 (1) 针对用户的原始输入生成最终回复,要么 (2) 请求 工具调用(Tool Call)(例如,「运行 ls 并报告输出」)。
执行与重试 :在情况 (2) 下,智能体执行工具调用并将输出附加到原始提示词中。该输出用于生成新的输入以重新查询模型;智能体随后可以考虑这些新信息并再次尝试。
这个过程会一直重复,直到模型停止发出工具调用,而是为用户生成一条消息(在 OpenAI 模型中称为助手消息 / Assistant Message)。在许多情况下,这条消息会直接回答用户的原始请求,但也可能是对用户的一个后续提问。
由于智能体可以执行修改本地环境的工具调用,其「输出」并不局限于助手消息。在很多情况下,软件智能体的主要输出是它在您机器上编写或编辑的代码。尽管如此,每个轮次(Turn)总是以助手消息结束(例如「我已经添加了你要求的 architecture.md」),这标志着智能体循环的终止状态。从智能体的角度来看,它的工作已经完成,控制权交还给用户。
图中所示的从「用户输入」到「智能体回复」的过程被称为对话的一个轮次(Turn)(在 Codex 中称为 Thread)。一个对话轮次可以包含模型推理和工具调用之间的多次迭代。每当您向现有对话发送新消息时,对话历史记录都会作为新轮次提示词的一部分,其中包括之前轮次的消息和工具调用。
这意味着随着对话的进行,用于模型采样的提示词长度也会增加。
长度非常重要,因为每个模型都有上下文窗口,即单次推理调用中可以使用的最大 Token 数(包括输入和输出)。你可以想象,智能体在一个轮次中可能会决定进行数百次工具调用,从而耗尽上下文窗口。
因此, 上下文 窗口 管理 是智能体的众多职责之一。
现在,让我们深入了解 Codex 是如何运行智能体循环的。
模型推理
Codex CLI 通过向 Responses API 发送 HTTP 请求来运行模型推理。OpenAI 将检查信息如何流经 Codex,并利用 Responses API 驱动智能体循环。
Codex CLI 使用的 Responses API 端点是可配置的,因此它可以与任何实现了 Responses API 的端点配合使用:
使用 ChatGPT 登录 Codex CLI 时,端点为 https://chatgpt.com/backend-api/codex/responses 。
使用 OpenAI 托管模型的 API 密钥认证时,端点为 https://api.openai.com/v1/responses 。
运行 codex –oss 以配合 ollama 或 LM Studio 使用 gpt-oss 时,默认指向本地运行的 http://localhost:11434/v1/responses 。
也可以配合云服务商(如 Azure)托管的 Responses API 使用。
接下来,让我们探索 Codex 如何为对话中的第一次推理调用创建提示词。
构建初始提示词
作为终端用户,你在查询 Responses API 时并不会逐字指定用于采样的提示词。相反,你会在查询中指定各种输入类型,而 Responses API 服务器决定如何将这些信息结构化为模型设计的提示词。你可以将提示词看作一个「项目列表」。
在初始提示词中,列表中的每个项目都关联一个角色(Role)。角色指示了相关内容的权重,取值如下(优先级从高到低):system(系统)、developer(开发者)、user(用户)、assistant(助手)。
Responses API 接收包含多个参数的 JSON 负载。OpenAI 重点关注这三个:
instructions :插入模型上下文的系统(或开发者)消息。
tools :模型在生成回复时可能调用的工具列表。
input :输入给模型的文本、图像或文件列表。
在 Codex 中,instructions 字段读取自~/.codex/config.toml;否则使用模型自带的 base_instructions(例如 gpt-5.2-codex_prompt.md)。
tools 字段是符合 Responses API 架构的工具定义列表。对于 Codex,这包括 CLI 提供的工具、API 提供的工具以及用户通过 MCP(模型上下文协议) 服务器提供的工具。
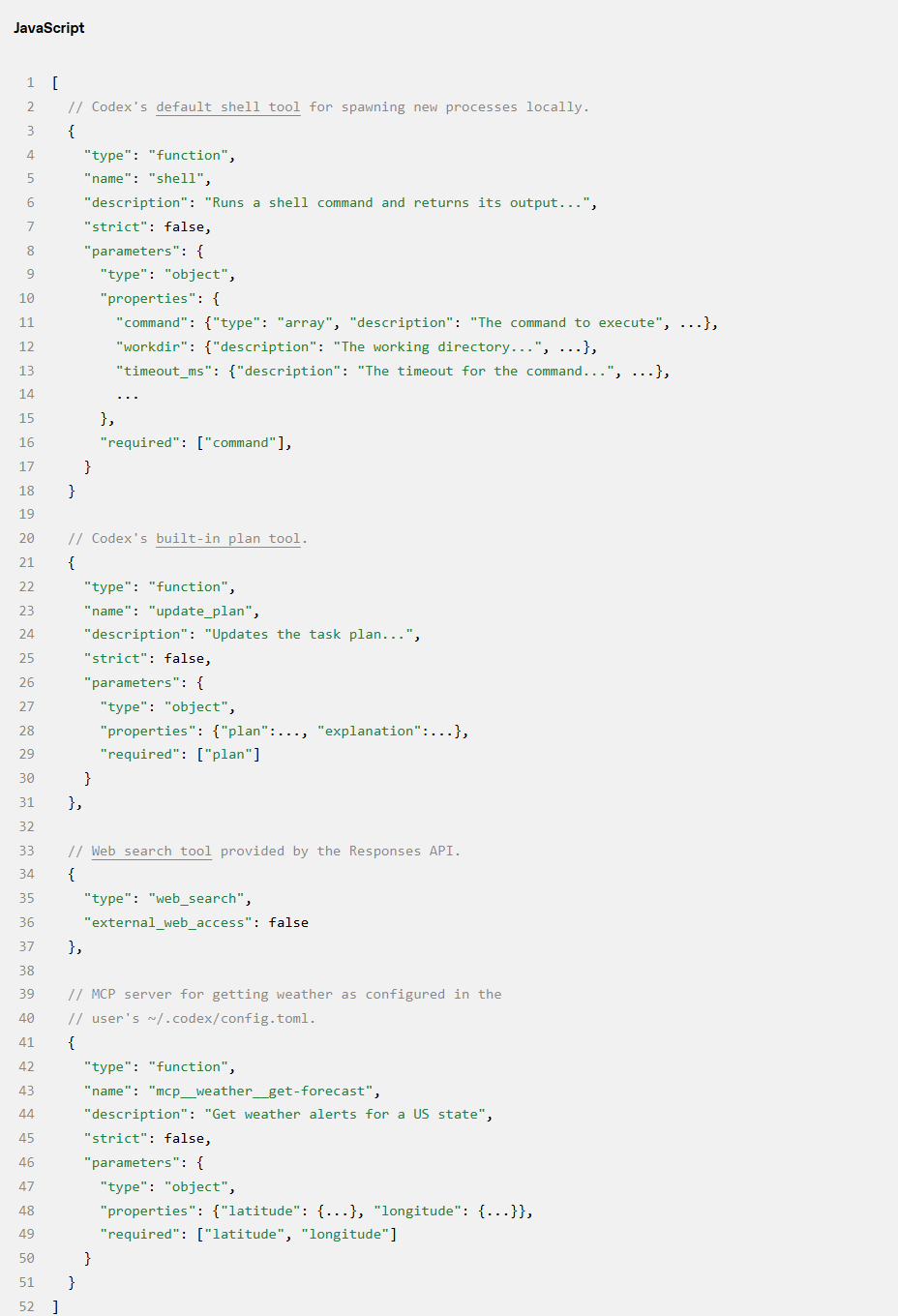
最后,JSON 负载的 input 字段是一个项目列表。Codex 在添加用户消息之前,会在 input 中插入以下项目:
1. 一条 role=developer 的消息,描述仅适用于 tools 部分定义的 Codex 提供之 shell 工具的沙箱环境。也就是说,其他工具(如 MCP 服务器提供的工具)不受 Codex 沙箱限制,需自行负责执行安全准则。该消息是根据模板构建的,其中关键内容来自捆绑在 Codex CLI 中的 Markdown 片段,如 workspace_write.md 和 on_request.md:

2.(可选)一条 role=developer 的消息,其内容是从用户的 config.toml 文件中读取的 developer_instructions 值。
3.(可选)一条 role=user 的消息,其内容是「用户指令(User Instructions)」,这些指令并非来源于单一文件,而是从多个来源汇总而来的。通常,更具体的指令会出现在后面:
$CODEX_HOME 中 AGENTS.override.md 和 AGENTS.md 的内容。
受限于一定大小(默认为 32 KiB),在从当前工作目录(CWD)的 Git / 项目根目录到 CWD 自身的每个文件夹中查找:添加任何 AGENTS.override.md、AGENTS.md 或 config.toml 中 project_doc_fallback_filenames 指定的文件内容。
如果配置了任何 Skills:关于 Skill 的简短序言、每个 Skill 的元数据、关于如何使用 Skill 的章节
4. 一条 role=user 的消息,描述智能体当前运行的本地环境。这指定了当前工作目录和用户的 Shell:
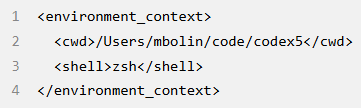
一旦 Codex 完成上述所有初始化输入的计算,它就会附加用户消息以开始对话。
之前的例子集中在每条消息的内容上,但请注意,input 的每个元素都是一个具有 type、role 和 content 的 JSON 对象,如下所示:

一旦 Codex 构建好发送给 Responses API 的完整 JSON 负载,它就会发出带有 Authorization 标头的 HTTP POST 请求,该标头取决于~/.codex/config.toml 中 Responses API 端点的配置方式(如果指定了额外的 HTTP 标头和查询参数,也会一并添加)。
当 OpenAI Responses API 服务器收到请求时,它会使用 JSON 按如下方式推导出模型的提示词(当然,自定义的 Responses API 实现可能会有不同的选择):
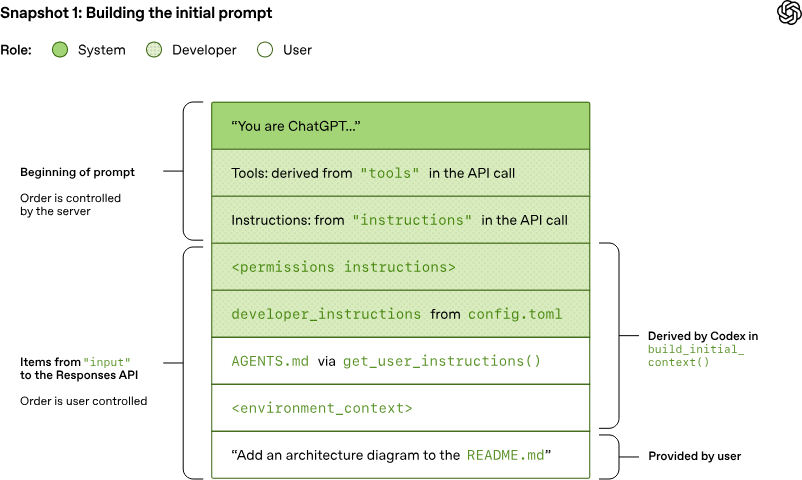
如你所见,提示词中前三项的顺序是由服务器而非客户端决定的。即便如此,在这三项中,只有 system 消息的内容也受服务器控制,因为 tools 和 instructions 是由客户端决定的。紧随其后的是来自 JSON 负载的 input 以完成提示词。
既然有了提示词,OpenAI 就可以开始采样模型了。
第一轮对话
对 Responses API 的这个 HTTP 请求启动了 Codex 对话的第一个「轮次」。服务器以服务器发送事件(SSE)流的形式进行回复。每个事件的数据都是一个 JSON 负载,其 type 以 response 开头,可能类似于这样(事件的完整列表可以在 OpenAI 的 API 文档中找到):

Codex 消费这些事件流,并将它们重新发布为可供客户端使用的内部事件对象。像 response.output_text.delta 这样的事件用于支持 UI 中的流式显示,而像 response.output_item.added 这样的事件则被转换为对象,附加到后续 Responses API 调用的 input 中。
假设对 Responses API 的第一个请求包含了两个 response.output_item.done 事件:一个类型为 reasoning(推理),一个类型为 function_call(函数调用)。当 OpenAI 再次使用工具调用的结果查询模型时,这些事件必须体现在 JSON 的 input 字段中:

在随后的查询中,用于采样模型的提示词将如下所示:
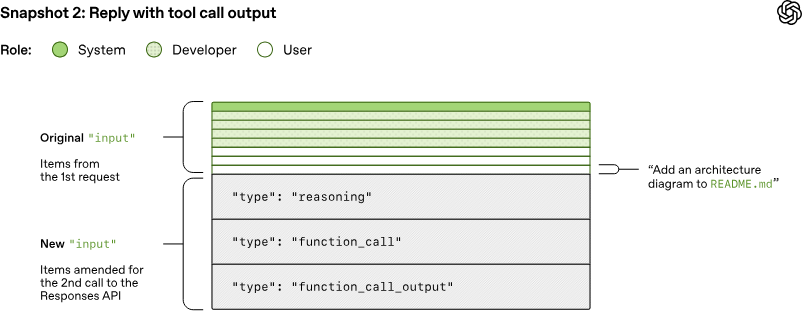
特别要注意的是,旧提示词是新提示词的精确前缀。这是有意为之的,因为这使得后续请求更加高效,因为它使 OpenAI 能够利用 提示词缓存(Prompt Caching) (OpenAI 将在下一节关于性能的内容中讨论)。
回顾 OpenAI 的第一张智能体循环图,OpenAI 看到在推理和工具调用之间可能存在多次迭代。提示词可能会持续增长,直到 OpenAI 最终收到一条 Assistant 消息,表明该轮次结束:

在 Codex CLI 中,OpenAI 将 Assistant 消息呈现给用户,并聚焦编辑器以向用户表明轮到他们继续对话了。如果用户回复,则前一轮的 Assistant 消息以及用户的新消息都必须附加到 Responses API 请求的 input 中,以开始新轮次:

再一次,由于 OpenAI 正在继续对话,OpenAI 发送给 Responses API 的输入长度会不断增加:

让 OpenAI 来看看这种不断增长的提示词对性能意味着什么。
性能考虑
你可能会问自己:「等等, 智能体循环在对话过程中发送给 Responses API 的 JSON 量难道不是呈二次方增长吗? 」
确实如此,虽然 Responses API 确实支持一个可选的 previous_response_id 参数来缓解这个问题,但 Codex 目前并未使用它,主要是为了保持请求完全无状态,并支持零数据保留(ZDR)配置。
避免使用 previous_response_id 简化了 Responses API 提供者的工作,因为它确保了每个请求都是无状态的。这也使得支持选择零数据保留(ZDR)的客户变得简单,因为存储支持 previous_response_id 所需的数据会与 ZDR 冲突。请注意,ZDR 客户并不会失去从前几轮的专有推理消息中受益的能力,因为相关的 encrypted_content 可以在服务器上解密。(OpenAI 会保留 ZDR 客户的解密密钥,但不会保留其数据。)有关 Codex 支持 ZDR 的相关更改,请参见 PR #642 和 #1641。
通常,采样模型的成本远高于网络传输的成本,因此采样是 OpenAI 提高效率的主要目标。这就是为什么提示词缓存如此重要,因为它使 OpenAI 能够重用之前推理调用的计算结果。当 OpenAI 命中缓存时,采样模型的时间复杂度是线性的而非二次方的。
OpenAI 的提示词缓存文档对此进行了更详细的解释:
缓存命中仅适用于提示词内的精确前缀匹配。为了获得缓存收益,请将静态内容(如指令和示例)放在提示词的开头,并将变量内容(如用户特定信息)放在末尾。这也适用于图像和工具,它们在请求之间必须完全一致。
考虑到这一点,让 OpenAI 看看哪些类型的操作会导致 Codex 中的「缓存未命中」:
在对话过程中更改模型可用的工具。
更改 Responses API 请求的目标模型(实际上,这会改变原始提示词中的第三项,因为它包含模型特定的指令)。
更改沙箱配置、批准模式或当前工作目录。
Codex 团队在 Codex CLI 中引入可能破坏提示词缓存的新功能时必须保持严谨。例如,OpenAI 最初对 MCP 工具的支持引入了一个 Bug,即 OpenAI 未能以一致的顺序排列工具,导致了缓存未命中。
请注意, MCP 工具可能特别棘手 ,因为 MCP 服务器可以通过 notifications/tools/list_changed 通知随时更改它们提供的工具列表。在长对话中间响应此通知可能会导致昂贵的缓存未命中。
如果可能的话,对于对话中发生的配置更改,OpenAI 通过在 input 中附加一条新消息来反映更改,而不是修改之前的消息:
- 如果沙箱配置或批准模式发生变化,OpenAI 会插入一条新的 role=developer 消息,格式与原始的
项目相同。 如果当前工作目录发生变化,OpenAI 会插入一条新的 role=user 消息,格式与原始的
相同。
为了性能,OpenAI 竭尽全力确保缓存命中。此外,OpenAI 还必须管理另一个关键资源:上下文窗口。
上下文管理与压缩
OpenAI 避免耗尽上下文窗口的总策略是: 一旦 Token 数量超过某个阈值,就对对话进行压缩(Compaction) 。
具体来说,OpenAI 用一个代表对话的小型新项目列表替换 input,使智能体能够在理解迄今为止发生的事情的情况下继续工作。早期的压缩实现需要用户手动调用 /compact 命令,该命令会使用现有对话加上自定义的总结指令来查询 Responses API。Codex 将生成的包含总结的 Assistant 消息作为后续对话轮次的新 input。
自那以后,Responses API 已演进为支持一个特殊的 /responses/compact 端点,该端点能更高效地执行压缩。它返回一个项目列表,可用于替代之前的输入以继续对话,同时释放上下文窗口。此列表包含一个特殊的 type=compaction 项目,带有一个不透明的 encrypted_content 项,它保留了模型对原始对话的潜在理解(latent understanding)。
现在,当超过 auto_compact_limit 时,Codex 会自动使用此端点来压缩对话。
下期预告
本博客介绍了 Codex 智能体循环,并详细讲解了 Codex 在查询模型时如何构建和管理其上下文。在此过程中,OpenAI 强调了适用于任何在 Responses API 之上构建智能体循环的开发者的实际考虑因素和最佳实践。
虽然智能体循环为 Codex 提供了基础,但这仅仅是个开始。
在接下来的文章中,OpenAI 表示将深入探讨 CLI 的架构,探索工具调用的具体实现方式,并详细了解 Codex 的沙箱模型。
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com
]article_adlist–>
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

