大模型虽已具备强大的感知与推理能力,但在面对复杂的计算机图形界面操作(Computer Use)任务时,仍受限于高质量数据稀缺与环境交互反馈缺失的双重挑战。美团技术团队推出了 EvoCUA 模型并在Github、Huggingface开源,通过构建可验证数据合成引擎与十万级并发的交互沙盒,将训练范式从传统的”静态轨迹模仿”转变为高效的”经验进化学习”。该方案在权威评测基准 OSWorld 上以 56.7% 的成功率刷新了开源 SOTA(2026年1月6日榜单),验证了基于经验的进化范式在 GUI 智能体领域的有效性。
01 背景与挑战
随着大模型的发展,AI 已经具备了强大的感知与推理能力。但在真实的使用场景中,我们希望 Agent 不仅能回答问题,更能解决问题——比如自动处理 Excel 表格、在浏览器中完成复杂的资料检索或跨应用协同。这种对解决问题能力的追求,推动了基础模型从 Chat(对话者)到 Agent(行动者) 的转变。
在这一进程中,Computer Use Agent(CUA,计算机操作智能体) 是一个关键里程碑。CUA打破了 API 的限制,构建了一种原生的交互方式——像人类一样,通过高分辨率视觉感知屏幕,并利用鼠标键盘完成跨应用的长链路任务,有可能成为下一代操作系统的核心交互入口。
然而,要训练出一个通用的 CUA,我们面临着严峻的数据扩展(Data Scaling)瓶颈。当前主流的训练范式依赖于对专家轨迹的模仿学习,但在将其推向工业级可用时,这种方式面临着三大挑战:
- 数据合成质量低: 真实的高质量轨迹数据极度稀缺且昂贵,而试图用大模型直接生成数据往往会陷入”幻觉”。模型生成的指令或计划经常看似合理,但在真实的 UI 状态下根本不可执行。
- 缺乏交互反馈: 静态数据模仿学习只能告诉模型”什么是对的”,却无法告诉它”如果点偏了会发生什么”。缺乏在大规模环境交互中产生的反馈,模型就无法捕捉操作与环境变化之间复杂的因果动态,难以适应真实环境中渲染差异、网络延迟等随机扰动。
- 长链路探索效率低:计算机操作往往涉及数十步甚至上百步的连续决策,无约束的探索空间巨大且低效。仅靠简单的模仿学习,模型很难学会如何从中间的错误状态中反思并纠错。需要一种更高效和可扩展的范式,让模型专注于从海量自身成功和失败的经验里学习和进化。
面对上述挑战,我们正式推出了 EvoCUA , 一种原生的计算机操作智能体模型。EvoCUA致力于构建一种进化范式,让模型在大规模沙盒环境中,像生物进化一样,通过不断的试错,反思和修正,积累海量成功和失败经验,进而不断提升自身能力。
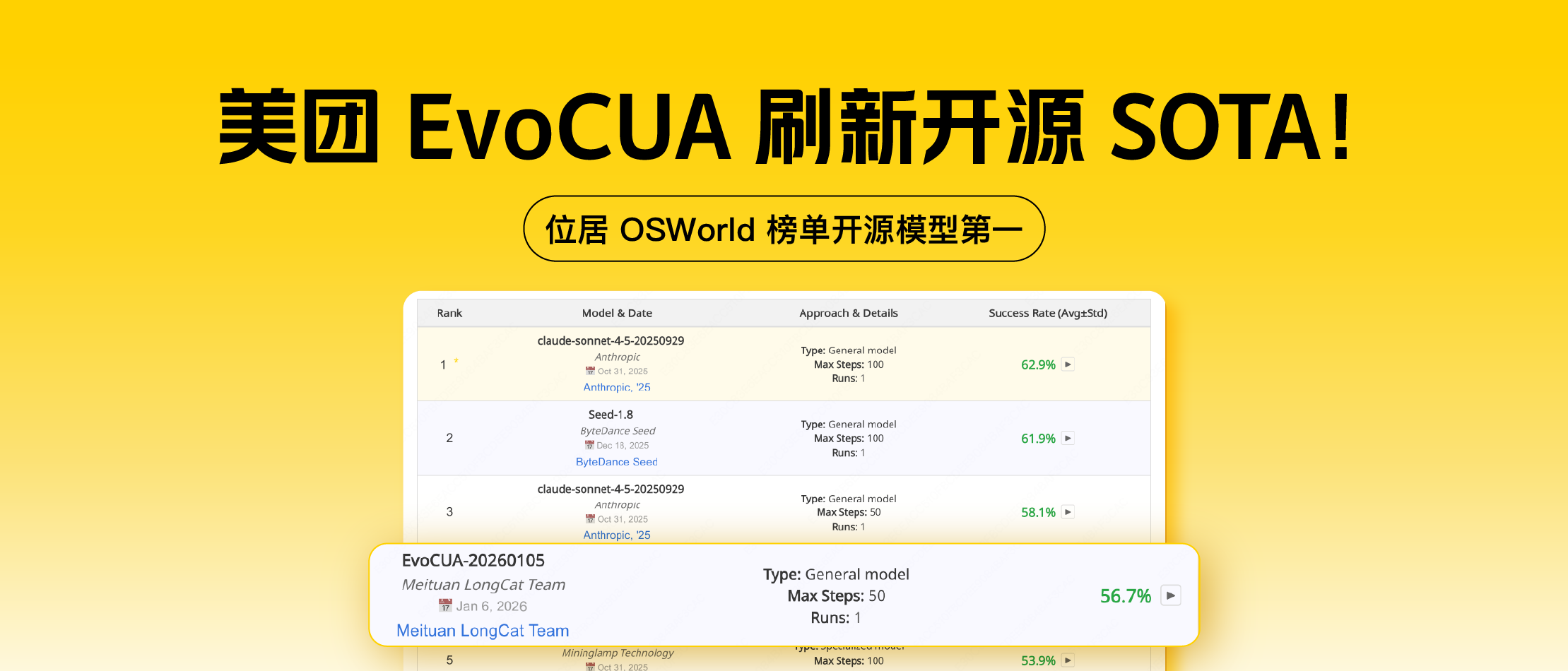
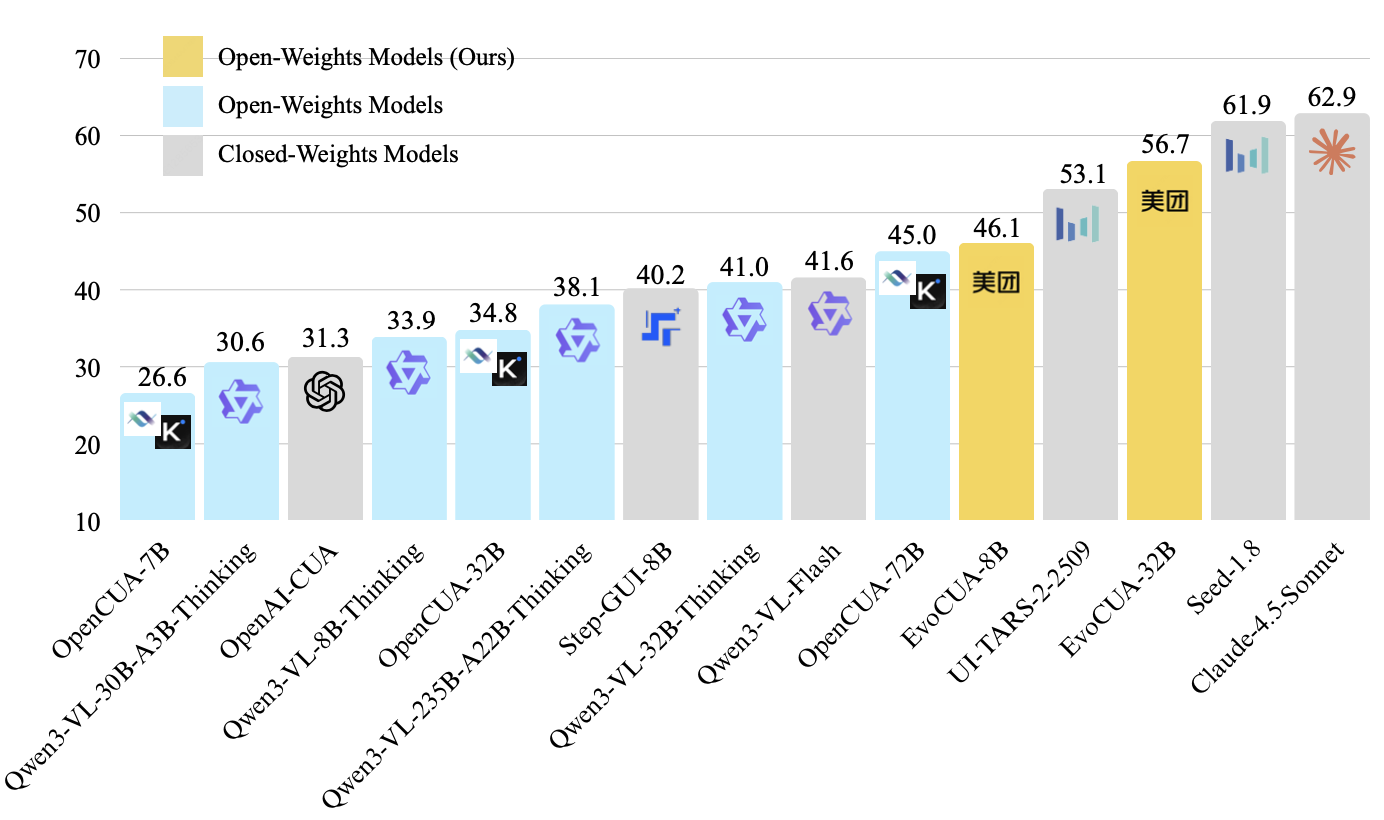
通过这一范式,EvoCUA-32B 在 Computer Use权威的在线评测基准 OSWorld 上取得了 56.7% 的成功率,刷新了开源模型的 SOTA 记录,以更少的参数量和推理步数超过此前的开源SOTA OpenCUA-72B (45.0%),以及领先的闭源模型UI-TARS-2 (53.1%)。此外,实验证实该方案的通用性,在不同基座(如 Qwen3-VL、OpenCUA)及多个尺寸(8B 至 72B)的模型上均能显著提升 Computer Use 能力 。
模型上网查询如何配置rbenv开发环境并帮用户安装的示例:
02 核心技术架构
EvoCUA 的核心在于构建”交互-反馈-修正”的闭环。我们针对数据、环境、算法三个维度构建了自维持的进化架构:可验证数据合成引擎 负责生产高质量任务,高并发交互基建 支持海量轨迹合成,基于经验的迭代算法提供模型进化的关键路径。
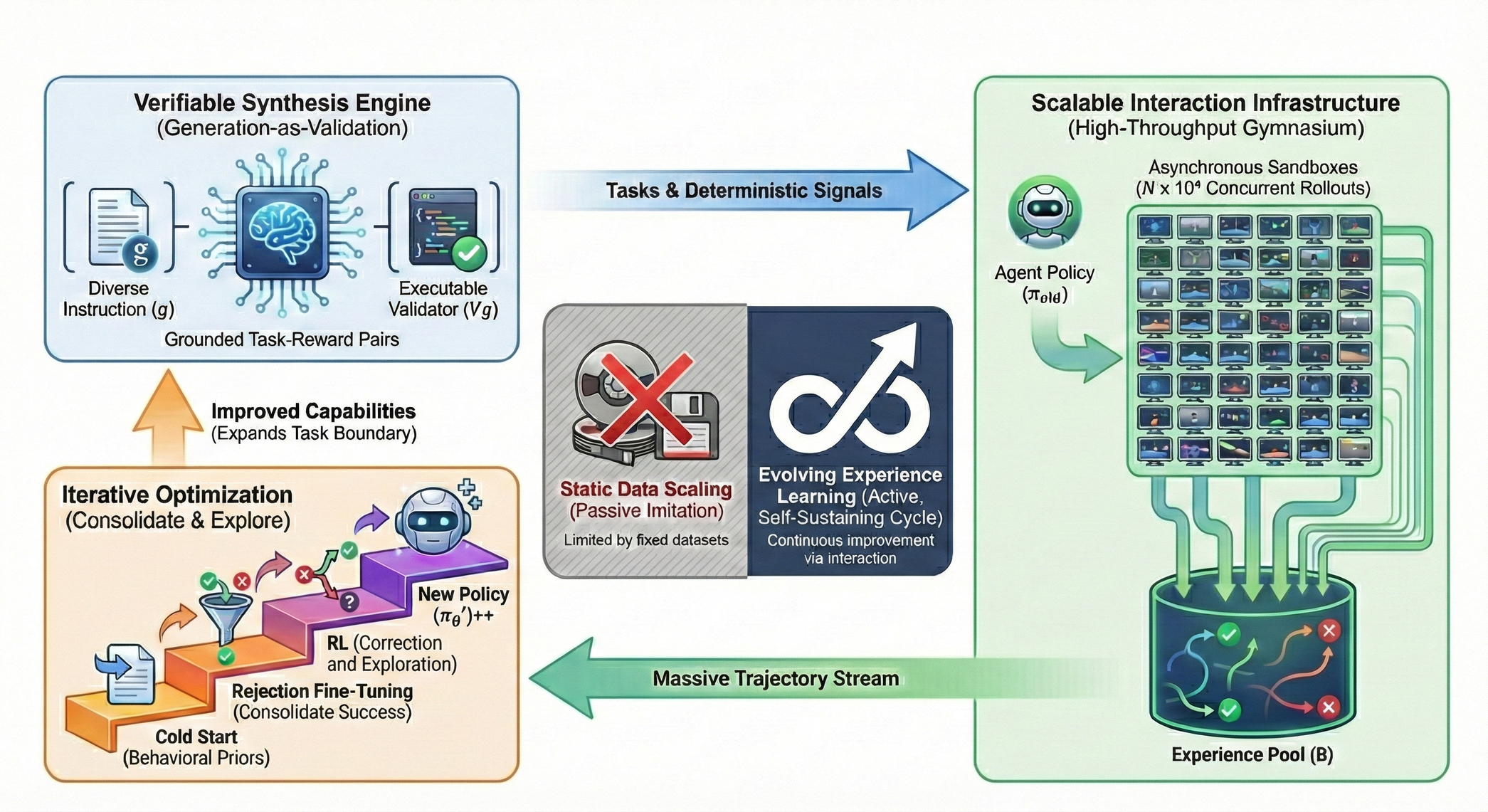
2.1 可验证数据合成引擎
EvoCUA 数据层的核心任务是构建一个自动化流水线,能够合成覆盖各个垂直领域的高质量任务指令。我们要求合成数据要满足两个指标:
- 场景完备性:覆盖从文档办公、Web 检索到系统管理的全场景操作。
- 执行确定性:每一条数据必须在真实环境中可执行、可验证,杜绝逻辑幻觉。
在实现这一目标时,我们发现业界通用的”大模型生成 + Reward Model (RM) 筛选”范式在 Computer Use 场景下存在本质缺陷:
- 语义与执行的割裂:传统的 RM 基于语义匹配打分,只能判断生成的指令在文本层面是否合理,无法验证其在物理层面能否执行。
- Reward Hacking:模型倾向于生成逻辑通顺但包含”幻觉”的指令(例如点击不存在的 UI 元素)。这些不可执行的任务会引入大量训练噪音,导致模型在真实操作中产生严重的错误累积。
为了解决数据可信度问题,我们提出了 “生成即验证” 范式,在生成自然语言指令的同时,同步生成可执行的验证代码,并以沙盒中的实际运行结果作为判断数据是否有效的唯一标准。
整体数据合成框架如下:

2.1.1 结构化任务空间构建
在构建任务空间时,我们并未盲目堆砌数据,而是基于对 GUI 操作本质的两个核心洞见:
- 原子能力的可迁移性与泛化性:GUI 操作虽然千变万化,但其底层的”原子技能”是跨域复用的。例如,”数据筛选”这一能力,无论是在 Excel、CRM 系统还是网页后台中,其逻辑内核是同构的。
- 复杂任务的组合本质:真实世界中的复杂任务,本质上是由有限的原子能力通过特定逻辑编排而成的序列。掌握了原子能力的组合方式,就等于掌握了生成无限复杂任务的”语法”。
基于这两点思考,我们采用分层构建策略来初始化任务环境。
- 原子能力拆解:我们将复杂的桌面操作任务解构为标准的原子能力单元。基于分层领域分类体系,例如将”Excel 财务分析”任务拆解为”公式计算”、”多列排序”、”透视表生成”等子技能。
- 资源文件合成 :为了模拟真实环境的复杂性,我们在环境初始化阶段实施了两种资源生成策略。
- 参数化合成:针对结构化数据(如销售报表),我们利用代码生成器批量生产 Word/Excel 文档,随机化其中的姓名、价格、日期等参数。
- 非参数化合成:针对非结构化数据,我们直接注入无版权问题的互联网上的公开资源(如真实的图片、音频、复杂的 PPT 幻灯片),强迫 Agent 处理真实世界中不可预知的视觉噪声和布局多样性。
相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


