
本文由来自南洋理工大学、爱丁堡大学、宾夕法尼亚大学、伦敦大学学院和麻省理工学院的研究者合作完成。作者团队在 RF / 毫米波感知、人体建模、机器人感知与控制等方向均有长期积累。
Junqiao Fan:NTU 在读博士,指导老师为 NTU 教授 Lihua Xie。
Chris Xiaoxuan Lu:UCL 副教授。
Jianfei Yang:NTU 助理教授。
Fangqiang Ding:MIT 博后研究员。
Yunjiao Zhou, Yizhuo Yang, Jiarui Zhang:NTU 在读博士。
Xinyuan Cui:Upenn 在读硕士(部分工作为 Xinyuan Cui 和 Fangqiang Ding 在爱丁堡大学时完成)。
想象几个并不遥远的场景:
医院的病房里,刚做完手术的患者正在练习下床、走动,智能系统通过摄像头捕捉他的动作,判断步态是否稳定、有没有跌倒风险;回到家,在卧室或浴室这样私密的空间里,老人起身、转身、洗漱,甚至意外滑倒的瞬间,也可能被视觉传感器记录,只为了让 AI 能更早发现异常;另外,在养老院和托儿所场景里,老人或孩子的日常活动,同样可能长期处于 “被看见” 的状态。
这些系统的出发点无疑是好的:为了更安全的照护、更及时的提醒、更可靠的响应。但只要感知还依赖相机,一个问题就始终绕不开: 当 AI 越来越懂人,人是不是也在被越来越彻底地暴露?
人们担心的,不只是模型准不准,更怕那些包含外貌、身份、行为习惯甚至生活细节的视觉数据,被存储、泄露或滥用。哪怕什么都没发生,光是 “始终有一个镜头在看着你” 这件事本身,就足以让人不安。正是在这样的背景下,来自海外高校的研究者提出了 M4Human 。这项工作试图减少人体感知对相机单一模式的依赖,推动毫米波人体感知从粗粒度的识别,走向更高保真的人体建模与系统化评测。

论文标题:M4Human: A Large-Scale Multimodal mmWave Radar Benchmark for Human Mesh Reconstruction
作者: Junqiao Fan, Yunjiao Zhou, Yizhuo Yang, Xinyuan Cui, Jiarui Zhang, Lihua Xie, Jianfei Yang, Chris Xiaoxuan Lu, Fangqiang Ding
作者单位:南洋理工大学,爱丁堡大学,宾夕法尼亚大学,伦敦大学学院,麻省理工学院
论文链接: https://arxiv.org/pdf/2512.12378
代码与数据链接:https://github.com/FanJunqiao/M4Human
主页链接:https://fanjunqiao.github.io/M4Human-site/
研究背景
为什么人体感知不能只依赖相机
在未来的 Physical AI 系统中,机器不仅要 “看见” 人,还要理解人的运动和行为,并据此做出合适的响应。相比只预测少量人体关键点, 人体网格重建(Human Mesh Reconstruction, HMR) 能够恢复姿态、形状和全局运动,在人机交互、康复评估、健康监测、VR/AR 以及具身智能等场景中更有应用价值。
但当前高质量的 HMR 系统大多仍依赖相机。这条路虽然有效,却有两个现实限制:一是视觉数据会直接暴露人的外观,在儿童照护、养老陪护、居家康复等场景中容易引发隐私担忧;二是相机容易受光照和遮挡影响,弱光、逆光或复杂环境下的鲁棒性并不总能保证。正因如此, 毫米波雷达 正成为人体感知中越来越重要的一种模态 —— 它通过回波恢复空间信息,对光照不敏感,在部分遮挡条件下更稳健,而且不会记录人的外貌。
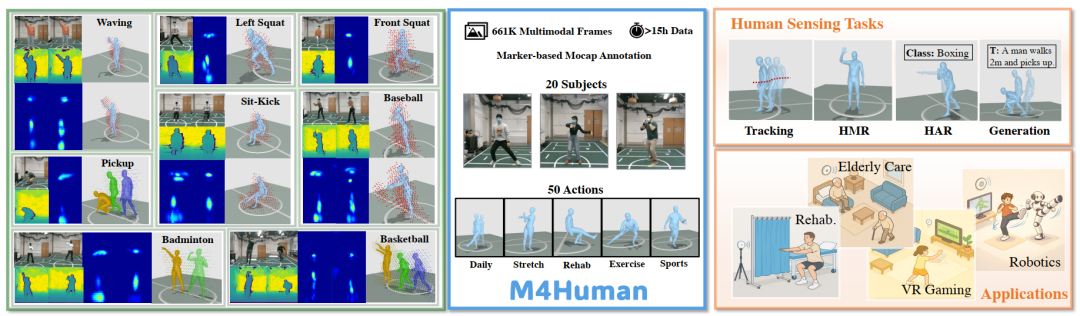
M4Human – 面向多任务的人体感知 benchmark:涵盖 50 类动作、20 位参与者、661K 帧数据,并支持 tracking、mesh reconstruction、activity recognition、generation 等任务。
现有问题
RF 人体感知真正缺的是 benchmark
过去几年,基于 RF / 毫米波的人体感知方法层出不穷,但这一方向的发展一直受限于数据基础。更准确地说,当前真正缺的不是模型,而是足够系统、足够高质量的 benchmark。现有许多 RF 数据集仍以粗粒度的人体姿态估计为主,标注通常停留在 skeleton 层面;少数涉及 mesh reconstruction 的数据集,也存在规模小、动作种类有限的问题,而且很多只开放经过处理后的稀疏点云。
这带来了几个直接限制:
标注粒度和精度不足,难以支撑更高保真的人体建模;
动作分布单一,大多集中在简单的原地动作,难以反映真实场景中的复杂动态;
原始雷达张量(raw radar tensor)缺失,后续研究只能在经过阈值处理后的点云上建模,无法充分利用雷达原始信号中更完整、更细粒度的空间信息。
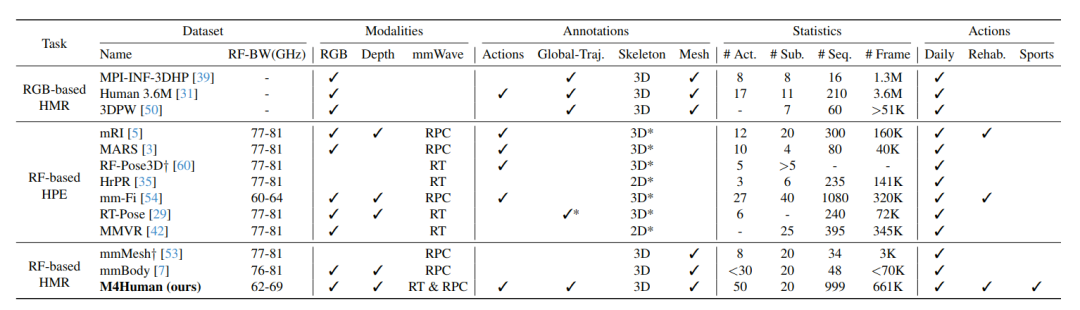
M4Human 与已有 RF/mmWave 人体感知数据集对比。M4Human 规模更大、动作更多、标注更细、同时开放 RT 与 RPC,并支持 mesh reconstruction 与全局轨迹。
数据集本身
M4Human 补上的是什么空白
M4Human 是一个面向高保真 RF / 毫米波人体建模的大规模多模态 benchmark, 包含 999 段序列、661K 同步帧、20 位参与者、50 类动作 ,总时长超过 15 小时。与此前许多数据集不同,M4Human 不仅提供 RGB 和 depth,还同时开放 raw radar tensor(RT) 与 radar point cloud(RPC),并配有基于高精度 marker-based MoCap 的 3D mesh 和全局轨迹标注。
这项工作的关键不是 “数据更多”,而是 “数据更适合高保真人体建模” 。一方面,M4Human 的动作设计更丰富 —— 不仅包含原地动作,还涵盖坐姿以及非原地的动态动作,整体分布更接近真实场景;另一方面,它提供了更完整的雷达数据表征,既开放后处理得到的点云,也保留原始 RT,让研究者可以探索从 radar tensor 到人体 mesh 的端到端建模。
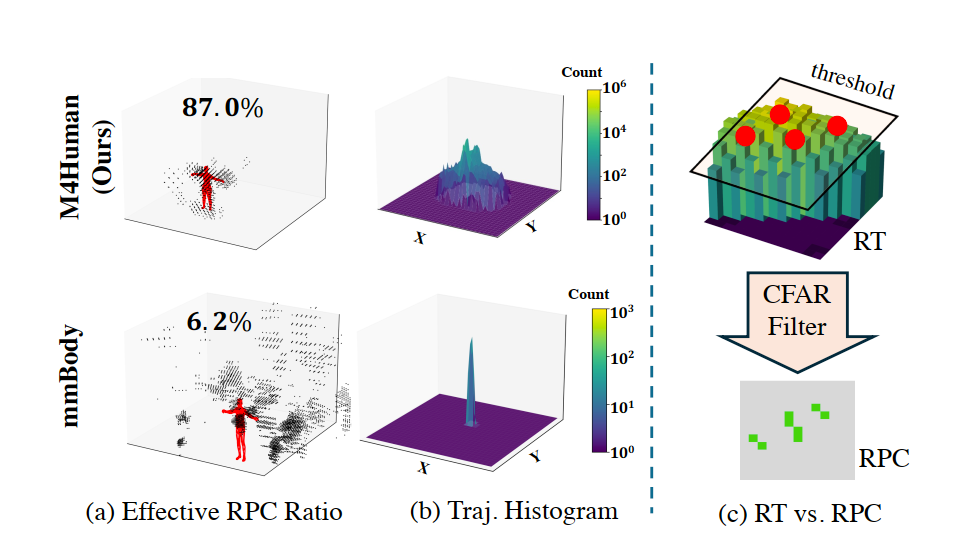 与 mmBody 等已有数据集相比,M4Human 不仅规模更大,还具有更高的人体有效点云占比,并额外开放原始雷达张量 RT。
与 mmBody 等已有数据集相比,M4Human 不仅规模更大,还具有更高的人体有效点云占比,并额外开放原始雷达张量 RT。数据怎么来的
采集系统与标注链路为什么可信
一个 benchmark 是否有说服力,很大程度上取决于数据采集与标注流程是否扎实可靠。M4Human 在这方面搭建了一套完整的 多模态采集平台 :作者将 Intel RealSense RGB-D 相机、Vayyar 成像毫米波雷达和 Vicon MoCap 系统集成到一起,相机与雷达固定安装,Vicon 系统则提供 高精度 三维运动捕捉。
基于这套系统,M4Human 一方面可以同步采集 RGB、depth、RT、RPC 等多模态数据,另一方面借助 MoCap 为人体 mesh 和全局轨迹提供高质量标注。论文中提到,作者使用了 37 个 markers 进行采集,并结合后续重建与人工检查,尽可能保证 mesh 标注的 准确性和时空一致性 。相比许多只提供 skeleton 标注的 RF 数据集,这样的流程显然更适合支撑 mesh 级的人体建模研究。
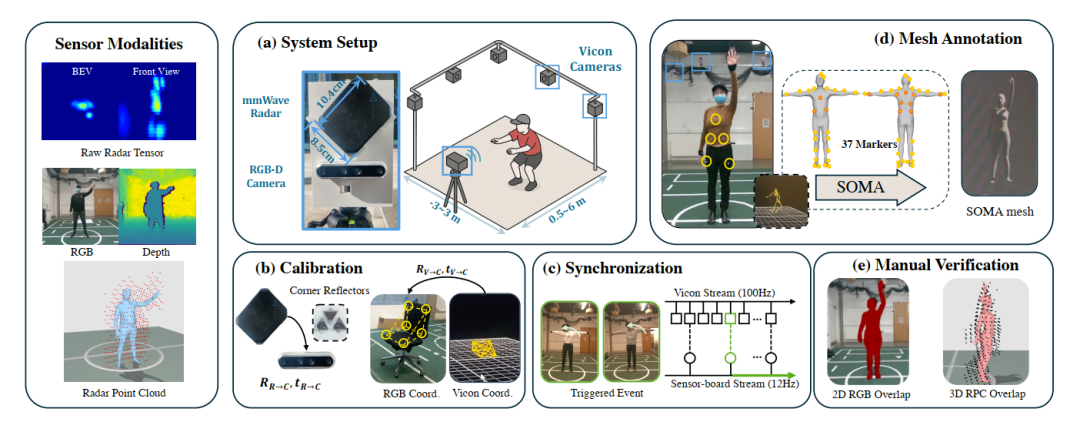
M4Human 的数据采集与标注流程:包括传感系统搭建、空间标定、时间同步、mesh 标注生成与人工校验。
M4Human 数据集中多模态传感器数据与 MoCap mesh 标注的同步演示,展示了不同动作情境下雷达数据与人体标注之间的对齐效果。
Benchmark 设计
它到底在评什么
M4Human 的价值不仅在于发布了一个新数据集,还在于建立了一套相对系统的评测框架。除了动作协议划分,论文进一步定义了 Random split 、 cross-subject 和 cross-action 三种划分方式,分别用于评估常规设置下的表现,以及更具挑战性的泛化能力。
这一设计很重要。很多方法在随机划分下能取得不错的结果,但一旦测试对象变成未见过的 subject,或者动作分布发生变化,性能往往明显下降。M4Human 将这些更难、也更接近真实应用的问题纳入统一的 benchmark,让评测不再停留在 “模型能不能跑通”,而是进一步关注模型在真实变化条件下是否还能保持泛化能力。
RT-Mesh:直接从原始雷达张量恢复人体 mesh
围绕这个 benchmark,作者提出了 RT-Mesh ,作为首个直接基于 raw radar tensor 进行 HMR 的 baseline。它的意义不在于一次性给出最终答案,而在于验证了一件更基础的事情: RT 并不只是辅助信息,它本身就可以成为高保真人体建模的核心输入表征 。
RT-Mesh 的整体思路是:先在 BEV 空间中进行高效定位,再从局部三维 radar tensor 中回归人体 mesh。这一设计为后续基于原始雷达信号的人体建模方法提供了一个清晰的起点,也让 M4Human 不止于 “提供数据”,同时给出了一个可复现、可比较的 baseline。
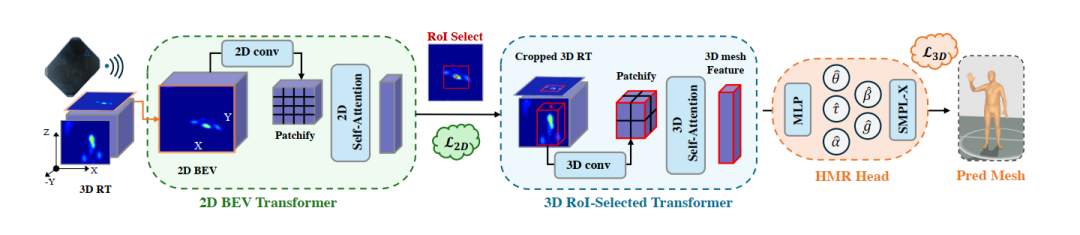 RT-Mesh 框架示意:先在 BEV 中进行高效定位,再从局部 3D radar tensor 中回归人体 mesh。
RT-Mesh 框架示意:先在 BEV 中进行高效定位,再从局部 3D radar tensor 中回归人体 mesh。结果一:RT 不只是可用,而且在泛化场景下更稳
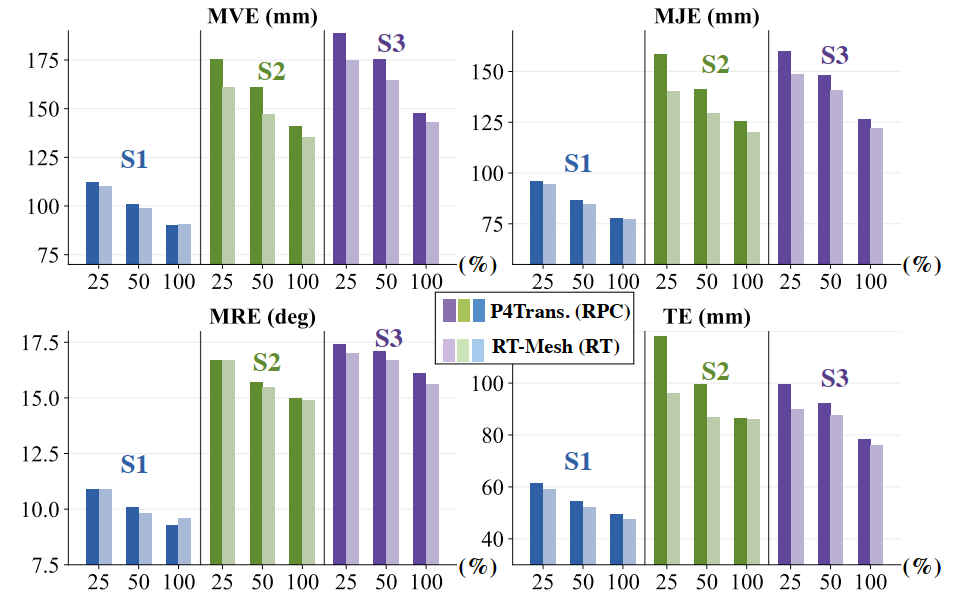
从实验结果看,在 radar-only 设置下,RT 和 RPC 在随机划分上的表现较为接近;但在 cross-subject 和 cross-action 这类更具挑战性的设置中,RT 往往更稳定。以 ALL 协议为例,RT-Mesh 的 MVE 在 S1/S2/S3 上分别达到 90.9 / 135.1 / 143.1 mm,推理延迟仅为 2.74 ms,计算量约 2.6 GFLOPs。
这说明原始 radar tensor 中保留了更连续、更完整的空间信息;而稀疏的 RPC 在经过阈值筛选和点云化后,会损失一部分对细粒度人体建模有用的信息。因此,在更复杂、也更强调泛化能力的测试条件下,RT 展现出更大的潜力。

Radar-only benchmark 结果。RT-Mesh 在整体性能、泛化稳定性和推理效率之间取得了较好的平衡。
数据规模对性能的影响分析:随着训练数据增加,cross-subject 与 cross-action 表现持续改善。证明了大规模数据集的优势。
结果二:mmWave 不是简单替代视觉,而是强互补模态
如果把雷达放到与视觉模态的对比中看,更准确的结论不是 “雷达取代相机”,而是 “雷达与视觉具有明确的互补性”。在单模态设置下,高分辨率 radar-only 在不少场景中已超过 RGB,并接近 depth 的表现;而在多模态融合设置下,Depth + RT 和 RPC + RT 都能带来进一步收益。
雷达的价值至少体现在两方面:
它本身具有更好的隐私友好性和环境鲁棒性;
它不是视觉系统的简单替代,而是 camera-based 系统的有效补充。
论文还指出,radar 在 root trajectory tracking 上尤其有优势,这与它对移动前景更敏感、对静态背景相对不敏感的特性一致。
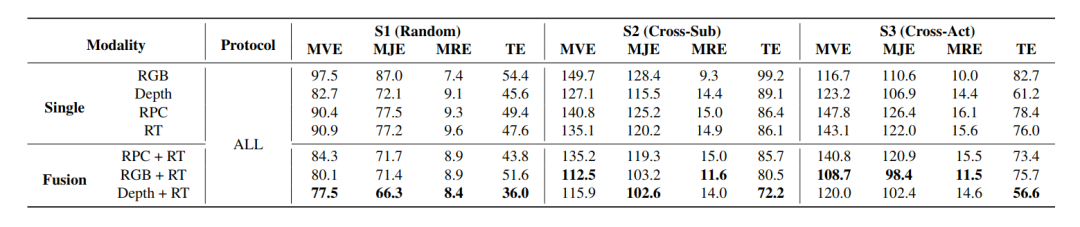
单模态与融合 benchmark:radar-only 已具备较强竞争力,而与视觉模态融合后还能进一步提升重建与跟踪表现。
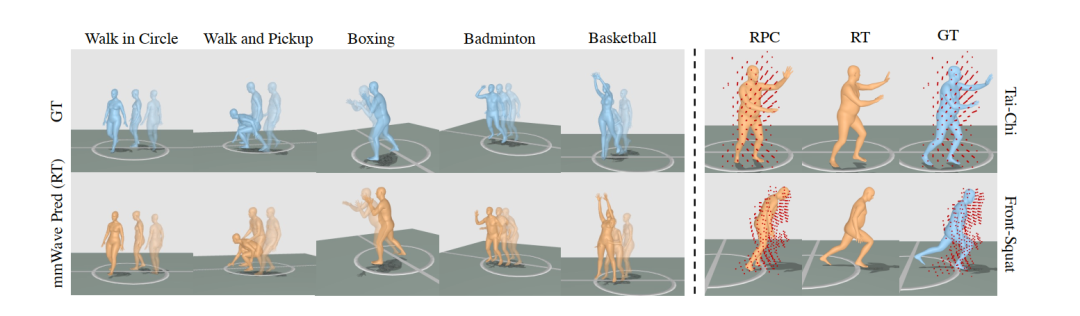
复杂非原地动作中的可视化对比:RT 能更稳定地支持 tracking 与 mesh reconstruction,而 RPC 在身体局部缺失时更容易失败。
复杂动作下的视频可视化结果,基于 radar 的方法得到了稳定精确的人体重建效果。
结语
从骨架到人体网格,RF 人体感知正在进入下一阶段
从更大的视角看,M4Human 推进的不只是一个新数据集,更体现了 RF 人体感知研究范式 的进一步演进。过去,这一领域的许多工作主要停留在 skeleton 级别的人体姿态估计;而 M4Human 把问题推进到 mesh 级建模,让隐私友好的人体感知开始具备更高保真的数据基础与评测支撑。
对于智能家居、医疗康复、人机交互以及具身智能等场景而言,未来真正需要理解的,往往不只是几个离散的关键点,而是人体在真实运动过程中的完整形态与动态变化。M4Human 为这一目标提供了 更系统的 benchmark ,也让 RF / 毫米波人体感知从一种可探索的感知模态,发展为一个更值得持续投入和长期建设的研究方向。
]article_adlist–>
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

