在 Generalist AI 发布 Gen-1 两周之后,具身赛道的另一位重量级玩家 ——Physical Intelligence 也亮剑了,发布了新模型 π 0.7,VLA 又往前走了一步。
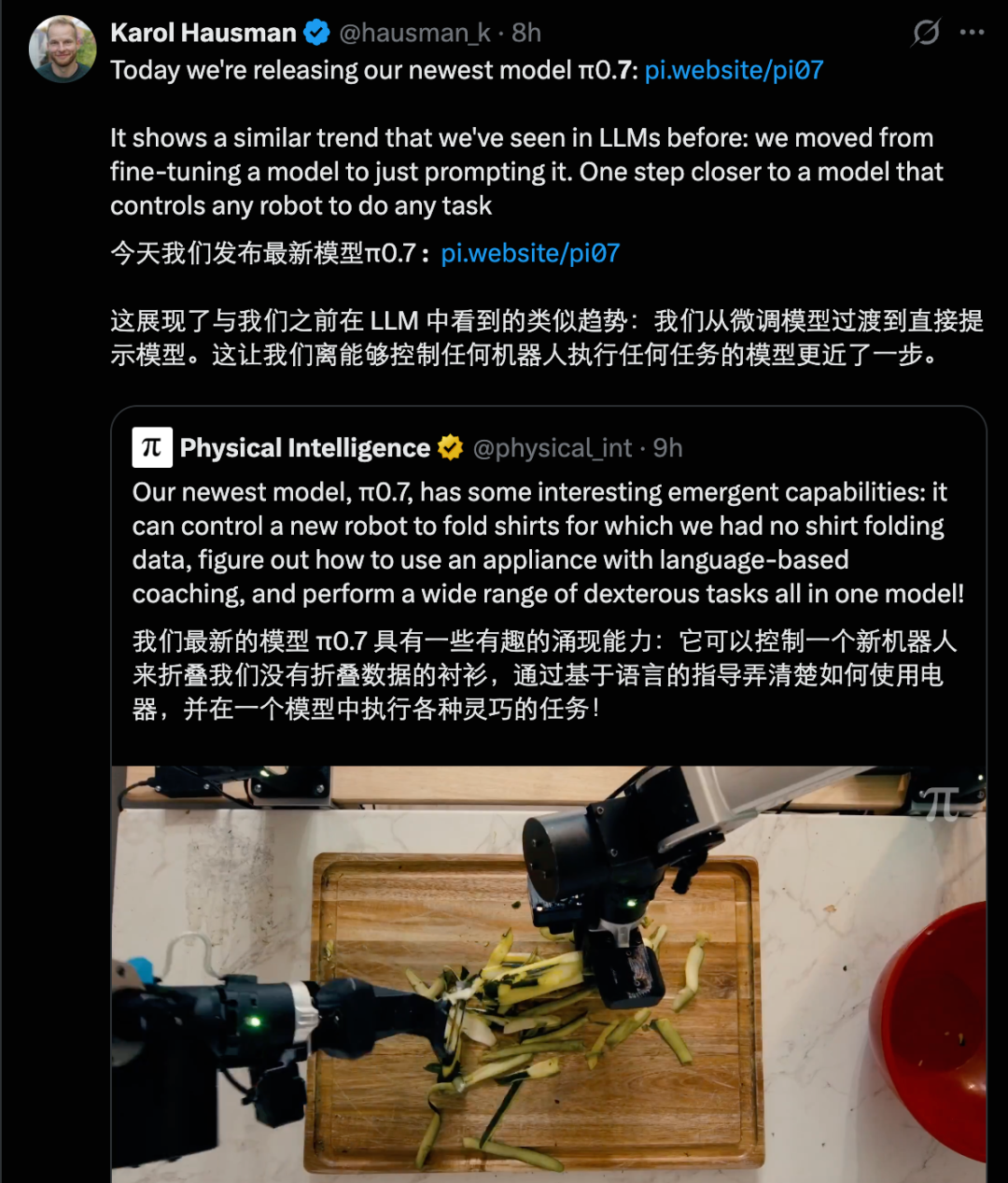
这个模型的重大突破在于 —— 它不只是重复训练中遇到的任务,而是展现出了 组合泛化的初步迹象 。什么叫组合泛化?举个例子,你会切菜、会打开燃气、会翻炒,当你想吃番茄炒蛋时,虽然你从来没有做过,但只要看一眼菜谱,你也能把这些技能组合起来,把菜做出来。现在的大语言模型之所以那么强大,本质上也是因为具备这种能力。
但在机器人领域,这种能力还没有大规模涌现。比如现在广泛使用的 VLA(视觉 – 语言 – 动作)模型,虽然能听懂各种指令和概念,但它们还不会把学过的技能灵活组合起来用。你给它一个新工具或者没见过的厨房用具,它就不知道怎么用了。而且,就算是它学过的技能,通常也得专门再「调教」一下,效果才会好。这跟早期那些语言模型很像,处理不同的问题也得单独做微调。
π (0.7) 看起来不一样。Physical Intelligence 提到了一个空气炸锅的例子。他们从未让 π0.7 学习过「用空气炸锅烤红薯」这个具体任务。但是,当通过分步的语言指令(就像指导一个第一次使用空气炸锅的人那样)来「辅导」它时,这个模型能够理解并执行。它需要将「关闭炸篮」、「放置食物」等从不同数据片段中学到的概念组合起来,应用到一个全新的、完整的任务流程中。
更有趣的是,经过几次这样的语言辅导后,研究人员可以微调一个高层策略,让模型完全自主地生成这些语言子目标,从而独立完成整个空气炸锅任务。这说明 π0.7 能够将观察到的、零散的行为片段组合起来,形成全新的、连贯的行为序列,这就像大型语言模型组合文本片段一样。

研究人员自己也很好奇,π0.7 到底是从哪里学会「空气炸锅」这个概念的。毕竟,训练数据里并没有直接演示「用空气炸锅烤红薯」的完整过程。由于训练集的规模很大且非常多样,很难精确追踪到是哪几段数据赋予了模型这个知识。研究人员的推测是,它很可能 来自机器人操作数据和大规模视觉语言预训练的共同作用 。
他们花了不少力气去搜寻,最终找到了两段相关的家庭数据:一段是机器人关闭空气炸锅,标注为「把炸篮推进空气炸锅」;另一段是「把空气炸锅的炸篮放在台面最左边」。此外,他们还找到了开源 DROID 数据集中一台 Franka 机械臂的相关操作片段。有趣的是,这些片段看起来与 π0.7 在实际实验中用移动机器人执行空气炸锅任务时的行为差异很大。这说明 π0.7 并不是简单模仿某一段数据,而是像大型语言模型组合网络上不同文本片段那样,把这些看似不同的、零散的行为片段重新组合起来,泛化成一个全新的、连贯的「向空气炸锅装入红薯」的任务。他们认为。这是组合泛化能力的生动体现。
除了组合泛化, π0.7 在跨本体迁移方面的表现也非常亮眼 。
在一个叠衣服的例子中,π0.7 被要求控制一个它从未训练过的、形态差异很大的双臂机器人(UR5e 系统)来叠衣服。UR5e 系统由两台 UR5e 工业机械臂搭配 Robotiq 平行夹爪组成。这台机器人很难遥操作:机械臂很重,惯性很大,夹爪也相对不够精确。研究人员之前完全没有收集过这台机器人做叠衣服任务的任何数据。
他们让 π0.7 去控制这台机器人折叠衣物。出乎意料的是,它能够稳定地完成这一操作。值得注意的是,该机器人在折叠 T 恤时的物理动作,与他们最初采集训练数据所用的那台更小型机器人的动作存在显著差异。最终,π0.7 在该任务上的成功率,与经验丰富的遥操作员在同样使用双臂 UR5e 系统进行「零样本」操作时的成功率持平。这些操作员平均拥有 375 小时的遥操作经验,他们正是最初在原始机器人上采集训练数据的同一批专家。
除了广泛的任务泛化能力,研究团队还希望机器人干活又准又快。之前他们开发了一个叫 Recap 的算法,用强化学习专门优化特定任务的策略,让机器人动作更稳、速度更快。
以前的做法是为每个任务单独训练一个 Recap 专家模型。但现在他们换了个思路:把 Recap 训练过程中产生的经验连同策略元数据一起喂给 π0.7。
通过这种知识蒸馏,π0.7 这一个通用模型就学会了 Recap 优化的所有技巧。结果是,无论是叠衣服、做咖啡还是折盒子, π0.7 的成功率和速度都达到了之前专门训练的 Recap 专家模型水平,有时甚至更好 。
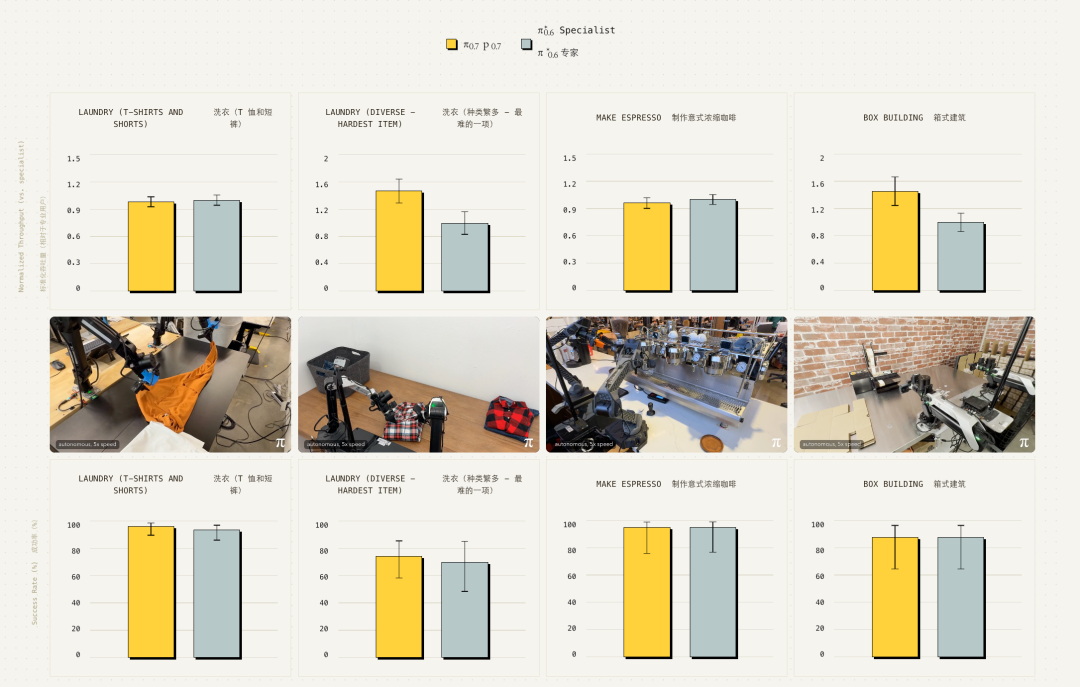

也就是说,现在他们不再需要为每个任务单独维护一个专家模型,一个通用模型就能搞定所有活儿,这也是语言模型领域发生过的重要转折。


π0.7 是一个通用模型,因为它能够控制各种不同的机器人执行各种不同的任务。前面提到的那些都是针对特定能力(比如泛化性、跨本体迁移)做的专门测试,除此之外他们还试了更多日常场景 —— 像削蔬菜、用清洁剂擦玻璃门这些活儿它都能干。
π0.7 为何如此强大?
π0.7 为什么能泛化得这么开?核心在于数据要杂,但提示要细。
基础模型想泛化好,本来就得多喂 各种来源的数据 —— 他们汇集了几十种不同机器人的操作记录、人类演示视频,还有各种自主策略跑出来的实验数据。
不过,光是把这些数据混在一起可不行。关键是要在「提示词」上下功夫:不仅要告诉模型做什么,还要告诉它怎么做(steer)。
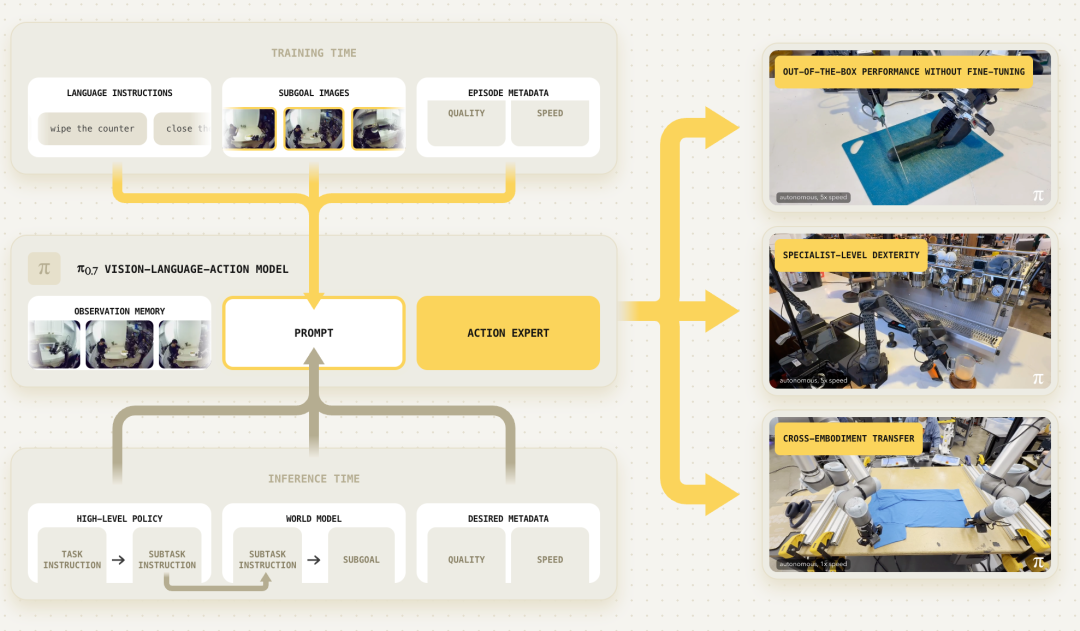
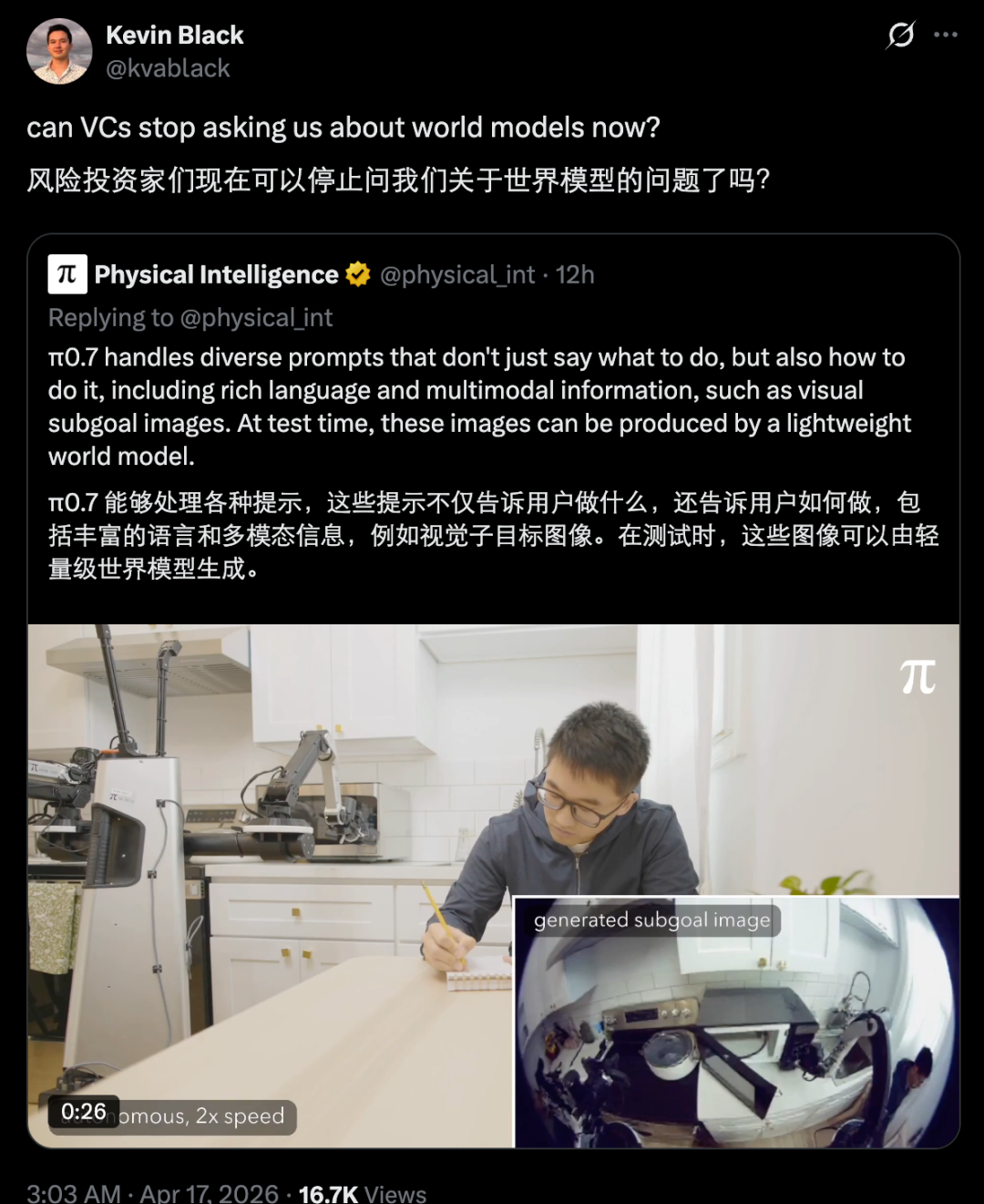
具体来说,研究人员给模型设计了一套 多样化的提示结构 ,包含多模态信息。比如,除了文字描述任务,还可以给一张「视觉子目标」图片,告诉模型物体最终要摆成什么样;也可以给一个期望的任务时长,告诉模型做快一点还是慢一点。这些额外信息能消除行为上的歧义,让模型从不同策略、不同水平的数据中都能学到东西。

这套提示框架让 π0.7 可以把以前难以合并的数据源统一利用起来,包括:
描述任务和每一步的语言指令;
描述操作方式(比如快慢、质量高低)的元数据;
控制模式标签(用关节控制还是末端控制);
视觉子目标图片 —— 可以在测试时由世界模型实时生成,帮助模型理解「下一步长什么样」。
有了这些丰富的标注信息,π0.7 就能放心地使用更多类型的数据。举个例子,那些质量不高的自主数据,本来可能会「教坏」模型,让模型学出低质量的动作。但只要给这类数据打上合适的标签,比如「质量偏低」或「速度偏慢」,模型就能正确理解,不会照单全收。
在论文中,Physical Intelligence 还公布了 π0.7 的更多细节。
π0.7 基于 π0.6 的 VLA 架构与 MEM 记忆系统构建,并新增多模态上下文条件调制。模型包含以 Gemma3 4B 视觉语言模型初始化的 VLM 主干(含 0.4B 视觉编码器),以及 0.8B 参数的流匹配动作专家,总参数约 5B。
下图展示了模型架构的整体概况:

大家如果关心更多细节,可以去论文里找找看:

论文标题:π0.7: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
论文链接:https://www.pi.website/download/pi07.pdf
未来方向:数据和上下文才是关键?
π0.7 是一个统一的通用模型,它具备一种「组合式泛化」的能力 —— 不仅能听懂各种指令、看懂视觉子目标,而且开箱即用,表现相当出色。即便是以前需要专门训练、精细调优的「专家模型」才能完成的任务,它也能直接上手。
研究人员认为,像 π0.7 这样能力强、可操控的模型,未来有可能解决更复杂、从未见过的任务。怎么做到呢?让模型自己「想一想」,先思考可能用什么方法去完成任务,利用它遵循多种提示的能力,把这些想法落地成具体的动作,然后再根据执行结果反思、调整方案。
所以,高效的提示遵循和泛化能力,不仅让人更方便地告诉机器人「我想让你做什么」,还能让现代基础模型把它们的语义推理和问题解决能力「翻译」成物理世界中的行动。换句话说,让机器人真正理解并动手干活。
除了这些展望,Physical Intelligence 团队还分享了他们关于 世界模型 以及未来 scale 方向的看法。团队成员 Lucy Shi 提到,他们原本赌世界模型会是机器人泛化能力的关键,结果数据规模一拉大,VLA 基线就把 world model 吃掉了,而且架构简单得多。



她把这个「苦中带甜」的教训写成论文和 π0.7,结论是: 大规模多样数据 + 正确上下文 ,就能自然涌现出惊人的组合泛化能力,很多过去觉得「很难」的问题其实没那么难。

不过,他们也没有完全否定 world model。在 π0.7 中,他们仍然使用了轻量级 world model 来生成视觉子目标。
同时,Lucy Shi 也发现,现在模型能力是提上来了,但评估又成了新的瓶颈。数据那么多,你很难确定模型到底见没见过某个任务相关的数据,因此泛化也很难定义。这也是未来值得发力的一个方向



