
本文由来自盛大东京 AI 研究院、东京大学、和东京科学大学的研究者合作完成。作者团队在数字人方向有长期积累。部分工作为共同第一作者 Xuangeng Chu (https://xg-chu.site) 和 Ruicong Liu (https://ruicongliu.github.io) 在盛大东京研究院担任研究实习生时完成。
在游戏 NPC、虚拟主播、在线客服等数字人对话场景中, 倾听时的 “扑克脸” 问题一直是行业长期痛点 —— 虚拟人说话时口型可以做到精准同步,但倾听时却表情僵硬、毫无反应,严重影响对话的自然感和沉浸感。盛大 AI 研究院(东京)与东京大学联合提出 UniLS(Unified Listening and Speaking) , 首个仅凭双轨音频即可端到端同时驱动说话和倾听面部动作的统一框架 。该方法在说话精度上达到 SOTA,倾听自然度分布指标提升高达 44.1%,同时支持 500+ FPS 的实时生成, 已被 CVPR 2026 录用 。

论文地址:https://arxiv.org/abs/2512.09327
项目主页: https://xg-chu.site/project_unils/
代码地址: https://github.com/xg-chu/UniLS
数据地址: https://huggingface.co/datasets/xg-chu/UniLSTalkDataset
背景
构建逼真的对话式数字人需要同时处理说话和倾听两种状态。说话时需要精准的口型同步和面部表情协调,倾听时则需要展现自然的点头、眨眼和微表情等互动反应。然而,现有方法大多只关注单向生成:speak-only 方法(如 ARTalk、DiffPoseTalk 等)仅生成说话动作,listen-only 方法仅生成倾听反应,二者无法在统一框架内协同工作。
唯一尝试联合建模的 DualTalk 依赖对方说话者的预计算面部序列作为额外输入,导致系统非端到端、无法实时部署。UniLS 针对这一空白,提出将倾听行为分解为 “内在运动先验” 与 “外部音频调制” 两个独立组成部分,通过两阶段训练范式分别学习,仅以双轨音频作为输入,端到端地生成双方的面部动作。
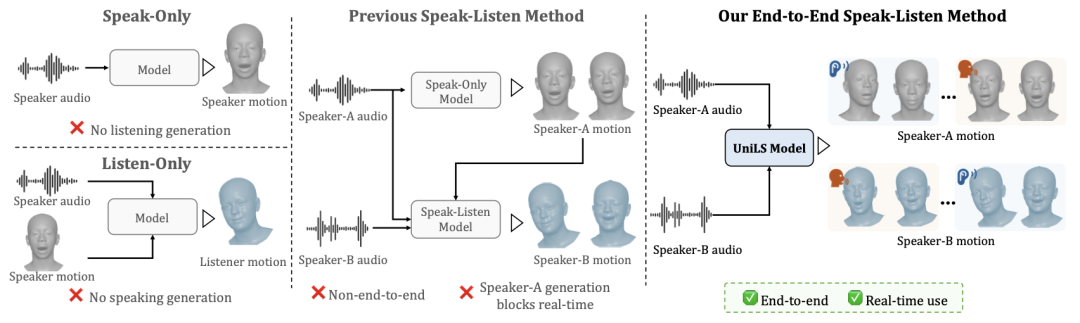
图 1: 现有方法与本文提出的方案之间的对比。大多数之前的研究仍局限于单向生成,即仅针对 “说话” 或仅针对 “倾听”。先前的 “说 – 听” 交互方法需要先生成演讲者 A 的面部序列,然后才能产生演讲者 B 的动作。这种对演讲者 A 生成过程的依赖,使其无法实现端到端训练,并阻碍了实时性能。相比之下,本文方法提供了一个端到端框架,能够实现统一且实时的 “说 – 听” 动作生成。
UniLS 的方法和设计
1. 核心发现:音频 – 动作关联的不平衡
为什么直接端到端训练会导致倾听僵硬?研究者通过对音频特征与面部动作参数在 t-SNE 空间的分布分析揭示了根本原因。如下图 1 所示,说话时音频与面部动作高度关联,二者在嵌入空间中紧密聚集、距离一致性强;而倾听时面部动作与对方音频的关联非常微弱 —— 因为倾听中的许多行为(如眨眼频率、微表情、肌肉协调)本质上独立于对方语音信号。
这种不平衡导致联合训练时网络能轻松为说话分支学到强映射,却为倾听分支接收到的监督信号不足,使其退化为安全的、低方差的静态表情。这一发现直接启发了 UniLS 的核心设计思路:不应将倾听建模为音频到动作的直接映射,而应分两步走 —— 先学习运动本身的内在规律,再引入音频进行调制。
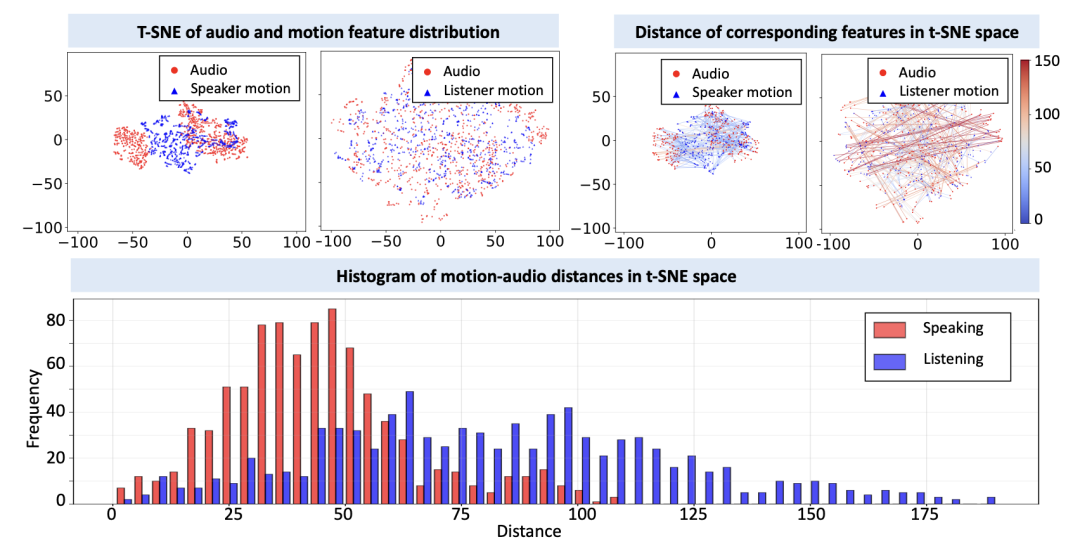
图 2: 面部表情参数与对应音频特征之间的相关性。对于说话状态,音频是指说话者自身的语音;对于倾听状态,音频则来自对方的语音。
2. 两阶段训练框架
Stage 1:无音频生成器训练 —— 学习内在运动先验 。第一阶段在大规模非配对多场景视频数据上训练一个无音频的自回归生成器。训练数据来自 CelebV、TalkingHead-1KH、TEDTalk、VFHQ 等多个数据集,涵盖新闻播报、访谈、演讲、日常对话等多种场景,共计 546.5 小时。面部动作使用 FLAME 3D 参数化模型表示(包含表情、头部姿态和眼球注视),通过多尺度 VQ 编解码器离散化。生成器以过去的运动 chunk 和风格嵌入为输入预测下一个运动 chunk。由于完全不使用音频,模型只能依赖运动本身的时序规律来预测未来,从而自然地学习到眨眼频率、头部微动、表情转换等内在运动先验。
Stage 2:音频驱动微调 —— 引入双轨音频调制 。第二阶段使用 Seamless Interaction 配对对话数据(251.5 小时说话 + 406.0 小时倾听)对生成器进行微调。架构在 Stage 1 基础上新增两个交叉注意力层:一个关注说话者 A 自身的音频(驱动口型同步和面部表情),另一个关注说话者 B 的音频(调制倾听反应)。Stage 1 的自注意力和 FFN 骨干权重通过 LoRA 高效微调,新增的交叉注意力层从头训练。这一设计既保留了 Stage 1 习得的丰富内在运动先验,又赋予模型根据双轨音频信号分别调制说话和倾听的能力。
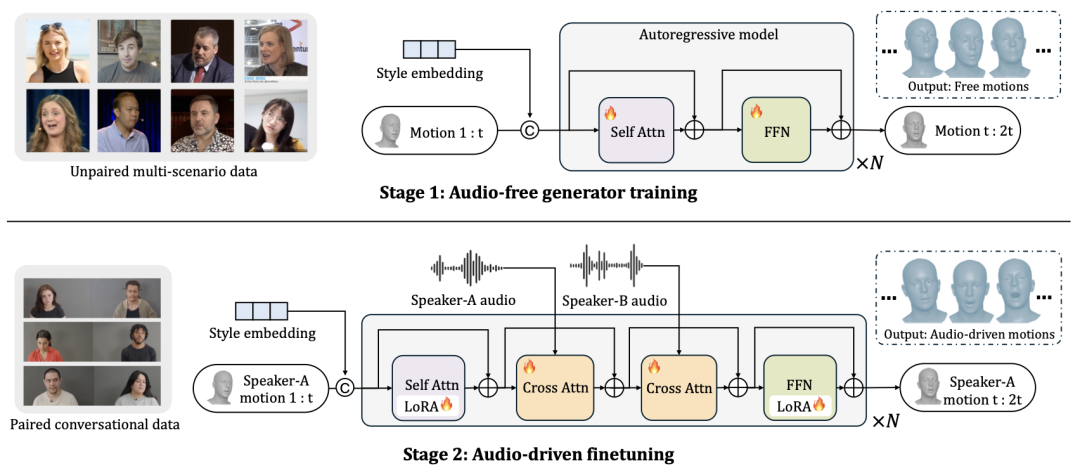
图 3: 两阶段训练策略概览。第一阶段: 在不使用音频的情况下,基于非配对的多场景视频数据训练一个无音频生成器。该模型根据过去的动作序列和风格嵌入,预测未来的动作块。第二阶段: 在配对的对话片段上对生成器进行微调。通过交叉注意力机制,将说话者 A 和说话者 B 的音频作为条件输入,从而生成由音频驱动的 “说 – 听” 动作。
实验结果
1. 定量对比(Seamless Interaction 数据集)
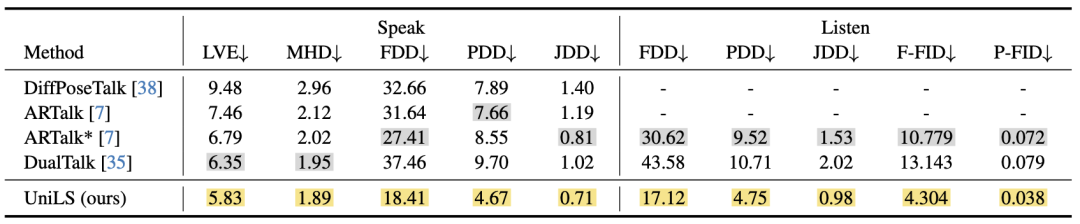
表 1: 在 Seamless Interaction 测试集上评估说话和聆听时的面部动作。分别用金色和银色表示第一名和第二名。
表 1 的量化指标显示 UniLS 在全部指标上取得最优:说话方面,LVE 降至 5.83、MHD 降至 1.89,表明模型不仅精确追踪了音素 – 动作对应,还捕捉到了上脸参与和头 – 颌协调运动等动态特征。倾听方面,FDD 从 DualTalk 的 43.58 大幅降至 17.12,F-FID 从 13.143 降至 4.304,P-FID 从 0.079 降至 0.038,分布指标提升高达 44.1%,有效解决了倾听僵硬问题。
2. 用户研究
与 DualTalk 相比,超过 91% 的用户偏好 UniLS 的倾听反应自然度,90% 偏好其表情自然度,86% 偏好其口型同步质量。
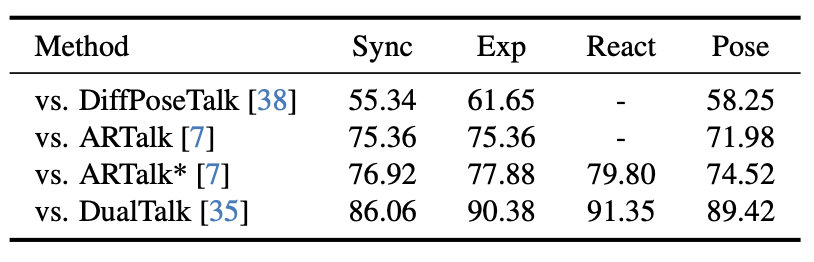
表 2: UniLS 的用户研究结果。数字(%)表示用户更喜欢本文方法而非各基线方法的比例。“同步” 衡量唇部同步性,而 “Exp”、“Re-act” 和 “Pose” 分别评估面部表情的自然度、聆听反应和头部姿势。
3. 实时性能
在出色的生成质量之外,UniLS 在单张 RTX 5090 GPU 上以 560.6 FPS 运行(参数量 421.3M),显著优于 ARTalk * 的 357.7 FPS(489.5M),而 DualTalk 由于非端到端设计无法支持实时。UniLS 在质量、速度与规模之间实现了最优平衡。
总结
UniLS 是首个能够生成统一 “说 – 听” 面部动作的端到端音频驱动框架。通过对音频与动作相关性的深入分析,作者发现了传统端到端训练中导致 “倾听僵硬感”(listening stiffness)的根本原因。基于这一见解,该研究引入了一种两阶段训练范式,将内部动作先验的学习与音频驱动的调制过程分离开来。在大型对话数据集上进行的大量实验表明,UniLS 实现了优秀的口型同步准确度,丰富多样且自然的倾听表情和出色的实时性能。总而言之,UniLS 为对话式数字人奠定了基础,并为极具互动感、逼真的 AI 人机交互开启了新的可能性。
]article_adlist–>
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

