GPT-4o 一边看屏幕一边和你语音对话;Veo-3、MovieGen、Seedance 2.0 直接把原生音轨纳入视频生成链路;HappyHorse 这类近期模型也开始探索音视频联合生成;OpenVLA 让机器人” 听音辨物”—— 音视频大模型,正在从” 加在视觉模型旁边的一个 ASR”,进化成 omni-modal 基础模型的核心能力之一。
NUS 联合牛津、多伦多、UTD、HKUST、QMUL、微软研究院、罗切斯特大学等共 9 家机构最近推出 据作者 所知第 一份系统的音视频智能(AVI)大模型综述 ,用一张演化树串起十年发展,给出统一 taxonomy、三条主线与六大未来研究轴,把 AVI 在大模型时代的角色与待解问题摆到了同一张地图上。

一、9 机构、首份” 音视频大模型” 综述
近年来,AI 圈最显著的变化之一,是” 模型不再只看图”。
2024 年 GPT-4o 把语音、视觉、文本塞进同一个 backbone,2025 年 Google Veo-3、Meta MovieGen 把” 原生带音轨的视频生成” 作为统一目标,2026 年字节 Seedance 2.0 和 HappyHorse 等工作进一步把文本、图像、视频、音频条件与同步音视频输出放进同一代视频生成叙事中;Qwen-Omni 把多模态对话推到流式实时层面,OpenVLA、π0、GR00T 这一线 VLA 模型则开始让机器人同时处理语音指令、视觉、动作甚至环境声响。
但与此同时,整个领域的 学术地图却仍 然 高度分散 。ASR、数字人 / 说话头(talking head)、Foley(拟音)合成、视频配音(V2A)、音频驱动视频生成(A2V)、音画编辑、音视频问答(AVQA)、空间音频推理、AV 导航、AV 操作…… 每一个子方向都有自己的范式、benchmark 与评测口径。
正是在这一背景下,新加坡国立大学(NUS)联合牛津大学、多伦多大学、UTD、HKUST、QMUL、微软研究院、罗切斯特大学等机构,推出了 据作者所知第一份专门针对” 音视频大模型(AVI in Large Foundation Models)“的系统综述 。

论文标题: Audio-Visual Intelligence in Large Foundation Models: AComprehensiveSurvey
论文:https://arxiv.org/abs/2605.04045
HF Paper:https://huggingface.co/papers/2605.04045
GitHub(Awesome-AVI,持续更新):https://github.com/JavisVerse/Awesome-AVI
项目主页:https://javisverse.github.io/
论文把过去十年里散落在十几个子社区的 AV 工作,重新组织成 理解世界(Understanding the World)/ 创造世界(Creating the World)/ 与世界交互(Interacting with the World) 三条主线,给出统一的 taxonomy、基础技术拆解、应用版图、以及面向未来 1–3 年的六轴研究路线。
论文本身的立意,是把 AVI 当作大模型时代下、与单模态语言模型同等重要的一支基础能力 来梳理:从音视频对齐、到联合音视频生成、再到实时闭环交互,应该形成一个连贯的研究框架,而不是被 ASR、Foley(拟音)、数字人 / 说话头、AVQA 各自的范式继续切碎。
二、十年 AVI” 进化树”:从” 对得上” 到” 听 – 看 – 说 – 动一体”
打开 paper 第一页,先映入眼帘的就是这张 2016–2026 AVI 进化树 :
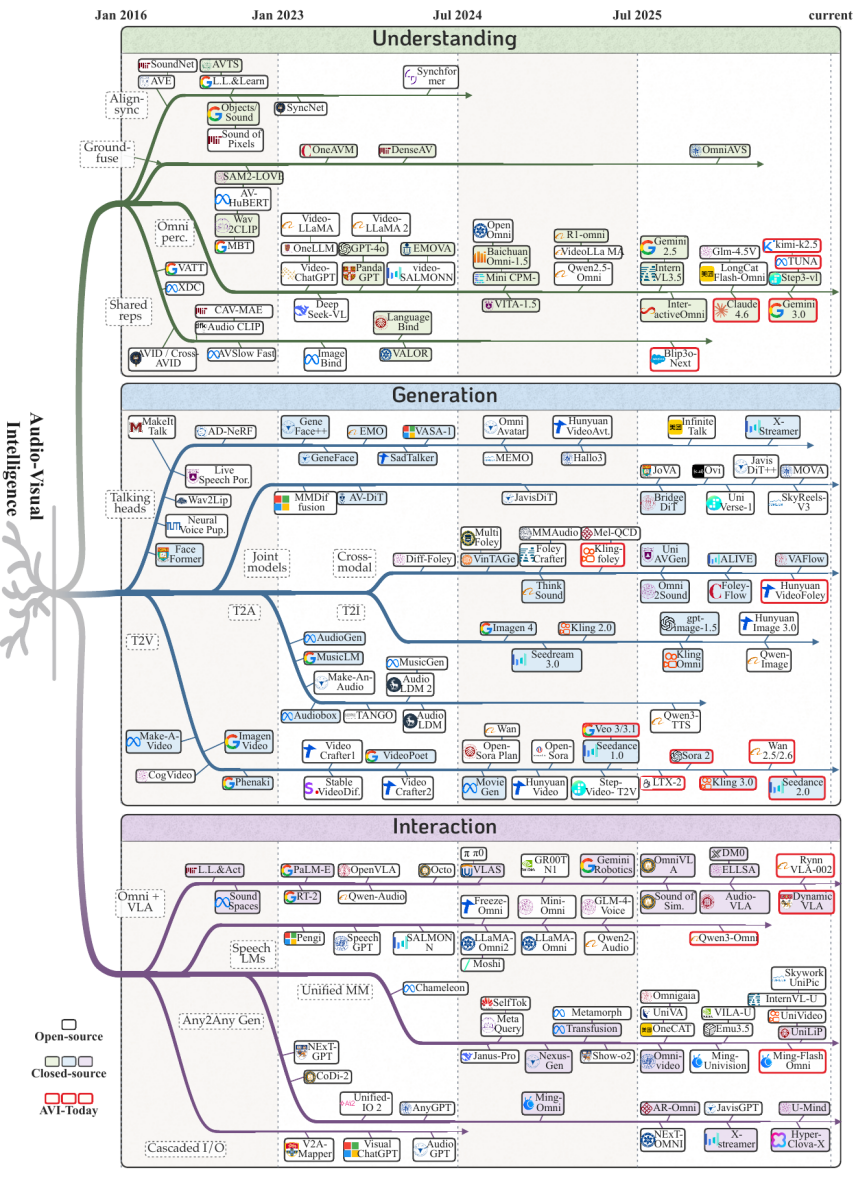
论文把整个 AVI 的发展分成 4 个时代:
Era 1(2016–2018):AV Alignment ——L3-Net、AVTS、Wav2Lip、Audio2Head,加上”ASR + LLM + TTS” 的级联式语音对话。问题集中在” 对得上”。
Era 2(2019–2022):Scaled Representation s ——XDC、AVID、VATT 这些大规模对比学习方法登场,AudioLDM、MusicGen 等单模态生成开始爆发,SpeechGPT、SALMONN、Qwen-Audio 一路走出 audio-native LLM。
Era 3(2023–2024):AV Creation ——MBT、AV-HuBERT、Diff-Foley、MMAudio、FoleyCrafter、MusicInfuser、AudioGPT、Mini-Omni、NExT-GPT,把” 以一种模态生成另一种模态” 和”AV 控制器” 推到舞台中央。
Era 4(2024–2026) :Omni / V L A ——ImageBind、Qwen-Omni、JavisDiT、MovieGen、Veo-3、Seedance 2.0、HappyHorse、GPT-4o、OpenVLA、Audio-VLA,原生融合的 AV 大模型、同步音视频生成模型与 VLA 一起走上前台。
更重要的是,论文明确指出,从 Era 1 到 Era 4,有 6 条瓶颈贯穿始终 :音画同步、时序一致性、可控生成、评测体系、实时延迟、安全治理与数据合规。这些问题不会因为模型变大就自动消失,反而会随着场景升级(短视频 → 长视频 → 实时 omni → agentic)反复出现。
三、统一 Taxonomy:感知 / 生成 / 交互三条主线
论文给出的统一 taxonomy 是核心交付物之一,它把 AVI 拆成三条主线:
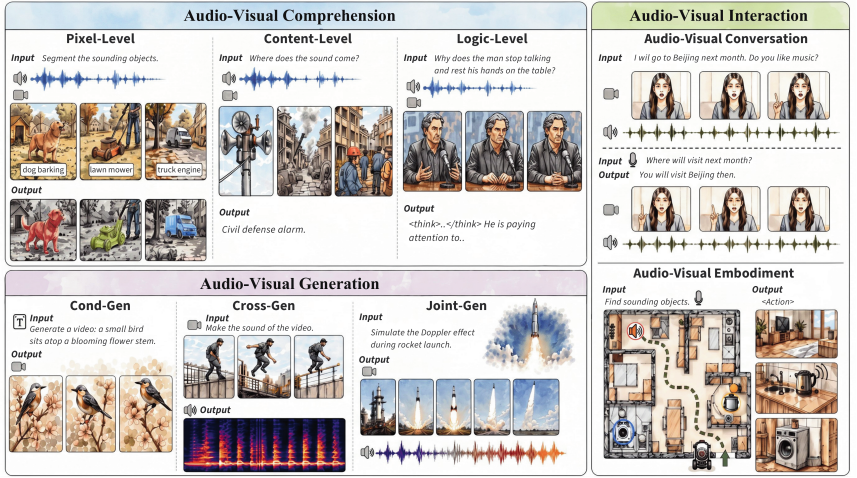
理解世界(Understanding the World,Perception): 包括音视频语音识别(AV-ASR)、唇语识别(lip reading)、活跃说话人检测(ASD)、声源定位与分离、音视频事件理解、跨模态检索、音视频问答(AVQA)这些经典任务,加上越来越多基于 AV-LLM 的长视频理解与因果推理任务。
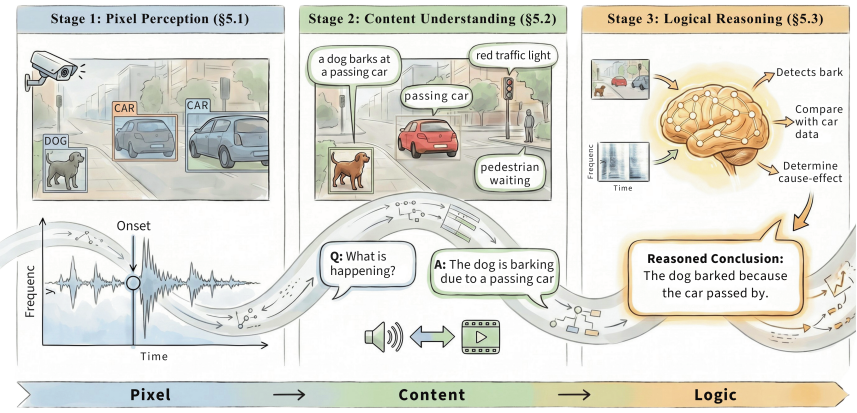
创造世界(Creating the World,Generation): 被进一步拆成” 条件生成 / 跨模态生成 / 联合音视频生成 / 音画编辑” 四类,覆盖视频配音(V2A)、音频驱动视频生成(A2V)、joint AV 生成等代表方向。论文特别指出, 真正” 原生联合” 的音视频生成才刚刚开始 ——MovieGen、Veo-3、Seedance 2.0、JavisDiT,以及 HappyHorse 这类近期模型已经能从文本或多模态条件生成带原生音轨的视频,但跨身份、跨时长、跨场景物理合理性的音画同步生成,以及局部、可控的音画编辑,仍是开放问题。
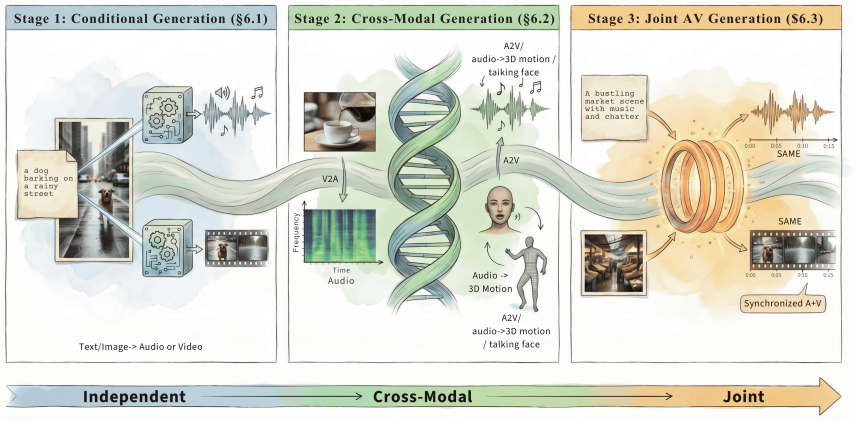
与世界交互(Interacting with the World,Interaction): 包含两条线,一条是” 音视频对话”(从级联 ASR + LLM + TTS,到 audio-native LLM,再到 GPT-4o / Qwen-Omni 这类原生 omni-modal 实时音视频对话),另一条是” 具身智能与机器人”(AV 导航、AV 场景理解、AV 操作,对应 SoundSpaces、AVLMaps、OpenVLA、Audio-VLA)。
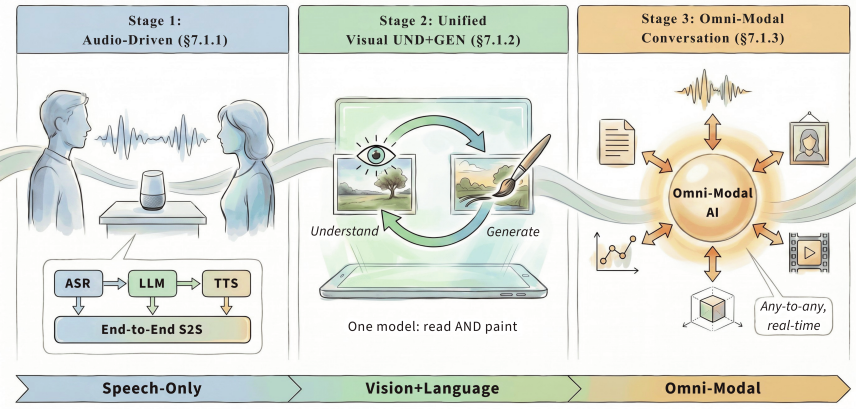
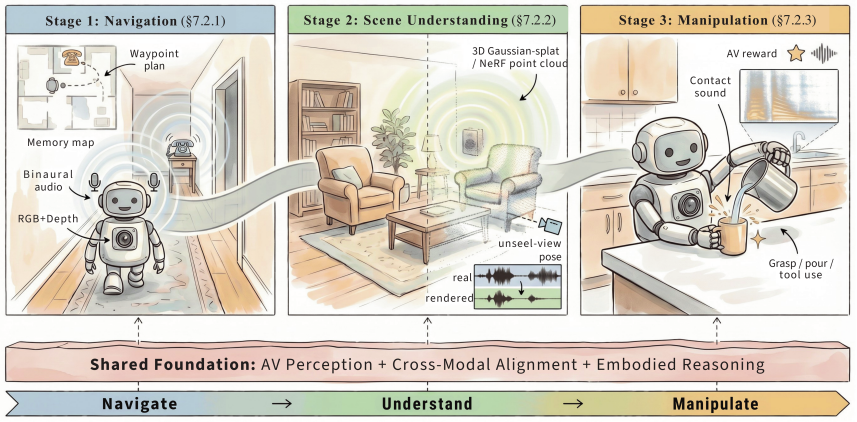
论文强调:交互不是一次性输出,而是带状态的闭环 —— 感知 → 推理 → 响应 / 行动,要在延迟、反馈和用户意图的约束下持续运行。这也是为什么 omni-modal 与 VLA 类模型会在 Era 4 同时出现。
四、基础技术:表示、生成、LLM-centric
如果说三条主线组织的是” 做什么”,基础技术这一章组织的就是” 怎么做”。论文把 AVI 的技术栈拆成三块:
Representation(表示): 音频与视觉特征抽取、VAE / 重建式压缩、离散化 tokenization、跨模态对齐与融合。在大模型语境下,关键问题已从” 特征对不对得上” 升级为” 用哪种 token 把音视信号塞进 LLM 才最高效”。
Generation(生成): 系统梳理 VAE / GAN / Diffusion / 自回归(AR)/ Masked Autoregressive(MAR) 五类生成范式各自的能力边界与组合方式,特别覆盖了 diffusion /flow matching 的演化、AR 模型在视觉与音频上的进展、以及 hybrid AR + Diffusion 的最新方向。
LLM-centric 系统范式 : 论文把当前 AV 大模型按结构归成几种典型范式 ——Encoder + LLM、LLM + Generator、 统一感知生成模型(unified Encoder + LLM + Decoder) 、以及 Agentic 系统与 VLA 模型。这也是工业界搭” 音视频版 GPT-4o” 时最直接对应的架构选择。
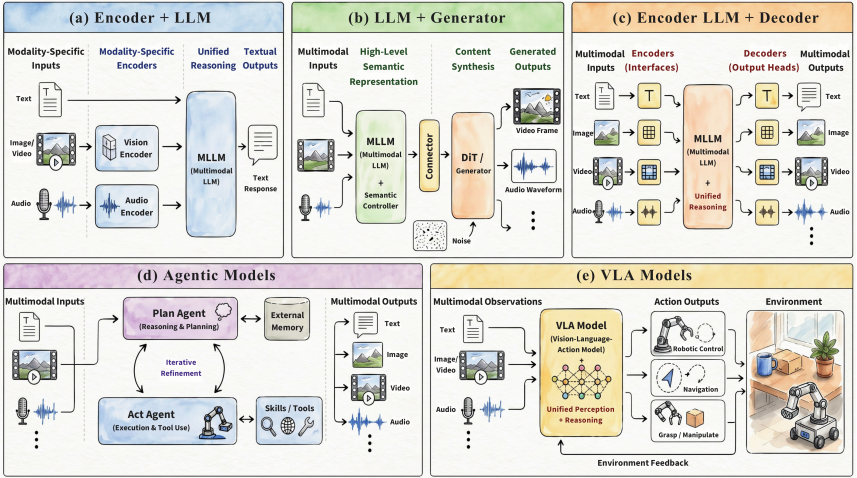
对正在搭” 音视频版 GPT-4o” 的工程团队来说,这张图大体相当于一份 AV 大模型架构选型的速查表,可以拿来对照自己当前的 backbone /encoder/decoder 划分。
五、应用版图:从短视频 AIGC 到具身机器人
论文用一整章梳理了 AVI 的下游应用版图:

围绕音视频基础模型展开,作者把应用归纳为 6 大方向 :
1. AIGC 与创意内容: 视频配音 / Foley(拟音)合成、跨语言唇形同步、配乐与音画编辑,再到一次性出” 带原生音轨短场景” 的 JavisDiT、Veo-3、Seedance 2.0、HappyHorse 等联合音视频生成模型;
2. 数字人与社交交互: 从 Wav2Lip 的 2D 唇形同步、到 GaussianTalker 的 3D 神经渲染、再到 EmoGene、EMAGE、Stereo-Talker 的高保真全身数字人;
3. 人本服务: 以 Qwen-Audio、SALMONN 等 audio LLM 为核心的对话助手 / 会议转写 / AI 教学 / 无障碍辅助;
4. 沉浸式体验与 Metaverse: 空间音频推理、AV-NeRF、AVLMaps,以及 <20 ms 级别的低延迟硬约束;
5. 具身 AI 与机器人: 从 SoundSpaces 一脉的 AV 导航,到 OpenVLA / π0 / GR00T / SmolVLA 的统一 VLA 策略;
6. 泛在感知与安全治理: 智慧城市、工业 IoT、深伪检测、声学异常检测、水印与数据合规、隐私与边缘部署。
六、未来六大研究轴:超越” 更长清单”,给出结构性能力
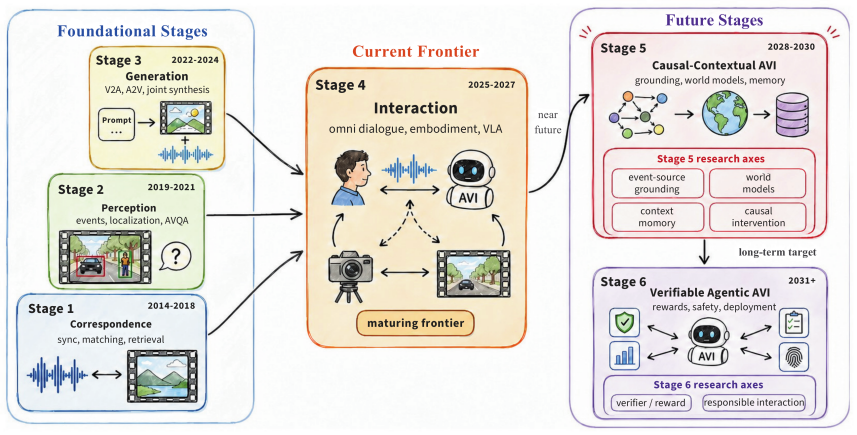
AVI 发展路线图:前三阶段建立起” 对应 / 感知 / 生成” 的能力基础,当下处于交互式 omni-modal 与具身模型这一前沿,再往后是因果 – 上下文 AVI 与可验证的 agentic AVI—— 下文六大主轴正对应路线图右侧两段需要补齐的关键能力。
论文最后给出六条未来研究主轴,覆盖音画同步、因果事件 grounding、空间音频推理、长程上下文记忆、可控生成、安全治理、水印与数据合规等关键问题,并强调这六轴 不是更长的待办清单 , 而是把 AVI 与” 通用多模态学习” 区分开的结构性能力 :
1. 因果事件 – 声源 grounding: 建模延迟、遮挡、画外音、多源混合下的源级 / 事件级 / 因果对齐,把音画同步推向因果可解释层面;
2. AV 世界模型: 把音视频当作几何、材质、动力学、可供性、用户 / 社交状态的互补证据,并以空间音频推理作为关键能力;
3. 长程 AV 上下文记忆: 构建流式 / 情景 / 语义多层、可选择、可溯源的 AV 记忆,而不是简单加长上下文窗口;
4. 因果 AV 干预与可控生成: 让生成与编辑支持对物体、声音、身份、情绪、空间、时间的局部、因果、同步干预;
5. Verifier 与 Reward 生态 : 超越 FAD / FVD / CLIP / SyncNet 这些代理指标,发展面向 grounding、物理合理性、音频不可替代性、长程一致性、任务效用的验证器;
6. 交互式与负责任 AV I : 在低延迟、隐私、版权、水印与数据合规等安全治理约束下,把 AV 模型变成可被信任的实时合作者。
这六条主轴,每一条都几乎对应着某条工业界正在追的产品线:
因果事件 – 声源 grounding ↔ 视频理解 / 视频搜索;
AV 世界模型 ↔ 世界模型 / Sora 系列;
AV 上下文记忆 ↔ 长会议、长直播、长游戏陪伴的 omni assistant;
因果 AV 干预 ↔ AI 视频后期 / 影视特效;
Verifier & Reward 生态 ↔ AI 视频质量评估、自动剪辑;
交互式与负责任 AVI ↔ omni 助手 / 实时陪练 / 具身机器人。
七、对行业意味着什么
最后做一个简短的产业向解读:
1. 论文给出了” 音视频大模型” 研发的统一坐标系。 不论你是在做视频生成、数字人 / 说话头、omni 助手,还是 AV 智能体或具身机器人,都能在这张全景图里找到自己的位置,进而判断邻接技术栈在哪里、可借鉴的方法是什么。
2. 它明确指出了 omni-modal 模型的下一波竞争点不在” 能不能听 / 能不能看”,而在” 能不能在统一 backbone 或统一生成链路下做长程 AV 上下文推理 + 原生音画同步生成 + 实时闭环交互”。 GPT-4o、Veo-3、Seedance 2.0、Qwen-Omni、OpenVLA,以及 HappyHorse 这类近期联合音视频生成尝试,都在从不同侧面推进这一趋势。
3. 评测体系正在重塑。 论文对 FAD / FVD / CLIP / SyncNet 这类代理指标在音画同步与音频不可替代性维度上的局限做了系统讨论,并明确把 verifier & reward 生态列为未来主轴之一。可以预期未来一年,AV 评测会从” 主观打分 + 代理指标”,走向” 任务效用 + 物理合理性 + 安全可溯源” 的多维评测体系。
4. 安 全治理 已经从锦上添花走向基础设施层面。 深伪、版权、隐私、水印与数据合规、实时滥用,将成为部署侧不可绕过的硬约束。
对任何在做 AV 大模型、omni-modal 模型、视频生成、数字人 / 说话头、AV 智能体、具身机器人、空间音频或深伪检测的团队,这篇综述长文都值得完整通读一次。
配套的 Awesome-AVI 仓库会持续更新方法、数据集与 benchmark,研究者可以围绕它跟踪最新进展。
]article_adlist–>
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

