背景:自回归图像生成的崛起与推理瓶颈
大语言模型的成功让 “next-token prediction” 这套范式从文本延伸到了图像领域。把图像用视觉分词器编码成离散 token,再一个接一个的预测出来 —— 这就是自回归(AR)图像生成的核心思路。从早期的 PixelCNN、iGPT、Parti,到近期的 Emu3.5、LlamaGen、Lumina-mGPT、GLM-Image,AR 模型的生成质量已经全面逼近甚至超过了扩散模型。
但 AR 模型有个绕不开的问题: 慢 。标准的 raster-scan 解码从左到右、从上到下,一步只出一个 token。生成一张 512×512 的图要走 32×32 = 1024 步串行前向传播,单卡耗时超过两分钟。延迟随分辨率线性增长,GPU 的并行算力也用不起来 —— 高分辨率和实时场景下,基本没法实际部署。
现有加速方案
为了突破这一瓶颈,研究者们已经探索了多种加速策略,但都面临不同的局限:
重新设计生成范式: 例如如 VAR 的 “下一尺度预测”、NAR 的 “近邻预测”、PAR 的分组并行解码,虽然能大幅降低解码步数,但这些方法需要 从头预训练 ,无法复用已有的大规模预训练 AR 模型,训练成本高昂。
离散扩散适配 : 例如 Emu3.5 原文采用的 DiDA,他们通过后训练将 AR 模型改造为支持并行解码的离散扩散模型。但这种方法 改变了原始的预测目标 ,引入了预训练和推理之间的不一致性,往往导致生成质量显著下降,在我们的复现实验中,相同数据量,Emu3.5 在 block diffusion 后训练过程中,geneval 分数会在总体会有一个比较大的 drop
推测解码 : 作为一种无需训练的加速插件,实际加速效果受限于草稿模型的接受率,提升效果相对比较有限。
这就引出了一个关键的开放性问题: 能否在不从头训练、不改变原始预测目标的前提下,将已有的预训练 AR 模型改造成高度并行的生成器,同时继承其强大的生成能力?
来自浙江大学和阿德莱德大学的研究团队提出了 FlashAR —— 一个轻量级的后训练加速框架。 不需要从头训练 ,在 Emu3.5-Image-34B 模型上,仅用原始训练数据的 0.05%(约 8 万张图片),就能将预训练好的自回归模型改造成高度并行的生成器 Emu3.5-34B-Flash,实现最高 22.9 倍 的端到端加速。


论文标题: FlashAR: Efficient Post-Training Acceleration for Autoregressive Image Generation
论文主页:https://lxazjk.github.io/FlashAR/
论文链接: https://arxiv.org/abs/2605.09430
代码链接: https://github.com/lxazjk/Emu3.5-FlashAR
核心思路:从 “逐个生成” 到 “对角线并行”
传统的自回归图像生成模型遵循严格的光栅扫描顺序 —— 从左到右、从上到下,每一步只预测水平方向的下一个 token。对于一张由 H×W 个 token 构成的图像,需要 H×W 步才能完成生成。
FlashAR 的关键洞察在于:图像天然具有 2D 结构,如果我们为模型新增垂直方向的下一个 token 的预测能力,在每个步骤中,水平解码头和垂直解码头并行工作,解码步数从 H×W 骤降至 H+W-1。以 512×512 分辨率(16×16 下采样倍率)为例,解码步数从 1024 步直接降到 63 步。
但要让一个已经训练好的 “水平方向” 预测模型具备 “垂直方向” 预测能力,并不容易。FlashAR 为此设计了三个关键组件:
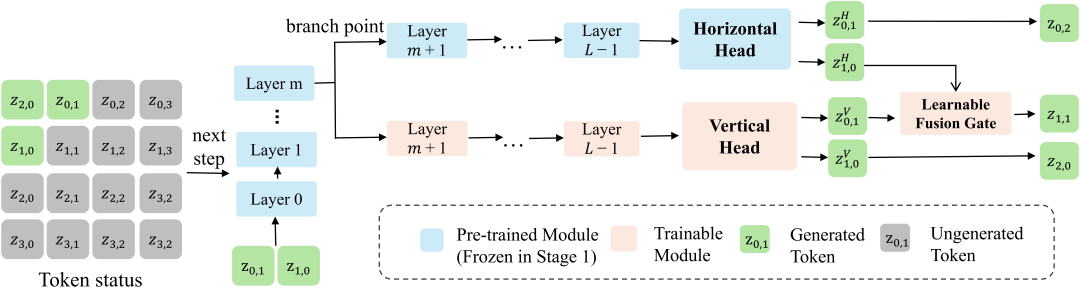
1. 中间层分支(Intermediate Branching)
FlashAR 没有把轻量级的 Vertical Head 接在预训练模型的最终层,而是从中间层分出一条支路,让它和原有的水平预测头并行工作。
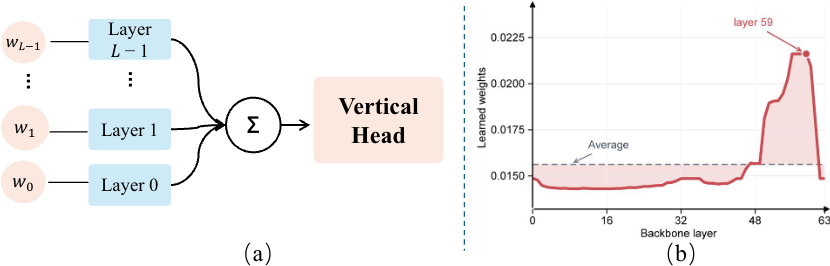
为什么不直接用最终层?因为经过完整训练后,最终层特征已经更偏向原本的水平方向光栅预测任务,针对这个目标做了充分适配,但也因此不一定适合再拿来做垂直方向预测。相比之下,中间层往往还保留着更丰富的二维空间信息,用来适配新的预测方向会更自然。
这样的设计还有一个额外好处:从中间层分支之后,Vertical Head 可以和原有分支并行执行,从而为整体吞吐带来提升。
我们也在消融实验里验证了这一点。具体来说,我们用 linear probing 系统评估了预训练模型不同层的特征,结果发现,最终层特征并不是最适合做垂直预测的。这也进一步支持了我们从中间层引出 Vertical Head 的设计。
2. 可学习融合门(Learnable Fusion Gate)
水平和垂直方向的预测分别建模了互补的空间依赖,其贡献在不同空间位置上并不一致。基于这一观察,FlashAR 引入了一个轻量级的 MLP 融合门,在逐位置的粒度上自适应地融合两个方向的预测结果,以避免简单平均所导致的预测模糊。
3. 两阶段适配训练(Two-Stage Adaptation)
具体而言,训练过程分为两个阶段:
在第一阶段,冻结骨干网络,仅优化垂直预测头,以使其快速学习到有意义的预测能力;
在第二阶段,进一步联合微调垂直预测头和骨干网络,使模型更好地适配新的解码范式。这样的渐进式训练策略提升了后训练过程的稳定性,并提高了数据利用效率。
在推理阶段,FlashAR 还部署了硬件感知的推理优化管线:利用 FlexAttention 动态编译稀疏的二维近邻注意力掩码,配合批量化 KV 缓存更新,将理论上的并行性切实转化为真实的加速效果。
实验结果
Emu3.5-Image-34B 加速
将 FlashAR 扩展到 340 亿参数的 Emu3.5 模型上,是对框架能力的严格考验:
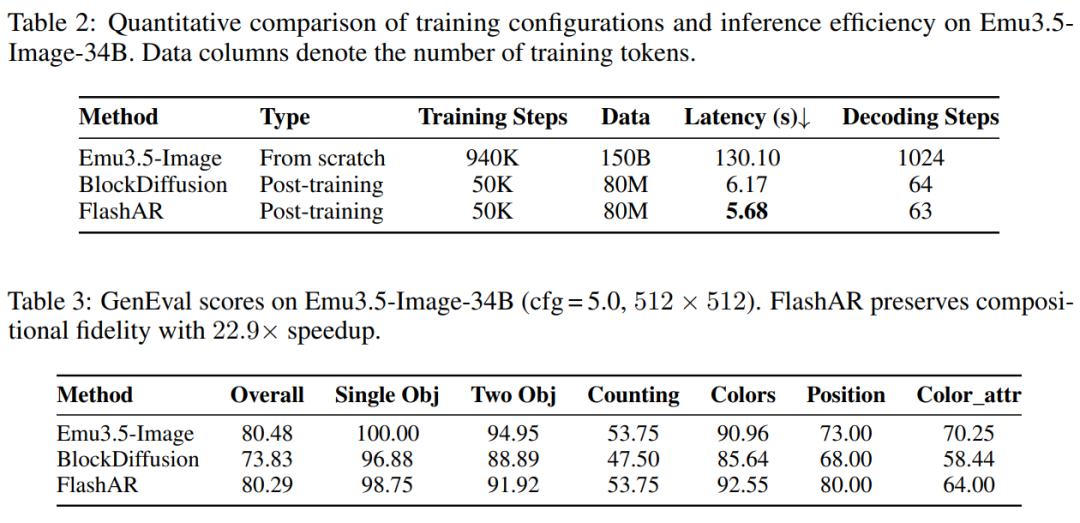
用 0.05% 的原始训练数据(80M token,约 8 万张图片),FlashAR 将 512×512 图像生成速度从 130.10 秒压缩到 5.68 秒,实现 22.9 倍 加速。更关键的是,加速几乎不损失质量。在 GenEval 基准上,FlashAR 的 GenEval 总分仅下降 0.19 分(80.48→80.29),在颜色(+1.59)和位置(+7.00)两个子项上甚至超过了原始模型。相比之下,BlockDiffusion 在相同设置下性能大幅下降至 73.83。
ImageNet 类别条件生成
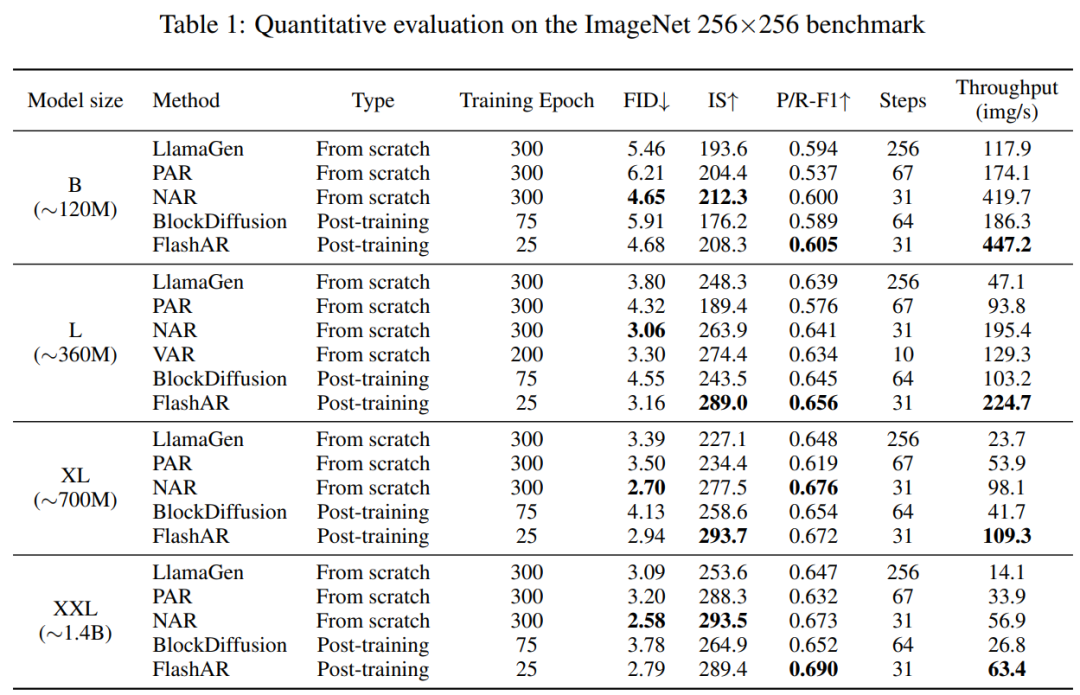
在 ImageNet 256×256 基准上,FlashAR 在四个模型规模(B/L/XL/XXL)上全面超越现有后训练方法 BlockDiffusion。
值得注意的是:
FlashAR-L 的 IS(289.0)甚至超过了从头训练的 NAR-L(263.9) ,而 FlashAR 仅需轻量级后训练;
FlashAR-B 达到 447.2 img/s 的吞吐量 ,超过了 NAR-B(419.7 img/s);
FlashAR 仅需 25 个 epoch 的后训练 —— 只有 BlockDiffusion 训练量的 三分之一。
为什么 FlashAR 如此高效?
我们总结了 FlashAR 的核心优势
无 需从 头训练 :直接复用现有预训练 AR 模型,通过轻量后训练实现加速;
数据极致高效 :仅需 0.05% 的原始训练数据;
性能保持优异 :生成质量几乎无损,部分指标甚至提升;
框架通用性强 :在 LlamaGen(120M~1.4B)和 Emu3.5(34B)上均验证有效;
实际加速显著 :最高 22.9 倍端到端加速。
FlashAR 证明了一个重要观点: 通过精心设计的后训练适配,可以在几乎不改变原始模型训练目标的前提下,将自回归模型改造成高度并行的生成器 ,完整继承预训练模型的强大能力。
]article_adlist–>
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

