维权提醒:如果你或身边的朋友近五年内因投顾公司虚假宣传、诱导交费导致亏损,别放弃!立即联系小羊维权(158 2783 9931,微信同号),专业团队帮你讨回公道!

<h1>Databend 是什么?</h1> Databend 于 2021 年 3 月成立,团队成员主要来自 ClickHouse 社区、Google、阿里云、青云和 OB 等国内外知名数据库团队。整个团队有着深厚的行业背景,几乎每个人都在数据库领域深耕了十年以上。

目前 Databend 的产品线分为两条:一是 Databend Cloud。目前主要面向海外市场,在很多场景下支持单表数据规模达到 PB 级;二是私有化部署企业版。在国内已与省级大数据交易所、证券公司和移动运营商等都有合作。Databend 产品完全基于 Rust 开发,代码已在 GitHub 上开源,欢迎大家参与。社区对 Databend Rust 技术栈的评价也非常高。从 GitHub star 数来看,海外用户的关注度甚至占了一半以上。
在云时代,所有基础架构都值得重新设计。Databend 的定位是在云时代为大家提供一个低成本、易用且高性能的数据平台。尽管业界已有许多相对成熟的解决方案,但在云端如何实现最低成本、最优易用性和最佳性能,仍值得我们不断探索。
此外,云端为我们带来了许多以往难以实现的能力,比如跨国数据中心的统一管理,甚至异地多活的数据中心建设。借助云上如 S3 等对象存储服务,异地复制、跨 IDC 建设变得非常方便。同时,全球范围内写入 S3 数据不收取费用,我们也可以利用这一特性高效汇总全球数据。
在高可用方面,传统自建数据库时需要自行设计存储和计算的高可用机制,而在云端,对象存储本身已保证高可用,计算资源则可以依托 Kubernetes 等技术平台实现弹性和高可用。
现在很多用户都采用多云策略,在一朵云上使用一些产品,在另一朵云上选择其他方案。Databend 是一个跨云解决方案,目前主流云平台的 Marketplace 都支持部署。无论用户选择哪个云平台,我们都可以支持。
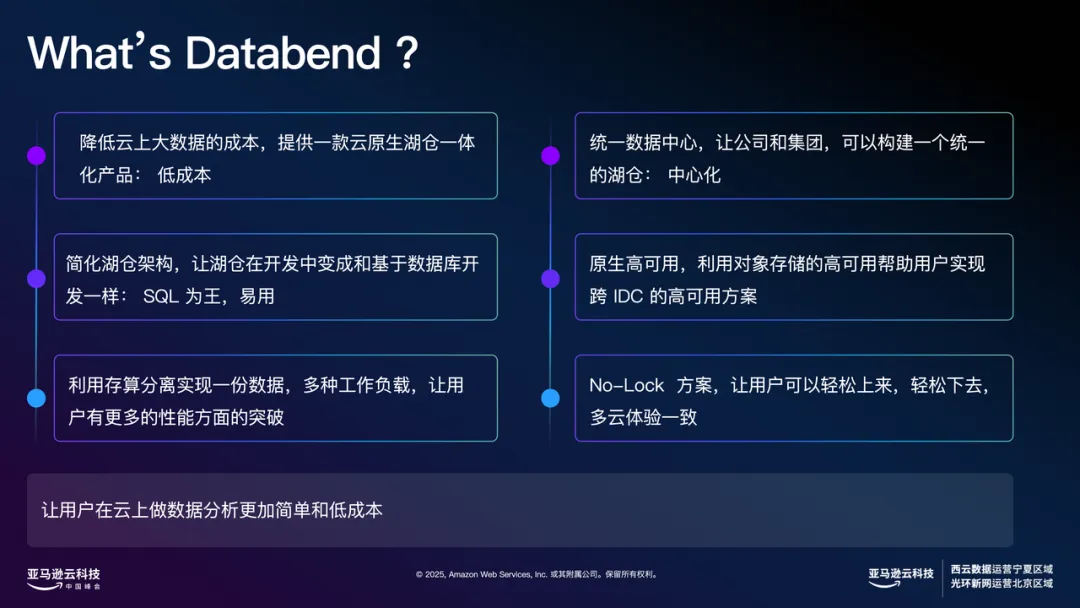
Databend 的架构非常轻量,分为两个核心角色:一个是元数据节点,负责管理系统元数据,通常只需 3-5 个节点即可支撑每秒上百万并发,以及单租户上百万张表的场景。另一个是计算节点(Query 节点),计算节点本身是无状态的,通过两个标签绝对它在哪个租户和集群。租户决定数据的可见性,集群决定算力的分配。
底层采用基于 S3 的共享存储架构,数据接入可由单独集群负责,适应实时或分钟级数据接入需求。实际在 Amazon 上的测试中,16 核心机器每秒数据处理能力可以达到 500-700 万条。
数据治理任务则通过独立的集群来处理,可借助 Spot 实例大幅降低成本。对于数据挖掘、探查等高负载任务,每个计算集群资源完全独立,不会影响主业务集群,真正实现了存算分离和弹性伸缩。资源可以随用随拉,闲时自动收缩,数据只需存一份即可。
下面我想通过一个具体案例,带大家感受一下这种平台架构的独特魅力。
Databend 的架构实际上支持两种模型,上图是其中一种模型。以当前 AI 时代为例,许多企业都在思考如何利用 AI 赋能业务。通常,第一步需要将分散的数据收集起来,将非结构化、半结构化数据转化为结构化数据。过去,每个部门如果要做一次 AI 训练实验,经常需要从其他地方拉取数据,或者部门之间合作时反复进行数据同步,有时甚至需要每五分钟同步一次,数据同步任务十分繁琐且耗时。
现在,云上的理念发生了变化。我们希望做到”一份数据,多方共享”,避免数据反复搬迁和多次校验。无论是总部向集团内各公司共享数据,还是下属公司向总部共享数据,都无需重复上传和下载。
以国内某手机零售商为例,过去,每个门店的库存数据都需要由仓管人员每天汇总并上报总部。采用 Databend 的架构后,每个租户的数据都可以直接在总部系统中注册一份,总部能够实时全局查看每个用户的具体情况。这样,日常的数据对账和同步工作变得更加高效透明,大大节省了人力和时间。
这种云端架构的优势还体现在存算分离和数据共享上。只需存储一份数据,就可以支持多种业务场景,甚至实现与多个用户的灵活共享,从而极大减少了数据同步和核对的工作量。
另外,我们在 S3 上也实现了高效的数据压缩。例如,订单类数据的压缩率可以达到 30 到 40 倍,日志类数据压缩率更高,部分甚至能达到 50 到 100 倍。这些优化让我们在存储和传输层面都实现了极大的成本节约。
我们的最终目标就是让用户只需维护一份数据,就能满足多种应用需求。
还有一个典型场景,是我们当前应用较多的——偏向实时计算的业务模式。用户数据一经接入,平台便能进行实时处理和治理,并及时向下游系统提供服务。比如,将处理后的数据投递到 MySQL 或 Redis 中,再比如在游戏场景下,玩家每打完一局游戏,所有相关数据会立即被动态计算,玩家可以立刻看到本局的数据统计,了解队友表现是否存在问题,是否有人作弊等。这些能力让企业能够实时激励或处罚相关行为,实现业务流程的自动化与智能化。这类实时模型在我们的架构下都能顺畅、高效地运行。
为什么要选择 Databend 以及为什么选择 Spot 实例?
接下来谈谈 Databend 为什么会选择 Spot 实例和 Graviton 这两个产品。其实这个选择源自于我们在湖仓架构落地过程中的实际需求。我们希望为企业用户,尤其是数据量在几个 TB 到 10 TB 以内的公司,提供极具性价比的数据分析能力——理想状态下,每月大数据分析的成本能控制在 1000 到 2000 美元以内。如果能够实现这一点,对企业而言将大大降低数字化转型和数据分析的门槛。因此我们围绕这个目标,持续探索并实践了 Spot 和 Graviton 的各种可能性。

首先,选择 Spot 实例是出于成本和资源弹性的考量。在具体实践中,我们以 Kubernetes(K8s)作为资源调度和管理平台,利用 Spot 实例灵活调度计算资源。资源的声明和分配也借助 Terraform、Prometheus 等工具实现自动化和声明式运维。只需预先定义好资源需求和分布,平台就可以自动拉起合适的实例,无需人工反复干预。
比如说,在对公网提供开放式服务、支持上万人注册的场景中,每个人对应一个独立的 warehouse,实际资源消耗可以根据需求灵活控制,真正做到了弹性伸缩,极大地降低整体资源成本。
另外,数据分析和处理任务本身具有强烈的突发性,有的用户喜欢在夜间批量跑大任务,白天科学家则进行一些探索性分析。这种波峰波谷的资源需求非常适合用 Spot 实例来动态调度,不仅省钱,也让资源分配更加高效。包括我们自己的开发、CI/CD 流程、代码提交和自动化测试,也都通过拉起 Spot 实例来完成,大幅降低了运维和测试成本。
Graviton 方面,我们对其性价比优势感受尤为明显。传统上,大家关注 benchmark 成绩,但现在海外客户更关心”跑完一个标准测试到底花了多少钱”。例如在 16 核 64GB 的机器上跑 TPCH-100 标准测试,而 Graviton 实例无论在价格还是性能上都表现优异。
另外,在高并发场景下,Databend 的表现也非常出色。由于我们本身是基于 Rust 开发的产品,整体兼容性和移植性很强,无论是 x86 架构还是 Arm 架构(如 Graviton),用户几乎无需感知差异,直接编译即可运行。
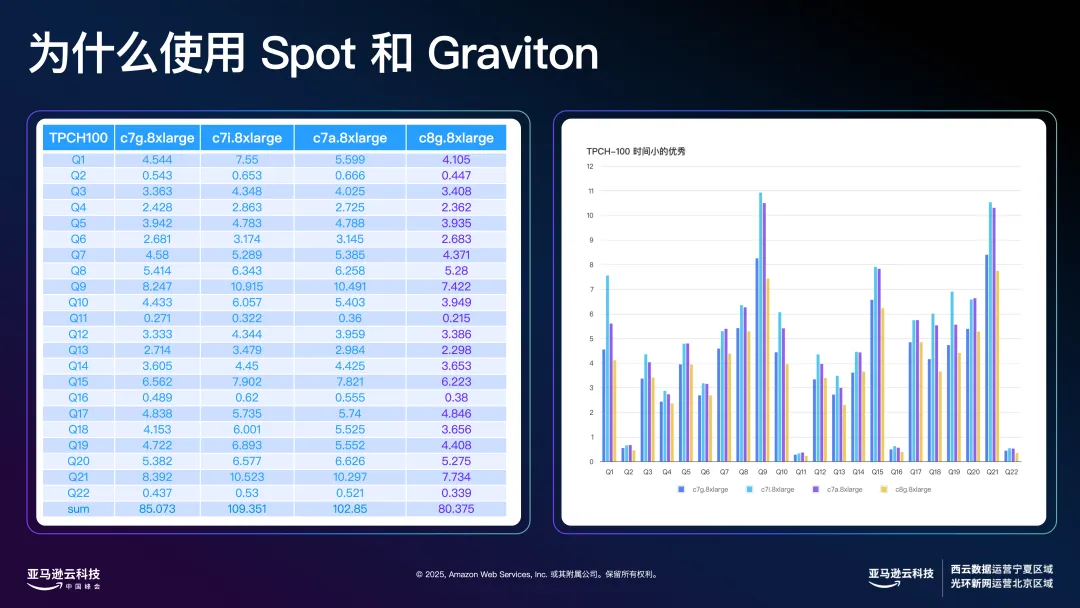
在我们的性能测试中,主要选用了三四类实例:C7i、C7a、C7g 以及 C8g。其中,C8g 属于 Graviton 的第四代产品,目前英特尔和 AMD 尚未有直接对标的同类产品,因此只能与 C7 系列进行横向对比。
具体对比来看,C7g 在高并发、数据密集型计算场景下的性能显著优于 C7i,虽然 C7g 的发布时间比 C7i 还早,但实际测试中表现更为优越。此外,C7g 和 C8g 在 Q1 指标上的表现也接近于 C7i 的两倍。如果看整体执行时间,C7g(32 核 64GB 配置)单实例运行 22 条 TPC-H 查询可以进入 100 秒以内,这一成绩已达到海外行业内”TPCH 百秒俱乐部”的标准。实际上,在更低配置(如 16c64g)下,同样能够取得非常不错的成绩。
当然,这里我们并未追求极限速度。如果增加机器数量,三台节点并行的话,总体任务耗时还可大幅缩短,最快能进入 50 秒以内,实现极高的并行效率。
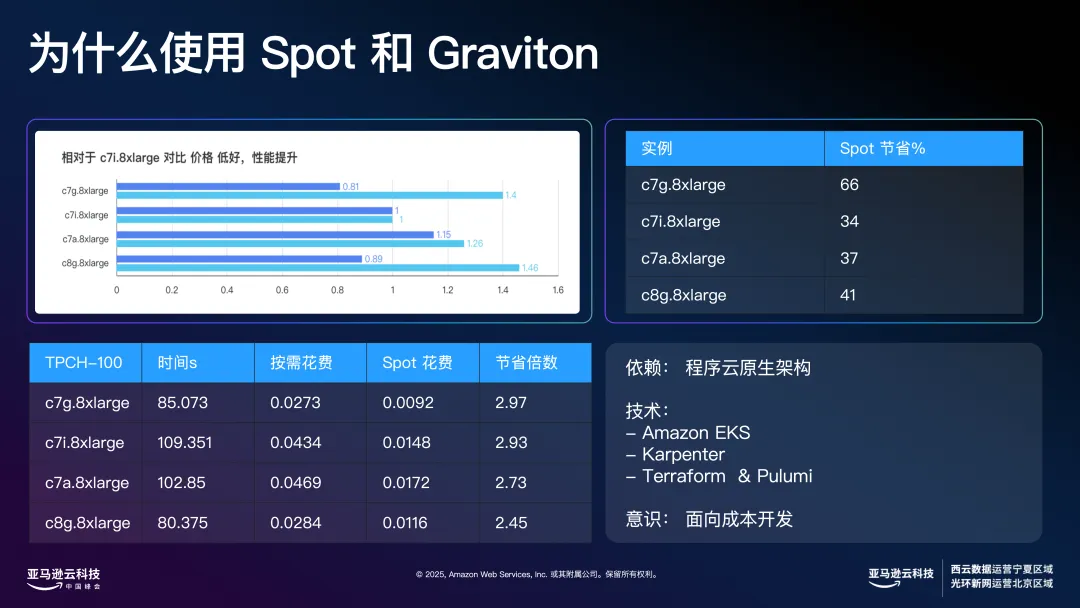
如果从价格维度来看,以 C7i.8xlarge价格为基准标定。深蓝色代表价格,浅蓝色代表性能。C7g.8xlarge 的价格比 C7i.8xlarge 便宜约 20%,而性能提升达到 40%;C8g.8xlarge 的价格便宜约 10%,性能提升接近 50%。在这种对比下,C7g.8xlarge 和 C8g.8xlarge 的性价比优势非常明显。
在海外客户的实际应用中,大家越来越关心”完成一次标准测试实际花了多少钱”。以我们在 TPCH-100 测试为例,按需计费模式下,单次测试花费大约只有 0.02 美元。综合来看,C7g.8xlarge 的性价比无疑是最优的。
而在竞价实例(Spot Instance)场景下,成本优势更为突出。我们实际测试后发现,仅需极低的成本即可完成复杂的数据分析任务,这种场景下的性价比几乎”令人难以置信”。
另外,在云上进行云原生基础架构部署时,实际上需要围绕如 Amazon EKS、Karpenter、Terraform、Pulumi 等现代云原生工具链来构建资源调度和自动化能力,包括对 Spot 实例的自动订阅与回收管理。例如 Spot 实例在被回收后,如何能够迅速申请到新的资源,有一些实用技巧和注意事项,这也是保障弹性服务稳定性的关键。

在我们自身的开发实践中,尤其是与 GitHub 开源项目的集成方面,大量的自动化服务和测试任务都依赖于 Spot 实例来支撑。例如,在 GitHub 上进行开源项目开发,每一次代码提交(PR)都需要通过完整的测试集验证,而测试集的规模通常非常庞大。以 Databend 为例,SQL 测试用例已接近千万级,每个 PR 都要跑一轮完整的测试,确保所有场景都能正确覆盖。
目前,我们将所有测试用例分为 76 个测试集,涵盖了各种业务逻辑和边界场景,所有这些自动化测试也都是通过 Spot 实例来高效完成,大大节省了云资源成本。同时,在产品发版和持续集成(CI/CD)过程中,我们也充分利用 Spot 实例,实现弹性、高效的自动化发布。
对于 Databend Cloud 的云上用户,我们也采用了按需分配的模式。用户在公有云平台注册时,系统会为其自动分配一个 Spot 实例,但只有在用户真正开始使用服务时,才会动态拉起计算资源,平时不会占用任何资源。这种弹性分配机制,极大地降低了预留成本,也能支持上万人的大规模用户的注册和使用,保证了平台的高可用性与经济性。
Databend Cloud 在 Amzon 上的实践
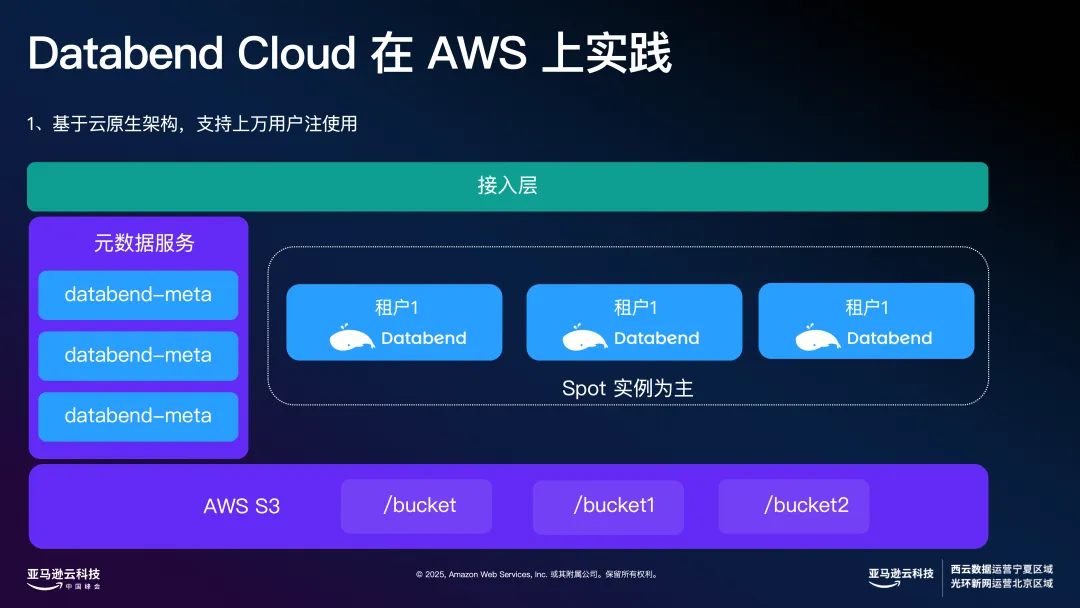
接下来再分享一下 Databend 在 Amazon 上的一些实践经验以及整体的云架构。这个架构的设计初衷,就是为了支撑上万用户的注册与使用。Databend 的方案以 Spot 实例为主,所有新注册的公有云用户,系统默认分配的是 Spot 资源。这些资源是全局共享的,每个用户都拥有独立的 Namespace(命名空间),能够看到自己的数据,而无法访问到其他用户的数据,实现了严格的隔离。
这种弹性分配机制有一个显著优势:只有在实际需要时才会动态申请和分配资源,如果用户没有使用,则不会占用任何资源。这样一来,即便注册用户数快速增长到上万,也不会导致费用激增,整个系统能够平稳高效地运行。
在存储方面,Databend 依赖 S3,并采用高压缩算法,大幅降低了数据存储成本。这也是我们为什么强调使用高性能 CPU ,既能支持高效压缩,也能在解压时保障计算能力,为存储与计算之间找到了最佳平衡点。云上的资源弹性和性价比,让我们在业务创新和架构演进方面有了更多的可能性。
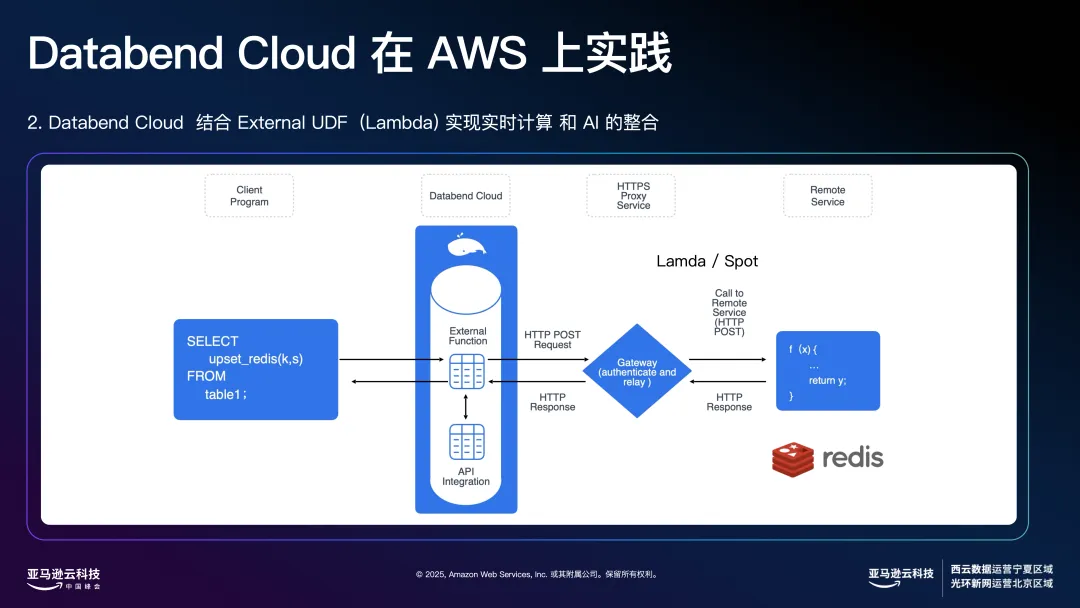
在流式计算能力上,我们解决了以往流式处理框架成本高、门槛高的问题。例如,在游戏行业,玩家打完一局后,系统需要在极短时间内生成战力榜和队友匹配结果。以前,这类需求往往依赖 Flink 等大数据流处理框架,实际部署和运维成本很高。但在我们的方案中,数据从前端传入后,可以在秒级时间内进入 Databend 内部,通过每张表的增量流(stream)机制计算出所需数据。计算过程中,我们支持灵活使用复杂的 UDF(用户自定义函数),这些 UDF 可以运行在 Lambda 或 Spot 实例上,通过负载均衡注册到 Databend Cloud,完成数据清洗、转换和实时入库展示。整体流程非常高效、低成本,且具备极佳的弹性伸缩能力,不会因高并发或突发流量造成服务压力。
有了这样的架构,我们还进一步探索了 AI 能力的集成。当前,AI 已成为数据平台的重要入口。无论是 Snowflake 还是 Databricks,国外领先厂商都在尝试把 AI 能力融合进数据平台。我们同样可以在这一层连接大模型,通过 Python 等方式实现模型集成,并将 AI 算法以 UDF 的形式注册进平台。这样,数据库可以通过调用 UDF 实现自动纠错、日期规范化等智能处理,甚至支持更复杂的语义分析和向量检索等 AI 场景。

例如,早期我们就尝试通过 ChatGPT、OpenAI 等大模型以向量化的方式做了一些自然语义完成和近似度检索能力,把知识库与数据分析系统高度融合。一些先进客户已在实际业务中广泛应用 AI,例如用 AI 做竞争对手广告分析:投放广告后,系统自动分析竞品投放内容,通过近似度和语义分析挖掘市场洞察。
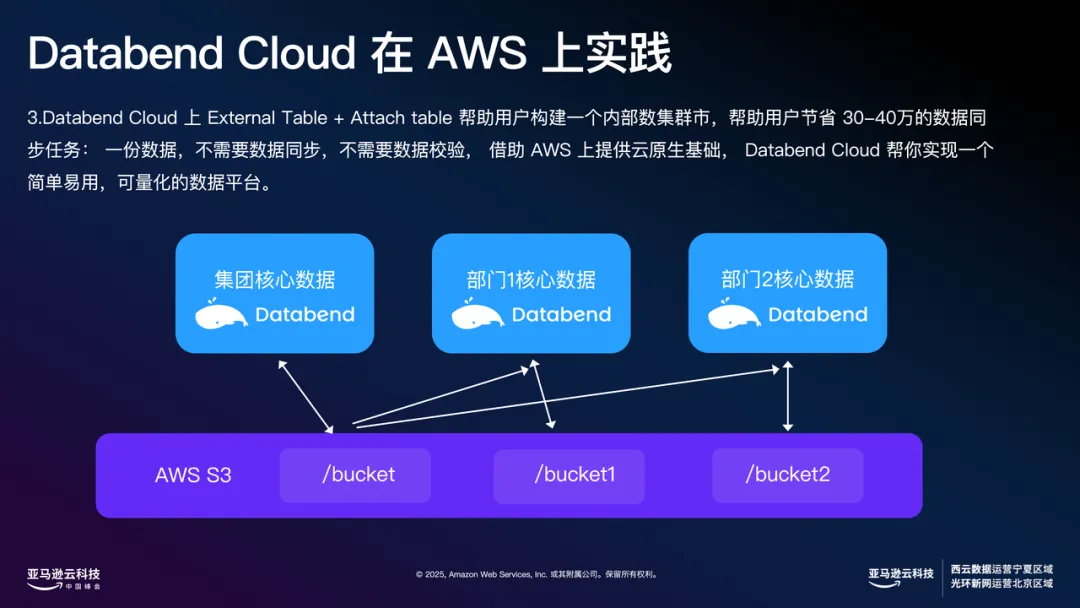
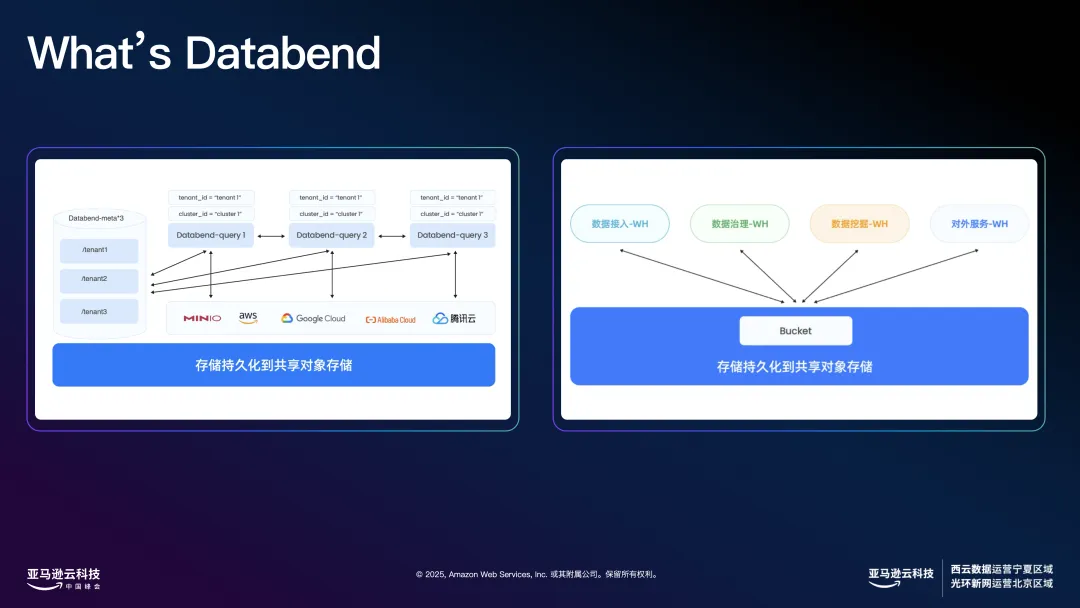
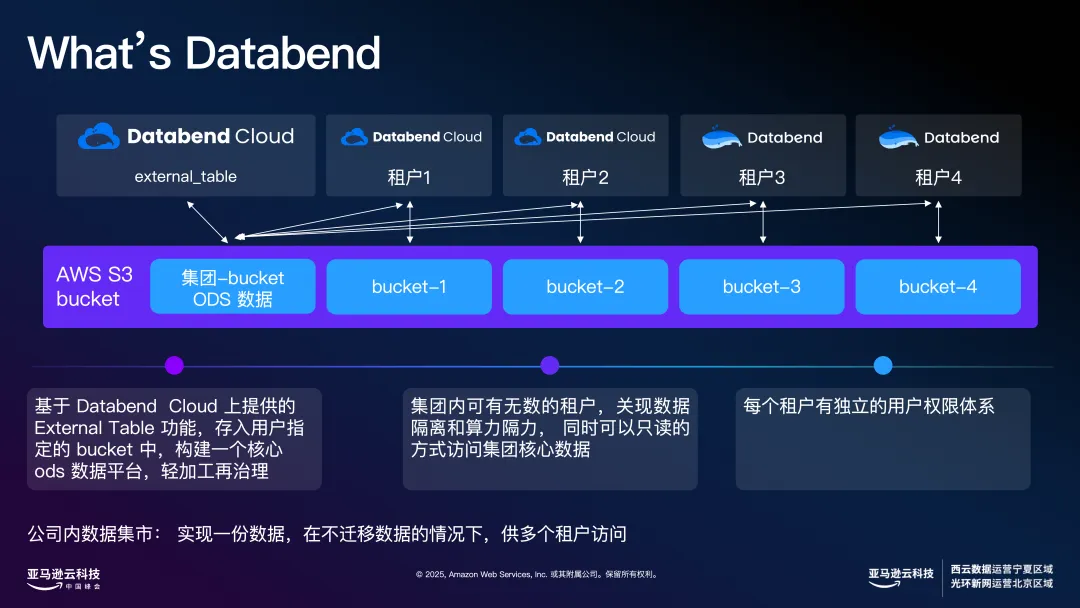
最后一个是目前在 AI 行业做的非常多的场景。用户可以在创建表的时候把 External Table 指定到高性能 SSD 存储上,进一步提升数据共享和分析速度。Databend Cloud 上 External Table+Attach Table 可以帮助用户构建一个内部数据集市,帮助用户节省 30-40万数据的同步任务:一份数据,不需要数据同步,不需要数据校验,借助 Amazon 上提供云原生基础,实现一个简单易用,可量化的数据平台。在 Amazon 上,还可以灵活选择不同存储类型,满足不同业务的高性能需求。
过去一年,Databend 凭借开源、云原生的数据湖仓产品,在全球多个企业场景中落地使用,包括游戏、社交、金融、广告、电商等高并发实时分析场景,并在多个客户项目中实现了成本降低 50% 以上、分析效率提升数倍的显著效果。本次峰会,我们将站在这个全球技术舞台上,与全球开发者与云计算先锋交流最新技术成果与实践经验。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式湖仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
👨💻 Databend Cloud:databend.cn
📖 Databend 文档:docs.databend.cn
💻 Wechat:Databend
✨ GitHub:github.com/databendlab…
</div>

