
<blockquote> 作者:vivo 互联网算法团队
本文入选 EMNLP 2025 Main Conference
EMNLP 会议全称为 Conference on Empirical Methods in Natural Language Processing,由国际计算语言学协会 ACL 举办,是自然语言处理和人工智能领域最重要的学术会议之一。EMNLP 2025 会议共有 8174 篇投稿,Main Conference 接收率仅为 22.16%。

项目主页:
https://github.com/vivo/DiMo-GUI
摘要:
本文介绍了一种无需额外训练的 GUI 定位框架 DiMo-GUI,针对多模态大语言模型(MLLMs)在复杂图形用户界面(GUI)定位任务中的挑战,通过动态视觉推理与模态感知优化显著提升性能。DiMo-GUI 采用逐级缩放的动态定位机制,迭代裁剪聚焦目标区域,减少视觉冗余;同时分离文本与图标模态,独立推理后结合指令评估确定最终目标,有效平衡多模态处理能力。在 GUI 定位任务最新的基准数据集上,DiMo-GUI 相较基线展现显著性能提升。作为即插即用框架,DiMo-GUI 适用于网页导航、移动应用自动化等场景,未来可通过回溯机制进一步提升鲁棒性。
该工作由 vivo 互联网算法团队、加州大学默塞德分校、昆士兰大学共同完成。
一、引言
随着图形用户界面(Graphical User Interface, GUI)在自动化导航和操作系统控制等领域的广泛应用,基于自然语言查询的 GUI 定位(GUI Grounding)成为多模态大语言模型(multimodal large language models, MLLMs)的重要研究方向。然而,GUI 环境的视觉复杂性、语言歧义以及空间杂乱等问题为精准定位带来了显著挑战。
本文基于最新研究《DiMo-GUI: Advancing Test-time Scaling in GUI Grounding via Modality-Aware Visual Reasoning》,介绍了一种无需额外训练的 GUI 定位框架——DiMo-GUI,通过动态视觉推理和模态感知优化显著提升了多模态大模型在复杂 GUI 环境中的定位性能,推动了推理时扩展(test-time scaling)在该领域的发展。
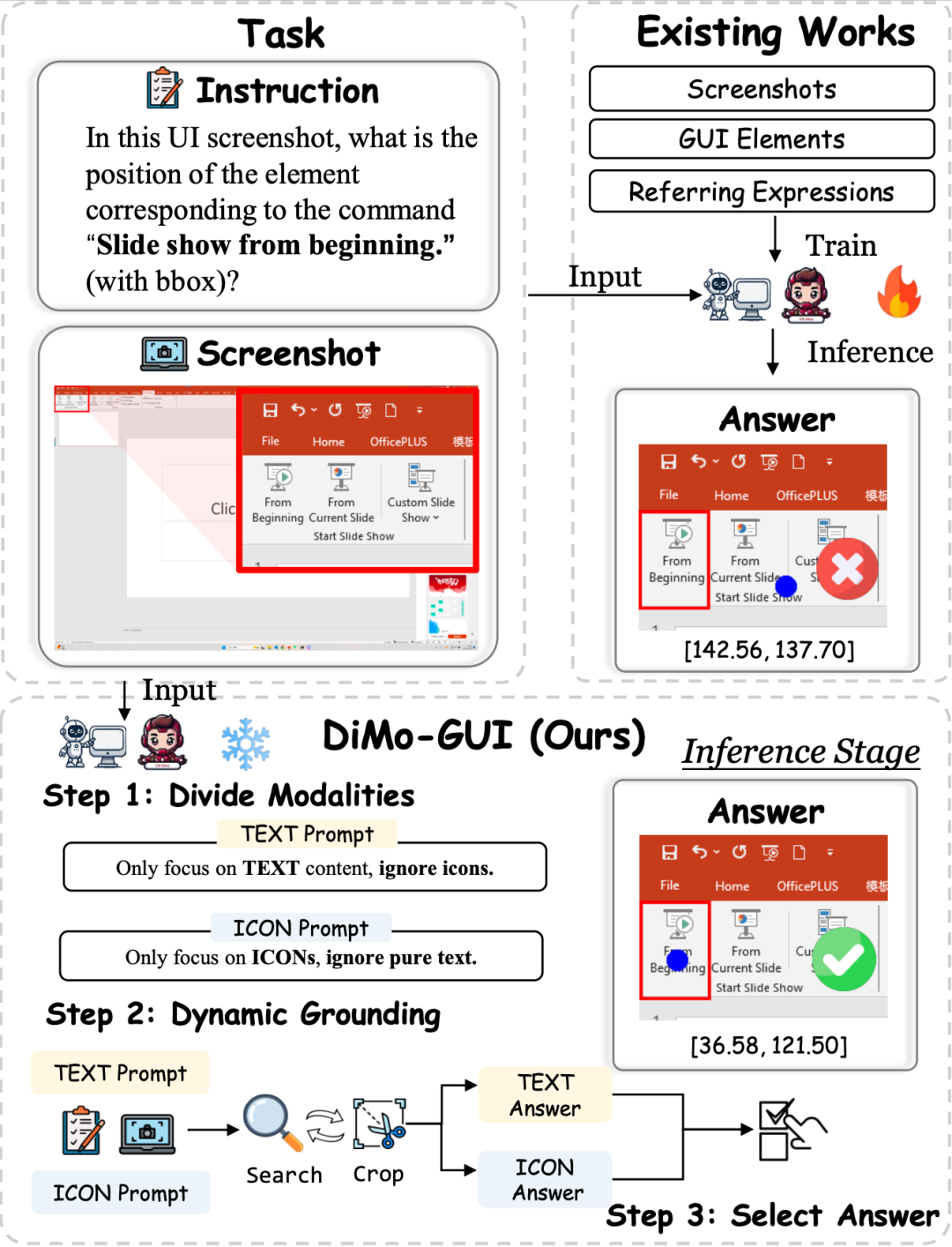
日常生活中,我们与电脑、手机的交互离不开图形用户界面。小到点赞、大到数据分析,我们都希望 AI 能像人一样,理解屏幕上的每一个按钮、每一段文字,并准确执行指令。然而,对于飞速发展中的多模态大模型来说,这却是前所未有的艰巨挑战。在一个复杂的 App、网页或桌面软件中,用户可能随手一句“点击开始播放”,但对于 AI 来说,准确找到这个指令对应的图标/按钮并不简单:
模态混杂:用户界面同时包含文本、图标、背景、装饰性元素等,干扰多;并且大多数 VLM 对文字理解更强,图标处理却弱,造成严重偏差;
冗余信息:高分辨率 UI 中,重要区域可能只占整体的几十分之一,模型容易定位错误区域。
研究发现,传统方法如基于文本推理或单次视觉定位的管道在高分辨率、视觉拥挤的 GUI 中表现不佳。例如在最新的 ScreenSpot-Pro 数据集上,大多数通用模型如 GPT-4o, Qwen2-VL 等只有 1%左右的正确率, 即使是针对于 GUI 定位任务的 ShowUI, Aria-UI 等智能体也只有 10%左右的正确率。
二、关键改进:模态分离 + 动态定位
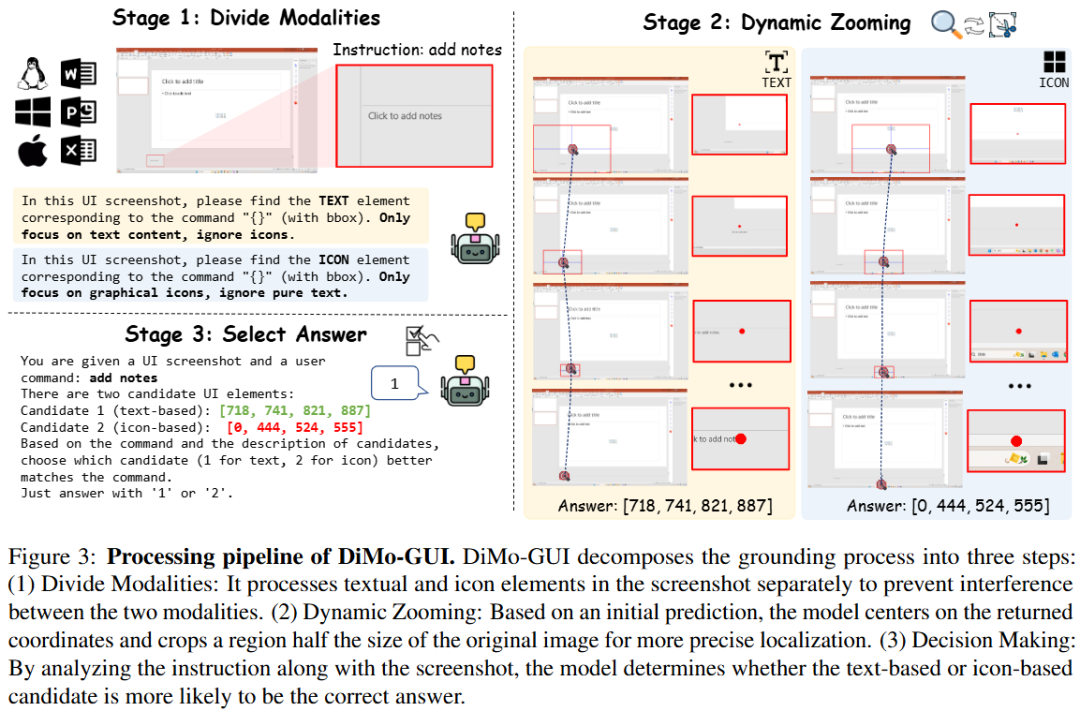
从上述问题出发,该研究推出零训练成本的 DiMo-GUI,通过模态感知的视觉推理推进训练时扩展,显著提升多模态大模型的图形界面(GUI)理解能力。主要的改进方式包括以下两点:
动态视觉定位:DiMo-GUI 采用逐级缩放机制,从粗略预测开始,基于初始坐标生成候选焦点区域,并通过迭代裁剪逐步聚焦目标。例如,首次推理后,模型以预测坐标为中心裁剪半个图像大小的区域作为下一轮输入,显著减少视觉冗余。动态迭代机制根据前后预测的坐标距离(小于图像对角线六分之一时停止)实现自适应停止,避免“过度思考”。
模态感知优化:DiMo-GUI 将 GUI 元素分为文本和图标两类,分别进行独立的定位推理,生成文本坐标(C_text)和图标坐标(C_icon)。随后,模型结合原始指令和全分辨率图像评估两个候选坐标,确定最终目标 (C*),有效平衡文本和图标的处理能力。
这样的方式推动了推理时拓展(Test-time Scaling)在 GUI 定位这一领域的发展,提供了新的思路和方式。
三、实验结果:无需训练和任何额外数据,只在推理阶段就可以大幅提升性能
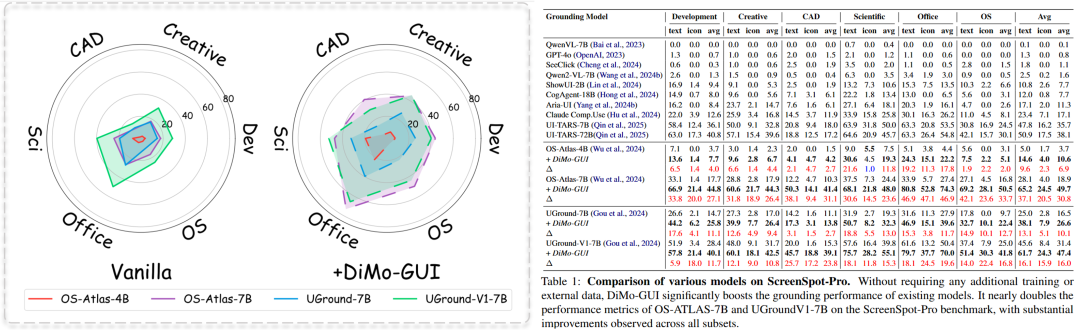
团队在最新的高分辨率 GUI 数据集 ScreenSpot-Pro 上验证发现:
DiMo-GUI 可以作为即插即用的框架大幅提升多个 GUI 模型的性能。
其中 OS-Atlas-7B 在引入 DiMo-GUI 之后获得了超过两倍的指标提升(18.9% — 49.7%), UGround-7B 和 UGround-V1-7B 也均获得了超过 10%的指标提升。
在相对简单的 ScreenSpot 数据集上,DiMo-GUI 同样可以提升多个模型的性能。
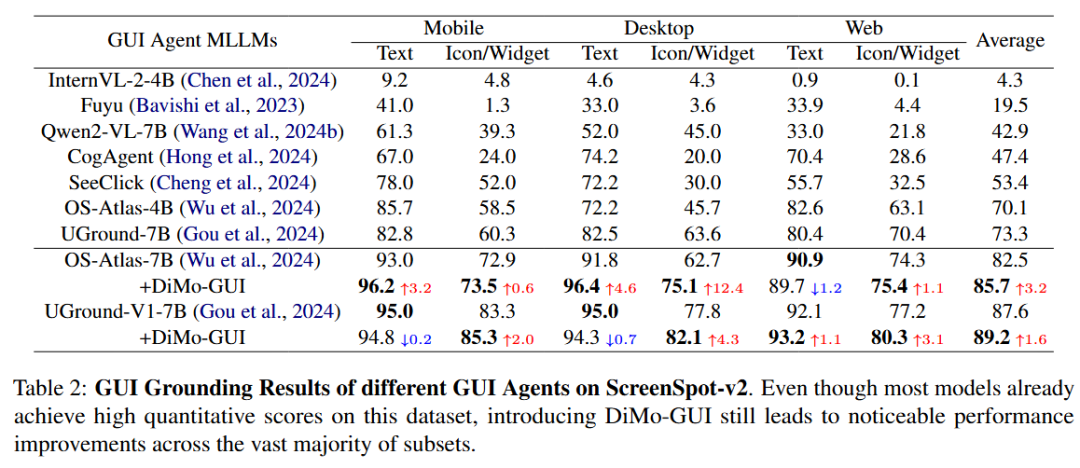
定性结果表示,模型加入 DiMo-GUI 之后可以通过动态定位逐步逼近正确结果。
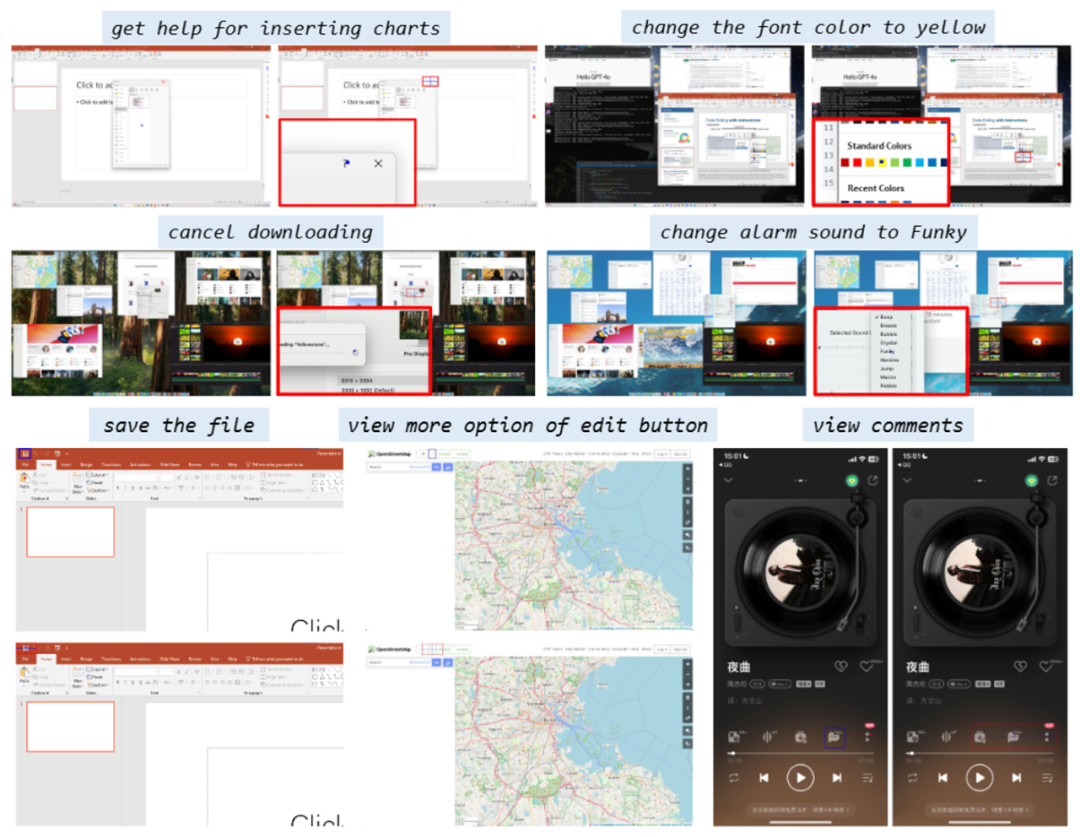
四、总结
DiMo-GUI 提供了一种高效、通用且无需训练的 GUI 定位框架,通过动态视觉推理和模态感知优化显著提升了多模态大语言模型在复杂 GUI 环境中的表现。其“即插即用”特性使其可无缝集成到现有 GUI Agent 中,适用于网页导航、移动应用自动化等场景。未来研究可探索引入回溯机制以纠正早期错误,进一步提升定位鲁棒性。
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


