
<h2>一、概述</h2> 对于分析型数据库系统来说,读取数据所需要的磁盘 IO 和网络资源耗费了大量的机器资源,尤其是存算分离模式下,远端存储的数据通过网络传输到本地进行数据处理,所以数据裁剪能力对于分析型数据库系统来说非常重要。近期的研究中也体现出这点,比如在扫描节点上使用过滤操作可以降低 **50%**以上的执行时间[1],PowerDrill 通过应用恰当的策略可以裁剪 **92.41%**的数据读取,而 Snowflake 的测试显示其在自己的消费者数据集上可以裁剪 **99.4%**的数据[2]。
以上的例子是基于不同的数据集的测试结果,并不具有直接的比较价值,但是我们可以得到一个确切的结论,对于现代分析型数据系统,处理数据最快的方式就是尽可能不去处理数据。在 Apache Doris 中,我们探索了多种方式让系统变得更加智能,从而尽可能跳过不需要处理的数据。本文将对 Apache Doris 中所有用到的数据裁剪优化技术进行展开讨论。
二、相关工作
现代分析型数据库系统中,数据通常以水平分区的方式存储在不同的物理空间当中,通过使用分区级别的元数据,数据库执行引擎可以跳过所有不需要处理的数据。例如使用每一列的最大/最小值和查询当中存在的谓词做比较,从而可以跳过所有不符合条件的分区,具体的方法有 zone map[3]和 SMA[4]。还有一种通用的方法是使用二级索引技术,比如使用 Bloom-filter[5],Cuckoo-filters[6] 或者 Xor-filters[7]。另外,许多数据库也实现了一些数据的动态过滤方法,所谓动态过滤,就是在查询执行的过程中生成过滤谓词,并使用运行中生成的谓词对数据进行过滤,相关研究包括[8][9]。
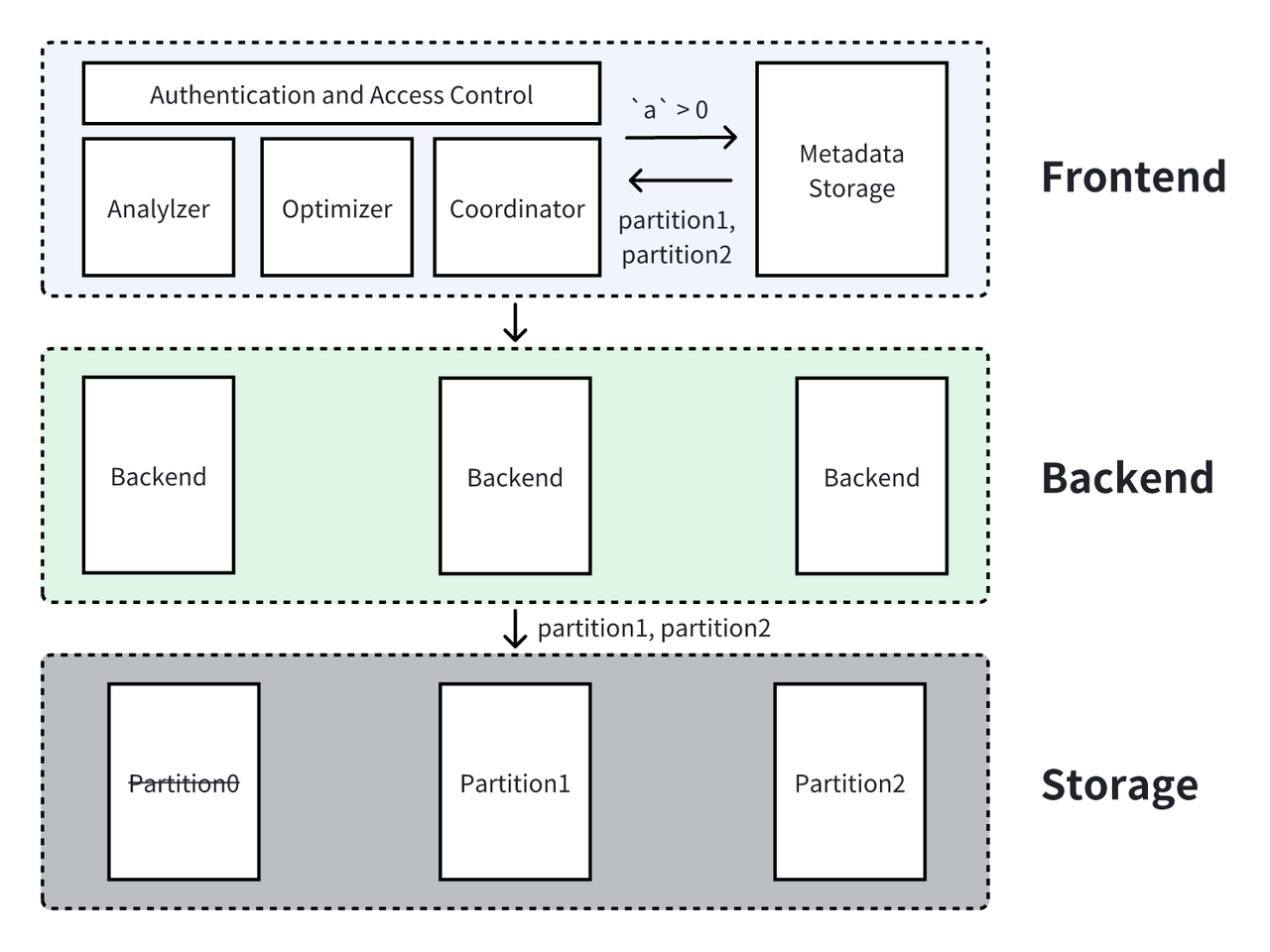
三、Apache Doris 架构介绍
Apache Doris[10]是面向实时分析的现代数据仓库。在这一部分中,我们会简单介绍整体的架构以及现有架构中 Apache Doris 处理数据过滤的概念与能力。
3.1 Apache Doris 整体架构
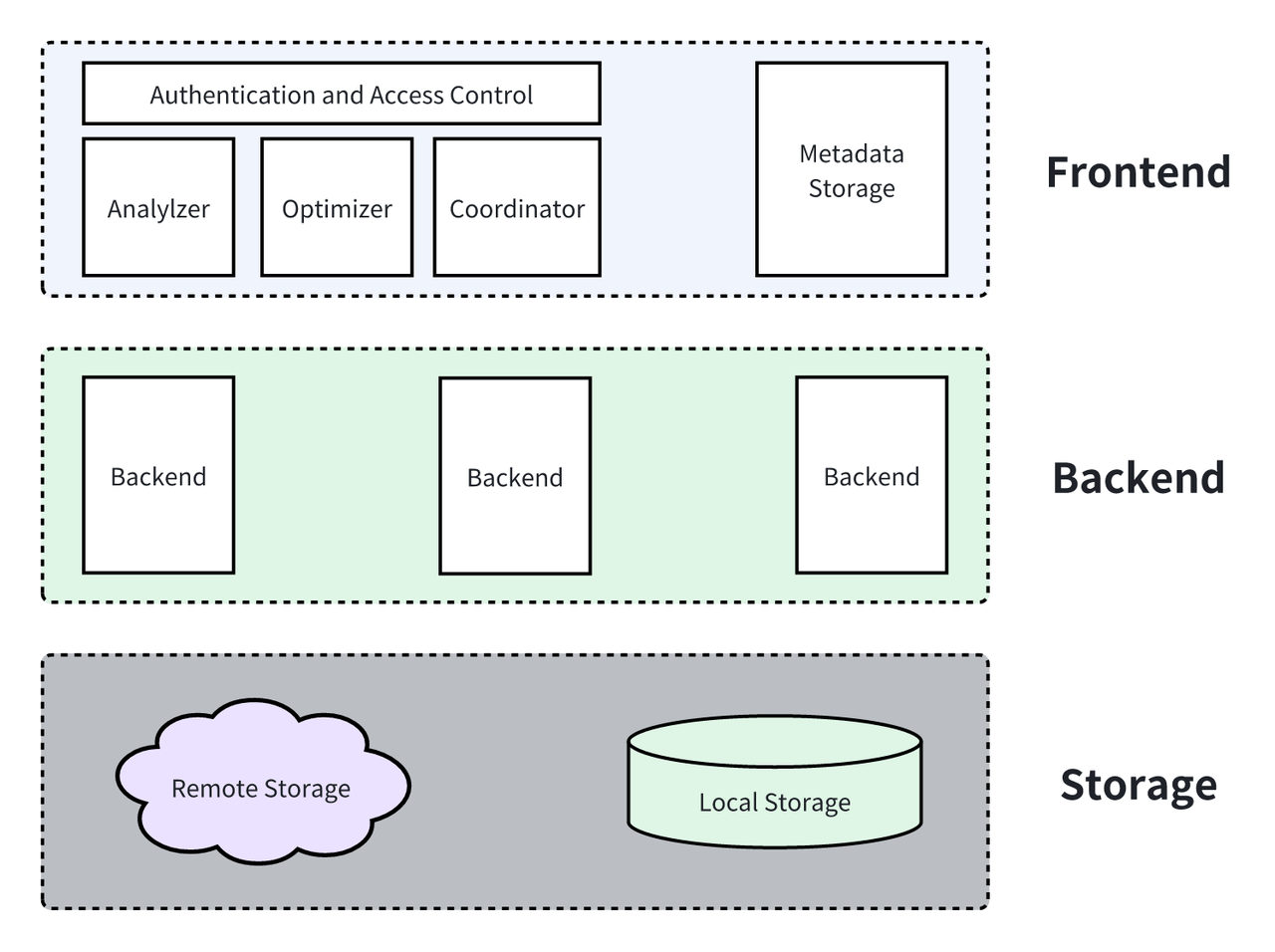
一个完整的集群包括了 Frontend,Backend 和存储组件三个部分,其中:
- Frontend 主要是作为服务接口面向用户,完成对 DDL/DML 等任务进行解析,使用优化器对任务进行优化,收集 Backend 执行结果等功能。
- Backend 作为系统的执行组件,主要通过一系列控制逻辑以及复杂计算操作对数据进行加工最终返回用户需要的数据。
- 存储组件作为数据最终存储的位置,需要管理数据分区、数据读写。在 Apache Doris 中,存储组件根据目的位置分为本地存储和云端存储。
3.2 Apache Doris 数据存储概述
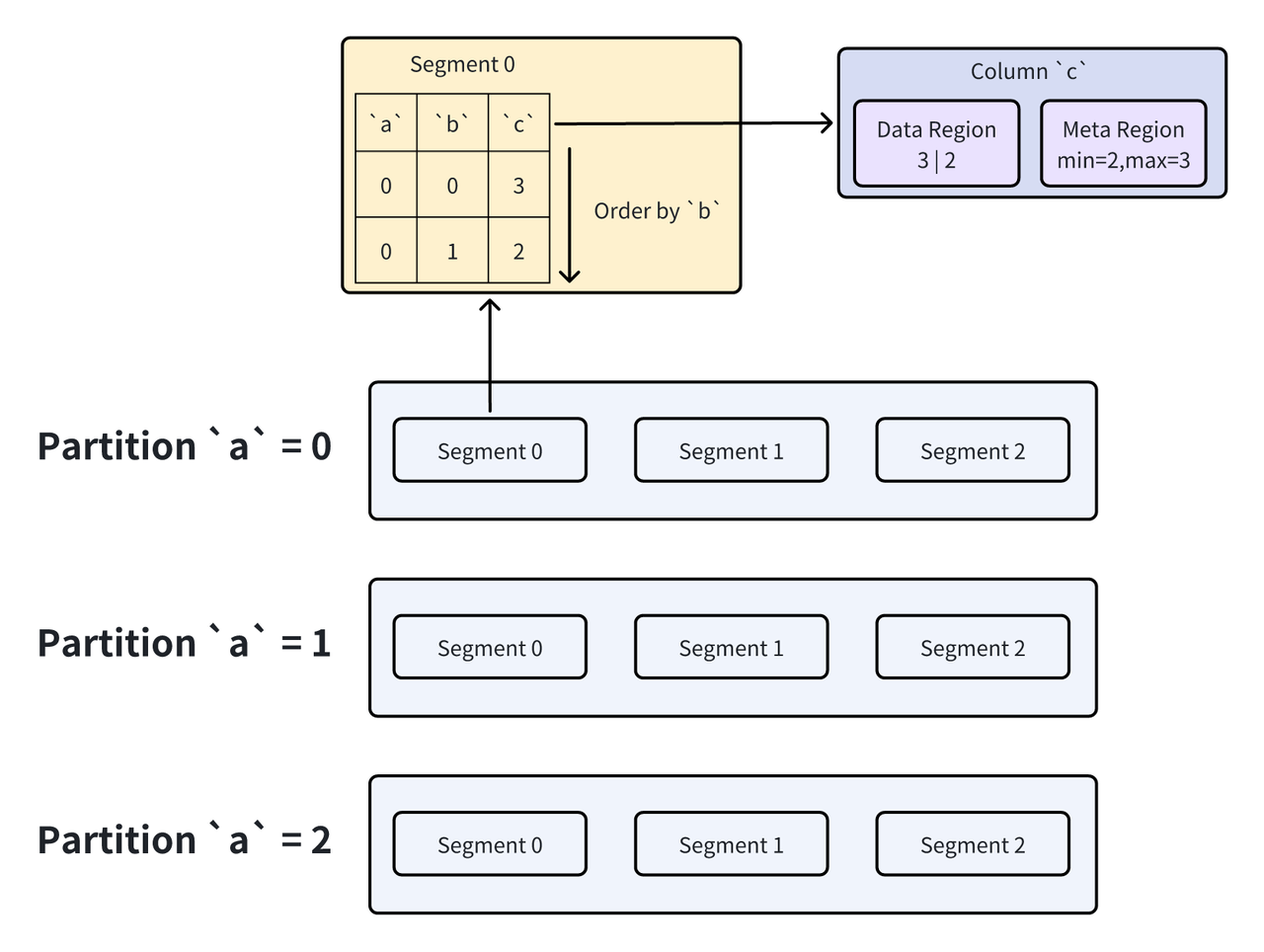
在 Apache Doris 的数据模型中,一个数据表通常包含了分区列、Key 列以及数据列。在存储层中,分区的信息在元数据中进行维护,当有用户的查询到达时,Frontend 可以直接根据元数据的信息决定要读取哪些分区的数据。而 Key 列主要是为了能够在存储层完成一些数据聚合的需求,在实际的数据文件中,由 partition 进一步拆分得到的 Segment 按照 Key 列的顺序对数据进行组织,也就是说,Key 列在 segment 内部是有序的。在 Segment 内部,每一列又以单独的列数据文件进行存储,这也是 Doris 中存储的最小单位的数据文件。列数据文件中又进一步维护了该文件的元数据,例如最大最小值等。
3.3 Apache Doris 数据裁剪概述
根据数据裁剪发生的时间,我们将数据裁剪分为两大类,即静态裁剪 和动态裁剪。其中,静态裁剪指查询 SQL 被查询解析器和优化器处理后直接决定的数据裁剪。通常来说,这种方式主要包括 SQL 中已经被写好的过滤谓词,例如当需要查询 a > 1 的数据时,我们可以在优化器中直接决定不再读取 a <= 1 的全部分区。与之相反,动态裁剪是发生在执行过程中决定的裁剪策略。例如,对于一个包含简单等值内连接(inner join)的查询来说,probe 侧只需要读取与 build 侧值相同的行的数据即可,这就需要我们在运行时动态获取这些值并且使用它进行数据裁剪。
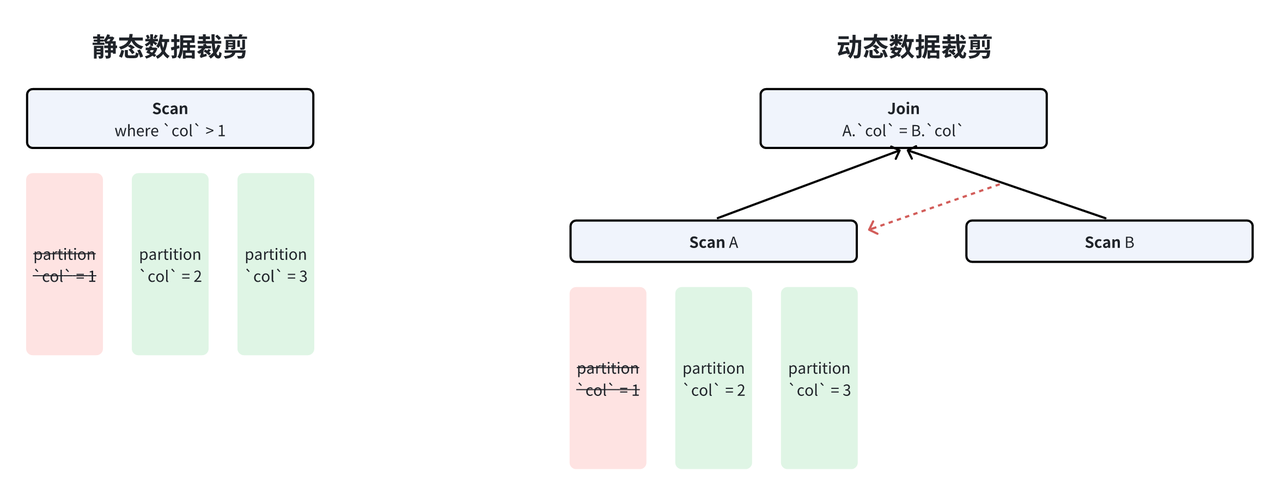
更进一步地,为了详细阐述 Apache Doris 中每一种数据裁剪技术的实现细节,我们根据不同的裁剪方式进一步将数据裁剪技术分为 4 种,分别是谓词过滤 ,LIMIT 裁剪 ,TopK 裁剪 和 JOIN 裁剪。其中谓词过滤由用户的 SQL 决定,所以其属于静态数据裁剪。其余 3 种均属于动态裁剪。
Apache Doris 集群的执行层通常包含多个实例,所以动态裁剪的挑战也越大,这是因为在动态裁剪的过程中,我们需要在多个实例中进行交互与协调。后面也将对这里的一些细节进行展开探讨。
四、谓词静态过滤
在 Apache Doris 中,静态谓词在 Frontend 内部经过 Analyzer 和 Optimizer 之后产生。根据这些静态谓词作用的不同列,其生效的时间也不一样。具体而言,
- 对于分区列的谓词来说,Frontend 能够通过读取到的元数据来确定所需的数据存储在哪些分区中,从而直接对数据分区进行裁剪,这也是最高效的数据裁剪方式。
- 对于 Key 列的谓词来说,由于 Segment 内部以 Key 列的顺序进行数据的组织,所以我们只需要根据谓词生成 Key 列的上界和下界,再通过二分查找的方式就可以得到我们需要读取的行的范围。
- 对于普通列的谓词来说,首先单个的列文件中维护了最大最小值等元数据信息,所以我们能够根据谓词条件和元数据进行比较对列文件进行过滤,然后我们读取全部需要读取的列文件再进行谓词计算,就得到了谓词过滤后的数据行号。
接下来我们用一些简单的例子进行解释。首先我们定义表结构,
CREATE TABLE IF NOT EXISTS `tbl` (
a int,
b int,
c int
) ENGINE=OLAP
DUPLICATE KEY(a,b)
PARTITION BY RANGE(a) (
PARTITION partition1 VALUES LESS THAN (1),
PARTITION partition2 VALUES LESS THAN (2),
PARTITION partition3 VALUES LESS THAN (3)
)
DISTRIBUTED BY HASH(b) BUCKETS 8
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
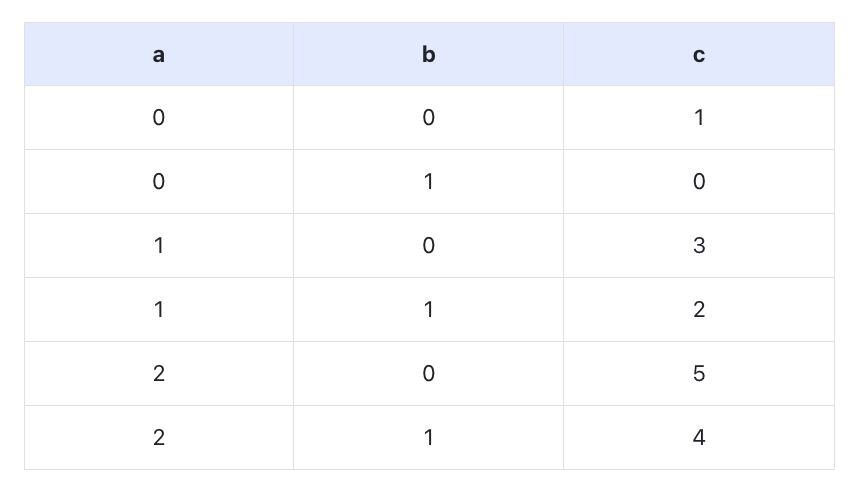
然后我们插入数据到p1,p2,p3这三个分区中:
4.1 分区列谓词过滤
SELECT * FROM `tbl` WHERE `a` > 0;
如前所述,分区裁剪在 Frontend 层完成,通过与元信息交互就可以查询到所有需要的分区。
4.2 Key 列谓词过滤
使用以下 SQL 对表进行查询,其中b列为 key 列。
SELECT * FROM `tbl` WHERE `b` > 0;
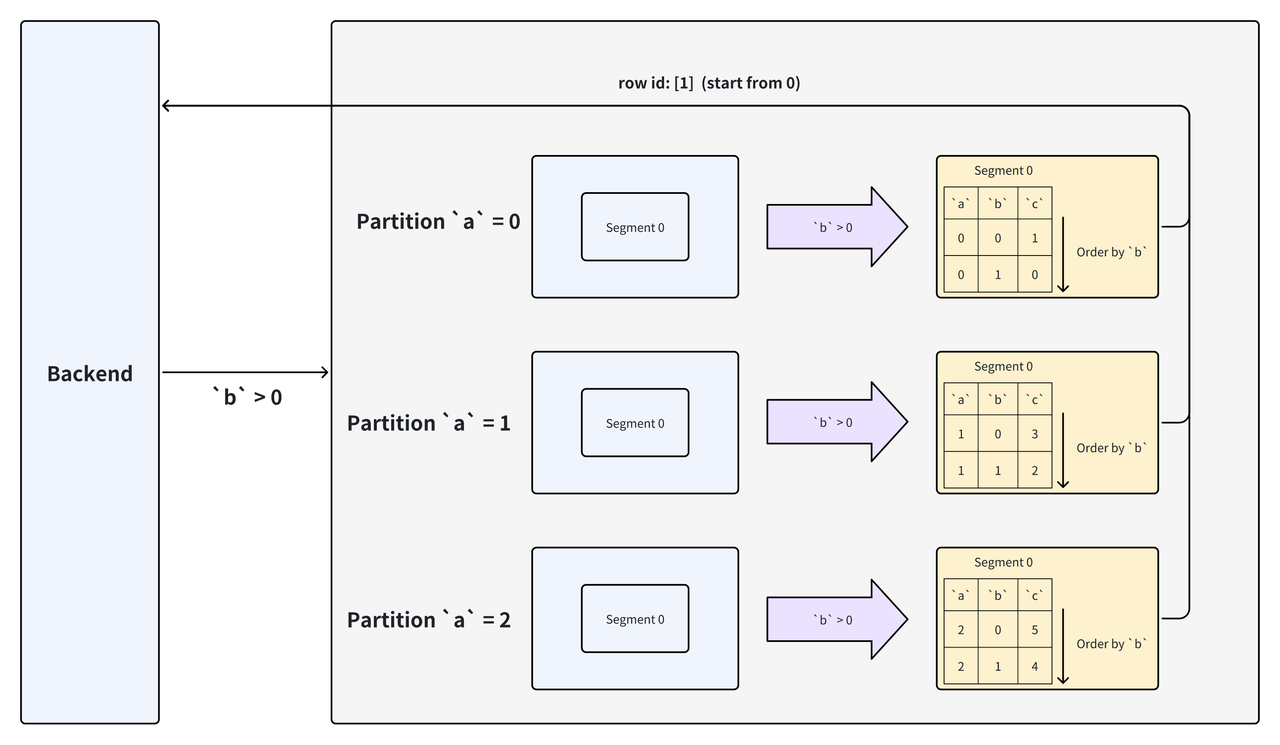
在上述例子中,存储层使用谓词中 Key 列的下界 0(非包含)对 segment 进行二分查找,最终返回符合条件的数据的行号 1(第二行),根据行号再进行其他列的数据读取。
4.3 数据列谓词过滤
使用以下 SQL 对表进行查询,其中c列为数据列。
SELECT * FROM `tbl` WHERE `c` > 2;
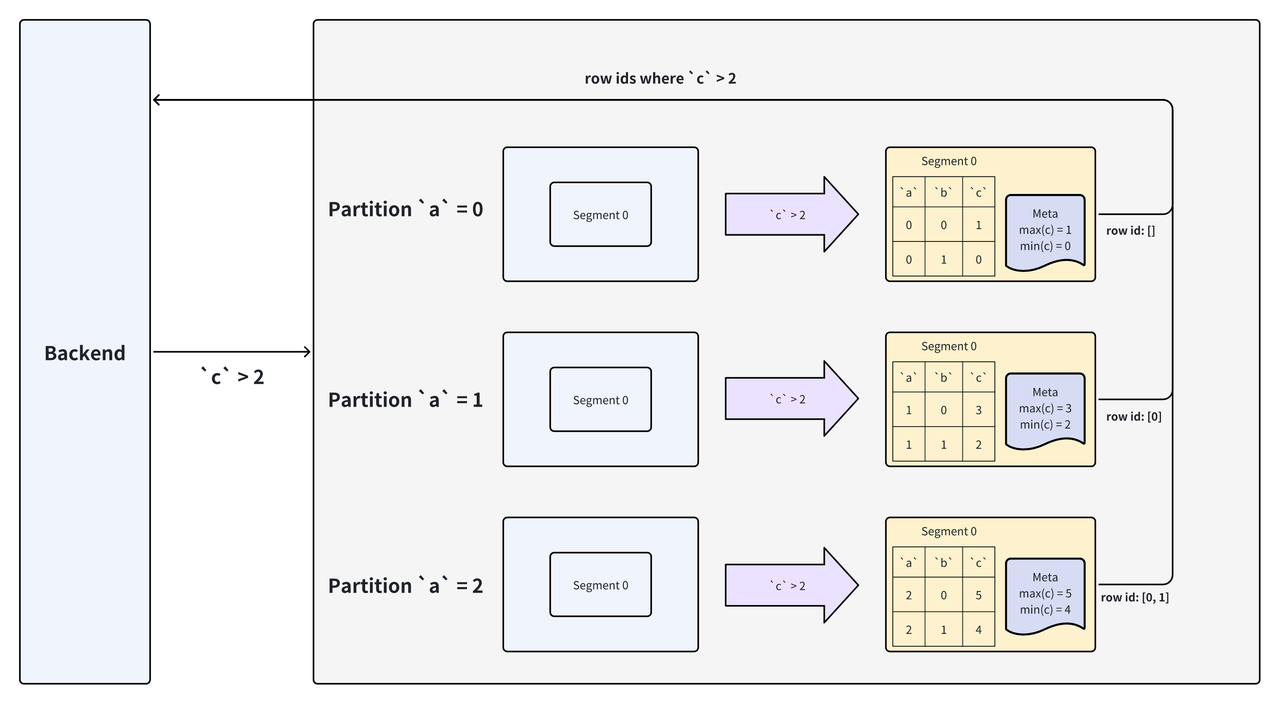
在上述例子中,存储层在所有的 Segment 中使用数据谓词中c列的数据文件进行计算,在计算之前首先根据数据文件中维护的最大最小值决定是否跳过当前文件的读取,在本例中,Column File 0 的最大值小于我们需要读取的数据的下界,所以可以直接跳过对应数据的读取,而在计算 Column File 1 后我们得到了匹配数据的行号,根据行号我们就可以再进一步读取其它列对应行的数据。
五、LIMIT 动态数据裁剪
在分析型任务中,LIMIT 查询是非常常见的一类查询[11]。对于普通查询来说,Doris 使用并发读取的方式来加速数据扫描,而对于 LIMIT 查询来说,Doris 使用了不同的策略从而对数据进行提前裁剪。
对于 Scan 上出现的 LIMIT,为了尽可能避免读取不需要的数据,Doris 把扫描并发设置为 1,并在返回数据行数到达 LIMIT 后停止。
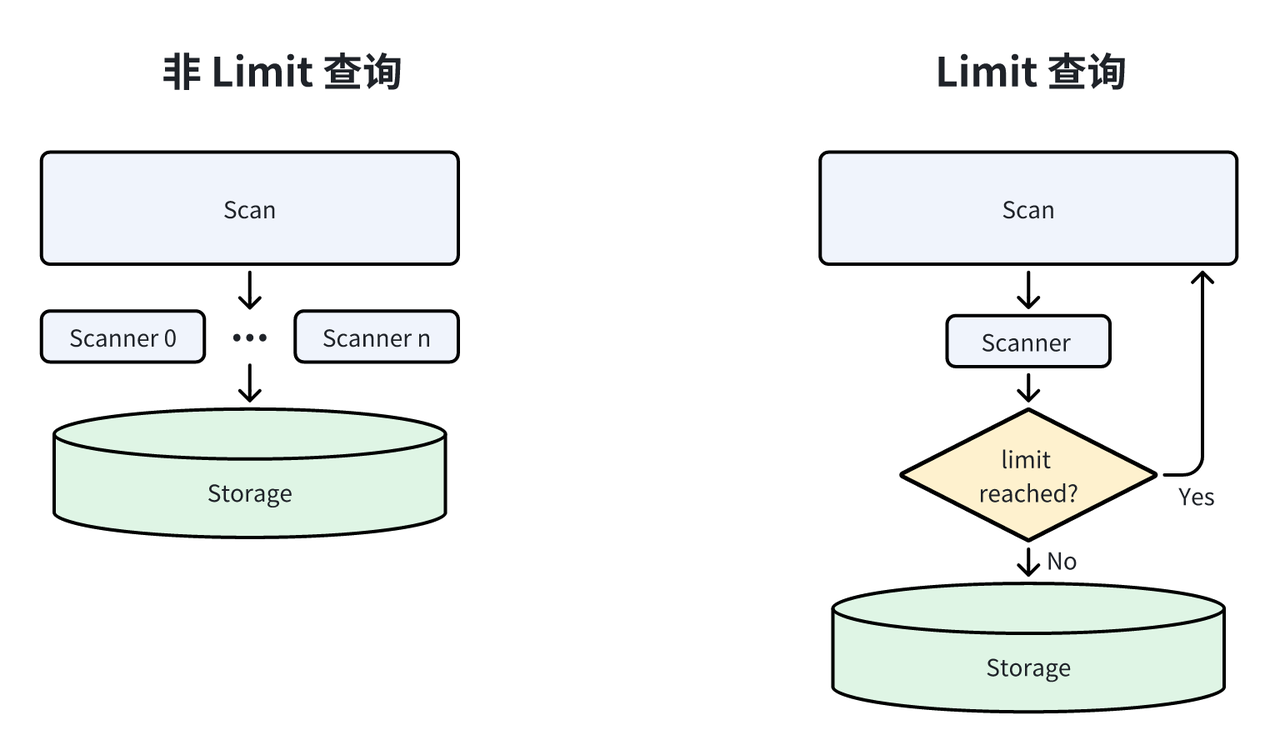
对于其它节点上出现的 LIMIT,Doris 执行引擎在数据达到 LIMIT 需要后立刻停止上游所有数据读取。
六、TopK 数据裁剪
TopK 查询在 BI 业务中是一类非常广泛使用的查询。简单来说,TopK 查询是指根据某几列顺序取出的前 K 个结果。和 LIMIT 裁剪类似,如果我们按照最基础的方法,把数据做完整排序再取最靠前的 K 个结果,那么扫描数据带来的开销是非常大的。所以,在数据库系统中,一般我们采用堆排序的方法来执行排序。在堆排序的过程中,我们如果能够应用一些特殊的优化手段,只扫描符合查询条件的数据,将会大大提升查询执行的效率。
标准堆排序方法
处理 TopK 查询最直观的方法是维护一个最小堆(对于降序排序),随着数据不断被扫描出来,也将被插入这个堆中,这也伴随着堆的更新。在这个过程中,不在堆中的数据将被丢弃,即不存在维护其它数据的开销。在所有数据都被扫描结束后,堆中的数据就都是我们需要的数据。
理论最优解法
理论最优解法是指我们能够扫描数据得到正确结果所需要的数据扫描量。在 Doris 中,数据在 Segment 内部按照 Key 列顺序存储(见 3.2),所以当 TopK 查询的结果是按照 Key 列进行排序时,我们只需要读取每个 Segment 的前 K 行,再对其进行汇总排序就可以得到最终结果。而如果排序结果是根据非 Key 列进行排序时,那么理论最优方法应该是读取每个 Segment 的排序数据进行排序,随后再根据排序结果取出对应行的数据,而不需要读取全部数据进行排序。
针对 TopK 类型的查询,Doris 做了针对性的优化。首先我们在数据扫描的线程中,先对数据做一个局部裁剪,随后再利用一个全局的 Coordinator 做数据的完整排序,并根据排序结果对数据进行全局裁剪。所以,TopK 查询在 Doris 执行过程中其实经历了两个阶段,第一个阶段中我们按照上述解法读出排序列,并对其进行局部排序和全局排序,得到满足条件的数据的行号。第二阶段我们根据第一阶段排序得到的行号重新读取我们需要的全部列得到输出结果。
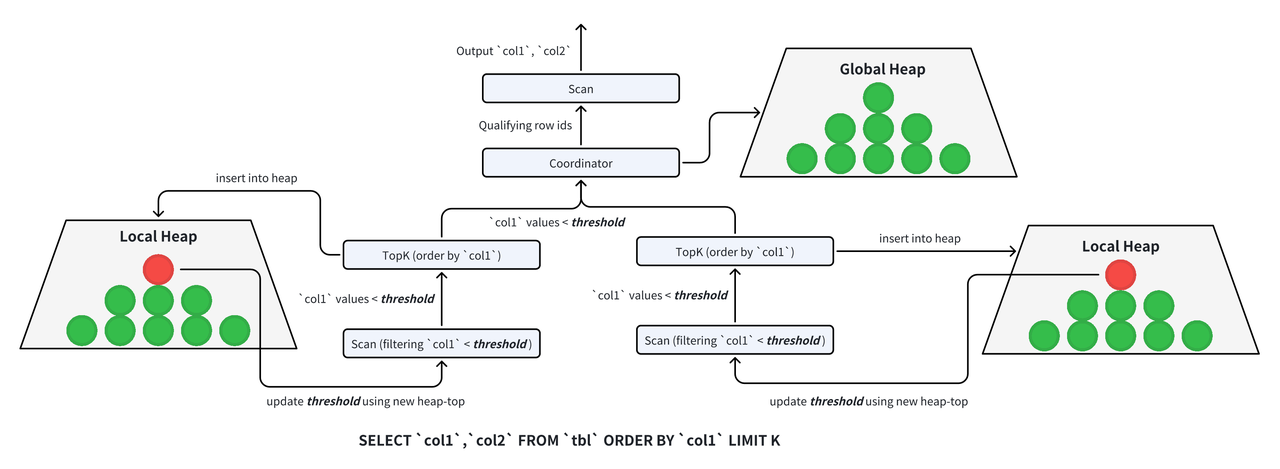
6.1 局部数据裁剪
通常来说,Apache Doris 以集群的形式为用户提供服务。在集群执行查询的过程中,数据首先被多个独立的线程读取出来,然后再经过各自计算,最终到达一个汇总线程得到最终结果。
在 TopK 查询中,扫描数据的独立线程需要首先完成对数据的局部裁剪。具体来说,每个扫描节点都伴随着一个 TopK 节点,这个 TopK 节点需要维护一个大小为 K 的堆,当数据行数小于 K 时,代表数据量没有到达查询结果的行数,所以继续扫描接下来的数据。当数据量到达 K 时,我们就需要丢弃其它不需要的数据,而在下一次扫描数据时,我们把这个堆顶元素作为过滤谓词,即只需要扫描出比它更小的数据。用这种方式,我们不断读出比堆顶元素更小的数据并且不断更新堆,再用新的堆顶元素去过滤数据,这样的方式能够保证我们每次读到的数据都是当前阶段满足 TopK 条件的数据。
6.2 全局数据裁剪
在经过局部数据裁剪后,N 个执行线程会最多返回 NK 行符合条件的结果,所以我们还需要对这些数据再做一次汇总排序,才能得到最终结果。这一步中,我们依旧使用堆排序,把 NK 个数据进行排序,最终得到满足条件的 K 条数据及其行号输出给 Scan,再进一步读出查询结果所需的其他列。
6.3 复杂查询的 TopK 裁剪
上述两部分中,局部数据裁剪不涉及多线程协作,所以比较直观,只要在扫描数据的阶段能够感知到 TopK,就可以完成局部堆的维护和使用。而全局数据裁剪的方法比较复杂,在一个数据库集群中,这个全局协调节点的工作方式直接影响了查询正确性和性能。在 Doris 中,我们设计了一个通用的 Coordinator,这个 Coordinator 对于全部 TopK 查询都同样适用,例如对于包含多表连接的查询来说,我们只需要在第一阶段读出所有需要计算表连接和排序的列进行排序,第二阶段再使用同样的方式,把行号下推到多个表中进行扫描即可。
七、JOIN 数据裁剪
多表连接(join)是数据库系统中最为耗时的操作。从执行的角度来说,数据越少,那么 Join 带来的开销也就越小。如果使用两个表做暴力连接,即计算笛卡尔积,假设两个表的大小分别是 M 和 N,那么笛卡尔积的时间复杂度就是 O(M*N)。所以通常来说我们会选择 Hash Join 作为一种更高效的表连接方法。在 Hash Join 中,我们首先选择数据量少的表作为 Join 的 Build 侧,根据其中的数据构建一个 Hash Table。随后,我们使用另一侧的表作为 Probe 侧,对 Hash Table 进行探测。理想情况下,我们不考虑访存影响,并且假定使用的数据和数据结构都是高效的,那么完成一行数据的 Build 和 Probe 的复杂度都是 O(1),整个 Hash Join 的复杂度是 O(M+N)。由于 Probe 侧数据一般都远大于 Build 侧,所以如何减少 Probe 侧数据的读取和计算是一个非常重要的课题。
在 Apache Doris 中,我们提供了多种方法完成 Probe 侧数据的裁剪。由于 Hash Table 中 Build 侧数据的值是确定的,所以我们可以根据数据量的大小对 JOIN 数据裁剪的方式进行选择。
7.1 JOIN 数据裁剪算法
对于 Join 来说,数据裁剪的预期结果是在不影响正确性的条件下,降低探测阶段的开销。所以我们需要权衡根据 Hash Table 构建谓词的开销以及探测的开销。当 Hash Table 的数据很少时,我们可以直接构造出一个精确谓词,比如一个 In 谓词,In 谓词保证了所有参与探测的数据一定是最终需要输出的结果。
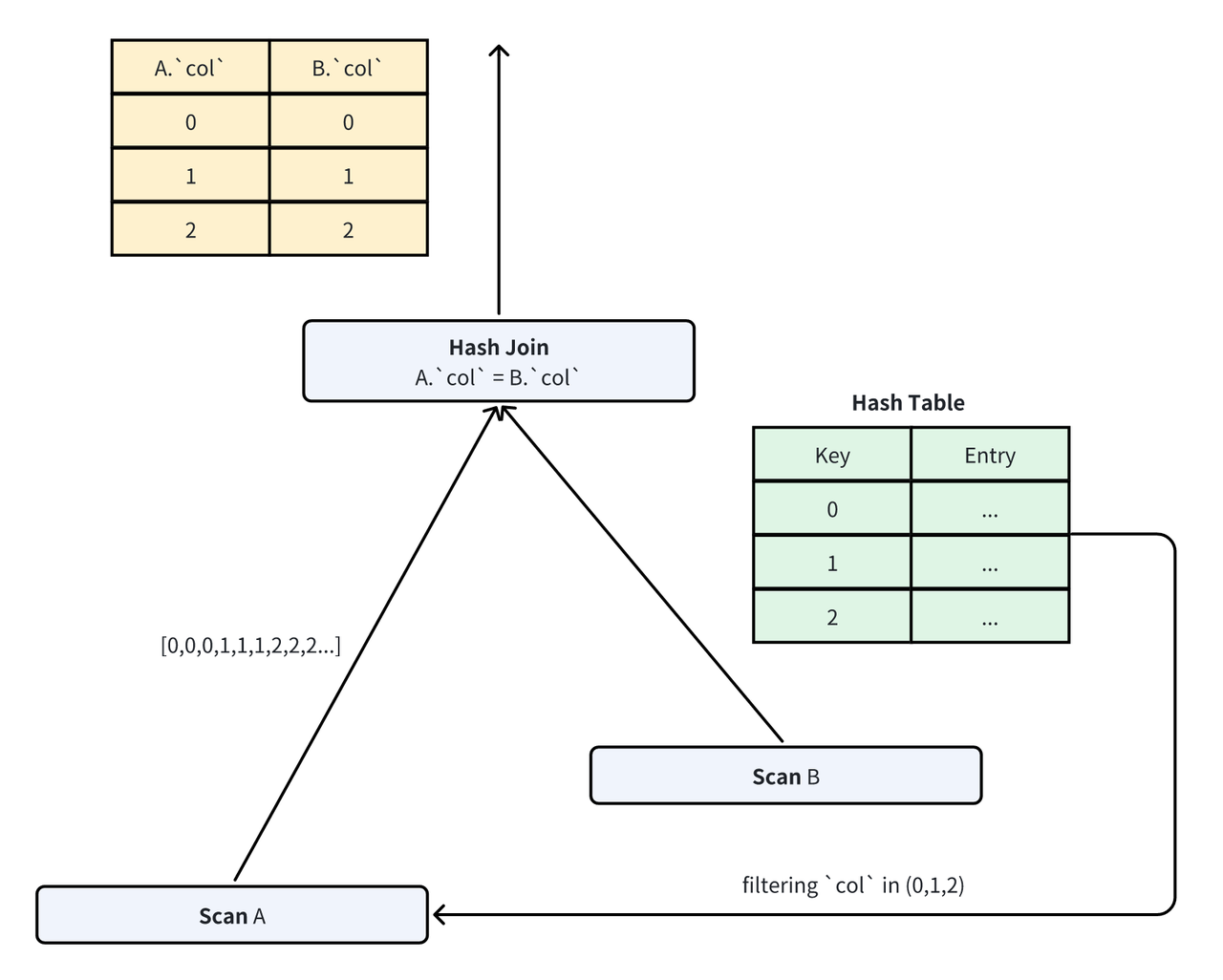
而当 Build 侧数据量大于一定阈值时,构造 In 谓词需要的去重开销就会变得很大。对于这种情况,Doris 舍弃了一部分探测的性能,即降低数据的过滤率,转而选择了构建和计算开销都更低的 Bloom Filter[5]。Bloom Filter 是一种允许一定误判率(the Flase Positive Probability,e.g。 FPP)的高效过滤器。通过使用 Bloom Filter,我们能够在 Build 侧数据量很大的时候同样拥有较低的谓词构建开销,同时,因为数据被过滤后最终还需要经过 Join 的探测过程,所以正确性也能够保证。
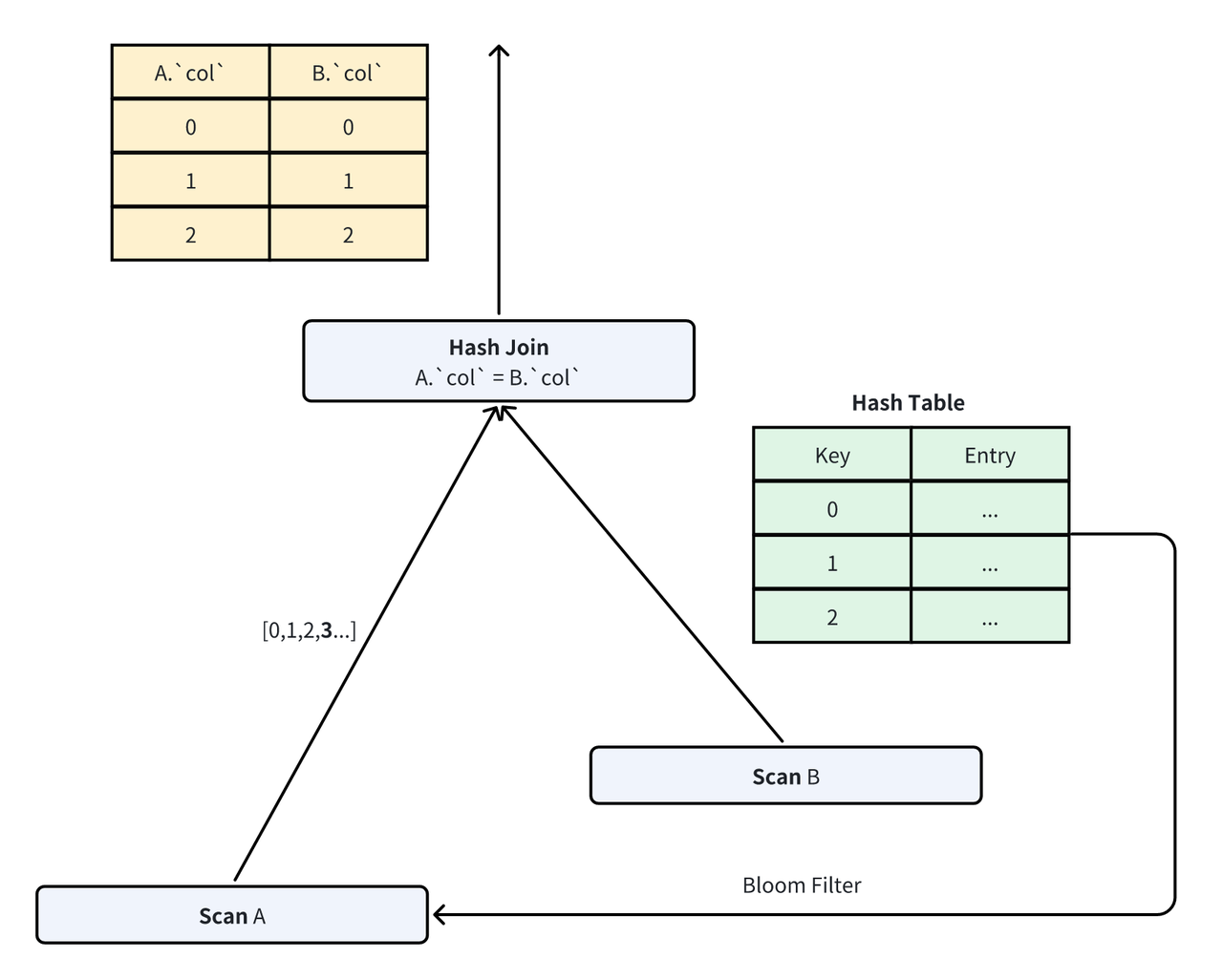
在 Apache Doris 中,Join 过滤谓词在运行时动态构建,无法在执行前静态确定,因此我们默认采用了一种自适应的方式,即首先使用 In 谓词进行构建,当去重值的数量到达一定数量后,重新构建 Bloom Filter 作为 JOIN 谓词。
7.2 JOIN 谓词等待策略
由于 Bloom Filter 的构建也需要一定的开销,所以 Doris 中自适应的裁剪算法选择并不能完全避免 Build 侧开销非常大的时候查询等待延迟特别高的问题。所以 Doris 引入了 Join 谓词等待的策略。默认情况下,我们假定这个谓词在 1 秒内构建完成,所以 Probe 侧数据扫描最多等待 1 秒,如果还没有等到 Build 侧传过来的谓词就直接开始执行。
与此同时,如果在数据扫描过程中,Build 侧的谓词构建完成,则在谓词构建完成后立刻发给 Probe 侧对之后的数据进行过滤。
八、总结与展望
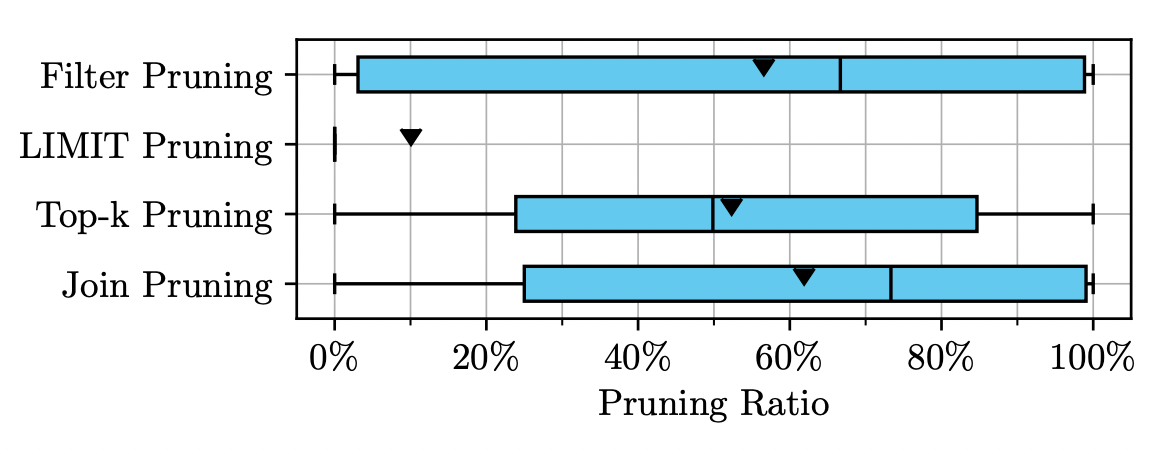
本文展示了 Apache Doris 中,谓词过滤、LIMIT 数据裁剪、TopK 数据裁剪、JOIN 数据裁剪四种数据裁剪方式的实现策略。目前,Apache Doris 通过这四类高效的数据裁剪策略极大提升了处理数据的效率。根据 SnowFlake 在 2024 年的客户数据[12],谓词裁剪、TopK 裁剪、Join 裁剪的裁剪率的平均值都超过了 50%,而 LIMIT 裁剪的裁剪率平均值在 10%。可以看出,四类裁剪策略极大影响了客户的查询执行效率。
在未来,Apache Doris 社区将继续探索更通用、更高效的数据裁剪策略。在数据需求越来越大的当下,数据裁剪的效率将很大程度影响数据库系统的处理效率,所以,这将是一个持续的发展方向。
参考文献
[1] Alexander van Renen and Viktor Leis. 2023. Cloud Analytics Benchmark. Proc. VLDB Endow. 16, 6 (2023), 1413–1425. doi:10.14778/3583140.3583156
[2] Alexander Hall, Olaf Bachmann, Robert Büssow, Silviu Ganceanu, and Marc Nunkesser. 2012. Processing a Trillion Cells per Mouse Click. Proc. VLDB Endow. 5, 11 (2012), 1436–1446. doi:10.14778/2350229.2350259
[3] Goetz Graefe. 2009. Fast Loads and Fast Queries. In Data Warehousing and Knowledge Discovery, 11th International Conference, DaWaK 2009, Linz, Austria, August 31 – September 2, 2009, Proceedings (Lecture Notes in Computer Science, Vol. 5691), Torben Bach Pedersen, Mukesh K. Mohania, and A Min Tjoa (Eds.). Springer, 111–124. doi:10.1007/978-3-642-03730-6_10
[4] Guido Moerkotte. 1998. Small Materialized Aggregates: A Light Weight Index Structure for Data Warehousing. In VLDB’98, Proceedings of 24rd International Conference on Very Large Data Bases, August 24-27, 1998, New York City, New York, USA, Ashish Gupta, Oded Shmueli, and Jennifer Widom (Eds.). Morgan Kaufmann, 476–487. http://www.vldb.org/conf/1998/p476.pdf
[5] Burton H. Bloom. 1970. Space/Time Trade-offs in Hash Coding with Allowable Errors. Commun. ACM 13, 7 (1970), 422–426. doi:10.1145/362686.362692
[6] Bin Fan, David G. Andersen, Michael Kaminsky, and Michael Mitzenmacher. 2014. Cuckoo Filter: Practically Better Than Bloom. In Proceedings of the 10th ACM International on Conference on emerging Networking Experiments and Technologies, CoNEXT 2014, Sydney, Australia, December 2-5, 2014, Aruna Seneviratne, Christophe Diot, Jim Kurose, Augustin Chaintreau, and Luigi Rizzo (Eds.). ACM, 75–88. doi:10.1145/2674005.2674994
[7] Martin Dietzfelbinger and Rasmus Pagh. 2008. Succinct Data Structures for Retrieval and Approximate Membership (Extended Abstract). In Automata, Languages and Programming, 35th International Colloquium, ICALP 2008, Reykjavik, Iceland, July 7-11, 2008, Proceedings, Part I: Tack A: Algorithms, Automata, Complexity, and Games (Lecture Notes in Computer Science, Vol. 5125), Luca Aceto, Ivan Damgård, Leslie Ann Goldberg, Magnús M. Halldórsson, Anna Ingólfsdóttir, and Igor Walukiewicz (Eds.). Springer, 385–396. doi:10.1007/978-3-540-70575-8_32
[8] Lothar F. Mackert and Guy M. Lohman. 1986. R* Optimizer Validation and Performance Evaluation for Local Queries. In Proceedings of the 1986 ACM SIGMOD International Conference on Management of Data, Washington, DC, USA, May 28-30, 1986, Carlo Zaniolo (Ed.). ACM Press, 84–95. doi:10.1145/16894.16863
[9] James K. Mullin. 1990. Optimal Semijoins for Distributed Database Systems. IEEE Trans. Software Eng. 16, 5 (1990), 558–560. doi:10.1109/32.52778
[10] https://doris.apache.org/
[11] Pat Hanrahan. 2012. Analytic database technologies for a new kind of user: the data enthusiast. In Proceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2012, Scottsdale, AZ, USA, May 20-24, 2012, K. Selçuk Candan, Yi Chen, Richard T. Snodgrass, Luis Gravano, and Ariel Fuxman (Eds.). ACM, 577–578. doi:10.1145/2213836.2213902
[12] Andreas Zimmerer, Damien Dam, Jan Kossmann, Juliane Waack, Ismail Oukid, Andreas Kipf. Pruning in Snowflake: Working Smarter, Not Harder. SIGMOD Conference Companion 2025: 757-770
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


