
清华大学朱军教授团队, NVIDIA Deep Imagination 研究组与斯坦福 Stefano Ermon 团队联合提出了一种全新的扩散模型强化学习(RL)范式 —— Diffusion Negative-aware FineTuning (DiffusionNFT) 。该方法首次突破现有 RL 对扩散模型的基本假设,直接在 前向加噪过程(forward process) 上进行优化,在彻底摆脱似然估计与特定采样器依赖的同时,显著提升了训练效率与生成质量。文章共同一作郑凯文和陈华玉为清华大学计算机系博士生。

论文标题:DiffusionNFT: Online Diffusion Reinforcement with Forward Process
论文链接:https://arxiv.org/abs/2509.16117
代码仓库:https://github.com/NVlabs/DiffusionNFT
背景 | 扩散模型的 RL 困境
近年来,强化学习在大语言模型(LLMs)后训练中的巨大成功,催生了人们将类似方法迁移到扩散模型的探索。例如,FlowGRPO 等方法通过将扩散采样过程离散化为多步决策问题,从而在反向过程上应用策略梯度优化。然而,这一思路存在多重根本性局限:
1. 似然估计困难 :自回归模型的似然可精确计算,而扩散模型的似然只能以高开销近似,导致 RL 优化过程存在系统性偏差。
2. 前向–反向不一致 :现有方法仅在反向去噪过程中施加优化,没有对扩散模型原生的前向加噪过程的一致性进行约束,模型在训练后可能退化为与前向不一致的级联高斯。
3. 采样器受限 :需要依赖特定的一阶 SDE 采样器,无法充分发挥 ODE 或高阶求解器在效率与质量上的优势。
4. CFG 依赖与复杂性 :现有 RL 方案在集成无分类器引导 (CFG) 时需要在训练中对双模型进行优化,效率低下。
因此,如何设计一种既能保留扩散模型原生训练框架,又能高效融入强化学习信号的统一方法,是亟待探索的问题。
方法 | 基于前向过程的负例感知微调
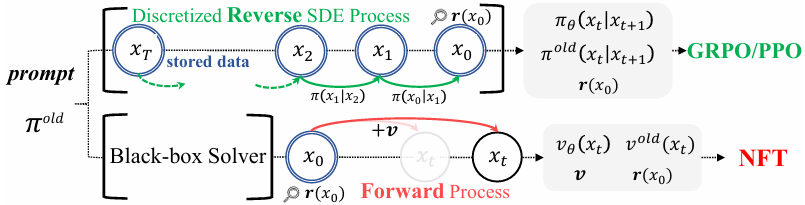
DiffusionNFT 提出了一个全新的思路: 把强化学习直接作用于扩散的前向加噪过程 ,而非反向去噪轨迹。这一设计带来了范式性的转变。
核心机制包括:
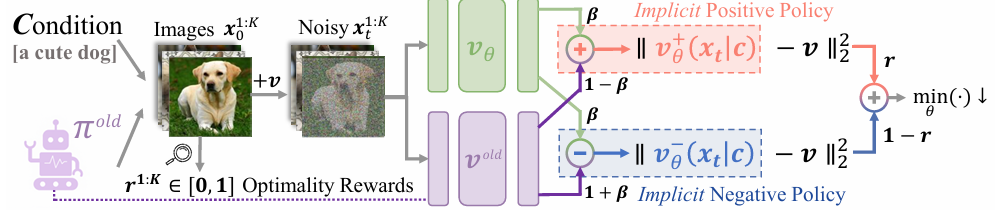
正负对比的改进方向 :在采样生成中,利用奖励信号将样本划分为正例与负例,从而定义出一个隐式的 “改进方向”。与只使用正样本的拒绝采样微调(Rejection FineTuning, RFT)不同,DiffusionNFT 显式利用负样本信号,确保模型有效 “避开” 低质量区域。
负例感知微调 (Negative-aware FineTuning, NFT) :通过一种巧妙的隐式参数化方式,从目标模型同时定义正向策略与负向策略,将正负分布对比转化为单一网络的训练目标,不需额外判别器或引导模型。
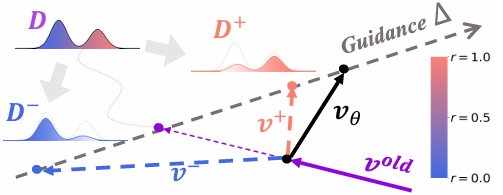
强化指导 (Reinforcement Guidance) :在数学上,DiffusionNFT 将优化目标刻画为对旧策略分布的偏移量 ∆,这一过程与 CFG 类似,但不依赖双模型结构,而是内生于训练目标中。
这样的设计使 DiffusionNFT 同时满足以下优势:
1. 前向一致性 :训练目标严格符合扩散的 Fokker–Planck 方程,不破坏与前向过程的一致性,使得训练后的模型仍然是良定义的扩散模型。
2. 采样器自由 :训练与采样彻底解耦,可使用任意黑盒 ODE/SDE 求解器,摆脱对一阶 SDE 的依赖;同时在训练时只需存储最终样本与对应奖励值,无需整条采样轨迹。
3. 似然无关 :不再需要变分下界或反向轨迹似然估计,训练只依赖生成图像与奖励。
4. CFG-free 原生优化 :直接学习到奖励引导的生成能力,避免 CFG 的推理开销,同时仍可兼容 CFG 进一步提升性能。
实验 | 高效性与生成质量
研究团队在多个奖励模型上验证了 DiffusionNFT 的有效性。主要结果包括:
大幅效率提升 :在 GenEval 任务上,DiffusionNFT 仅需 1k 步 即可将得分从 0.24 → 0.98 ,而 FlowGRPO 需超过 5k 步才能达到 0.95。整体上,DiffusionNFT 在不同任务上表现出 3×~25× 的训练效率优势 。
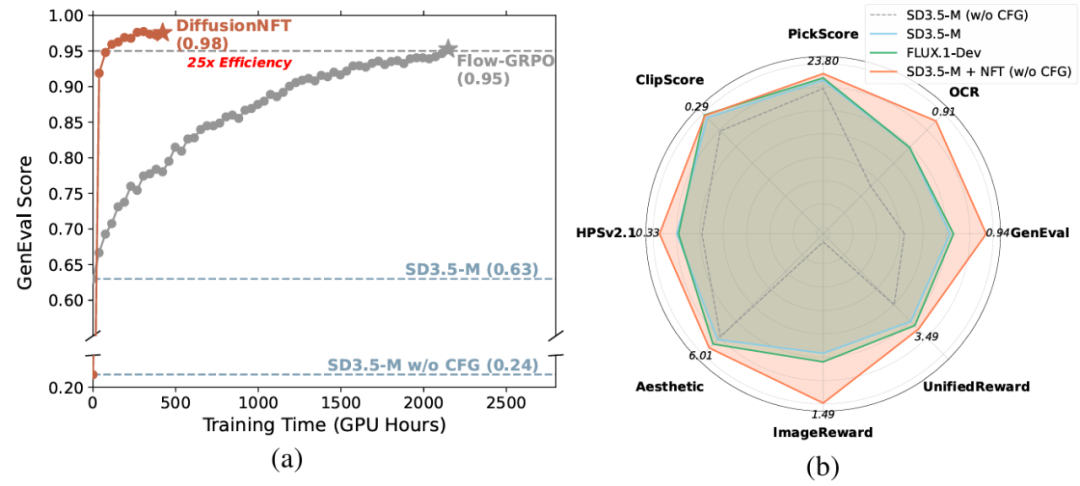
CFG-free 场景下显著提升 :即便完全不依赖 CFG,DiffusionNFT 也能在美感、对齐度等方面显著优于原始模型。
多奖励联合优化 :在 SD3.5-Medium 上同时优化 GenEval、OCR、PickScore、ClipScore、HPSv2.1 等多种奖励,最终模型在 所有指标 上均超越原始模型,与只针对单一奖励进行优化的 FlowGRPO 持平,并超过更大规模的 SD3.5-L 与 FLUX.1-Dev 模型。

展望 | 向统一的生成对齐范式迈进
DiffusionNFT 的提出,不仅为扩散模型的强化学习提供了一个高效、简洁且理论完备的新框架,也对更广泛的生成模型对齐研究具有启发意义。从语言模型到视觉生成,DiffusionNFT 展示了 负例感知 + 前向一致性 普适价值。它打破了似然估计与反向轨迹的限制,建立起 监督学习与强化学习之间的桥梁 。在未来,DiffusionNFT 有望推广至 多模态生成、视频生成以及大模型对齐 等更复杂场景,成为统一的生成优化范式。
]article_adlist–>
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

