作者:来自ElasticSean Handley 及 Max Jakob

了解 Elastic 的 EIS 如何利用 GPU 推理和 ELSER 来支持快速、准确的语义搜索。
测试 Elastic 的领先、开箱即用的功能。深入了解我们的示例笔记本,开始免费云试用,或立即在本地计算机上试用 Elastic。
今年,Elastic 的推理工具推出了由
GPU 驱动的 Elastic 推理服务
(EIS),提供了一个平台,通过始终在线的专用服务简化了对 LLM、嵌入和重新排序模型的访问。
今天,我们将重点介绍 EIS 如何使用我们的稀疏嵌入模型 ELSER(Elastic Learned Sparse EncodeR)简化语义搜索体验。将语义搜索作为基础可以帮助解锁许多其他能力,包括混合检索以及能够为您的代理工作流程的 LLM 提供良好的上下文。
让我们开始吧!
开始使用语义搜索
现在,你可以使用由 EIS 提供支持的推理端点,开始端到端的语义搜索用例。
使用新端点创建语义文本字段
首先,让我们使用 semantic_text 字段类型和 EIS 推理 ID .elser-2-elastic 创建一个新索引。
PUT semantic-embeddings
{
"mappings": {
"properties": {
"content": {
"type": "semantic_text",
"inference_id": ".elser-2-elastic"
}
}
}
}
这会创建一个名为 semantic-embeddings 的索引,其中 content 字段会自动使用 .elser-2-elastic 推理端点生成嵌入。
在未来的版本中,这个推理 ID 将成为默认值,因此你无需显式指定它。
重新索引你的数据
接下来,让我们重新索引一个包含国家公园数据的现有文本索引,以便它可以通过我们刚创建的索引使用新的 semantic_text 字段。
如果你想将现有数据引入由 EIS 提供支持的索引,这是必要的步骤,但在我们的下一个版本中,这一过程将进一步简化,允许你在不重新索引的情况下更新现有索引映射。
POST _reindex?wait_for_completion=false
{
"source": {
"index": "bm25-based-index",
"size": 100
},
"dest": {
"index": "semantic-embeddings"
}
}
搜索
最后,让我们通过语义搜索查询索引中关于国家公园的信息。
GET semantic-embeddings/_search
{
"query": {
"semantic": {
"field": "content",
"query": "Which park is most popular?"
}
}
}
以及响应结果:
{
"took": 168,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 17.655077,
"hits": [
{
"_index": "semantic-embeddings",
"_id": "ldJ9C5oBYmL2EI9TGdMP",
"_score": 17.655077,
"_source": {
"text": "Rocky Mountain National Park is one of the most popular national parks in the United States. It receives over 4.5 million visitors annually, and is known for its mountainous terrain, including Longs Peak, which is the highest peak in the park. The park is home to a variety of wildlife, including elk, mule deer, moose, and bighorn sheep. The park is also home to a variety of ecosystems, including montane, subalpine, and alpine tundra. The park is a popular destination for hiking, camping, and wildlife viewing, and is a UNESCO World Heritage Site."
}
},
{
"_index": "semantic-embeddings",
"_id": "k9J9C5oBYmL2EI9TGdMP",
"_score": 12.741274,
"_source": {
"text": "Yellowstone National Park is one of the largest national parks in the United States. It ranges from the Wyoming to Montana and Idaho, and contains an area of 2,219,791 acress across three different states. Its most famous for hosting the geyser Old Faithful and is centered on the Yellowstone Caldera, the largest super volcano on the American continent. Yellowstone is host to hundreds of species of animal, many of which are endangered or threatened. Most notably, it contains free-ranging herds of bison and elk, alongside bears, cougars and wolves. The national park receives over 4.5 million visitors annually and is a UNESCO World Heritage Site."
}
},
{
"_index": "semantic-embeddings",
"_id": "lNJ9C5oBYmL2EI9TGdMP",
"_score": 11.813252,
"_source": {
"text": "Yosemite National Park is a United States National Park, covering over 750,000 acres of land in California. A UNESCO World Heritage Site, the park is best known for its granite cliffs, waterfalls and giant sequoia trees. Yosemite hosts over four million visitors in most years, with a peak of five million visitors in 2016. The park is home to a diverse range of wildlife, including mule deer, black bears, and the endangered Sierra Nevada bighorn sheep. The park has 1,200 square miles of wilderness, and is a popular destination for rock climbers, with over 3,000 feet of vertical granite to climb. Its most famous and cliff is the El Capitan, a 3,000 feet monolith along its tallest face."
}
}
]
}
}
就是这么简单!使用由 EIS 提供支持的语义搜索索引,你可以获得出色的写入性能、便捷的基于 token 的定价,以及随需可用的服务。
有关详细示例和教程,请参考 Elastic 文档中关于 ELSER 在 EIS 上的说明和教程。
那这是如何工作的呢?
Elastic Inference Service 运行在 Elastic 的基础设施上,按需提供对机器学习模型的访问。
团队使用Ray构建了该服务,特别是利用Ray Serve库运行我们的机器学习模型。它运行在 Kubernetes 之上,并使用 Elastic Cloud Platform 中的 NVIDIA GPU 池来执行模型推理操作。
Ray 为我们带来了许多优势:
- 可开箱即用地支持 PyTorch、Tensorflow 及其他 ML 库;
- 原生支持 Python,并支持自定义业务逻辑,便于与 Python 生态中的模型集成;
- 稳定可靠,可跨异构 GPU 池工作,支持分数资源管理;
- 支持响应流、动态批处理以及其他许多实用功能。
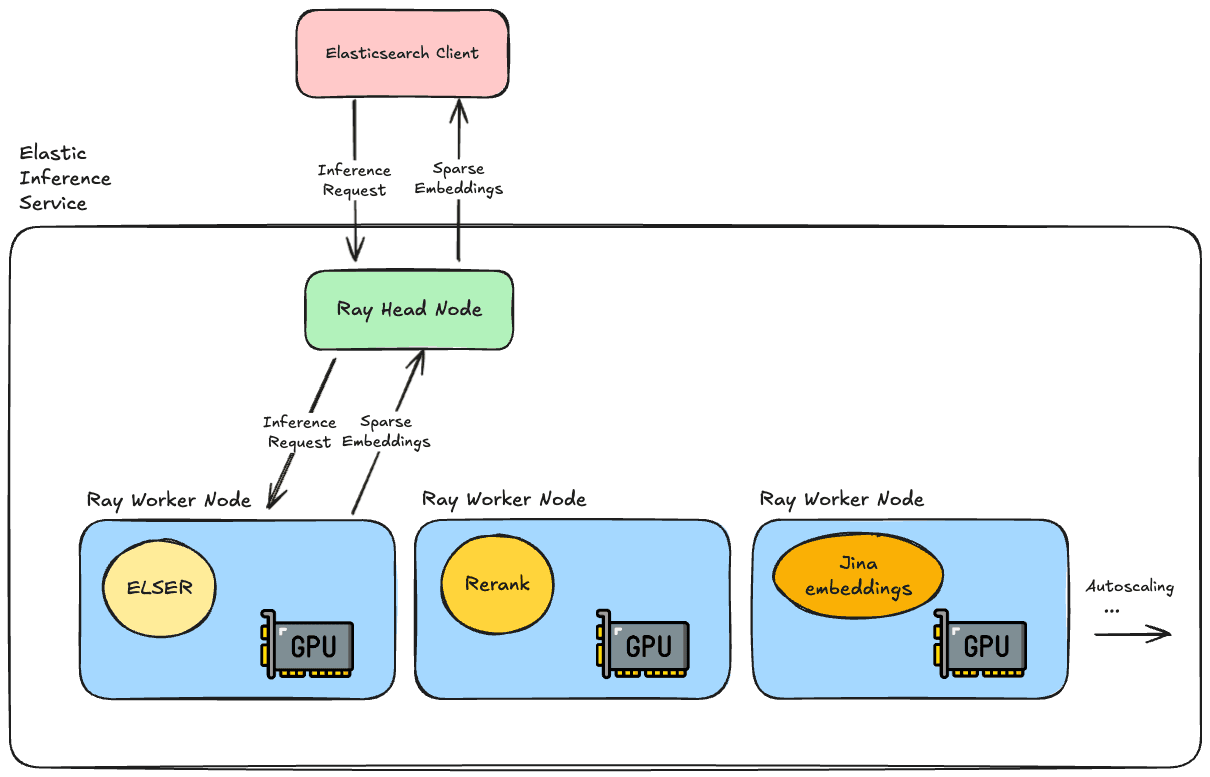
语义搜索的推理 API 请求到来时,我们的 ELSER 模型已经运行并准备生成稀疏嵌入。在 GPU 上运行使我们能够高效并行化操作,这对于需要定期摄取大量文档的情况尤其有用。
接下来是什么?
在未来版本的 Elastic 中,通过 EIS 的 ELSER 将成为默认的语义文本设置,因此在创建语义索引时,你甚至无需指定推理 ID。我们将增加功能,允许将索引更改为使用 EIS 的语义搜索,而无需进行任何重新索引。最后,也是最令人兴奋的,我们将添加新模型来支持重新排名和Jina 的多语言和多模态嵌入模型。
敬请关注未来的博客文章,了解更多关于服务工作原理的技术细节,以及更多模型和功能的最新消息!
原文: https://www.elastic.co/search-labs/blog/gpu-inference-elastic-semantic-search
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


