
<p><img src="https://oscimg.oschina.net/oscnet/up-303327ba3765576648c23d8b1462edf681a.png" alt=""></p> 现在用 AI,最怕的不是它不会,而是它不记得。
比如,我家的狗叫「十六」。
前一天,我刚手把手(打字)教会它“十六是我家狗”,还分享了三小时宠物日常。过两天打开新对话,我兴冲冲地发了句:“十六昨天终于学会游泳了!”结果,它用那种最标准的 AI 腔调回我:“很抱歉,您提到的「十六」是指什么?”

兄弟们,那一刻我的血压“噌”就上来了。这就是现实版的“赛博背叛”啊?🙄
一、AI 为啥总是“金鱼记忆”?
虽然如今的 AI 已具备短期记忆,却难以真正理解用户——这几乎是当下所有 AI 用户的核心痛点。其根本原因,正是模型缺乏长期记忆能力。
这也是为什么业界都在卷记忆:从 OpenAI 的长期记忆实验,到各类 Memory Agent 框架,大家都在试图解决如何让模型记住用户这件事。
要理解这个问题,我们得从模型的记忆架构说起。传统 LLM 的记忆机制主要分两类:
- 参数记忆(Parametric Memory):“焊”在模型权重里的知识,更新极其困难。
- 激活记忆(Activation Memory):对话时临时的上下文缓存,纯“日抛”记忆,会话结束当场失忆。
这意味着,模型在生成回答时,所能“看到”的信息完全取决于上下文窗口的大小。当上下文过长时,计算量将以平方级增长。为了控制计算成本,模型会自动遗忘较早的内容。于是,LLM 能和你聊逻辑,它却记不住你家狗的名字。能总结论文,却记不住你昨天说过的喜好。
更为严重的问题是幻觉——当模型缺乏连续上下文时,会自动补全缺失的信息,从而生成看似合理但错误的回答。
过去大家用 RAG(检索增强生成)或外部数据库来缓解这个问题,但那些方案大多是临时记忆:能查能存,却不懂何时调取、何时更新,更谈不上长期记忆。
二、让记忆成为一种系统资源:MemOS 登场
直到前段时间,我在 GitHub 上刷到一个开源项目——MemOS 专为 LLM 设计的长期记忆系统。
GitHub 地址:github.com/MemTensor/MemOS
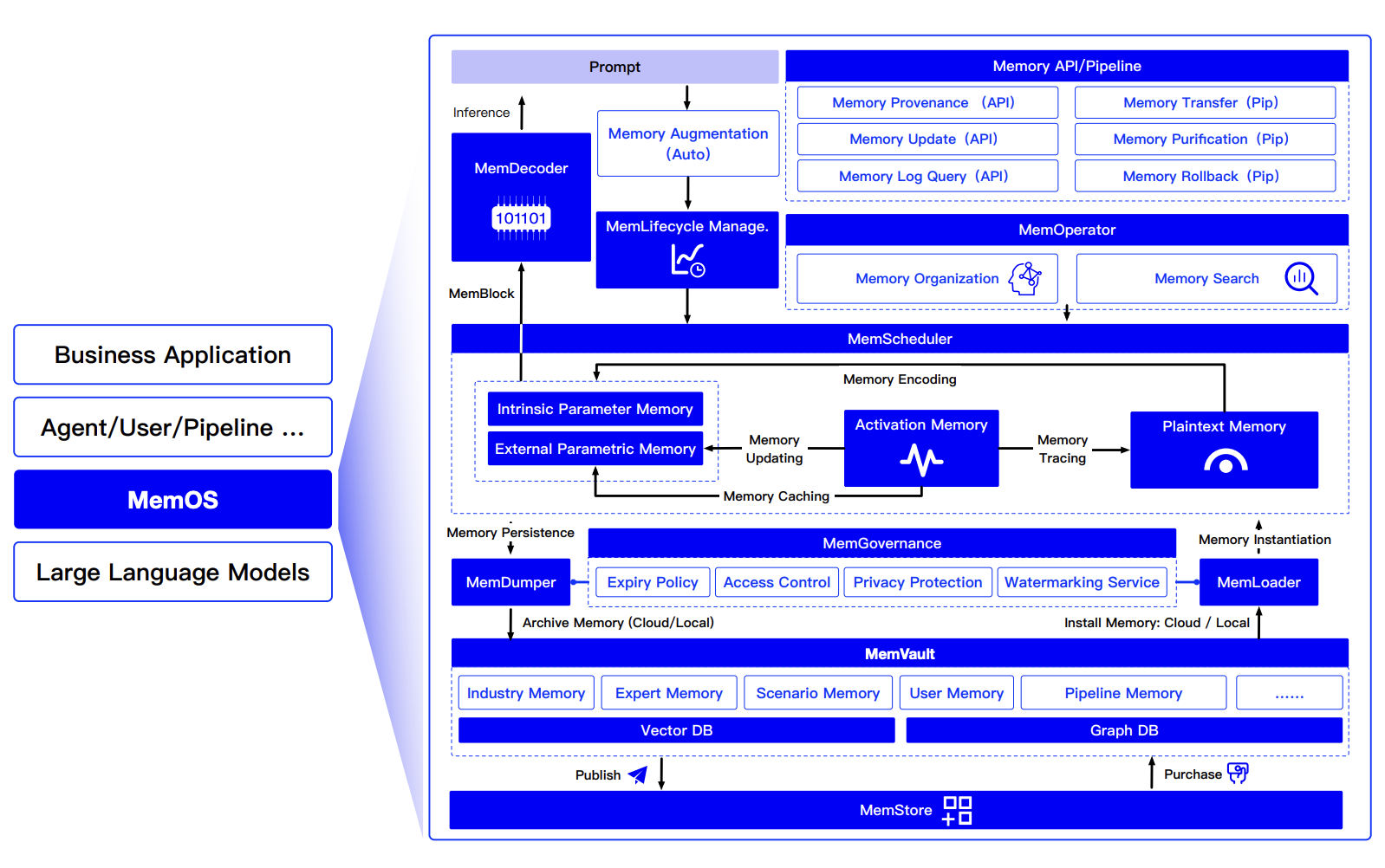
在了解 MemOS 之前,我一直认为 AI 记忆系统只是一堆“补丁”,开发者不得不反复折腾嵌入、检索和更新等繁琐的逻辑。而 MemOS 的理念,是把“记忆”抽象为系统级能力——你只需告诉它要记住的内容,其余都由系统自动处理。
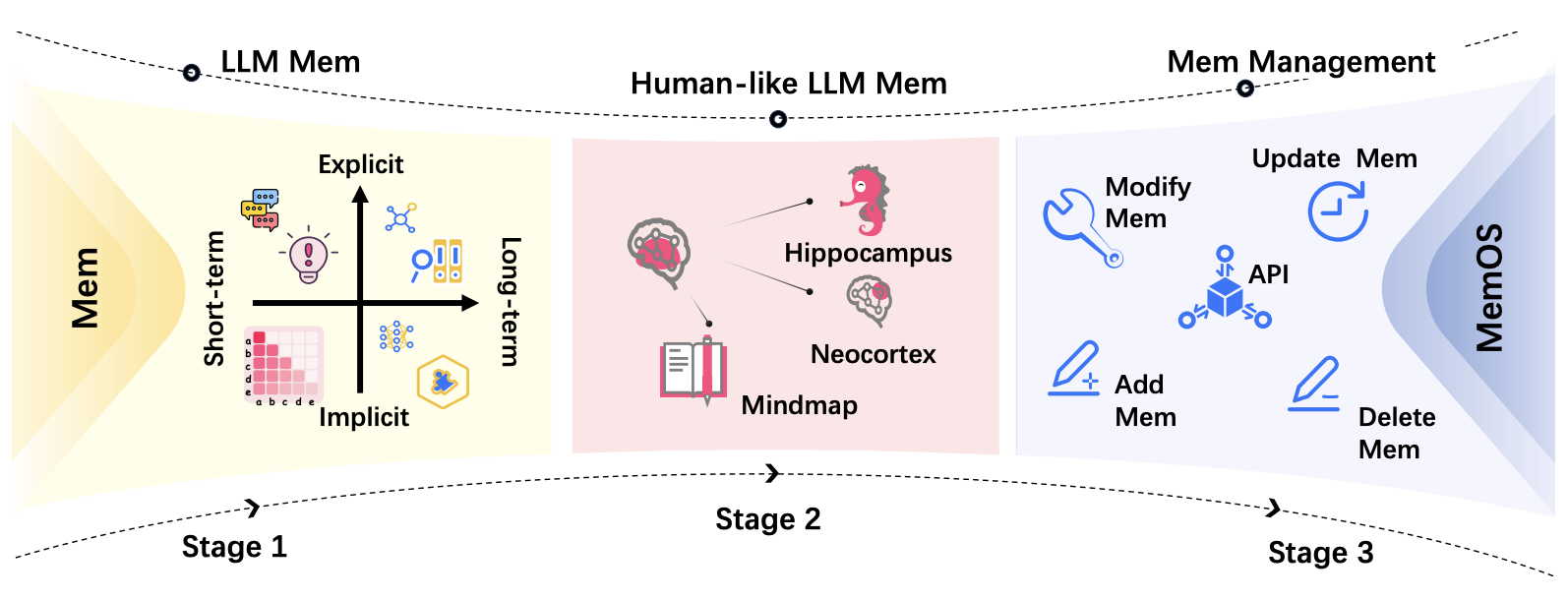
这听起来就像人脑的记忆机制:我们不是刻意存储信息,而是让重要的东西自然被记住。MemOS 就是在让 AI 拥有这种类人式的长期记忆能力。
三、记忆系统,如何“自己思考”?
我扒了扒它的文档,发现 MemOS 的记忆架构设计确实有点“东西”。
它并非简单地将聊天记录存入数据库,而是在每一条记忆之间建立关联——类似维基百科的超链接。它参考了操作系统的分层思想,将记忆系统划分为三层。
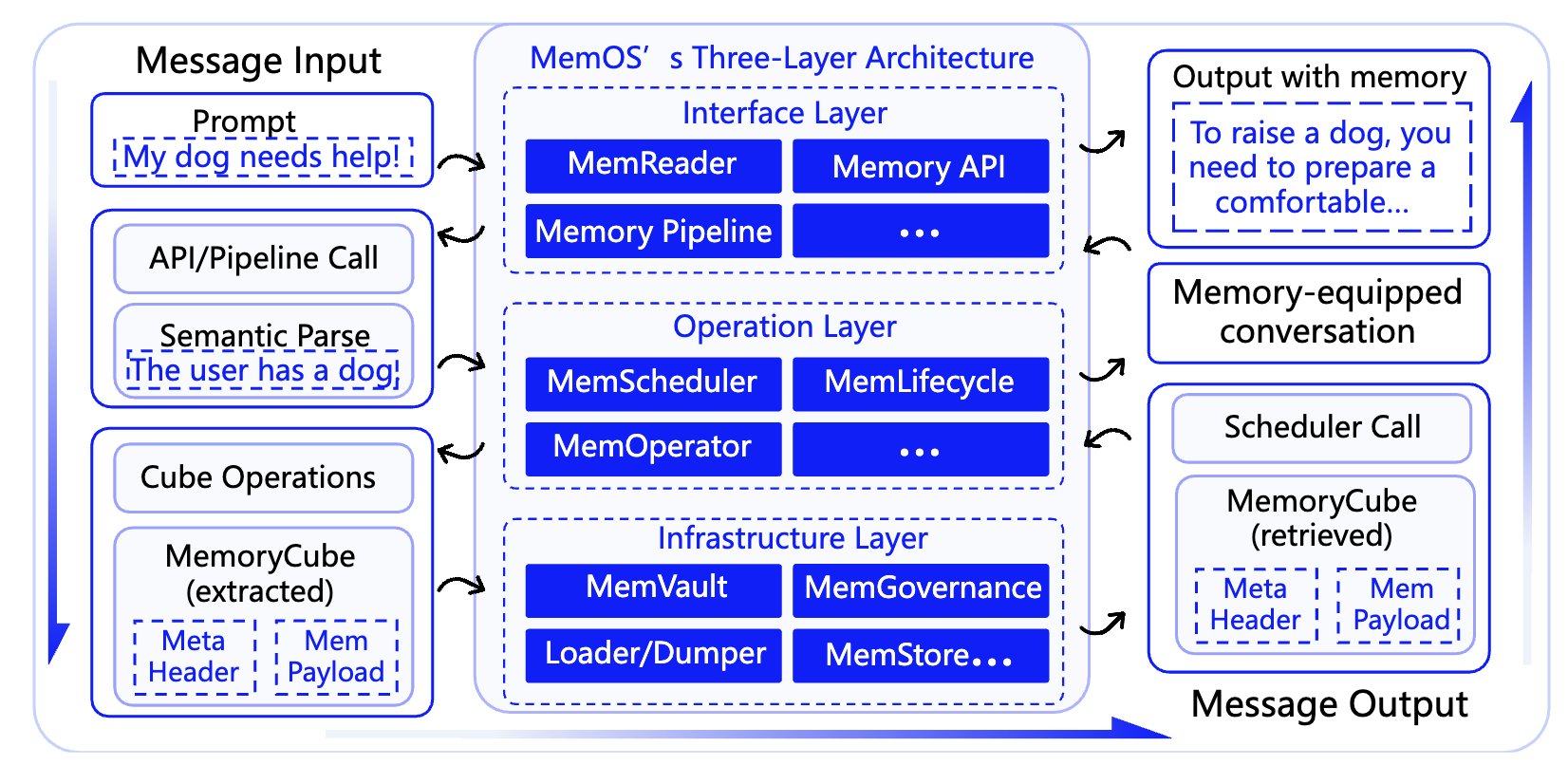
当我和 AI 聊到“十六”,系统不只是存下“十六 = 狗”这条信息,而是还会同时捕捉到对话的时间、情绪、上下文主题,并自动在它们之间建立语义链接。这样,下次你提“带十六去看兽医”,AI 就能主动推断出「十六」是那只宠物,而不是把它当作一个数字。
换句话说,MemOS 是让 AI “长记性”的操作系统。它不仅存数据,还能在推理中动态调度、复用和更新这些记忆。
更智能的是,系统会自动修剪和优化这张记忆图谱。当某些信息(比如「十六」)被频繁使用时,MemOS 会提高其优先级;反之则逐渐淡化。久而久之,系统会形成一张动态演化的记忆图谱,不断重塑、筛选、连接。
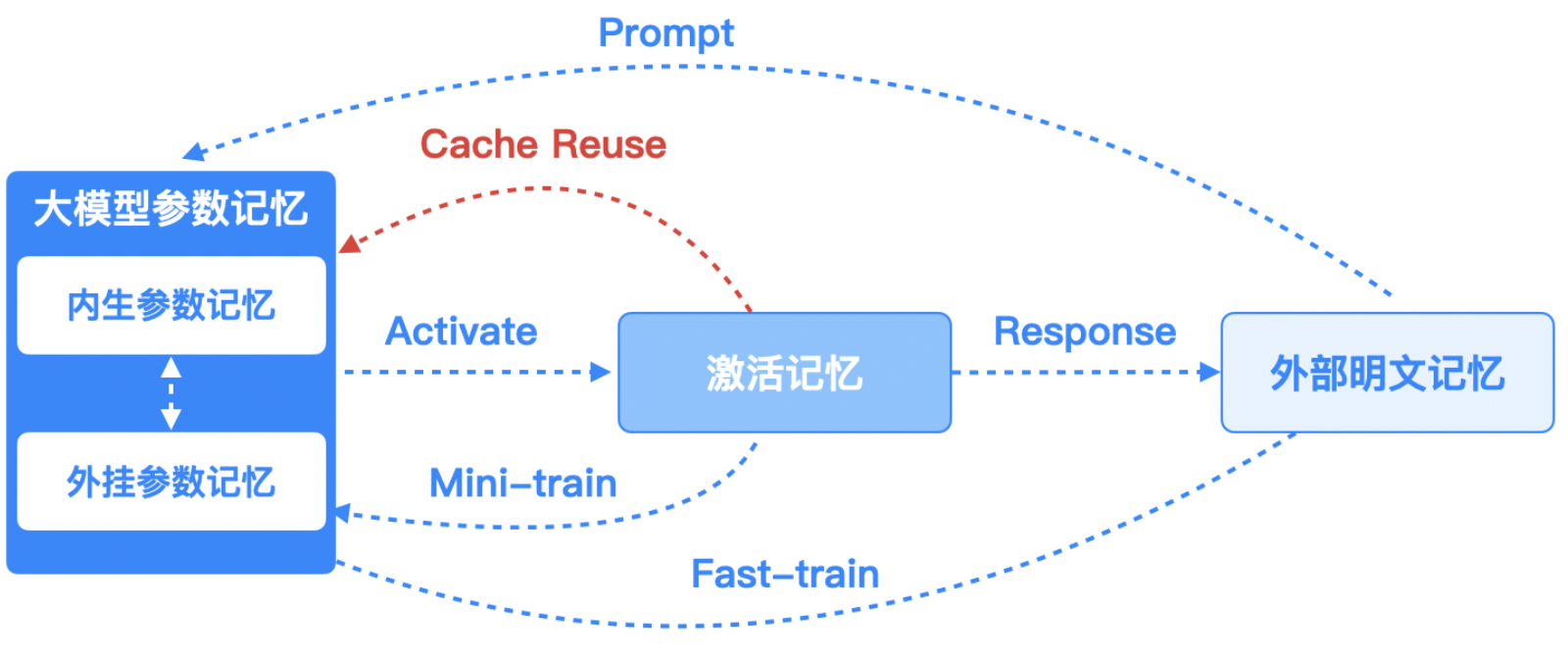
这意味着,AI 不再是死记硬背的机器,而是会“取舍”的伙伴。
四、从 Prompt 到 Context:记忆驱动的上下文工程
有了记性,还得会“用”才行。这就引出了上下文工程 这个核心技术。
-
传统 Prompt 工程:依赖“人工填鸭”,手动拼接提示词模板。
-
MemOS 模式:Prompt 不再是一次性的提示词输入,而是一个动态上下文重构的过程。
模型每次生成前,MemOS 会根据任务意图自动“三连”:
- 检索: 从记忆库中查出相关内容;
- 评估: 评估上下文权重;
- 注入: 将结果组织成结构化上下文并注入模型输入。
比如向 AI 提问:帮我查查上次说的那个”Redis 优化方案”。MemOS 会立刻自动找到历史记录,组合为上下文。
[2024-10-10] Redis 优化建议:
1. 使用 pipeline 批量命令;
2. 调整内存回收策略;
3. 添加监控指标。
再交给模型生成回答。这不仅极大减少了幻觉概率,也让推理更加稳健,具备了记忆连续性。
五、三步让 AI 记住「十六」
MemOS 已经为 AI 应用开发的开发者,提供了完善的 API 与 SDK,并且可以无缝集成主流智能体框架(如 Dify、LangGraph、Coze 等)。
以 Dify 为例,接入流程非常简单:
1.配置节点 在 Dify 的 ChatFlow 中添加两个 HTTP 节点:
/product/search:检索历史记忆/product/add:写入新记忆
2.连接逻辑节点
- 将
search的输出作为模型输入前的“上下文扩展” - 将模型的生成结果通过
add节点写回 MemOS
3.示例代码
# 添加记忆
curl -X POST "http://127.0.0.1:8002/product/add" \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "user", "content": "十六是我家的狗"},
{"role": "assistant", "content": "明白了,十六是你的狗狗!"}
],
"mem_cube_id": "user_001"
}'
# 检索记忆
curl -X POST "http://127.0.0.1:8002/product/search" \
-H "Content-Type: application/json" \
-d '{
"mem_cube_id":"user_001",
"query":"十六是谁",
"top_k":3
}'
几行代码,就能让 Dify 应用真正“记住”我家的狗「十六」!然后我还测试了一下,让它记住「十六」的生日,然后一周后再问它:“下周有什么要记得的事吗?”
它回答:“「十六」的生日要到了,别忘了准备小蛋糕。”
老实说,那一刻,我真有点被“治愈”到了。因为这不只是记忆被保存了,而是语境、情感和关系被理解并延续了。

这就是记忆的力量,让 AI 从一个工具变成了伙伴。
六、写在最后
人们常说“大模型的能力边界在模型之外”,而记忆,特别是模型长期记忆,就是让 AI 突破边界的关键一步。
我认为,AI 不缺知识,也不缺算力,真正缺的是「连续性」——一种能跨越会话、理解上下文、记住人和关系的能力。
这,正是 MemOS 这样的 AI 记忆系统试图重塑的核心方向。
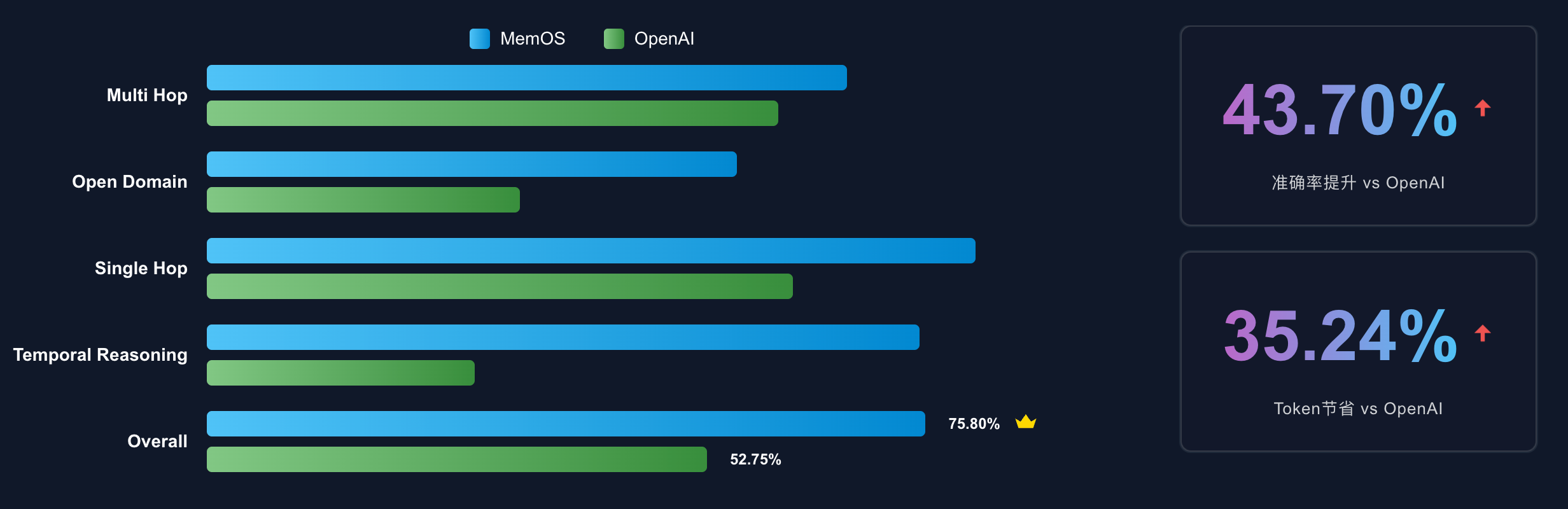
GitHub 地址:github.com/MemTensor/MemOS
或许在不久的未来,我们不会再说「和 AI 对话」,而是说「与一个真正记得你的智能体交流」。
因为到那时,AI 就不会再忘记 「十六」 的名字了。
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


