一、为什么我们放弃了Azkaban?
我们最早选择用 LinkedIn 开源的 Azkaban 做调度,主要是看中它两个特点:一是界面清爽,操作简单;二是它用“项目”来管理任务,非常直观。那时候团队刚开始搭建数据平台,这种轻量又清晰的工具,正好符合我们的需要。其他还有其他原因:
- 社区活跃(当时)
- 部署简单,依赖少(仅需 MySQL + Web Server + Executor)
- 支持 job 文件定义依赖,适合 DAG 场景
但随着业务规模扩大,Azkaban 的短板逐渐暴露:
- 缺乏任务失败自动重试机制
Azkaban 的重试策略极其原始:要么手动点击重跑,要么通过外部脚本轮询状态后触发。我们曾因一个 Hive 任务因临时资源不足失败,导致下游 20+ 个任务全部阻塞,运维不得不半夜手动干预。
- 权限粒度粗糙
Azkaban 的权限模型只有“项目级别”的读写权限,无法做到“用户A只能编辑任务X,不能动任务Y”。在多团队共用一个调度平台时,权限混乱导致误操作频发。
- 缺乏任务版本管理
每次修改 job 文件都会覆盖历史版本,无法回滚。我们曾因一次错误的参数修改,导致整个 ETL 流水线跑出错误数据,花了两天才定位到是哪个版本的 job 出了问题。
- 扩展性差
Azkaban 的插件机制确实不太给力,想接个企业微信告警、对一下内部的 CMDB,或者让它支持 Spark on K8s,基本都得去改源码。而且官方社区更新也慢,GitHub 上面一堆 issue 挂着,经常没人理。
反思: Azkaban 用在小团队、任务不复杂的时候还行,一旦数据平台规模上来了、团队变多了,就会发现它的架构有点跟不上了,各种限制就冒出来了。
二、为什么选择DolphinScheduler?
2022 年底,我们开始评估替代方案,对比了 Airflow、XXL-JOB、DolphinScheduler 等主流调度系统。最终选择 DolphinScheduler(以下简称 DS),主要基于以下几点:
- 原生支持丰富的任务类型
DS 内置 Shell、SQL、Spark、Flink、DataX、Python 等十几种任务类型,且支持自定义任务插件。我们无需再为每个任务类型写 wrapper 脚本。
- 完善的失败处理机制
- 支持任务级重试(可配置重试次数、间隔)
- 支持失败告警(邮件、钉钉、企业微信)
- 支持“失败后跳过”或“失败后终止整个工作流”
- 细粒度权限控制
在DS平台里,权限管理做得很细致。从租户、项目、工作流到具体任务,层层都可以设置不同人员的操作权限。这样既保证了安全,又让不同团队能够顺畅协作,特别实用。
- 可视化 DAG + 版本管理
拖拽式 DAG 编辑,支持任务依赖、条件分支、子流程 工作流每次发布自动保存版本,支持回滚到任意历史版本
- 活跃的中文社区
作为 Apache 顶级项目,DS 在国内有大量用户和贡献者,文档完善,问题响应快。我们遇到的几个生产问题,都在社区群中 24 小时内得到解答。
三、真实迁移案例:从 Azkaban 到 DolphinScheduler
背景
- 原系统:Azkaban 3.80,约 150 个工作流,日均任务数 800+
- 目标:平滑迁移至 DS 3.1.2,不影响业务数据产出
迁移步骤
-
任务梳理与分类
- 对现有的 Azkaban 作业做个盘点。先按任务类型(例如 Shell 脚本、Hive SQL、Spark 作业)分个类,然后重点梳理出它们之间的强依赖关系,把整个任务的上下游链路明确下来。
- 标记强依赖关系(如 A → B → C)
-
DS 环境搭建与测试
- 部署 DS 集群(Master + Worker + API Server + Alert Server)
- 创建租户、用户、项目,配置资源队列(YARN)
-
任务重构与验证
- 将 Azkaban 的 .job 文件转换为 DS 的工作流定义
- 重点处理:参数传递(Azkaban 用
${},DS 用${}但语法略有不同);依赖逻辑(Azkaban 用dependencies,DS 用 DAG 连线)
- 在测试环境跑通全流程,验证数据一致性
-
灰度切换
- 先迁移非核心报表任务(如运营日报)
- 观察一周无异常后,逐步迁移核心链路(如用户行为日志 ETL)
- 最终全量切换,保留 Azkaban 只读状态 1 个月用于回溯
踩坑记录
- 坑1:参数传递不一致
Azkaban 中 ${date}会自动注入当前日期,而 DS 需要显式定义全局参数或使用系统内置变量 {system.datetime}。我们写了个脚本自动转换参数语法。
- 坑2:资源隔离问题
之前我们所有任务都挤在同一个YARN队列里,结果那些跑得久的大任务动不动就把资源全占了,搞得其他小任务一直卡着。后来我们给每个业务线都单独开了账户和YARN队列,这下总算清净了,大家各跑各的,谁也不耽误谁。
- 坑3:告警风暴
任务失败动不动就告警,一开始每天狂响上百条,实在头疼。后来我们调整了策略:只给核心任务开实时告警,非核心的就每天汇总一下,发个邮件同步,清爽多了。
四、给后来者的具体建议
- 不要盲目追求“大而全”
如果你只有几十个 Shell 脚本任务,用 Cron + 简单监控可能效率更高一点。调度系统有运维成本,评估 ROI 再决定。
- 重视权限与租户设计
从第一天就规划好租户结构(如按业务线划分),避免后期权限混乱。建议开启“任务审批”功能,关键任务变更需 review。
- 建立任务健康度指标
- 任务失败率
- 平均运行时长波动
- 依赖阻塞次数
我们用 Prometheus + Grafana 监控这些指标,提前发现潜在问题。
- 善用子流程(SubProcess)
复杂的 DAG 一多,就容易乱得像“一锅粥”。我们可以把那些常用的功能,比如数据质检、日志归档这些,打包成独立的子流程。这样一来,不仅复用起来方便,后期维护也省心多了。
- 备份与灾备不能少
- 定期备份 DS 元数据库(MySQL/PostgreSQL)
- 配置多 Master 高可用
- 关键任务设置“跨集群容灾”(如主集群挂掉,自动切到备用集群)
五、关键对比速查表
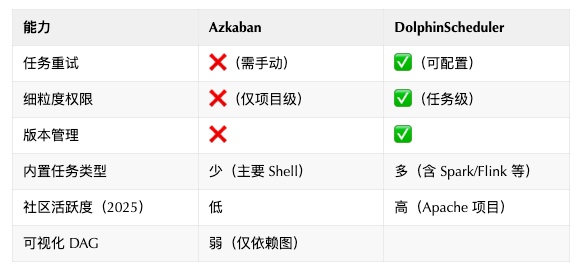
技术选型不是终点,而是持续优化的起点。
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


