向量检索这门技术,其发展由来已久,可以追溯到上世纪六七十年代。1975 年发表的 KD 树算法,就是早期经典的高维数据检索算法之一。然而,此后近四十年间,向量检索长期处于冷门状态,并没有特别多的应用需要它。
直到 2015 年,ImageNet 图片分类数据集及何恺明教授的 ResNet 等突破性论文引爆了深度学习,使得模型在多个任务上超越人类。推荐系统和搜索引擎快速成为向量检索技术主要落地场景,向量引擎也由此开始大规模应用。
大模型爆发又掀起第二轮热潮:基于向量检索的 RAG 架构,已成为解决模型幻觉、实现知识实时更新的关键技术,推动其在多模态、企业知识库等场景爆发式应用。
不久前,开源中国直播栏目《数智漫谈》邀请到了傅聪博士,分享了向量检索技术的发展情况。傅聪于浙江大学计算机博士毕业,曾赴美国南加州大学访问研究,其主导发明的 NSG、SSG、PSP、MAG 等高性能检索算法,已落地为千亿级向量检索系统,成为工业界大规模检索的标杆方案。目前,傅聪博士在shopee(新加坡)担任资深算法专家,专注于 AI 大规模应用落地方面的研究。
微信扫码,观看直播回放:

本文根据直播整理,介绍四种向量检索算法类型:哈希算法、树算法、量化算法、图算法。其中,哈希算法、树算法慢慢淡出了历史舞台,量化算法、图算法是当前主流。
哈希算法:向量检索的古早形态,已逐渐被淘汰
向量检索的最初形态——哈希算法,是一种历史悠久的向量索引方式。
从事计算机相关行业的朋友,对哈希表应该都不陌生。哈希的本质是什么?就是把数据通过一个哈希映射函数,映射到哈希桶(buckets)里。目标是让每个桶里的数据分布尽可能均匀,这样就能通过高效的二进制方式快速检索数据。

向量哈希函数与我们常规理解的哈希算法,核心区别在于,哈希函数本身是专门为向量设计的。大家无需深究其具体实现,只需知道这类函数能将向量相对均匀地分散到各个哈希桶中,从而实现高效检索。
那么,为什么哈希算法没有在当下各领域大规模应用呢?主要原因有两个:一是哈希表索引结构本身非常庞大;二是其效率低且精度差。
我们可以以构建一个线上工业级并发系统为例来说明。通常来说,系统性能的核心目标通常包括 QPS(即单机处理用户请求的最大并发能力)和 recall(召回精度)。在特定的延迟要求下,评估向量检索算法的关键指标是——在此延迟约束内能达到多高的召回精度。而哈希算法最大的问题恰恰是其精度不足,因此才逐渐被淘汰。
树算法:单棵树精度不够,昙花一现
历史上与哈希算法一样昙花一现的,还有树算法。它的本质就是分治思想。设想一个庞大复杂的高维向量空间,目标是通过方法将其逐层切分,最终把整个空间分割成许多小格子(也就是叶子节点),并让每个叶子节点包含的向量数量尽量接近。

这样就能借助树结构高效的索引逻辑进行快速查询。入门数据库时学到的那些索引,很多其实就是这种树结构,只是切分方式不同。
这种树索引有个明显特点:体积很大。 别光看它是一棵树就觉得体积小。问题在于,单棵树的检索精度通常不够好。所以实际应用中,要构建多棵树。
比如上个时代,有名的开源检索库 FLANN (Fast Library for Approximate Nearest Neighbors),它在计算机视觉领域用得挺多,就不会只建一棵树,而是构建多棵随机树进行并行查询,以此来提升效果。代价就是索引会膨胀得厉害。
相比哈希算法,它的精度确实高一些,但通常还是达不到在线产品系统的要求。关键问题在于:即使勉强达到某个精度(可能还不达标),它的检索速度也依然非常慢。
量化算法:低损耗,空间切分类算法的性能天花板
量化算法,和前两类算法(哈希和树算法)其实比较相似,可以把它们理解为空间切分类算法。这类算法有一个共同的缺陷,就是索引效率较低。
但量化算法另辟蹊径,它用一种低损耗的方式实现了较好的空间切分。这里有个比较经典的例子,就是 Meta 的FAISS 库(前身由 Facebook 开发),它最早集成的核心算法 IVFPQ(Product Quantization)代表了十年前的主流方案。PQ 的核心逻辑是通过聚类来切分空间,这和前两类算法的思路不太一样。
它具体是怎么做的呢?在切分好的空间里,选取中心点(图中红点)作为区域代表点。用户的查询向量只需要和这些中心点计算距离。这个距离近似等价于查询向量与该区域内所有原始数据点(蓝点)的距离比较。这样就能快速筛选出一部分近邻候选向量,最后再用真实距离进行精确比较。

(图片来源于 知乎用户 @vegetabledog)
这种算法的优势很明显:索引结构非常小(内存占比低),检索速度足够快,而且精度也比哈希和树算法更高。量化算法发展到这里,可以说空间切分类算法的性能天花板已经显现了。
也正是在这个阶段,创新的图检索算法开始兴起。
图算法:精度高、速度快,当前被普遍采用
图检索算法可以说和前面三种算法(哈希、树、量化)是完全不同的思路。
前面那些算法的核心是“分而治之”,像切割领土、筑墙建院一样去切割空间。而图算法的核心思想恰恰相反,它是要打通区块之间的壁垒——不是去切分空间,而是在空间的点与点之间构建四通八达的“高速公路”,这就是图算法的设计理念。
图算法的特点是,它的索引会比量化算法大很多。但从当前各种基准测试的表现来看,它能在保持极快速度的同时,以高精度碾压量化类算法。
那么图算法是怎么检索的呢?
假设我们已经构建好一个图结构,图中每个点只连接空间中的少量邻近点。比如起始点是黑色点 M,目标查询点是左下角的黑色点 P。从任意起点 M 逼近目标 P 的过程,本质上是一个贪婪式的图上“游走”:每一步都在当前点的邻近中寻找离 P 最近的那个点跳转过去,然后迭代重复这个过程。这样一步步跳转,最终就能逼近目标区域(红色点即为最近的候选结果)。
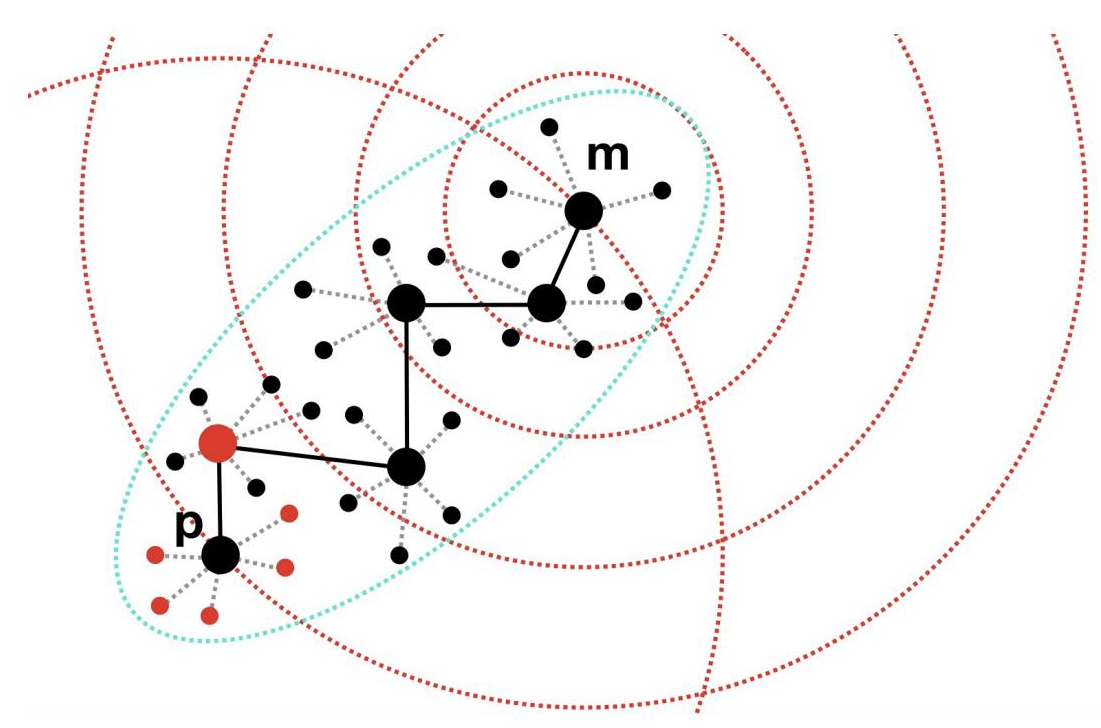
想要让图算法发展得更好——精度更高、速度更快——关键在于两点:第一,路径越短越好(跳转次数少则速度快);第二,邻近越少越好(每个点计算量小则算力需求低)。这意味着理想的图结构应该是足够稀疏,并且点与点之间的连通路径尽可能短。
选型:量化算法还是图算法?
现在开源项目或 Demo 中,最常用的就是量化算法和图算法。那要怎么选型、找到适用场景?根据长期工作经验总结如下:
- 如果数据总量较小,在线精度要求不高,但对内存或GPU显存有严格限制,就比较适合用量化算法。因为量化是用聚类中心代表其他点,这个过程必然有信息损失——数据量越小损失越小,数据量越大精度下降越明显。
- 如果数据总量非常大,同时要求高精度、低延迟,并且有充足的内存资源(目前内存也相对便宜了),那么图算法是更好的选择。实际上,当前无论是开源项目还是闭源产品,主流的向量检索方案普遍都在使用图算法。

量化算法有一个典型场景,就是推荐系统中的 GPU 端向量召回。例如在电商平台,需要构建一个约2000-3000万规模的精品商品库,通过向量表征模型(如生成 64 维或 128 维向量)实时召回个性化商品作为推荐候选集。
这些向量表征模型部署在 GPU 上进行推理,因此生成的向量数据会直接驻留在 GPU 显存中。我们希望向量检索也能在显存内完成,避免向 CPU 传输数据。然而,模型本身可能已占用 10 GB以上的显存,剩余可用显存往往仅剩2-3GB。
在这种显存受限的场景下,量化类检索算法就显得尤为合适。类似地,如果大模型应用中的知识库规模有限,且需要端到端 GPU 处理,量化算法也是理想选择。
至于图算法的典型场景,可以千亿级视频版权检测为例。抖音、快手等短视频平台,抖音、快手这类平台每日面临海量视频上传,必须在极短时间内完成版权筛查以避免法律风险,
其核心流程可分为三步:
-
特征提取:针对版权库视频,提取关键帧的画面特征并压缩为高维向量(如 CLIP 生成 1024 维向量),确保内容相似的视频片段在向量空间中距离相近;
-
索引构建:将向量存入支持 ANN(近似最近邻)检索的专用数据库(如 Milvus/FAISS),构建千亿级向量索引;
-
实时检索:新视频上传时,实时提取其特征向量,在毫秒级延迟内从向量库中检索相似内容,返回相似度超过阈值(如 >95%)的潜在侵权片段。
面对这种超大规模数据+高并发+高精度的需求,图检索算法,可以说是目前最有效的解决方案。
小结:
纵观向量检索的发展,从早期的哈希、树算法,到当前主流的量化、图算法,技术的迭代始终围绕着效率、精度与资源消耗的平衡。哈希与树算法受限于精度或效率瓶颈,逐渐淡出主流视野;量化算法凭借其低内存消耗的特性,在资源受限场景(如GPU显存下的中小规模召回)找到了稳固位置;而图算法则以其高精度、低延迟的优势,成为应对千亿级海量数据、高并发在线检索的首选。
技术迭代一直在进步。傅聪博士主导发明的基于图的 NSG 算法,已成为当前主流方案之一,但仍然在实践中不断演进——目前,他在 Shopee(新加坡) 带领团队已将其迭代至第三代 PSP 与第四代 MAG 算法,不断突破着大规模向量检索的性能边界。
【数智漫谈】
OSCHINA 视频号直播畅聊栏目【数智漫谈】,每期一个技术话题,三五位专家围坐,各抒己见,畅聊开源。给大家带来最新的行业前沿、最热门的技术话题、最有趣的开源项目、最犀利的思想交锋。如果你手上也有新点子、好项目,想要跟同行交流分享,欢迎联系我们,讲坛随时开放~

</div>维权提醒:如果你或身边的朋友近五年内因投顾公司虚假宣传、诱导交费导致亏损,别放弃!立即联系小羊维权(158 2783 9931,微信同号),专业团队帮你讨回公道! 📞立即免费咨询退费


