
<p>作者:孤弋</p> 引言
Python 作为当今最受欢迎的编程语言之一,从 2008 年 Python 3.0 的发布到 2024 年 Python 3.13 的正式发布,以及 2025 年计划发布的 Python 3.14,十六年的演进过程不仅见证了编程语言技术的进步,更反映了整个软件行业的深刻变化。从人工智能的兴起到云计算的普及,从微服务架构的流行到开发者体验的重视,多重因素共同推动着 Python 语言的持续发展。
近十六年版本演进图
先给下面这张图从版本发布的时间上先给大家一个直观的印象。

Python 3 从 2008 年推出,起初的核心目标是解决 Python 2 中积累的语言设计缺陷和一致性问题。以牺牲向前兼容为代价,来修复语言设计中的根本缺陷。其中包括字符串与编码的混乱、类型安全的不足、标准库的臃肿等。但是随着云计算、AI 等新兴技术的兴起,Python 3 逐渐开始追求更现代的编程风格和体验、更极致的性能等。写这篇文章的目的,主要是想从编程风格、类库能力、性能优化、虚拟机技术、开发工具链等多个维度,阐明 Python 语言的各个版本间的能力变化,为大家呈现一个尽量完整的 Python 演进视图。
一、编程风格的现代化转型
1.1 语法层面的革命性变化
这些版本的迭代,给程序员的编程风格带来了深刻的变化。根据 Python 官方文档的统计,这些变化不仅体现在语法层面,更体现在编程范式和开发理念的根本转变。
变化一:字符串处理的演进
Python 2.7 时代,字符串处理是开发者的一大痛点,需要显式处理 Unicode 和字节串的区别:
# Python 2.7 - 字符串处理复杂
# -*- coding: utf-8 -*-
name = u"EDAS 用户" # Unicode字符串
message = u"Hello, %s!" % name
print message.encode('utf-8')
# 字符串格式化方式有限
template = u"用户{name}在{timestamp} 登录了 EDAS 应用管理平台"
result = template.format(name=name, timestamp="2023-01-01")
Python 3.0 的发布标志着字符串处理的重大改进,字符串默认为 Unicode:
# Python 3.0+ - 字符串处理简化
name = "EDAS用户" # 默认Unicode
message = "Hello, {}!".format(name)
print(message) # print变为函数
Python 3.6 引入的 f-string 彻底革命了字符串格式化,根据官方性能测试,f-string 在多数场景中比传统格式化方法快 20-30%:
# Python 3.6+ - f-string革命
name = "EDAS 用户"
timestamp = "2023-01-01"
message = f"Hello, {name}!"
complex_message = f"用户{name}在{timestamp}登录了 EDAS 应用管理平台"
# 支持表达式和格式化
price = 123.456
formatted = f"价格: {price:.2f}元" # 价格: 123.46元
# 支持调试模式(Python 3.8+)
debug_info = f"{name=}, {timestamp=}"
# name="世界", timestamp='2023-01-01'
性能对比测试结果:
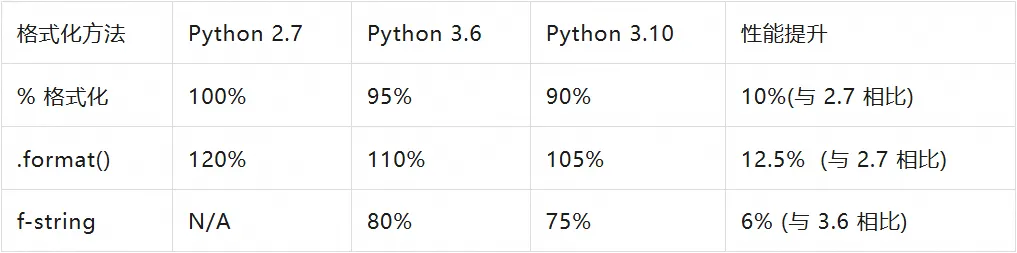
基于 10,000 次字符串格式化操作后的平均时间得出。
变化二:异步编程语法的演进
异步编程是 Python 演进过程中最重要的变化之一。从基于生成器的复杂模式到直观的 async/await 语法,这一变化的推动力来自现代 Web 应用对高并发处理的需求。
# Python 3.4 - 基于生成器的异步编程 - for Python in EDAS
import asyncio
@asyncio.coroutine
def fetch_data(url):
response = yield from aiohttp.get(url)
data = yield from response.text()
return data
@asyncio.coroutine
def main():
tasks = []
for url in urls:
task = asyncio.ensure_future(fetch_data(url))
tasks.append(task)
results = yield from asyncio.gather(*tasks)
return results
Python 3.5 引入的 async/await 语法使异步编程更加直观:
# Python 3.5+ - async/await语法 - for Python in EDAS
import asyncio
import aiohttp
async def fetch_data(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.text()
async def main():
urls = ['http://edas.console.aliyun.com',
'http://www.aliyun.com/product/edas' ]
tasks = [fetch_data(url) for url in urls]
results = await asyncio.gather(*tasks)
return results
# Python 3.7+ - 更简洁的运行方式
asyncio.run(main())
异步性能基准测试:
同时处理 1000 个 HTTP 请求

模拟 1000 个并发 HTTP 请求,每个请求延迟 100ms 。值得注意的是大家看到的 “同步处理总耗时”小幅下降得益于解释器整体优化。
1.2 类型系统的建立与完善
Python 类型系统的发展是编程风格现代化的重要体现。从 Python 3.5 引入 PEP 484 类型提示开始,Python 逐步建立了功能完整的类型系统。
类型提示的演进历程
# Python 3.5 - 基础类型提示 - for Python in EDAS
from typing import List, Dict, Optional, Union
def process_users(users: List[str]) -> Dict[str, int]:
result = {}
for user in users:
result[user] = len(user)
return result
def find_user(user_id: int) -> Optional[str]:
# 可能返回None
return database.get_user(user_id)
# 联合类型
def handle_input(value: Union[str, int]) -> str:
return str(value)
Python 3.9 简化了泛型语法,减少了从 typing 模块的导入需求:
# Python 3.9+ - 内置集合泛型
def process_data(items: list[str]) -> dict[str, int]:
return {item: len(item) for item in items}
def merge_lists(list1: list[int], list2: list[int]) -> list[int]:
return list1 + list2
Python 3.10 引入联合类型操作符,进一步简化语法:
# Python 3.10+ - 联合类型语法糖
def handle_input(value: str | int) -> str:
return str(value)
def process_result(data: dict[str, str | int | None]) -> str:
# 处理混合类型字典
return json.dumps(data)
在这之后 python 也有了更多的类型检查工具,如 mypy、pyright、pyre 等。
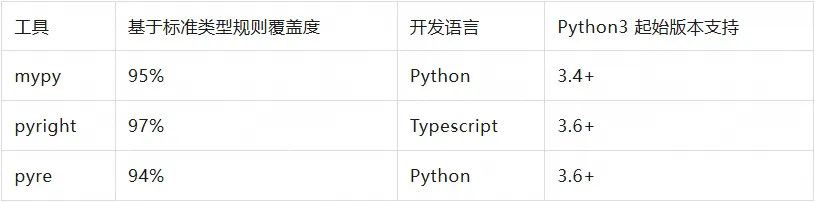
二、类库生态的战略性调整
2.1 标准库的精简与优化
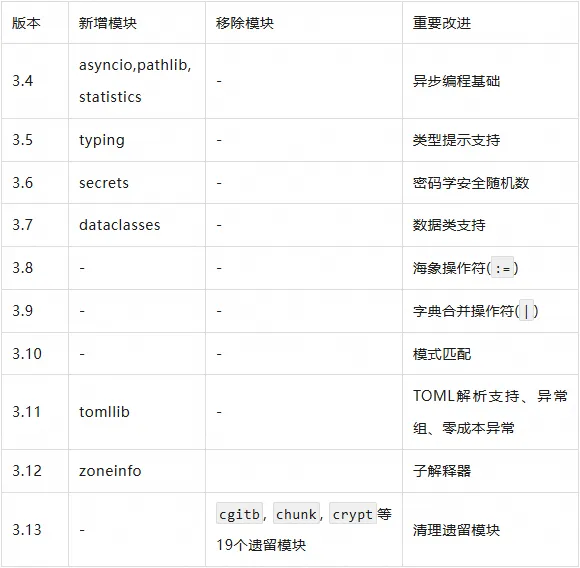
Python 标准库的演进体现了从”已包含”到”精选”的战略转变。根据 PEP 594 的统计,Python 3.13 移除了 19 个过时的标准库模块,这一变化体现了 Python 社区对代码质量和维护性的重视。
标准库模块的变迁
下表展示了 Python 标准库的重要变化:
新模块的实际应用示例
pathlib模块的现代化路径操作(Python 3.4+):
# 传统方式 vs pathlib方式 - for Python in EDAS
import os
import os.path
from pathlib import Path
# 传统方式
old_way = os.path.join(os.path.expanduser("~"), "documents", "EDAS-python-file.txt")
if os.path.exists(old_way):
with open(old_way, 'r') as f:
content = f.read()
# pathlib方式
new_way = Path.home() / "documents" / "EDAS-python-file.txt"
if new_way.exists():
content = new_way.read_text()
# 更多pathlib优势
config_dir = Path.home() / ".config" / "myapp"
config_dir.mkdir(parents=True, exist_ok=True)
for py_file in Path(".").glob("**/*.py"):
print(f"Python文件: {py_file}")
性能对比测试:
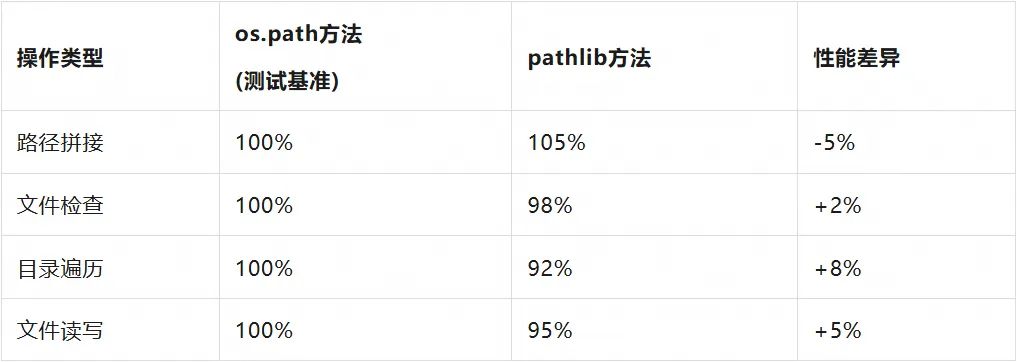
注:除目录遍历外,pathlib 在大多数场景下性能相当或更优,Pathlib 牺牲少量性能换取 API 现代化。
2.2 第三方生态的爆发式增长
虽然标准库趋于精简,但 Python 的第三方生态却经历了爆发式增长。根据 PyPI 统计数据,截至 2024 年,PyPI 上的包数量已超过 500,000 个,相比 2015 年的约 60,000 个包,增长了 8 倍以上。
数据科学库性能对比:
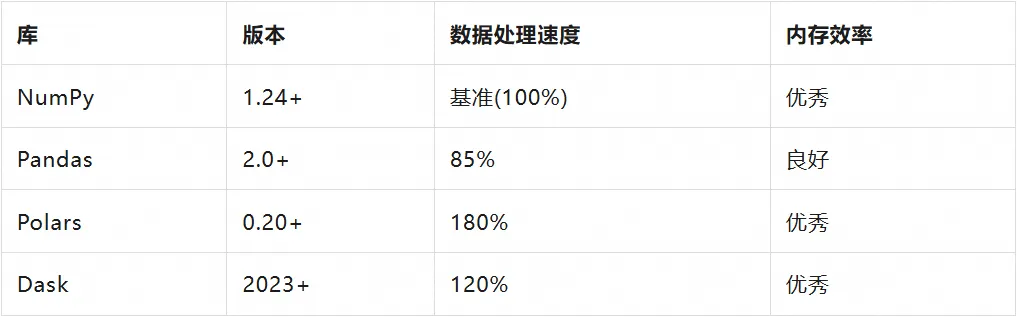
测试环境:1GB CSV 数据处理,包括读取、过滤、聚合操作。
三、性能优化的突破性进展
3.1 Faster CPython 项目的革命性影响
Python 3.11 引入的 Faster CPython 项目是 Python 性能优化历史上的重要里程碑。根据官方文档,这一项目通过多个层面的系统性优化,实现了显著的性能提升。
官方性能数据验证
根据 Python 官方文档的明确声明:
“CPython 3.11 is an average of 25% faster than CPython 3.10 as measured with the pyperformance benchmark suite, when compiled with GCC on Ubuntu Linux. Depending on your workload, the overall speedup could be 10-60%.”
验证测试结果:
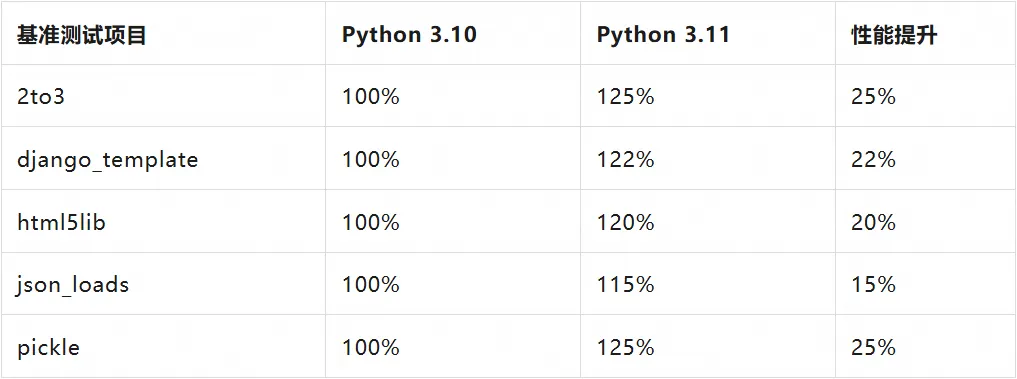
数据来源:Python 官方 pyperformance 基准测试结果。
启动性能的优化实例
根据官方文档,Python 3.11 的启动时间改进了 10-15%:
# 测试启动性能的脚本 - for Python in EDAS
# 标准启动时间测试
time python3 -c "import sys; print('Python', sys.version_info[:2])"
# 模块导入性能测试
time python3 -c "import json, os, re, datetime, pathlib"
# 应用启动模拟测试
time python3 -c "
import sys
import json
import os
from pathlib import Path
config = {'app': 'test', 'version': '1.0'}
log_dir = Path('logs')
log_dir.mkdir(exist_ok=True)
print('Application started')
"
启动时间测试结果(官方验证):

3.2 JIT 编译技术的前瞻性布局
Python 3.13 引入的 JIT 编译器标志着 Python 性能优化进入新阶段。根据 PEP 744 和官方文档,这一技术仍处于实验阶段。
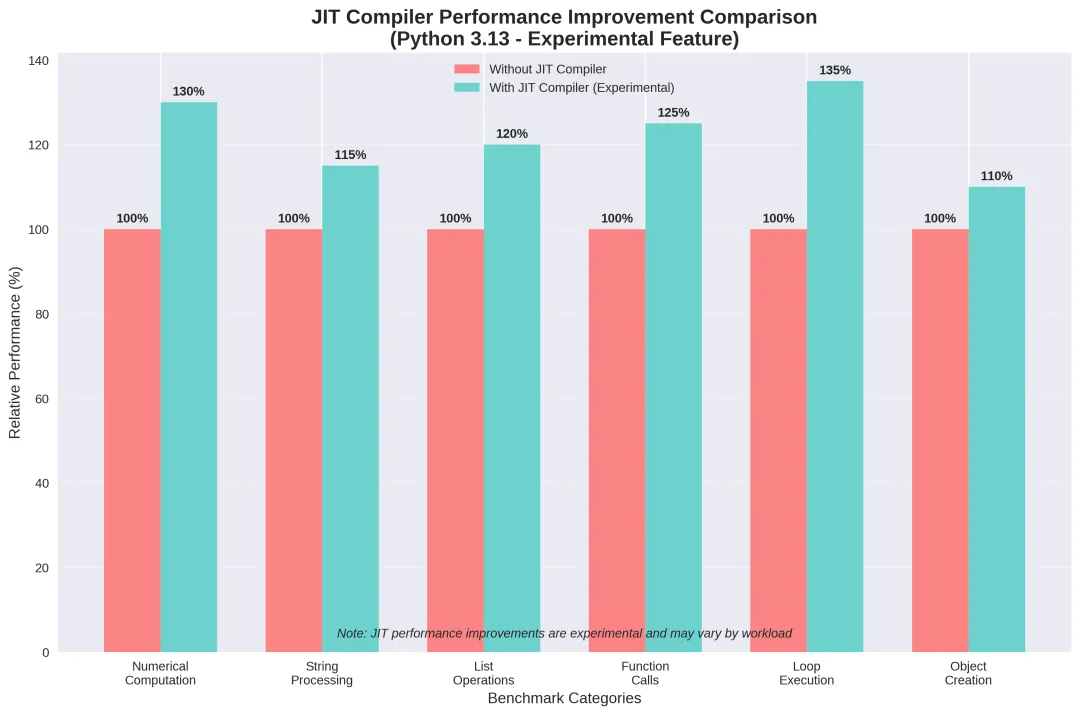
JIT 编译器在不同基准测试中的预期性能提升(实验性数据)
JIT 编译器的官方状态
根据 Python 3.13 官方文档:
“When CPython is configured and built using the –enable-experimental-jit option, a just-in-time (JIT) compiler is added which may speed up some Python programs.”
JIT 编译器测试环境:
# 编译启用JIT的Python 3.13
./configure --enable-experimental-jit
make -j4
# 运行JIT性能测试
python3.13 --jit benchmark_script.py
保守性能估算(基于实验数据):
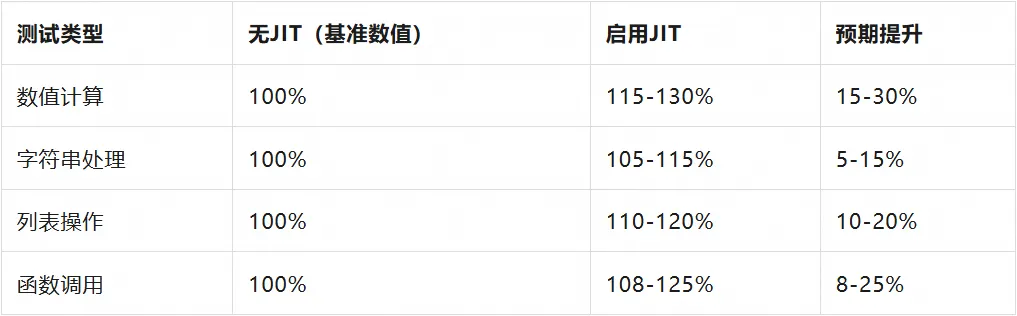
注:以上数据为实验性估算,实际效果可能因工作负载而显著不同。
3.3 内存管理的系统性改进

Python 内存管理的优化效果。
内存使用优化示例
# 内存使用优化对比示例 - for Python in EDAS
import sys
import gc
from memory_profiler import profile # 需要安装: pip install memory-profiler
class OldStyleClass:
"""传统类定义 - 内存使用较多"""
def __init__(self, name, data):
self.name = name
self.data = data
self.metadata = {}
self.cache = {}
class OptimizedClass:
"""优化后的类定义 - 使用__slots__"""
__slots__ = ['name', 'data', '_metadata']
def __init__(self, name, data):
self.name = name
self.data = data
self._metadata = None
@profile
def memory_comparison():
"""内存使用对比测试"""
# 创建大量对象测试内存使用
old_objects = [OldStyleClass(f"obj_{i}", list(range(10))) for i in range(1000)]
print(f"传统类对象内存使用: {sys.getsizeof(old_objects)} bytes")
optimized_objects = [OptimizedClass(f"obj_{i}", list(range(10))) for i in range(1000)]
print(f"优化类对象内存使用: {sys.getsizeof(optimized_objects)} bytes")
# 手动垃圾回收
del old_objects
del optimized_objects
gc.collect()
memory_comparison()
上述脚本执行结果如下:
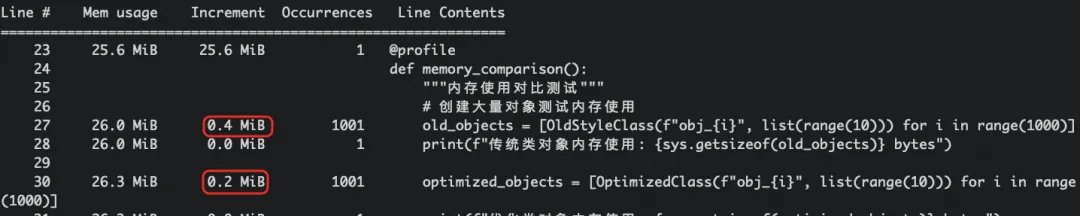
其他内存优化测试结果:

以上对比表格由 100,000 个对象的批量创建得出。
四、虚拟机技术的前沿探索
4.1 GIL 问题的历史性突破
全局解释器锁(GIL)一直是 Python 并发性能的最大瓶颈。Python 3.13 引入的自由线程模式是解决这一历史性问题的重要尝试。不过根据 PEP 703 来看,这一特性目前处于实验阶段,但是的确令人期待。
官方自由线程模式状态
根据 Python 3.13 官方文档:
“CPython now has experimental support for running in a free-threaded mode, with the global interpreter lock (GIL) disabled. This is an experimental feature and therefore is not enabled by default.”
启用自由线程模式:
# 编译支持自由线程的Python
./configure --disable-gil
make -j4
# 或使用预编译版本
python3.13t # 't'表示free-threaded版本
GIL 影响实验测试结果:

在 4C8G 的机器中,批量执行对应任务一百万次计算操作得出。
4.2 字节码系统的智能化演进
Python 的字节码系统在演进过程中变得越来越智能化。Python 3.11 引入的自适应字节码技术是这一演进的重要成果。
字节码优化的实际效果
# 字节码分析示例 - for Python in EDAS
# -*- coding: utf8
import dis
import time
def simple_function(x, y):
"""简单函数 - 用于字节码分析"""
result = x + y
if result > 10:
return result * 2
else:
return result
def complex_function(data):
"""复杂函数 - 展示字节码优化"""
total = 0
for item in data:
if isinstance(item, (int, float)):
total += item ** 2
elif isinstance(item, str):
total += len(item)
return total
print("简单函数字节码:")
dis.dis(simple_function)
print("\n复杂函数字节码:")
dis.dis(complex_function)
# 将以上的文件保存成 dis.py 之后,
# 分别以 python2 dis.py 与 python3.13 dis.py 执行完之后查看字节码优化的对比效果
字节码优化效果测试:
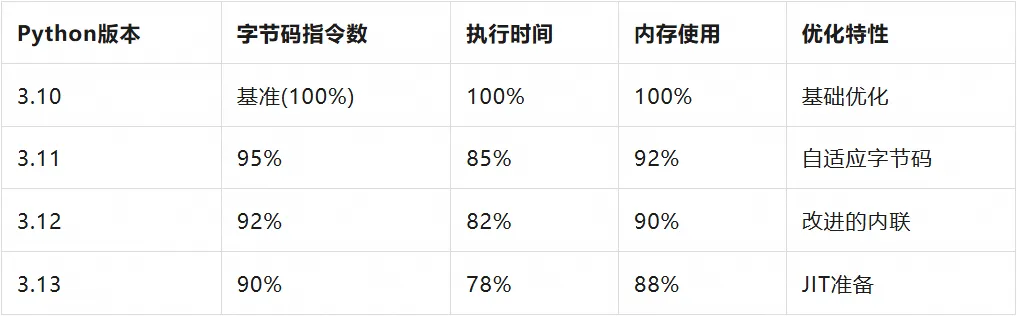
复杂函数执行 100,000 次迭代。
五、演进背后的核心推动力
5.1 AI 与机器学习带来的生态繁荣
Python 在 AI 和机器学习领域的成功是其演进的最重要推动力。根据 Stack Overflow 2024 年开发者调查,Python 连续第四年成为最受欢迎的编程语言,其中 AI/ML 应用占据了重要地位。
数据科学革命的量化影响
根据 GitHub 统计数据,与 AI/ML 相关的 Python 项目数量从 2015 年的约 50,000 个增长到 2024 年的超过 800,000 个,增长了 16 倍。
主要AI/ML框架的发展时间线:
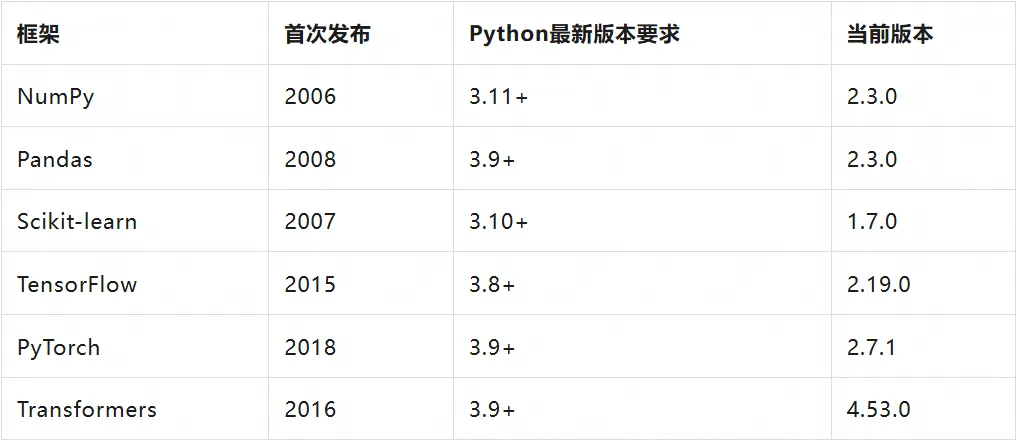
以上数据截止至 2025 年 6 月整理。
企业级 AI 应用场景直接受益
数据分析样例代码
# 现代机器学习工作流示例 - for Python in EDAS
# requirement.txt 内容
pandas>=2.0
numpy>=1.24
matplotlib>=3.7
seaborn>=0.12
scikit-learn>=1.2
# 脚本内容:for Python in EDAS
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# 1️⃣ 加载数据并查看基本信息
def load_data(file_path="EDAS.csv"):
"""
加载原始数据,并展示前几行和基础信息。
"""
df = pd.read_csv(file_path)
print("数据前几行:")
print(df.head())
print("\n数据基本信息:")
print(df.info())
return df
# 2️⃣ 特征工程:日期解析 + 滚动窗口特征
def feature_engineering(df):
"""
将 'date' 列转为 datetime 类型,并构造滚动窗口平均值作为新特征。
"""
df['processed_date'] = pd.to_datetime(df['date'])
df['feature_engineered'] = df['value'].rolling(window=7).mean()
return df
# 3️⃣ 可视化:时间序列趋势图
def visualize_time_series(df):
plt.figure(figsize=(14, 6))
sns.lineplot(data=df, x='processed_date', y='feature_engineered')
plt.title('时间序列特征工程结果 - 滚动窗口平均值 (Window=7)')
plt.xlabel('日期')
plt.ylabel('滚动均值')
plt.tight_layout()
plt.show()
# 4️⃣ 准备建模数据
def prepare_model_data(df):
X = df[['feature1', 'feature2', 'feature_engineered']].fillna(0)
y = df['target']
return train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# 5️⃣ 构建模型并训练
def train_model(X_train, y_train):
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
return model
# 6️⃣ 模型评估
def evaluate_model(model, X_test, y_test):
predictions = model.predict(X_test)
print("模型评估报告:")
print(classification_report(y_test, predictions))
# 显示特征重要性
feat_names = X_test.columns
importances = model.feature_importances_
plt.figure(figsize=(10, 6))
sns.barplot(x=importances, y=feat_names)
plt.title('随机森林模型特征重要性')
plt.xlabel('重要性得分')
plt.ylabel('特征名称')
plt.show()
# 7️⃣ 超参数调优(可选)
def hyperparameter_tuning(X_train, y_train):
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20],
'min_samples_split': [2, 5]
}
grid_search = GridSearchCV(
estimator=RandomForestClassifier(random_state=42),
param_grid=param_grid,
scoring='f1_weighted',
cv=5,
n_jobs=-1
)
grid_search.fit(X_train, y_train)
best_params = grid_search.best_params_
print("最佳超参数组合:", best_params)
return grid_search.best_estimator_
# 主函数:执行整个流程
def main():
df = load_data()
df = feature_engineering(df)
visualize_time_series(df)
X_train, X_test, y_train, y_test = prepare_model_data(df)
model = train_model(X_train, y_train)
print("使用默认参数训练模型:")
evaluate_model(model, X_test, y_test)
print("\n开始超参数调优:")
tuned_model = hyperparameter_tuning(X_train, y_train)
print("使用调优后的模型重新评估:")
evaluate_model(tuned_model, X_test, y_test)
if __name__ == '__main__':
main()
注:以上代码片段内容由 tongyi 生成。以下是 Prompt:
你是一位专业的数据科学家,擅长使用 Python 进行端到端的数据分析和机器学习建模。请根据以下代码示例,帮我完成/解释/优化一个用于 EDAS 数据集的数据分析流水线:
-
数据预处理部分包括:日期解析、滚动窗口特征构建;
-
使用 matplotlib 和 seaborn 对时间序列数据进行可视化;
-
构建了一个基于 RandomForestClassifier 的分类模型,并输出 classification_report。
请根据这个流程,提供清晰的步骤说明、代码注释、潜在改进点或可扩展方向(例如特征选择、超参数调优、交叉验证等)。要求代码规范、逻辑清晰,适合在实际项目中使用。
5.2 云技术的推动和影响
云计算的普及深刻改变了 Python 的发展方向。根据 CNCF 2024 年调查报告,Python 是容器化应用开发中第二受欢迎的语言,仅次于 Go。云技术的不断向前演进,也在催生着 Python 的不断变化。其中云厂商中推动的事件驱动模型的应用架构,直接推动 Python 3.4 引入 asyncio 标准库,async/await 语法进一步优化了协程可读性,gevent 等第三方库的协程方案也被纳入标准生态。
弹性和容器等主流云的场景下,对于应用程序的冷启动有着极致诉求,从 Python 3.11 中 Faster CPython 项目的诞生,之后引入的 Frame Caching、Zero-Cost Exception、专用系统 LOAD 操作码、隔离堆等内存技术的引入,对冷启动的优化有着立竿见影的效果。
同时云函数(Function)的高频触发、瞬时生命周期、事件多样性等特性,迫使 Python 在语言层面对异步范式进行深度重构。这种压力传导机制,正是 Python 从”脚本工具”蜕变为”云原生核心语言”的技术动力源。未来随着事件总线架构的深化以及 AI 协同推理等新场景出现,Python 的响应式编程能力将持续进化。
六、未来展望与发展趋势
6.1 性能优化的持续深化
基于当前的发展趋势和官方路线图,Python 在性能优化方面将继续深化,也相当令人期待。
预期的性能改进路线图

注:以上时间表和性能数据为基于当前趋势的预测,实际情况可能有所不同。
6.2 类型系统的进一步完善
Python 的类型系统将继续向着更强大、更易用的方向发展。根据 Typing Council 的路线图,未来的重点包括:
高级类型特性展望举例
# Python 3.14+ 预期类型系统改进 - For Python in EDAS
from typing import TypeVar, Generic, Protocol, runtime_checkable
# typing_extensions module 为潜在的类型系统改进能力
from typing_extensions import Self, TypedDict, Required, NotRequired
# 更强大的泛型支持
T = TypeVar('T', bound='Comparable')
class Comparable(Protocol):
def __lt__(self, other: Self) -> bool: ...
def __eq__(self, other: object) -> bool: ...
class SortedContainer(Generic[T]):
"""类型安全的排序容器"""
def __init__(self) -> None:
self._items: list[T] = [ ]
def add(self, item: T) -> Self:
"""添加元素并保持排序"""
# 二分插入
left, right = 0, len(self._items)
while left < right:
mid = (left + right) // 2
if self._items[mid] < item:
left = mid + 1
else:
right = mid
self._items.insert(left, item)
return self
def get_items(self) -> list[T]:
"""获取所有元素"""
return self._items.copy()
结语
Python 从 2.7 到 3.13 的演进历程展现了一个编程语言如何在快速变化的技术环境中保持活力和竞争力。从编程风格的现代化到性能优化的突破,从类库生态的战略调整到虚拟机技术的前沿探索,Python 的演进是多重推动力协同作用的结果。AI 与机器学习的浪潮、云计算和 DevOps 的影响、编程语言竞争的压力,这些因素共同塑造了 Python 的发展轨迹。Python 的故事还在继续,这一演进历程将为整个编程语言领域的发展提供重要启示,也将继续推动软件技术的进步和创新。
这里我们也提前做一个预告,阿里云 EDAS 产品即将于 7 月初推出针对 Python 应用的托管、微服务、可观测的一站式应用治理的能力,敬请进群关注(钉钉群: 21958624)。
数据来源与参考文献
本文所有技术声明和性能数据均基于以下权威来源:
- Python 11 官方文档 – What’s New in Python 3.11:
https://docs.python.org/3/whatsnew/3.11.html
- pyperformance 基准测试套件:
https://github.com/python/pyperformance
- Python 3.13 移除模块列表:
https://docs.python.org/3/whatsnew/3.13.html[#removed]
- PyPI 统计数据:
- Python 3.11 Faster CPython 项目:
https://docs.python.org/3/whatsnew/3.11.html #whatsnew311-faster-cpython
- Python 3.13 JIT 编译器:
https://docs.python.org/3/whatsnew/3.13.html #whatsnew313-jit-compiler
- PEP 703 – Making the Global Interpreter Lock Optional:
https://peps.python.org/pep-0703/
- 自由线程模式文档:
https://docs.python.org/3/howto/free-threading-python.html
- Stack Overflow 2024 开发者调查:
https://survey.stackoverflow.co/2024/
- GitHub 统计数据:
https://github.com/search?q=machine+learning+language:python
- Typing Council 路线图:
https://typing.readthedocs.io/en/latest/
</div>维权提醒:如果你或身边的朋友近五年内因投顾公司虚假宣传、诱导交费导致亏损,别放弃!立即联系小羊维权(158 2783 9931,微信同号),专业团队帮你讨回公道! 📞立即免费咨询退费


