
<span id="OSC_h1_1"></span> 一、前言
在云原生架构高速迭代的背景下,基础设施的性能瓶颈与安全隐患成为技术演进的关键挑战。本文系统记录了团队基于Rust语言改造Nginx组件的完整技术路径:从接触Cloudflare的quiche库,引发对Rust安全特性的探索,到通过FFI实现核心逻辑的跨语言调用;从突破传统C模块开发范式自研 ngx_http_rust_module SDK ,到全面采用Pingora框架构建新一代DLB 2.0流量调度平台。
实践表明,Rust的内存安全机制与异步高并发能力可显著提升负载均衡组件的性能边界与可靠性,为超大规模流量调度场景提供全新解决方案。本技术演进过程将详述架构设计、核心模块实现及性能优化策略,为同类基础设施升级提供可复用的工程经验。
二、Nginx+Rust 的模块化探索
探索的起点源于和quiche(cloudflare开发的高效quic实现)的初次邂逅,这扇门将项目组成员引入了 Rust 语言的世界。Rust 以其卓越的内存安全、无惧并发的特性以及出色的性能潜力,迅速展示了其作为系统级编程语言的优势。这份吸引力促使我们思考:能否将 Rust 的安全与性能注入我们更广泛的基础设施中?作为核心组件的 Nginx 自然成为了探索的焦点。
我们首先聚焦于FFI(外部函数接口)技术,通过它构建Rust与C语言的交互桥梁。借助FFI,我们将核心业务逻辑以Rust实现,并将Rust代码编译为符合C-ABI规范的动态链接库。这种设计使得Nginx能够像调用原生C模块一样无缝集成Rust编写的库,在保障系统稳定性的同时提升性能。
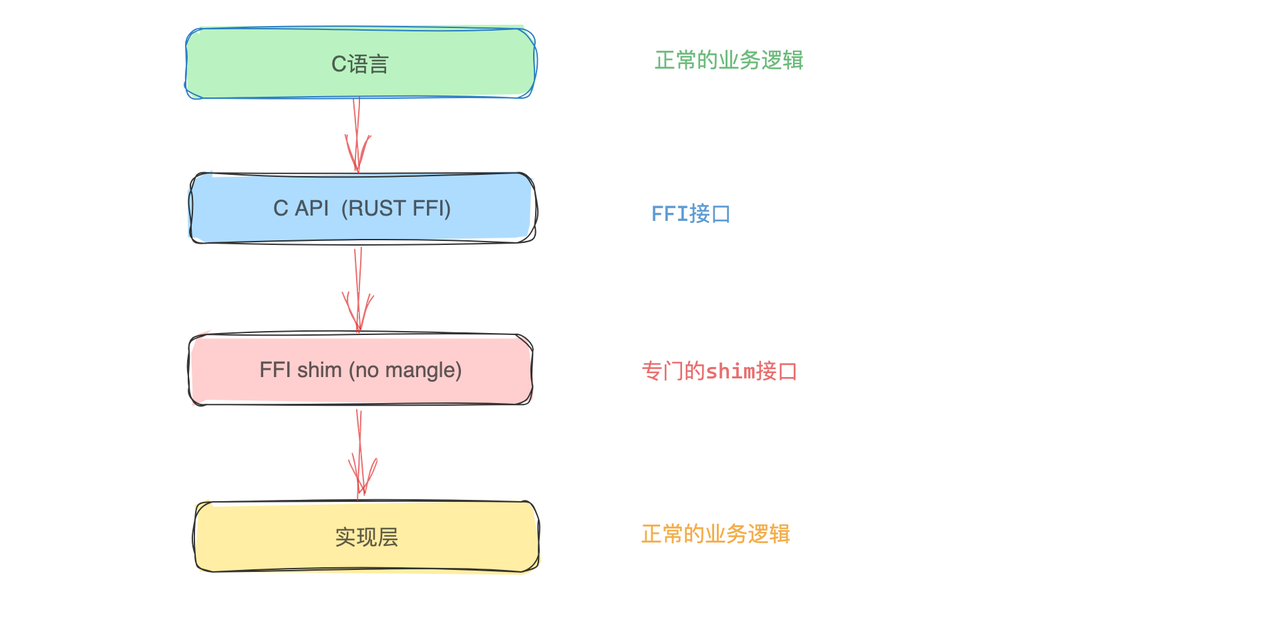
采用该方案的限流模块示例如下:

鉴于单向调用模式在应用场景上的局限性,如果仅仅支持上面的单向调用流,使用的场景将大打折扣,目前Nginx 中大量的功能以三方模块的形式呈现,C module的开发难度较高,需要理解的组件概念颇多,团队尝试开发了ngx_http_rust_module模块作为一个探索期的折中方案。
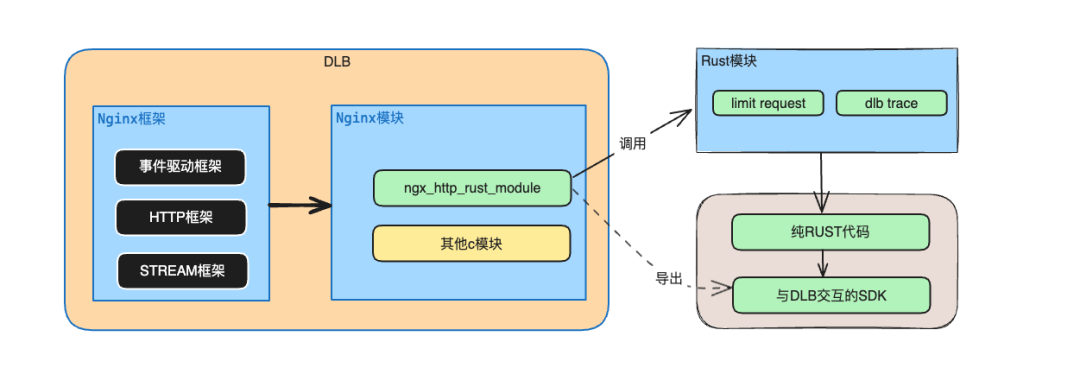
ngx_http_rust_module本质上是一个Rust SDK,是对传统C模块开发模式的一种现代化补充尝试。SDK层封装好的胶水function极大便利了rust module上层开发,可以实现纯Rust编码来实现业务功能,实践验证具备较高工程价值。
目前已封装的部分SDK展示以及设置响应header方法示例:
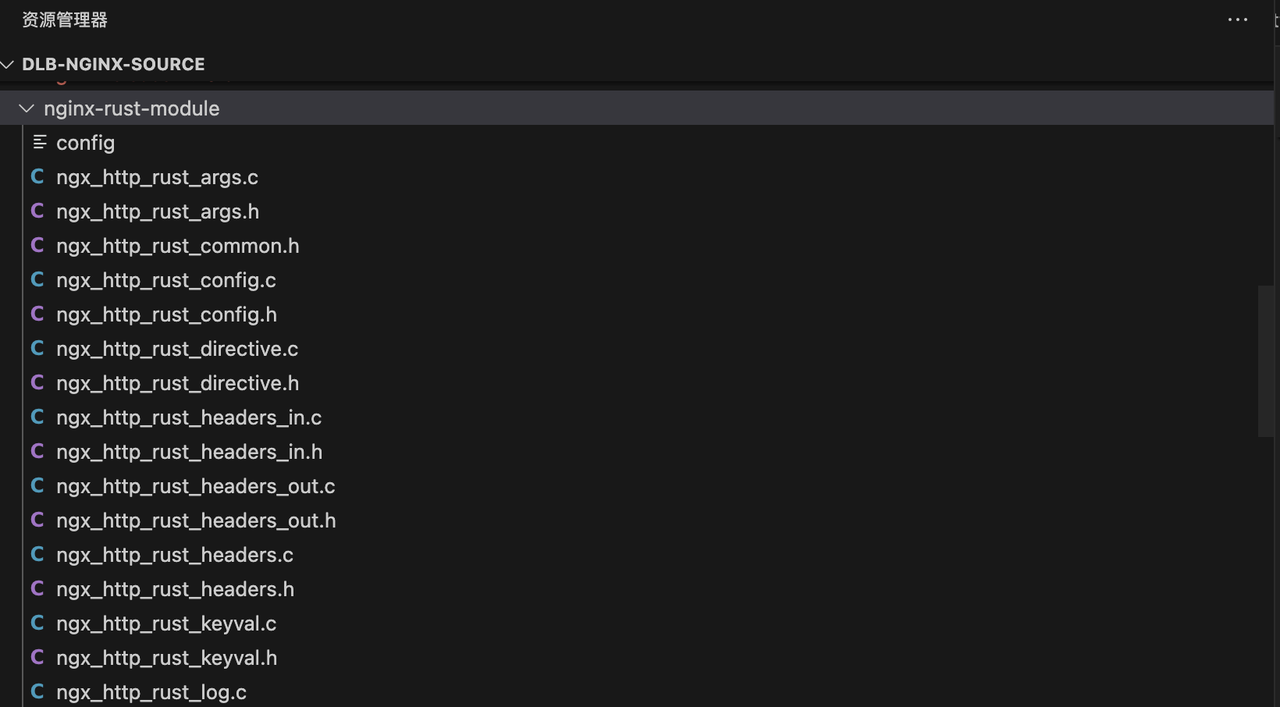
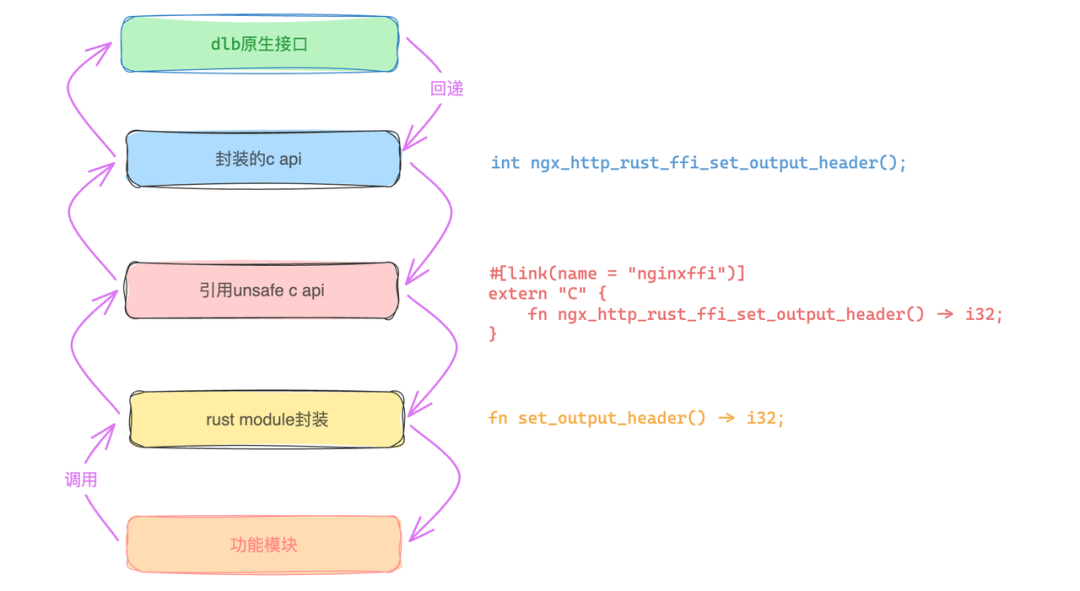
三、全面拥抱Rust进入DLB2.0阶段
完成Nginx模块的初步探索后,团队技术路线转向Cloudflare开源的Pingora框架,该高性能Rust框架专为构建可编程、高可靠的流量调度平台而设计。
核心优势
-
云原生架构 :通过异步任务调度消除Nginx的进程隔离瓶颈,实现CPU负载均衡与高效连接复用。
-
性能突破 :实测每秒可处理10万请求,资源消耗降至传统方案的三分之一。
-
协议生态 :原生支持HTTP/1-2、Websocket端到端代理。
-
安全演进 :基于Rust内存安全特性,集成FIPS认证的加密模块解决C/C++方案的安全隐患。
-
扩展能力 :提供可编程负载均衡API与热升级机制,满足超大规模流量调度需求。
在原型验证其技术可行性之后,团队决定在该框架骨干上构建了DLB 2.0产品体系:
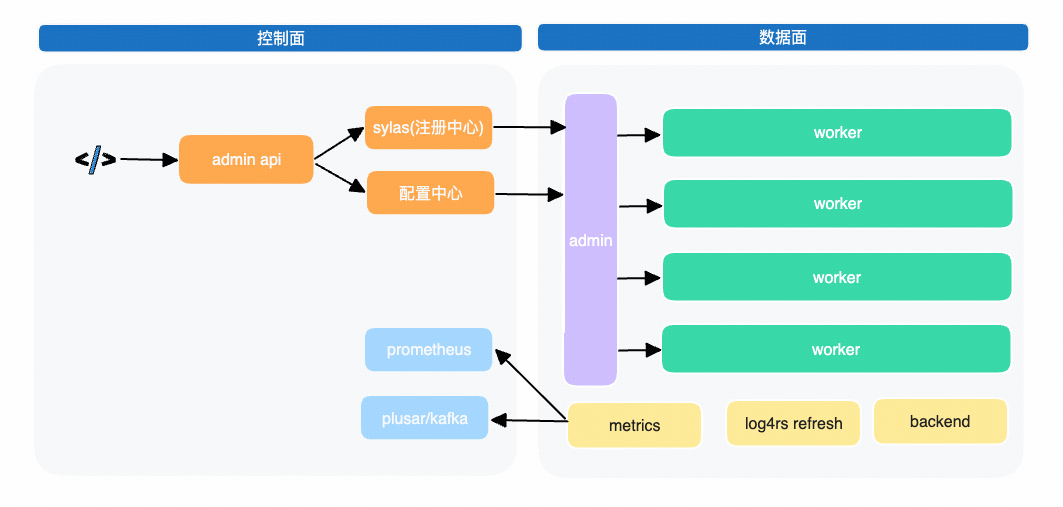
核心能力设计
-
声明式配置管理提供基于YAML的声明式配置接口,显著提升配置可读性与维护效率。支持热加载机制,实现流量无损的配置更新,彻底规避传统代理重载导致的503服务中断。
-
流量处理支持单一端口多域名TLS证书托管能力,简化HTTPS服务部署。提供与Nginx完全兼容的server/path路由匹配逻辑,确保无缝迁移。实现路径重写引擎,满足复杂流量调度需求。采用模块化Filter链设计,支持按需插拔流量处理组件。
-
服务发现集成静态资源配置与动态DNS服务发现双模式。支持sylas注册中心。企业级监控。提供增强型访问日志。输出完全兼容DLB 1.0的监控指标(VTS格式)。保留流量录制数据规范,确保监控体系平滑升级。
每个模块的设计均遵循”高内聚低耦合”原则,在保障生产环境稳定性的前提下,为超大规模流量调度场景提供可扩展的技术支撑,后续将逐一拆解部分关键模块的技术实现细节与性能优化策略。
配置体系
静态配置
DLB 2.0在配置层面按类型拆分成多个细粒度的yaml文件,其中最核心的是 server.yaml 以及 upstream.yaml ,为了对标Nginx核心概念、这部分不引入新的术语,继续沿用 server 、 location 、 upstream 三大基础模块。
-
通过 server 模块声明虚拟主机,支持多域名监听及端口绑定,兼容 server_name 的泛域名解析能力,同时实现单端口多域名 TLS 证书的精准匹配。
-
location 模块完整继承 Nginx 的路径匹配逻辑(含精确匹配 = 、正则匹配 ~ 等模式),支持基于路径的请求路由与正则表达式重写规则,确保策略迁移的零成本适配。同时支持 proxy_pass 、 if 、 proxy_headers 、 return 等核心指令。
-
upstream 动态服务发现机制支持权重负载均衡,通过 YAML 结构化配置实现后端集群的声明式管理,并与DNS的服务发现深度集成,彻底消除传统配置中硬编码 IP 的维护负担。
- id: "hjob.shizhuang-inc.com"
server_name: "hjob.shizhuang-inc.com"
service_in:
- "default_80"
- "default_443"
redirect: true
location:
- path: "/"
access_rule_names:
- "access_allow_d803a06f39ad4dcd8dfe517359a33a61"
- "access_deny_all"
client_max_body_size: "100M"
proxy_headers:
- "clientport:$remote_port"
- "Upgrade:$http_upgrade"
- "Connection:$http_connection"
- "Host:$host"
- "X-Forwarded-For:$proxy_add_x_forwarded_for"
- "X-Forwarded-Proto:$scheme"
proxy_pass: "http://hangzhou-csprd-hjob-8899"
- name: "hangzhou-csprd-hjob-8899"
peers:
- server: "1.1.1.1:8899"
weight: 100
backup: false
down: false
- server: "2.2.2.2:8899"
weight: 1
backup: false
down: false
max_fails: 3
fail_timeout: "10s"
max_connections: 1000配置解析
在DLB 2.0的配置模型中, server 、 location 、 upstream 三者构成层次化路由架构:

-
server 作为虚拟服务单元,通过 Vec
聚合任意数量的 location 路由规则。 -
location 作为请求路径处理器,可独立关联至不同的 upstream 服务组。
-
upstream 采用原子引用计数机制( Arc )封装配置,通过Arc::strong_count() 实时监控引用状态,避免冗余配置拷贝,基于Rust的并发安全特性,最终设计为 Arc
main thread解析完server.yaml与upstream.yaml后,将生成两个核心哈希映射:
-
server 配置映射表:关联域名与路由规则集。
-
upstream 线程安全容器:托管负载均衡服务组状态。
/// A map of server names to their respective configurations.
#[serde(skip)]
pub servers: HashMap<String, Arc<Mutex<ServerConf>>>,
/// A map of upstream names to their respective configurations.
#[serde(skip)]
pub upstreams: HashMap<String, Arc<Mutex<UpstreamConf>>>,运行时配置转化
上述的 ServerConf 与 UpstreamConf 面向的是用户,特点是易于理解与维护、支持YAML反序列化。
而为了专注运行时效率(比如负载均衡策略中的字符串转化为枚举类型),我们会将 UpstreamConf 转化为 RunTimeUpStream 结构, ServerConf 同理。
impl TryFrom<&UpstreamConf> for RunTimeUpStream {
type Error = Error;
fn try_from(value: &UpstreamConf) -> std::result::Result<Self, Self::Error> {
}
}转化之后得到全局唯一的 GlobalConf :
pub static GLOBAL_CONF: Lazy<RwLock<GlobalConf>> = Lazy::new(|| {
RwLock::new(GlobalConf {
main_conf: MainConf::default(),
runtime_upstreams: HashMap::with_capacity(16),
runtime_servers: HashMap::with_capacity(16),
host_selectors: HashMap::with_capacity(16),
})
});
#[derive(Default)]
pub struct GlobalConf {
// main static configuration
pub main_conf: MainConf,
//one-to-one between upstreams and runtime_upstreams
pub runtime_upstreams: HashMap<String, Arc<RunTimeUpStream>>,
//one-to-one between servers and runtime_servers;
pub runtime_servers: HashMap<String, Arc<RunTimeServer>>,
//one service one host selector
pub host_selectors: HashMap<String, Arc<HostSelector>>,
}
流量处理
域名匹配
如果仅有上面的 runtime_servers 这一个哈希表,还不能实现复杂的Nginx域名匹配规则,Nginx域名匹配的优先级机制包括:精确匹配>前置通配符>正则匹配(后置通配符在1.0版本未使用,暂且忽略),为了确保无缝迁移,需要提供与Nginx完全兼容的server匹配逻辑,考虑到代码可维护性,可以这样组织运行时数据:
-
为精确域名使用HashMap,实现O(1)查找。
-
前置通配符匹配存储为Vec,且确保最长匹配优先。
-
正则表达式只能顺序匹配,保持Vec
原顺序。
最终得到这样的结构体:
/// A struct to manage server selection based on host names.
///
/// This struct contains three fields: `equal`, `prefix`, and `regex`.
/// The `equal` field is a HashMap that stores server names and their corresponding IDs
/// when the server name exactly matches the host.
/// The `prefix` field is a Vec of tuples, where each tuple contains a prefix and its corresponding server ID.
/// The `regex` field is a Vec of tuples, where each tuple contains a Regex and its corresponding server ID.
///
/// The `HostSelector` struct provides methods to insert server names and IDs,
/// and to match a given host name with a server ID based on the rules defined in the struct.
#[derive(Clone)]
pub struct HostSelector {
pub equal: HashMap<String, String>,
pub prefixes: Vec<(String, String)>, //原始前通配符数据
pub prefix_nested_map: NestedHashMap, // 嵌套哈希结构优化匹配效率
pub regex: Vec<(Regex, String)>,
}其中需要留意的是成员 prefix_nested_map ,为了确保最长匹配优先,我们将 prefixes: Vec<(String, String)> 转化为了 NestedHashMap 结构, NestedHashMap 为一个嵌套哈希结构,可基于域名分段实现高效检索。
#[derive(Debug, Clone)]
pub struct NestedHashMap {
data: HashMap<String, NestedHashMap>, //层级域名节点
value: Option<String>, // 终端节点关联服务器ID
}
impl NestedHashMap
{
/// 基于域名分段实现高效检索(从右向左匹配)
pub(crate) fn find(&self, key: &str) -> Option<String> {
let tokens = key.split('.').collect::<Vec<&str>>();
let mut current_map = self;
let mut result = None;
// 遍历域名层级(如 www.example.com → [com, example, www])
for token in tokens.iter().rev() {
// 优先记录当前层级的有效值(实现最长匹配)
if current_map.value.is_some() {
result = Some(current_map.value.as_ref().unwrap());
}
// 向下一级域名跳转
let child = current_map.data.get(*token);
match child{
Some(child) => {
current_map = child;
}
None => {
break;
}
}
}
result.map(|value| value.to_owned())
}
}路由匹配
讲完了域名匹配,我们再深入路由匹配,在开始之前,我们先回顾一下Nginx的location指令。
Syntax:location [ = | ~ | ~* | ^~ ] uri { ... }
location @name { ... }
Default:—
Context:server, locationlocation 通常在 server{} 块内定义,也可以嵌套到 location{} 内,虽然这不是一种推荐的配置方式,但它确实是被语法规则支持的, localtion 语法主要有如下几种形式:
※ 修饰符语义及优先级(依匹配精度降序排列)
-
= :精确匹配(Exact Match),URI必须与模式完全一致时生效(最高优先级)。
-
^~ :最佳前缀匹配(Prefix Match),选中最长非正则路径后终止搜索(优先级次于=)。
-
~ :区分大小写的正则匹配(Case-Sensitive Regex)。
-
~* :不区分大小写的正则匹配(Case-Insensitive Regex)。
-
@ :内部定位块(Named Location),仅限 try_files 或 error_page 指令调用,不对外暴露。
Nginx在解析完 location 之后会进行一系列的工作,主要包括:
-
分类: 根据location的修饰符参数标识不同的类型,同时去除name前面的修饰符
-
排序: 对一个server块内的所有location进行排序,经过排序之后将location分为了3类通用类型,通用类型的location将建立一棵最长前缀匹配树正则类型,顺序为配置文件中定义的顺序,正则会用pcre库先进行编译内部跳转类型,顺序也为配置文件中定义的顺序
-
拆分:将分类的3种类型拆分,分门别类的处理
其中最复杂的是最长前缀匹配树的构建,假设location规则如下,构造一棵最长前缀匹配树会经过如下几个步骤:

-
把locations queue变化locations list,假设一个location的name是A的话,所有以A前缀开头的路由节点都会放到A节点的list里(最长前缀匹配)。
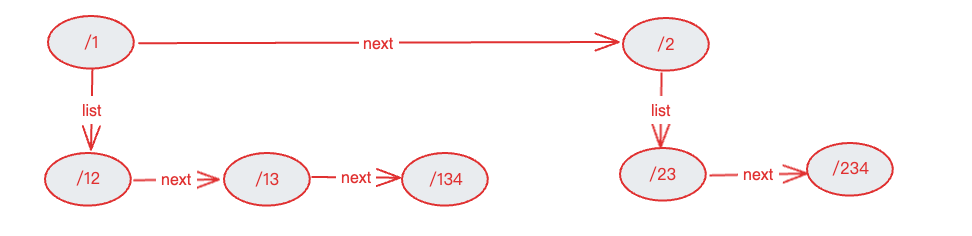
2.按照上述步骤递归初始化A节点的所有list节点,最终得到下面的list。
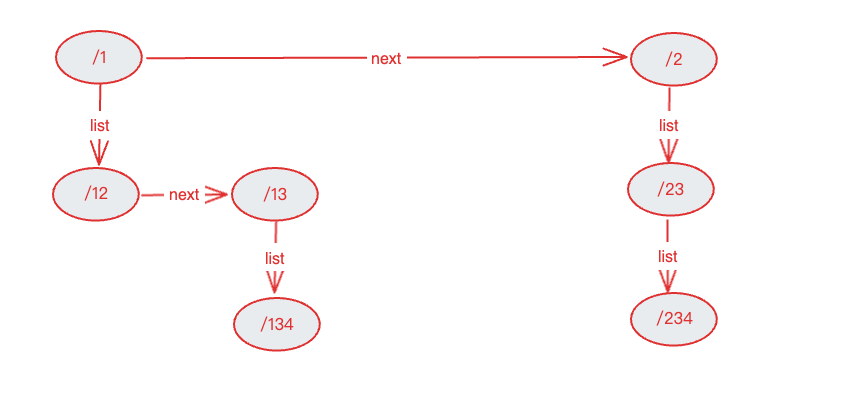
3.在上述创建的list基础上,确定中间节点,然后从中间节点把location分成两部分,然后递归创建左右子树,最后处理list队列,list队列创建的节点会加入到父节点的tree中,最终将生成一棵多叉树。
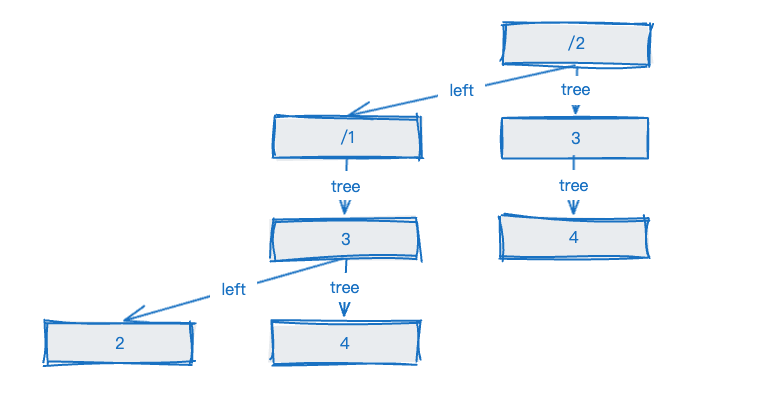
现在你应该已经明白了最长前缀匹配树的构建流程,让我们回到2.0的设计上来,这部分同样维护了三个结构分别对应精确匹配、正则匹配以及最长前缀匹配。
#[derive(Clone, Default)]
#[allow(unused)]
/// A struct representing a shared runtime server configuration.
pub struct RunTimeServer {
/// Unique identifier for the server.
pub id: String,
/// Name of the server.
pub server_name: String,
/// Indicates whether the server should redirect requests.
pub redirect: bool,
/// A HashMap storing equal-matched locations, where the key is the path and the value is the location.
pub equal_match: HashMap<String, Arc<RunTimeLocation>>,// 精确匹配字典
/// A Vec storing regex-matched locations, where each tuple contains a Regex and the location.// 正则匹配队列
pub regex_match: Vec<(Regex, Arc<RunTimeLocation>)>,
/// The root node of the static location tree.
pub prefix_root: Option<Arc<static_location_tree::TreeNode>>,
}精确匹配、正则匹配比较简单,我们重点介绍最长前缀匹配,最长前缀匹配树的构建基本上是把Nginx代码原原本本的翻译过来,通过 create_list() 分组节点、 create_tree() 生成多叉树。通过 find_location 遍历树结构查找最长有效路径,其中路径比较函数 path_cmp() 确保按字典序定位子树,匹配成功时返回( need_stop, location ),其中 need_stop 标志是否中止搜索(模拟 ^~ 行为)。
pub fn find_location(path: &str, node: &Arc<TreeNode>) -> Option<(bool, Arc<RunTimeLocation>)> {
let mut node = Some(node);
let mut uri_len = 0;
let mut search_node = None;
while let Some(current) = node {
let n = std::cmp::min(current.path.len(), path.len() - uri_len);
let node_path = ¤t.path[..n];
let temp_path = &path[uri_len..uri_len + n];
match path_cmp(node_path, temp_path) {
std::cmp::Ordering::Equal => {
uri_len += n;
search_node = Some((current.need_stop, current.val.clone()));
node = current.tree.as_ref();
if uri_len >= path.len() { break; }
}
std::cmp::Ordering::Greater => node = current.left.as_ref(),
std::cmp::Ordering::Less => node = current.right.as_ref(),
}
}
search_node
}路由重写
路由重写是实现请求路径动态转换的核心能力,在语义层面,我们完全兼容Nginx的配置语义。
regex replacement [flag] ,同时采用预编译正则引擎,在路由加载期完成规则编译。
#[derive(Clone, Copy, Debug, PartialEq, Eq)]
pub enum RewriteFlags {
Break,
Last,
Redirect,
Permanent,
NONE,
}
pub struct RewriteRule {
pub reg_source: String,
pub reg: Regex,
pub target: String,
pub flag: RewriteFlags,
}模块化Filter链
Pingora 引擎已经将请求生命周期划分了足够细的各个阶段,为了更精细化控制同一phase执行的各个Filter,可通过自定义的 ProxyFilter trait,与 Pingora 引擎的phase关联起来。
#[async_trait]
pub trait ProxyFilter: Sync + Send {
fn phase(&self) -> ProxyFilterPhase;
fn name(&self) -> ProxyFilterName;
fn order(&self) -> i32;
async fn handle(&self, _session: &mut Session, _ctx: &mut ProxyContext) -> HandleResult {
HandleResult::Continue
}
}ProxyFilter 主要包含四个方法:
-
phase : Filter 的执行阶段, 生命周期阶段锚点,可以根据实际需要进行扩展插入更细粒度的阶段进行请求处理。
-
name : Filter的名称。
-
order : 在同一个phase内Filter的执行顺序。
-
handle : Filter 的执行逻辑,若返回的是 HandleResult::Continue ,则表示当前filter执行完成,继续执行下一个 filter,否则停止filter chain 的执行动作。
#[derive(Debug, PartialEq, Clone, EnumString)]
pub enum HandleResult {
/// 表示当前filter执行完成,继续执行下一个 filter。
Continue,
/// 表示当前filter操作被中断,停止filter chain 的执行动作。
Break,
}目前我们已经实现的Filter包括但不限于:

四、总结
作为《从Rust模块化探索到DLB 2.0实践》系列的第一篇,本文介绍了开发DLB 2.0的背景以及详述了DLB 2.0如何通过声明式配置管理、分层路由架构及与Nginx完全兼容的匹配逻辑,实现亿级流量调度场景下的高可用与零迁移成本。
当前成果验证了Rust在负载均衡产品中改造中的工程价值:依托线程安全的运行时结构(如 Arc
在后续篇章中,我们将继续深入剖析服务发现、监控与日志等核心模块,为超大规模云原生架构提供完整的参考实践。
往期回顾
1.eBPF 助力 NAS 分钟级别 Pod 实例溯源|得物技术
2.正品库拍照PWA应用的实现与性能优化|得物技术
3.汇金资损防控体系建设及实践 | 得物技术
4.得物社区活动:组件化的演进与实践
5.从CPU冒烟到丝滑体验:算法SRE性能优化实战全揭秘|得物技术
文 / 雷泽
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。
</div>维权提醒:如果你或身边的朋友近五年内因投顾公司虚假宣传、诱导交费导致亏损,别放弃!立即联系小羊维权(158 2783 9931,微信同号),专业团队帮你讨回公道! 📞立即免费咨询退费


