
<span id="OSC_h4_1"></span> 导读
随着AI时代的到来,各类AI工具层出不穷,业界都在探索一套完整的AI加成的提效方案,我们团队基于自身特色,利用起团队沉淀好的历史知识库,落地了一套深度结合AI的工作流,用AI武装研发团队,实现研发效率的提升。
背景
-
各类AI研发工具层出不穷,很多现成工具可使用,业界都在探索一套完整的AI加成的提效方案
-
团队内部规范文档完备,但是没有融入开发流程中
-
Code review、研发自测、接口文档更新消耗大量时间
目标
1. 拥抱AI时代,让团队更先进。
2. 用AI武装研发团队,通过资源的配合与协调,实现研发效率的提升。
思路
1. 拆分研发流程,并找到AI结合点,并将其串联起来。
2. 深度探索AI IDE,得出最佳实践。
3. 利用起团队的知识库,为AI提供辅助能力。
定位
1. 这是一个锚点,自此开始团队研发流程向AI化转变。
2. 这是一个开始,带动团队与其他同学review当前研发流程,共建更多研发工作流。
01 研发链路
对研发链路进行拆解,得到不同阶段的AI工作流形态,并基于当前形态向下一形态进行推进。
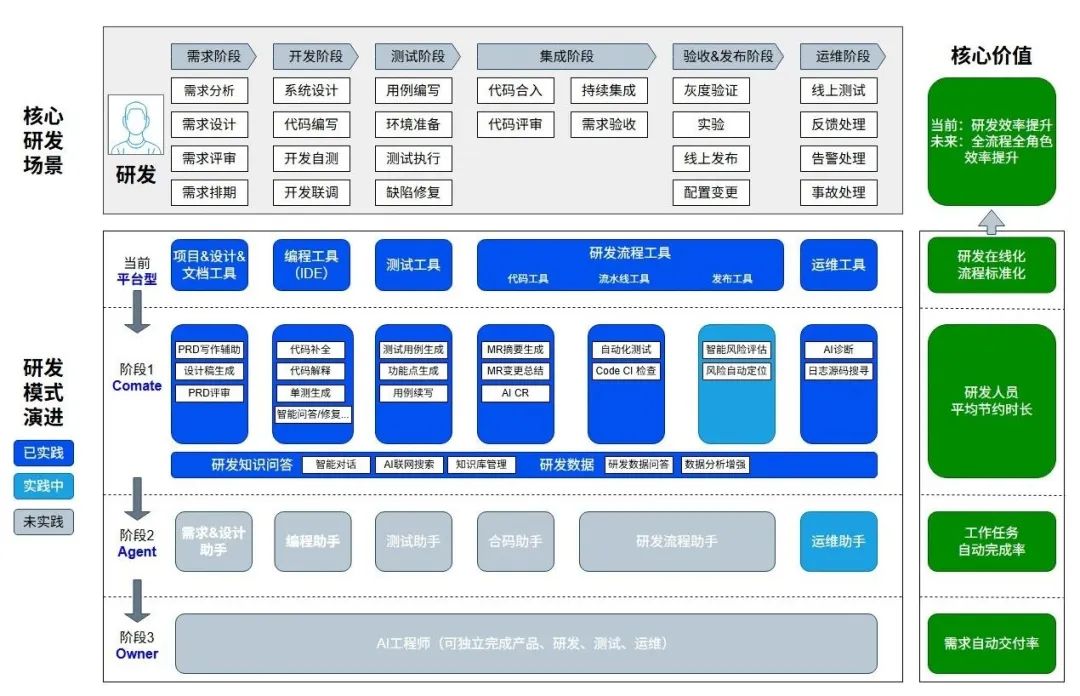
当前我们团队正处于阶段1接近完成,阶段2正在开始探索实践的阶段,因此下面我们会基于我们团队在这些方面的实践进行分享。
原本研发链路:

AI加持研发流程:

AI 工作流
对上面涉及到的AI工作流进行补充说明
AI-Cafes:AI生成需求文档,制作产品原型图,节省产品人天。
AI-Docs:需求文档转技术文档,节省研发梳理过程,节省研发人天。
AI-DocsCoding:基于技术文档,生成基础无业务逻辑代码,节省研发人天。
AI-Coding:基于团队内部代码规范生成代码,减少返工和代码理解成本,深度提高研发效率,节省研发人天。
AI-API:基于MCP Server打通接口文档,避免api文档/技术文档更新不及时,节省研发人天。
AI-CR:基于Rules,进行AI Code Review,节省研发人天。
AI-Develops:AI赋能测试、验证、监控环节,节省测试人天。
02 需求阶段
AI-CafeDocs
在原本的工作流中,在需求评审过后,研发同学通常需要至少0.5d的人力进行技术文档的落地,以及api接口的准备。
但是这一步中的大部分工作是重复的,可替代的,可节省的。
因此我们实现了了_需求文档 -> aisuda(百度的低代码平台)-> 大模型 -> 技术文档(markdown)_的工作流。
在微调好大模型之后,我们只需要以下两步就能完成技术文档+api接口准备的工作:
1. 投喂需求文档给大模型,得到初版技术文档。
2. 人工check技术文档。
在快速生成了技术文档后,后端再和前端进行沟通,根据细节进行修改具体实现。
AI-DocsCoding
在得到技术文档之后,我们下一步要做的则是落地。不得不承认,我们的工作中无可避免的会存在一些基础的CRUD环节,这是正常的,也是重复的,可替代的,可节省的。
因此,基于以上的 AI-CafeDocs环节,我们进行了进一步的延伸,实现了_技术文档 -> MCP Server -> AI IDE_ 的工作流
我们通过MCP打通了内部的知识库,使得AI能够阅读到需求文档和技术文档,了解上下文,并进行对应的开发工作。
当然,AI全流程开发只是一种理想的状态,就当前而言,AI-DocsCoding写出来的代码并不是完全可用的,在涉及到的业务逻辑越复杂时,代码的正确性就越低。
但是不要紧,我们在设计这个流程的时候,就早有准备。
还记得我们强调的一点:让AI取代重复的,可替代的,可节省的工作,那么正确的流程为:
1. AI通过MCP阅读需求文档、技术文档,生成本次功能的基础代码——除却业务逻辑之外的参数处理、数据处理的CRUD代码。
2. 人工补全核心的业务逻辑处理,人也只需要关心真正的业务逻辑,这些事AI无法替代的。
可以看到,在以上的两个工作流里,人的角色从执行者,变成了驱动者/观察者,或者说产品经理。
我们通过**向AI提出需求,监督AI工作,验收AI工作结果**的方式进行工作。
03 开发阶段
AI-Coding
AI-Coding这一块主要围绕 AI IDE的使用,现在市面上有很多的产品,比如Cursor、Comate、Trae等。其实在许多人看来,AI IDE的核心在于底层能够接入的模型,但是我觉得这不尽然,大模型的边界效应很强。
有些时候,我们对AI IDE的使用,还没有达到需要区分模型效果的地步。或者说,如果我们使用了世界上最好的模型,那我们是否就高枕无忧了,可以让AI全程进行Coding而不需要人为Review了?
至少使用到今天为止,我们认为AI-Coding,还离不开人的关注,因此如何更好地使用AI进行Coding,是AI提效的必经之路。
合理使用Rule
在AI IDE内,Rule是一个非常重要的环节,它是连接开发者意图与 AI 代码生成行为之间的关键桥梁。
定义:Rule 的 核心目的是指导 AI 更准确地理解当前代码库的上下文、遵循特定的项目规范与编码标准、生成符合预期的代码,或辅助完成复杂的工作流程。Cursor 官方文档将其描述为“控制 Agent 模型行为的可复用、有作用域的指令”。
作用:大型语言模型(LLMs)本身在多次交互之间通常不具备持久记忆。Rule 通过在每次 AI 请求的提示词(prompt)层面提供持久化、可复用的上下文信息,有效解决了这一问题。当一个规则被应用时,其内容会被包含在模型上下文的起始部分,从而为 AI 的代码生成、编辑解释或工作流辅助提供稳定且一致的指导。
上面有一个非常重要的点,那就是所有的rule在使用的过程中,都会占用我们上下文的token,因此如何更好的使用Rule,是提升AICoding能力的关键。
基于我们的实践,我们建议将 AI IDE 的rule进行层级划分:
第一层:IDE全局层 (User Rules)
-
位置:User Rules
-
范围:所有项目通用
-
内容:个人编码风格偏好
-
限制:50行以内
第二层:项目基础层 (Always Rules)
-
位置:
.xx/rules/always/ -
范围:整个项目强制遵循
-
内容:技术栈、核心原则、基础规范
-
限制:100行以内
第三层:自动匹配层 (Auto Rules)
-
位置:
.xx/rules/auto/ -
范围:特定文件类型或目录
-
内容:模块专门的开发规范
-
限制:每个规则200行以内
第四层:智能推荐层 (Agent Rules)
-
位置:
.xx/rules/agent/ -
范围:AI根据对话内容智能判断
-
内容:优化建议和最佳实践
-
限制:每个规则150行以内
第五层:手动调用层 (Manual Rules)
-
位置:
.xx/rules/manual/ -
范围:手动调用的代码模板
-
内容:完整的项目或模块模板
-
限制:每个规则300行以内
基于以上的划分,我们再给出对 已有/未有 Rule规范的代码库的 Rule 创建规则(语言不重要,以Go为例):
内容优化原则:
-
避免:
-
详细代码示例(每个100+行)
-
重复的概念解释
-
推荐:
-
简洁要点列表(每个20-30行)
-
具体的操作指令
globs精确匹配:
-
避免:
-
过于宽泛:
"**/*.go"(匹配所有Go文件) -
推荐
-
精确匹配:
"internal/handler/**/*.go"(只匹配处理器) -
精确匹配:
"internal/repository/**/*.go"(只匹配仓储层) -
精确匹配:
"**/*_test.go"(只匹配测试文件)
优先级设置详解:
优先级数值范围:1-10,数值越高优先级越高
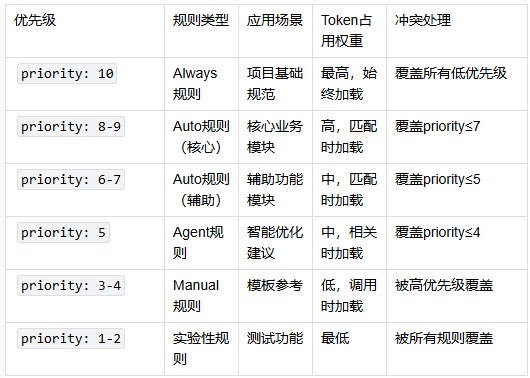
优先级使用策略:
1. 基础规范用10:项目必须遵循的核心规范
2. 核心模块用8-9:handler、service、repository等主要模块
3. 辅助模块用6-7:middleware、config、utils等辅助模块
4. 优化建议用5:性能优化、最佳实践等智能建议
5. 模板参考用3-4:代码模板、脚手架等参考资料
6. 实验功能用1-2:测试中的新规范,避免影响稳定功能
冲突解决机制:
-
当多个规则应用于同一文件时,高优先级规则会覆盖低优先级规则的冲突部分
-
相同优先级规则按文件名字母顺序加载
-
Always规则始终优先于所有其他类型规则
Rule 的核心价值在于它 ****为开发者提供了一种机制,用以精细化控制 AI 在代码理解、生成、重构等环节 ****的行为。
通过预设规则,开发者可以将项目规范、编码标准、技术选型乃至特定业务逻辑“教授”给 AI,从而显著提升 AI 辅助编程的效率、保证代码质量的均一性,并确保项目整体的规范性。
它使得 AI 从一个泛用的助手,转变为一个深度理解特定项目需求的“领域专家”。
记忆库
基于Rule的运用,我们通过memory bank + rule生成专属业务研发助手
在AICoding的使用中,有一种常见的痛点场景,就是在复杂的项目中,AI无法感知到整个项目的历史上下文,即便是有Codebase的存在,也对业务逻辑是一知半解。
在我们实践的过程中,引入了记忆库的模式,深化AI对项目的理解和记忆,使得每一次需求迭代的上下文都被记录下来。
生成了memorybank后,我们可以随时通过对话查看项目大纲和内容,并且每一次重新进入开发,不会丢失之前的记忆。
这种模式,其实就是Rules的一种应用,它把上下文总结在代码库的制定位置,强制AI在每次进入时会阅读上下文,回到上一次Coding的状态,对于解决上下文丢失的问题有非常大的帮助。
这里可能有人会问,记忆库和IDE本身的长期记忆功能有什么区别?
答:记忆库是公共的项目记忆库,IDE长期记忆是私人的IDE使用记忆。
而记忆库的详细内容,这里不作详细分享,它只是一份提示词,感兴趣的同学只要简单搜索一下就能找到很多的资源。
MCP Server(重点)
MCP(Model Context Protocol),模型上下文协议,由Anthropic于24年11月提出,旨在为大语言模型和外部数据源、工具、服务提供统一的通信框架,标准化AI与真实世界的交互方式
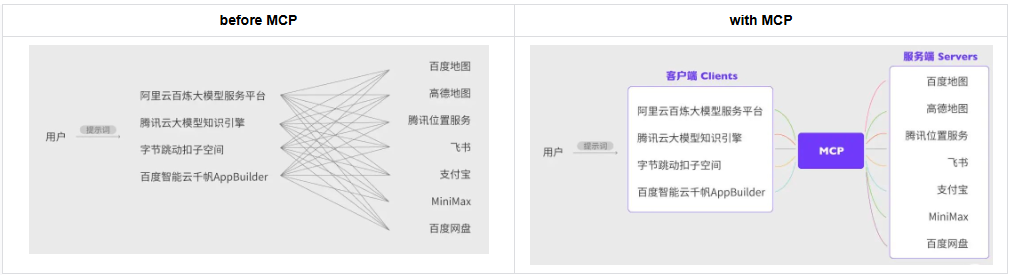
MCP的核心架构包括三环:
-
Host主机:用户与AI互动的应用环境,如Claude Desktop、Cursor;
-
Client客户端:充当LLM和MCP server之间的桥梁,将用户查询指令、可用工具列表、工具调用结果发给LLM,将LLM需要使用的工具通过server执行调用;
-
Server服务器:轻量级服务节点,给予AI访问特定资源、调用工具能力的权限;目前已有数据库类(如SQLite、supabase)、工具类(如飞书多维表格)、应用类(如高德地图)服务器。是MCP架构中最为关键的组件。
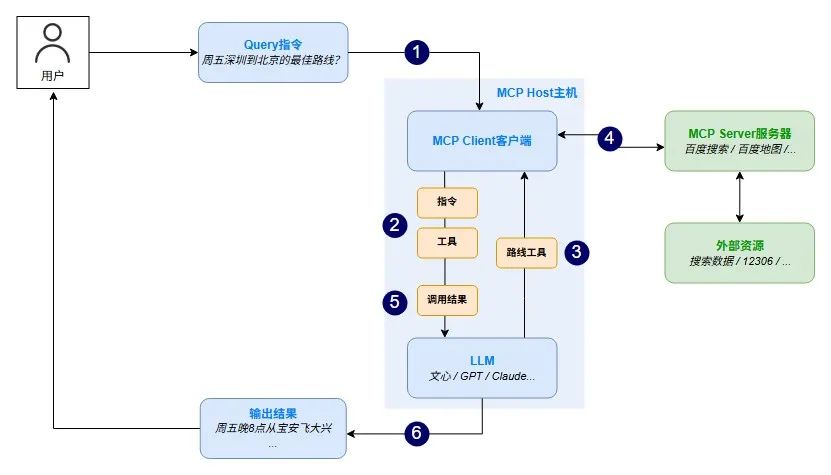
在开发中,我们可以接入以下几种MCPServer
1. 实时搜索,baidu/google/github/微博等
2. 存储,mysql/redis等
3. 工具,kubectl/yapi等
用法一:我们接入百度搜索的MCP
1. 搜索问题:在开发之余搜索一下 夜的命名术 是否完结。
2. 搜索知识点:在想知道Go1.24新特性时,通过MCP进行搜索,让AI进行总结。
3. 搜索用法:在想了解Linux的快捷命令时进行搜索。
以上这些场景,并非非MCP不可,非AI IDE不可,但是通过这样的方式,我们至少节省了切换到浏览器,搜索,自己总结结论,返回继续Coding这些步骤。
用法二:client里直接进行多client操作
1. Redis自然语言查询:
2. MySQL自然语言查询:
3. GCP自然语言查询:
其他的client(kubectl等)我就不一一列举了,但是可以看到,当我们在我们的IDE内集成了各种各样的client后,开发效率能极大地提升。
当然,这里有两个关键点:
1. 接入mcpserver并不需要我们研究,我们只要把mcp server的链接丢给AI,它自己就能开始接入
2. 禁止在开发环境使用线上client账号密码
AI-API
相信无论是前端还是后端开发,都或多或少地被接口文档折磨过。前端经常抱怨后端给的接口文档与实际情况不一致。后端又觉得编写及维护接口文档会耗费不少精力,经常来不及更新。
其实无论是前端调用后端,还是后端调用后端,都期望有一个好的接口文档。但是随着时间推移,版本迭代,接口文档往往很容易就跟不上代码了,更会出现之前的同学没有把接口文档交接清楚就离职,留下一个繁重复杂的项目,重新啃起来异常艰难,不亚于自己从头写一遍。
痛点
1. 重复劳动:每一个涉及到前后端的功能,研发都需要手动进行维护接口文档,在一些时候,接口最后和最开始的设定有可能大相径庭,每一次改动都是非常令人头疼的工作。
2. 低效沟通:前后端在沟通接口后,再进行对应的代码开发,其实是一件重复的,可替代的,可节省的工作。
为了解决这些痛点,通过引入 AI 自动化功能,搭建API MCP Server,帮我们解决这些冗杂的工作,让研发人力更多的集中在核心业务代码的开发上,提升代码开发效率、降低沟通成本。
这是我们一直畅想的场景,后端开发完代码 -> AI 推送接口文档 -> API文档自动更新 -> AI 拉取接口文档 -> 前端生成代码
也就是前后端的研发同学,只关注业务功能的实现,而不需要关注这些接口对接的繁琐工作。
Better Thinking
这是我想补充的两个使用AICoding的思想,也是我使用下来的一个感悟。
一:学会递归使用AI
场景:在IDE内布置MCP Server
通常的做法是:
1. 在MCP Server市场找到想用的MCP Server
2. 把配置部署好
3. 开始调试,完成后投入使用
递归式使用做法:
1. 在MCP Server市场找到想用的MCP Server
2. 把链接丢给AI,让它自己安装(递归)
3. 安装完后让它自己修改mcp.json的配置(递归)
4. 修改完成后让它自己调通(递归)
更进一步我们还可以:
1. @Web 让AI找一个可用的McpServer(递归)
2. …(递归)
3. …(递归)
4. …(递归)
二:把AI当成一个真正的工具
场景:写某篇文档的时候,我突然想要做一个Gif格式的图片示例。
已知:电脑支持录屏,但是我缺少视频转Gif格式的工具。
麻烦点:
1. 如果通过百度/Google搜索网页在线工具,非常麻烦,还要付费。
2. 如果通过内部的视频裁剪服务,还需要起服务来处理。
3. 如果通过剪映这样的工具,那还要下载一个软件。
以上这些点,都不算困难,但都相对麻烦,属于能做但是又要浪费一点精力。
解决方案:
理论上让AI写和让GPT/Deepseek写没什么区别,但是我们的操作步骤得到了以下简化:

也就是说,我们在遇到很多**自己能做,但是又觉得麻烦,浪费精力的场景 以及 大部分的杂活**,都可以第一时间Ask Ourself,Can AI Do it?
包括但不限于:
-
捞数据
-
写文档
-
找bug
-
…
AI-Coding VS Original-Coding
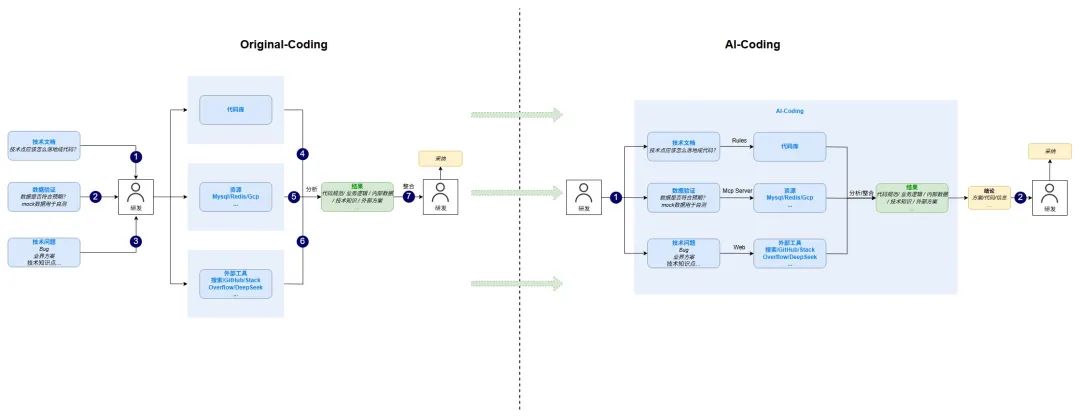
04 集成阶段
AI-CR
问题
1. 时间压力:团队每周可能需要审查数十个CR,高T同学需要审查的居多,每个 CR 的细节往往耗费大量时间。
2. 沟通低效:CR评论描述不清晰,开发者需要来回沟通确认修改点。
3. 重复劳动:相似的代码改动需要重复审查,难以专注关键问题。
为了解决这些痛点,通过引入 AI 自动化功能,提前规避一些基础问题,让CR人力更多的集中在关键问题上,提升代码审查效率、降低沟通成本。
解决方案
工作流

05 运维阶段
AI-Develops
随着业务系统的复杂度不断增加,运维过程中产生的告警数量急剧增长,传统的人工处理方式已经无法满足快速响应的需求。
目前在我们来看,现有的运维体系存在了以下的弊端:
1. 告警存在非常厚的方向壁垒,不同方向的同学遇到另一个方向的告警时大都只能进行Case路由。
2. 告警存在非常厚的年限壁垒,团队不同年限的同学遇到Case的应对时间有可能天差地别。
一个点是否足够痛,决定了我们是都要优化。
在我们团队内,有丰富的case处理文档和记录,也有着应对问题经验非常丰富的同学,但是在值班同学遇到告警轰炸的时候,同样会焦头烂额。
回顾起告警处理的过程,其实大部分都是重复的,可替代的,可节省的工作,它们是有方法论的,并非遇到之后就手足无措。因此我们构建一个智能化的应急诊断系统,通过AI技术提升故障处理效率,减少平均故障修复时间(MTTR)。
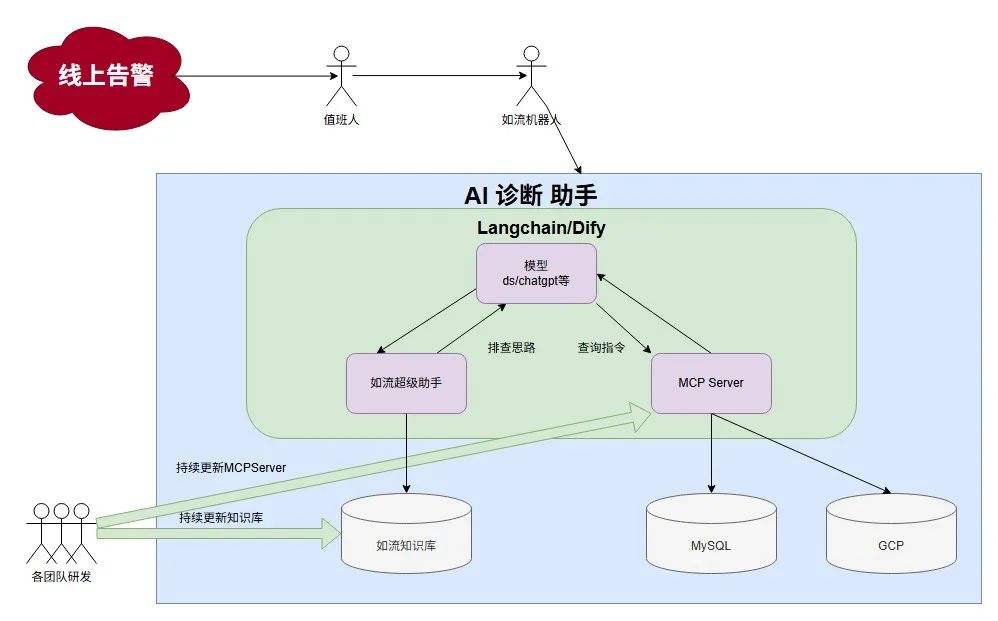
在这种模式下,AI可以自动捕捉消息,在遇到告警信息的时候自动分析给出结论,如果有AI无法解决的问题,才会轮到人工进行介入。
这种模式最大的优点在于:所有出现过的Case/已有的文档都会沉淀为AI的记忆和知识库,从今往后只会有新增的Case需要人来解决,存量全都会被AI拦截,换而言之,团队内多出了一个永远不会离开,且能够同时接受所有方向培养的AI运维人员。
06 总结
以上就是我们百度国际化广告团队的AI提效实践,也希望这篇文章能作为一个锚点,带动所有看到这篇文章的同学review自己所在团队的工作流程,共建更多的AI加持工作流。
就如我上面说的,其实AI的用法很简单,它就是我们的助手,假如我们的工作中真的存在一些重复的,可替代的,可节省工作,那不妨把这些工作交给AI试试。
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


