
<p>波司登集团作为全球领先的羽绒服公司,每年的销售旺季集中在四个月间,需高效把握业务机遇以实现高营收。为满足集团销售旺季的实时数据分析需求,同时降低淡季数据分析成本,波司登决定升级大数据架构,<strong>采用阿里云数据库 SelectDB 版升级数仓,基于阿里云 SelectDB 云原生存算分离架构,实现了资源隔离与弹性扩缩容,并取得了查询性能提升 2-5 倍、总体成本降低 30% 以上、效率提升 30% 的可观收益。</strong></p> 业务需求
波司登集团自 1976 年创立以来,专注羽绒服制造领域已有 48 年,产品畅销全球 72 个国家。2021 年,波司登羽绒服销售规模达到全球领先,并且在 2023 年实现全年营收 232.14 亿元,同比增长 38.4%。近年来,波司登集团通过数据驱动的精细化运营,成功从”羽绒服专家”转型为”多品类功能性服饰巨头”,其数据分析业务覆盖门店运营、电商平台、用户运营等多个环节。
- 门店运营:波司登门店规模目前已超过 3500 家,运营注重精细化及高效化**。门店数据分析服务须具备高并发与低延迟能力**,以应对节假日、新品发布、促销及寒潮期间的销售高峰期,实时监控库存与销售数据,快速调整销售策略与促销活动,基于单门店坪效和区域消费偏好,优化商品陈列及库存分配;
- 电商平台:波司登电商平台覆盖天猫、京东、抖音等主流平台,粉丝总量超 5000 万。由于线上促销活动频繁(如季节上新、节日大促),电商平台流量波动显著高于线下门店,数据分析服务需在具备高并发与低延迟能力的同时,具备弹性扩展能力,根据流量高峰与低谷灵活配置不同规模计算资源,以支持实时调整活动策略与管理库存;
- 用户运营:波司登用户运营聚焦精准化与个性化,数据分析服务需支持人群圈选,通过用户年龄、消费频次、偏好等标签划分细分市场。 结合 CRM 系统和大数据分析,实现会员生命周期管理(如休眠用户唤醒、高价值用户专属权益),并针对不同群体设计差异化活动(如向年轻用户推送联名款,向高净值客户推荐高端系列)。
为满足上述业务场景并驱动集团发展,波司登将数据分析需求分为以下四类:
- 实时报表: 建立上百张实时报表,覆盖线下门店库存管理、电商平台数据监控、供应链生产需求管理及物流配送优化等核心业务场景,确保业务部门能够实时掌握关键数据,快速响应市场变化;
- 离线报表: 离线报表为业务部门提供线下门店、线上各渠道基础运营分析,涵盖销售、库存、营销等维度的周报、月报和年报,帮助业务部门了解业务表现并制定长期策略;
- 人群圈选: 通过用户年龄、消费频次、偏好等多维度标签,精确划分市场。并针对不同群体设计差异化活动,帮助实现精准营销;
- 即席查询: 为内部专业的数据分析师提供自助式数据获取能力。支持对门店、物流、工厂等数据进行长周期的关联分析及深度下钻,挖掘业务洞察,辅助决策优化。
早期架构痛点
- 波司登集团原数据架构
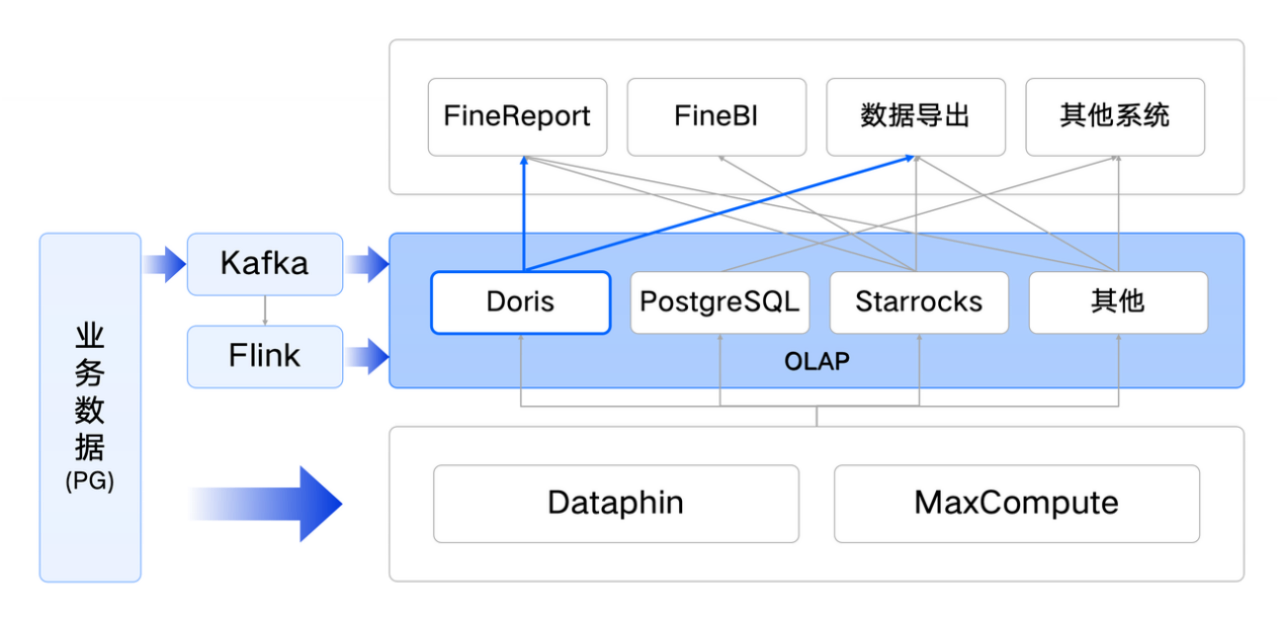
为支撑上述数据分析需求,研发与数据管理部门分别部署了 Apache Doris、PostgreSQL、StarRocks 等多个分析引擎。其中 Apache Doris 主要用于复杂业务逻辑的实时分析查询,PostgreSQL 主要用于简单业务逻辑的实时分析查询,StarRocks 则用于离线数据的 BI 报表分析和人群圈选业务。
该架构存在以下问题:
- 架构复杂、冗余存储:多分析引擎会存储多份数据,造成存储与计算资源冗余;
- 稳定性不足、性能受限:为满足时效需求,复杂报表有时直接在业务库中查询以提高数据时效性,但会为在线业务系统带来风险,影响其他重要业务稳定性。此外,复杂查询占用大量机器资源,性能受限,且因多个业务查询负载不同,需多独立计算组隔离资源,数据共享需多次跨计算组流转查询,导致效率较低;
- 不支持弹性扩缩容:存算一体模式在弹性扩容方面存在不足,导致扩缩容代价高昂,难以适应业务高峰和低谷期的差异。
为解决以上问题,波司登决定全面升级现有架构,统一分析引擎,引入存算分离新架构,完成新一代大数据平台和数仓升级建设。基于实际业务场景,波司登明确了以下升级需求:
- 新架构需支持高并发点查询,在海量并发读写实时报表场景下响应稳定,平均 RT 要求毫秒级别,以满足人群圈选业务与 VIP 报表查询需求,为业务高效运转提供支撑;
- 新架构需支持复杂 SQL 查询,在满足 10 并发的情况下秒级返回,以满足实时和离线报表高并发查询需求;
- 新架构需支持业务之间资源隔离,避免业务间相互影响。并需要拥有集群快速扩缩容能力,确保在高并发或大数据量处理时灵活配置资源,保持高性能和稳定性;
经过多款产品测试对比,波司登发现阿里云 SelectDB 能够支撑高并发点查询,实现秒级查询响应,并具备资源隔离能力,完全满足业务需求。利用阿里云 SelectDB 存算分离架构及快速弹性扩缩容特性,可实现按需付费,有效降低成本。最终,波司登决定基于阿里云 SelectDB 升级 OLAP 分析平台。
基于阿里云 SelectDB 升级 OLAP 平台
- 波司登集团基于阿里云 SelectDB 升级后的数据架构
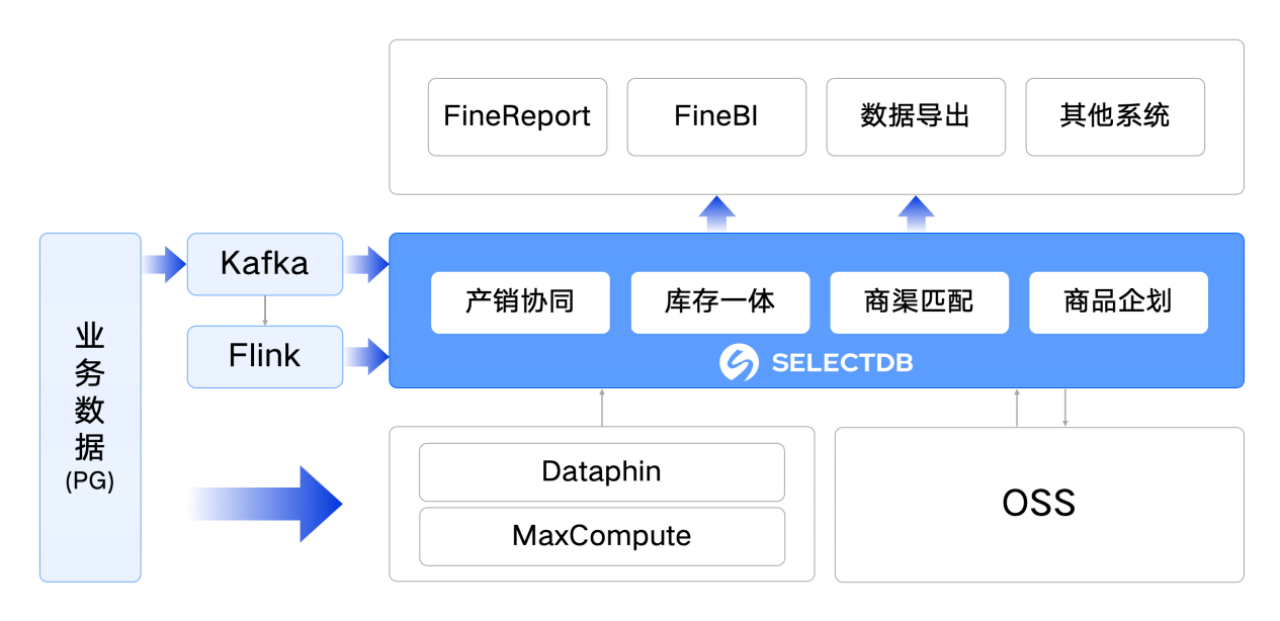
波司登将原架构查询引擎与计算引擎统一升级为阿里云 SelectDB,替换原先架构中 Apache Doris、Starrocks、PostgreSQL 等其他技术栈,并将原有的存算一体架构升级为存算分离架构。
- 阿里云 SelectDB 技术架构图

波司登集团升级后的数据架构基于阿里云运行,无需自行搭建并维护复杂的数据平台,而是由阿里云负责底层基础设施管理与维护,在运维方面降低了成本。
阿里云 SelectDB 存算分离架构能够根据波司登淡季、旺季不同规模的业务需求,灵活配置计算资源规模,迅速适应业务变化。同时,该架构支持不同业务在共享数据时,实现计算资源的有效隔离,兼具稳定性与高效率。
充分利用云上多样化存储介质,阿里云 SelectDB 将数据直接存储到成本较低的 OSS 对象存储中,在降低资源成本的同时,显著增强的数据的高可用性。此外,针对热数据,也会将其缓存至成本相对较高的 SSD 存储中,确保热数据查询的极速响应。
此外,作为阿里云生态系统的一员,阿里云 SelectDB 能够无缝集成阿里云其他产品与服务,这不仅简化了波司登的数据管理和分析的流程,同时提升了业务处理的效率。
数据流转方案
在基于阿里云 SelectDB 的新架构中,波司登数据链路分为实时与离线两条链路。
- 实时数据链路分为两条路径:
- 大规模实时报表场景主要采用 Debezium 采集源端数据,它能同时捕获上百张表。作为 Kafka Connector Source,Debezium 将业务数据写入至 Kafka。随后,Doris Kafka Connector 作为 Sink Connector,将数据从 Kafka 写入 SelectDB,此过程支持上百张表同时产生和消费数据, 并支持多 Topic 并行,实现了数据链路的统一管理和统一监控;
- 中小规模实时场景主要采用 Flink SQL 采集源端数据,后通过 Doris Flink Connector 消费数据写入到 SelectDB,Doris Flink Connector 支持攒批与 Checkpoint 模式,实现快速开发、数据实时入库与分析查询。
- 离线数据链路则专注于 T+N 数据处理,处理后的数据存储于 MaxCompute 中, Dataphin 以全量或增量方式通过 Stream Load 将数据写入阿里云 SelectDB 。在数据导入期间通过配置血缘关系,在合适的时机触发异步物化视图刷新,用于提升查询性能。
相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


