
<p><img src="https://oscimg.oschina.net/oscnet/up-82005e71e418bc9fc0008c21157e8844f3d.png" alt=""></p> 本方案中基于 Databend 实现一个数据快速汇聚及实时去重,实现一份数据多种工作负载,把原来数据共享的推模式变成:增量订阅模式 + 抽取推送两种模式。从而让有后台开发经验或会 SQL 的人,也可以在 Databend 上实现海量数据平台的建设。
基本概念
实时数据汇聚平台通常用于实时收集、整合和处理多个数据源的数据。 主要应用于:主数据平台建设,省级数据交易所基础数据汇聚等。在该平台建设中我们借助于 Databend 实现数据的高速摄入,治理,查询及对外服务等。
Databend 基于对象存储和 k8s 架构下开发的云原生数据平台,该产品使用 Rust 开发,注重平台的性能和安全性,以 SQL 为交互语言,支持海量存储和计算的数据平台。
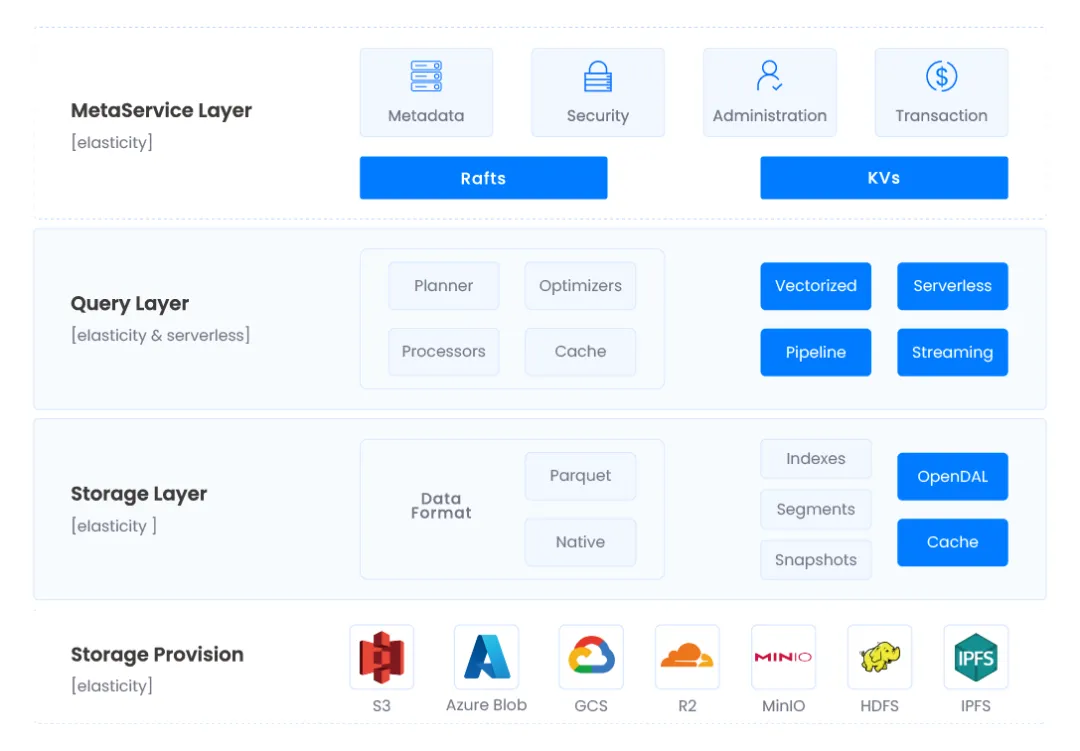
- Databend engine 内置微分区技术,让用户不用关注分区;
- 表级默认每个字段建立 min/max, bloom index 索引,让用户无需关注索引;
- 支持 cluster key,按某个列或组合列排序存储数据(linear cluster key, hilbert cluster key);
- 支持 fulltext index、聚合索引、like 加速,支持多种查询模式;
- 轻量化元数据设计,元数据服务无后顾之忧;
- 集群能力轻松扩展。
平台目标
- 实现数据的实时汇入,保留原始数据到一张表中 (ODS 层);
- 支持对 ODS 层的数据进行增量订阅及后续处理;
- 支持去重数据实时合并+更新到目标表中;
- 支持数据按条件抽取;
- 支持表级以 SQL 的方式获取增量及实现增量订阅能力;
- 支持 SQL 方式在平台做 SQL 治理;
- 支持完整的权限隔离;
- 支持租户和用户实现底层数据共享(非授权和跨库访问),需要的数据可以在当前库看到;
- 实现一份数据全平台共享;
- 实现一份数据多种工作负载;
平台架构及说明
在数据汇聚平台中需要考虑每个系统的边界,如何切分功能:如何保证数据异常的情况下实现数据的一致性; 如何做到各个组件的高可用实现等等问题。 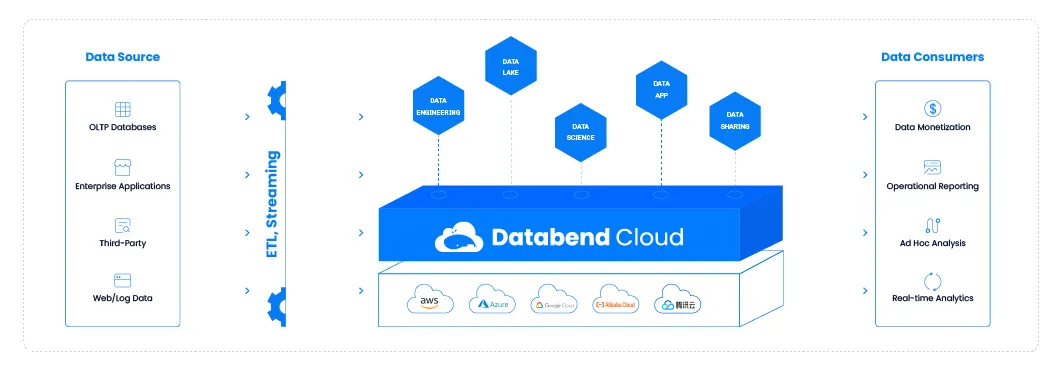
在基于 Databend 的数据汇聚平台,数据汇聚通常以 S3 作为中转,接收到的数据以 json 格式写入到 S3 中,Databend 支持面向 S3 的数据加载,在 Databend 中将 ETL 变成了 ELT。 另外一种边界是前端的数据摄入工具把数据写入 Kafka 中,Databend 从 Kafka 中获取订阅的数据。
下面部分把数据汇聚平台的一些工作细化一下,供各位参考。
2.1 高速写入
在数据汇聚平台,数据接入可以分为两类:从数据接入网关到 Databend 和 从 Kafka 中到 Databend 两种形式。 数据接入网关是一种海量的模式,可以应付每秒近千万的数据写入,从 kafka 到 Databend 可以用于每秒在百万以内的数据数据量接入。 其实两者有相通之处,可以共同切换,需要在实际落地中评估一下成本。
从数据接入网关到 Databend
数据平台通常需要面对海量的数据汇聚,可能同时需要上百张表或是上千张表的数据接入任务。整体架构如下: 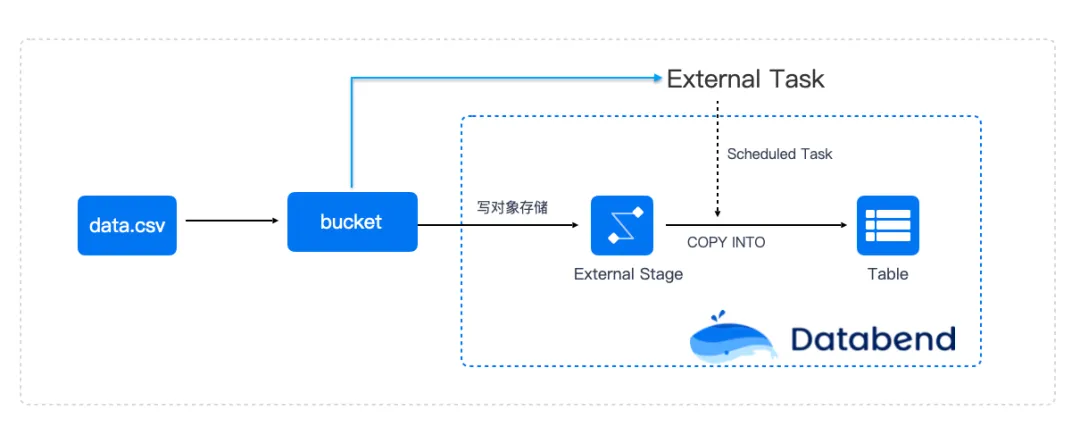
-
数据源产生数据上传到数据接入网关,数据接入网关把数据按某种频度或是行数写到对象存储指定的 bucket 下对应的位置
-
Databend 中通过 External Stage 概念和这个 bucket 关联
create stage mystage ‘s3://databend_upload‘ connection=( endpoint_url=”https://url“, region=’us-east-01′, access_key_id=”, secret_access_key=” );
-
数据接入网关通过调用定时调用 SQL 或是某个时间频度通过 SQL 下发命令对数据进行加载
copy into T from @mystage/20250310/ pattern=’.*[.]parquet’ file_format=(type=parquet) purge=true;
虽然 Databend 的 copy into 语句支持数据转换处理,但一般建议保留原始格式,不建议在此处进行转换。
该方式数据加载可以做到每秒 500 万-2000 万之间,随着集群的 CPU core 增加可以做到性能的提升。
更多内容参考下面文档 https://docs.databend.com/sql/sql-commands/dml/dml-copy-into-table
从 kafka 到 Databend
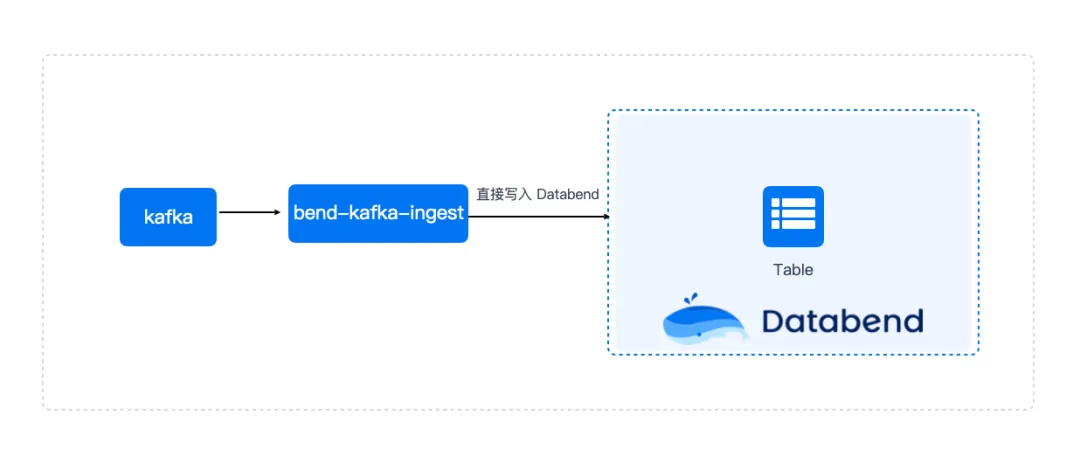
可以基于 bend-kafka-ingest 直接摄取 Kafka 中的数据, 该方式只支持 Kafka 中为 json 格式的消息体。
2.2增量获取
Databend 的 Stream 功能能够捕获表的插入、更新和删除增量,常用于实时数据流处理及分析场景。基于 Stream,用户可以轻松获取每个表的增量数据,实现流式计算分析。结合 Task 和 Stream,用户不仅能够优化数据分析性能,同时提高资源利用率。
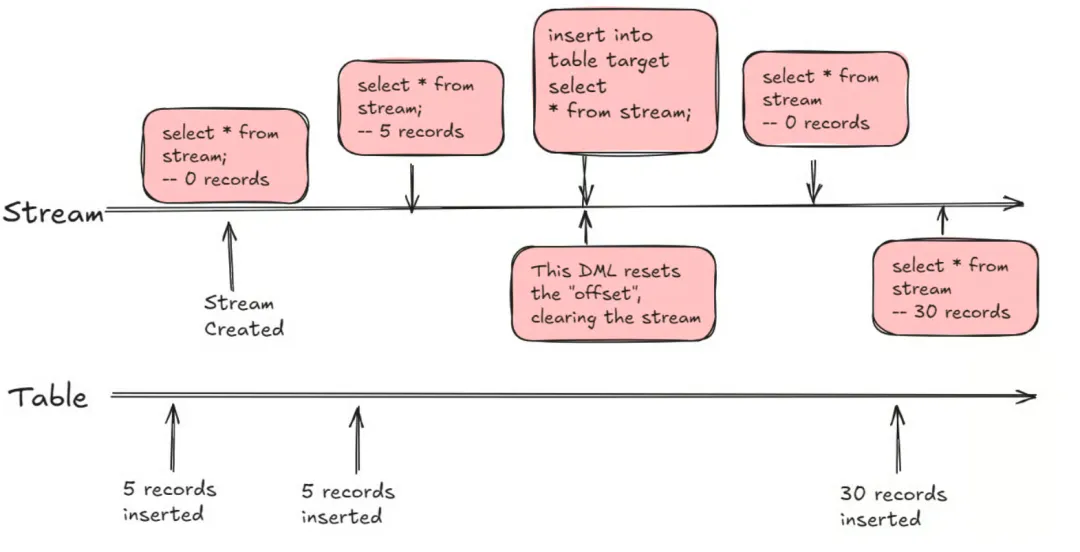
在 Databend 中,Stream 是对表更改的动态和实时表示。Stream 被创建以捕获和跟踪对关联表的修改,允许在数据更改发生时持续消费和分析数据变化。 Databend Cloud 上这个实际案例:更多用于推荐系统,利用 Stream 获取增量的数据,然后调用 Remote-UDF-Server Pool 中的相应函数,产生推荐使用的一些数据。
Databend Stream 是基于 Databend Fuse engine 的 Time Travel 特性构建,不需要额外的空间开销。
2.3 基于增量到目标表去重合并
在 Databend 可以把数据先加载到 ODS 表,然后对 ODS 的增量做去重后合并到目标表。
MERGE INTO target_dwd a
using
( select * from source_ods_stream qualify row_number() over(partition by pk order by add_time desc)=1) b
on a.pk = b.pk and ...
when matched and b.action='update' then
update ...
when matched and b.action='delete' then
delete
when not matched then
insert ...
通过整合 merge into 结合窗口去重针对指定的冲突键的情况下实现数据的近实时合并。
该过程是 merge into + stream 相当于传统大数据架构中的 kafka + flink 的区间去重。 但在这个过程中可以在 Databend 中直接使用 SQL 完成,大大减化了开发。
2.4 基于增量订阅
在 Databend 中一个表可以支持 N 个( N 没有限制)Stream 可以用于订阅数据的变化,也可以把 Databend 当成一个 Kafka 使用, 而且更方便做数据核对。
在 Databend 中,Stream 可以以两种模式运行:
- 标准模式:捕获所有类型的数据更改,包括插入、更新和删除;
- 仅追加模式:在此模式下,Stream 仅包含数据插入记录。数据的更新或删除不会被捕获。 用户在创建 Stream 时,可以使用 APPEND_ONLY 参数(默认为 true)来指定模式。 Databend Stream 的设计理念是专注于捕获数据的最终状态。例如,如果您插入一个值并多次更新它,Stream 只会在被消费之前保留该值的最新状态。 在 Stream 功能的支持上,加上 Task 管理员,可以让 Databend 非常友好的支持实时计算。
2.5 数据抽取
Databend 中支持基于 Stream 的增量数据抽取。
select * from source_ods_stream01 with consume;
该 SQL 执行后,对应的 Stream 会指向后续的数据增量。
另一种数据抽取建议基于时间或是指定的条件去通过 SQL 直接获取,这块需要用户控制 SQL 的 GAP 防止抽取中出现空洞出现丢数据的问题。
2.6 平台内数据共享
在 Databend 因为是存储分离架构,数据和计算分离,Databend 在对象存上也持久化了每个表对应的源数据,这样可以让该表非常容易被平台中其它租户或是用户使用,从而减少了数据搬家的开销。
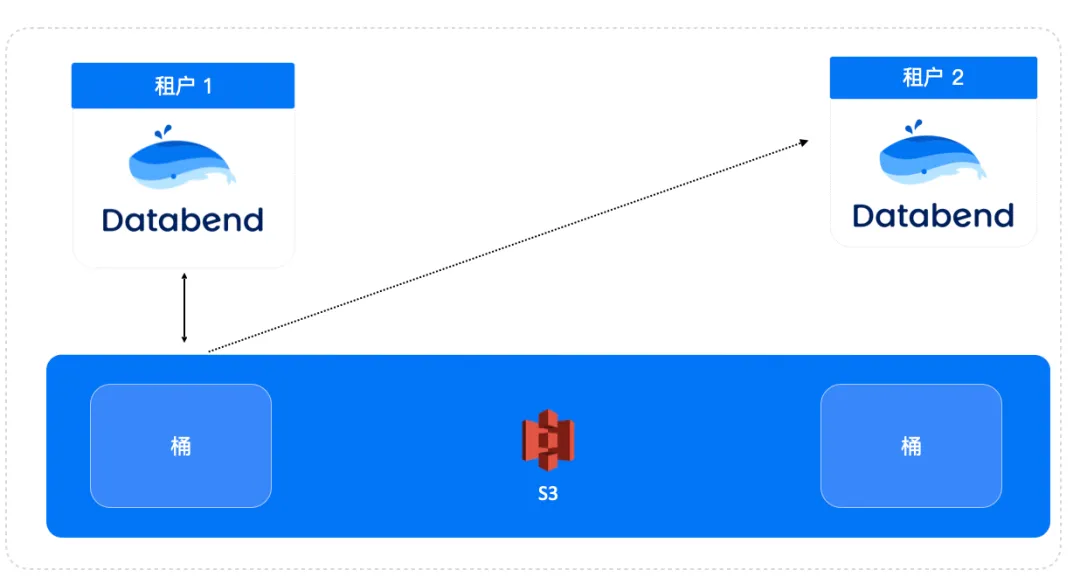
对应的 SQL 语句:
attach table attch_t01
's3://bucketname/db_id/table_id/ '
connection=(
endpoint_url="https://url",
region='us-east-01',
access_key_id='',
secret_access_key=''
);
Databend 通过存算分离的架构,支持一份数据全局使用,可以动态注册到不同的租户|用户中,节省数据迁移同步开销。一份数据多处使用。 基于 Databend 的 system.tables 可以非常方便的构建一个简易的数据集市。
2.7 一份数据多种工作负载
在 Databend 可以实现一份数据被多个不同工作负载的集群使用,对于计算层也可以有针性地去调优及配置资源。
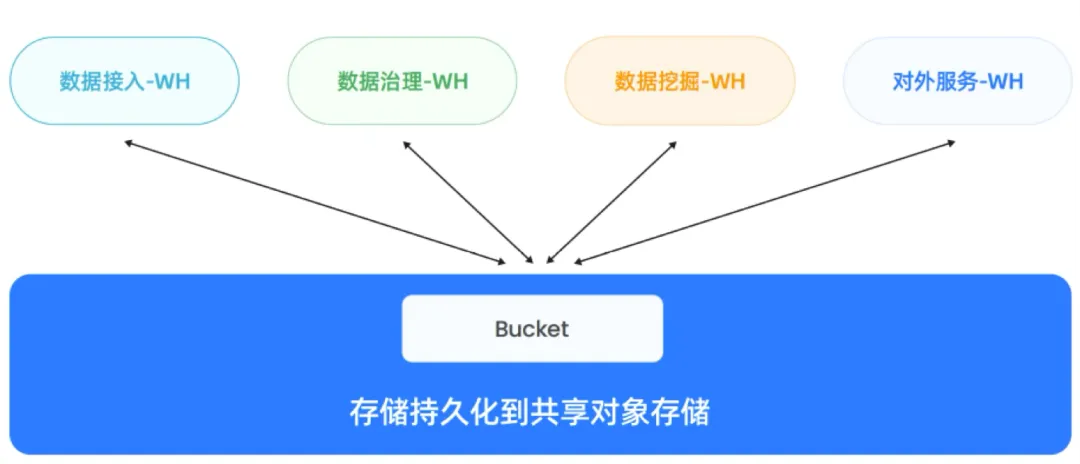
- 接入集群:使用批量加载功能,将 S3 中的文件加载到 Databend 的轨迹表中(可能会有重复数据),每个轨迹表带有一个 stream 表,通过内置的 CDC 进行增量数据捕获;借助于 stream 获取每个表的增量数据,并调用 ETL 语句将数据写入合并表,实现数据的简单加载处理;
- 数据治理集群可以对数据进行精细加工和治理;
- 数据挖掘集群,通常用于数据科学家做一些数据探索工作;
- 对外服务集群:可以对外提供 API 服务,允许外部系统通过 API 访问和查询数据。
同一个业务下支持多集群来顶并发
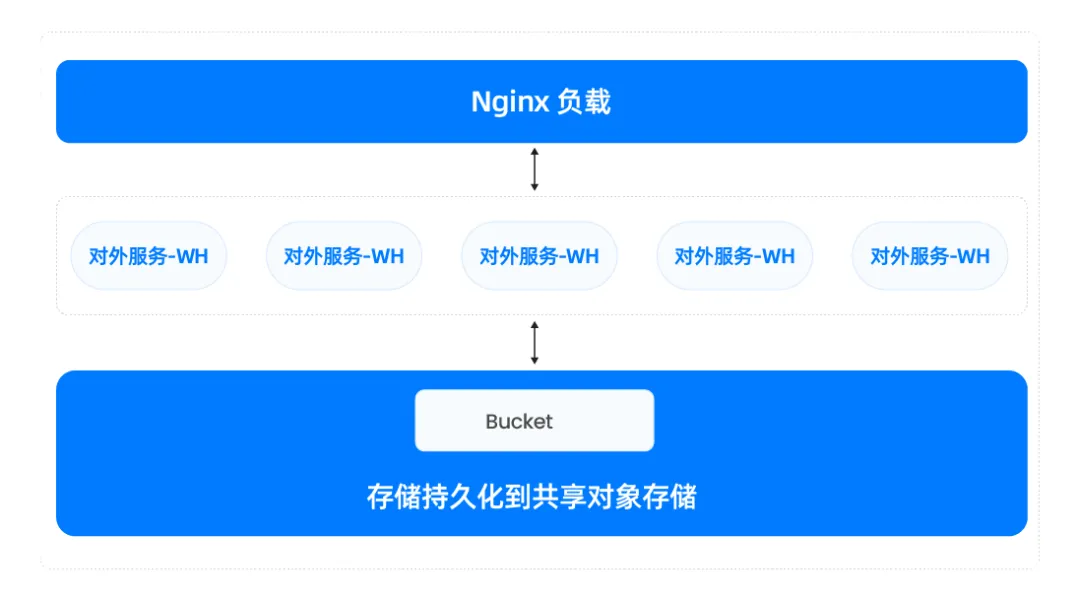
在实际业务中,许多项目需要面对高并发的需求。以上面的架构为例,当服务集群需要支持 2000 个并发请求,单集群又无法满足该并发能力时,可以采用”单业务多集群”模式进行扩展。例如,用户可以通过扩展多个同等规格的 Warehouse 来提升并发能力。在这种模式下,系统能够根据实际业务需求动态扩展资源。当业务量增加时自动扩展,当业务量下降时动态收缩。这种动态调整的过程对业务几乎没有感知,保证了系统的高效性与稳定性。
2.8 平台权限说明
Databend 基于 Role 的 RBAC 权限控制和基于 User 的权限制控制两种模式,对于大型项目平台,建议使用 RBAC 方式的权限控制。
2.9 平台资源隔离
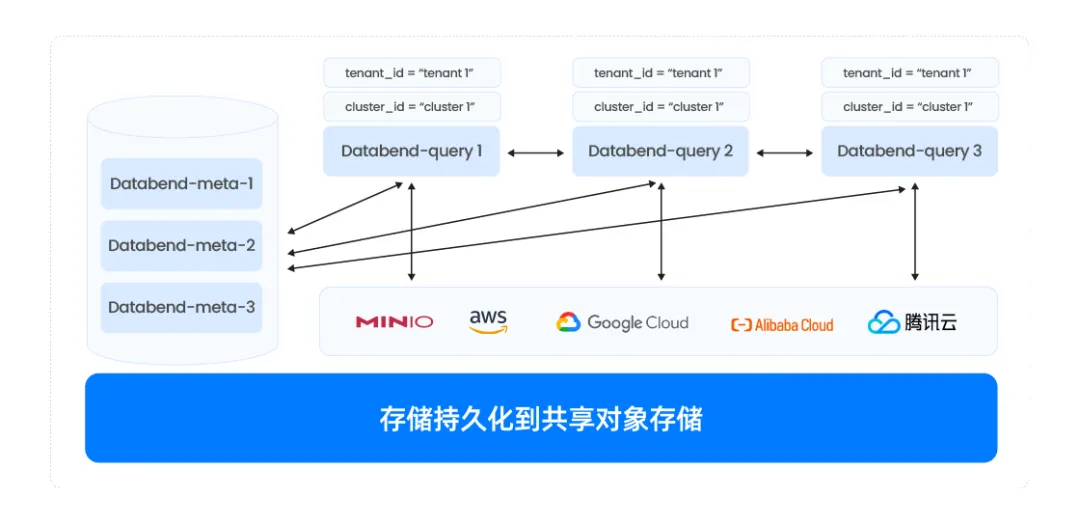
Databend 是一个存储分离架构,计算节点可以按业务拆分在独立的计算资上可以非常方便的实现物理的隔离及扩容。 也可以根据实际情况非常方便的对集群进行扩容。
开发人员使用
Databend 是一个通过 SQL 进行交互的数据平台,开发人员只需掌握 SQL 即可轻松使用 Databend,在 Databend 上开发数据平台就像平常开发管理后台一样简单。
- 不需要考虑分区, Databend 内置微分区实现;
- 不需要考虑索引, Databend 基于分区实现了 min/max , bloom index 索引;
- 不需要治理成大宽表, 支持多表 join ,子查询, CTE 等目前看到生产上最多的 join 超过 40 个表;
- 可以基于 SQL 处理替换大量 spark 数据清洗;
- 支持一份数据在多个租户及用户间共享;
- 有完善的用户权限系统;
- 支利用 python, js 做一些扩展表达: UDF, Remote UDF(Python)。
运维管理
Databend 设计的一个核心旨在简化大数据基础平台,Databend 运行态只有两个进程:
- databend-meta 用于元数据管理;
- databend-query 用于计算节点,通过配置标签决定其所属集群,目前也支持动态集群的创建及管理。
升级
基本是进程替换,重启即可
回滚
基本是进程替换,重启即可
启动
进程名 + 指定一个配置文件直接启动
高可用
数据本身:可以借助对象存储实现数据跨 IDC 复制;
databend-query: 无状态 databend-meta: 内置高可用部署,建议3-5个节点即可。
总结
Databend 是一个类似于 Snowflake 架构的存算分离的云原生数据平台,在国内落地中帮着用户节省大量的数据基础架构投入,大大简化了。 目前在国内已经替换过 CDP, Greenplum, 多种大数据平台。
案例一 某省级大数据交易所数据底座建设
大数据交易所原来使用传统大数据 Hadoop( HDFS, Hive, HBase ), Spark, S3, OLAP 产品等,构建了一个多产品解决方案。基础架构部分设计到的维护到的组件: HDFS, Hadoop Common, Hadoop Yarn, Hadoop MR, Hive. HBase, Yarn, Spark, Zookeeper, Kafka, Apache Ranger, OLAP 产品,每个产品可能又包含 3-5 个组件,平台复杂非常高。 平台挑战:
- 平台大量的数据同步任务,每天数据同步任务过万;
- 大量同步任务,经常因为异常停止,造成数据同步容易出现数据不一致;
- 需要用的核心表比较多,数据稽核压力比较大,稽核的资源经常无法满足平台需求;
- 多平台间数据同步任务占用了平台大量的资源;
- 平台技术上可用产品比较多,经常出现选择不合理的现象;
- HBase, Hive 都是 Schema 非严格约束,出现大量数据在入湖后本身就是错误,但无法溯源问题;
- Hive 和查询是分区级的,分区不合理或是没有分区的情况下任意的查询都是全表扫描,只用于跑批环境,不能用于 Adhoc 查询;
- HBase 只能基于 key 的请求,对于业务开发周期比较长,无法支撑业务的快速开发;
- 引入 OLAP 产品,希望直接在 OLAP 中对外服务,但发现大数据下数据量是海量的增长,OLAP 副本机制存储成本非常昂贵。 数据增长已经超越了 OLAP 承载能力。
- 平台运维复杂,很多产品更改一个参数需要大量的重启,损坏一块硬盘的修复成本都是天级的人员投入,平台中某些产品扩容几乎是需要惊动所有平台。
从传统大数据到 Databend 后的收益
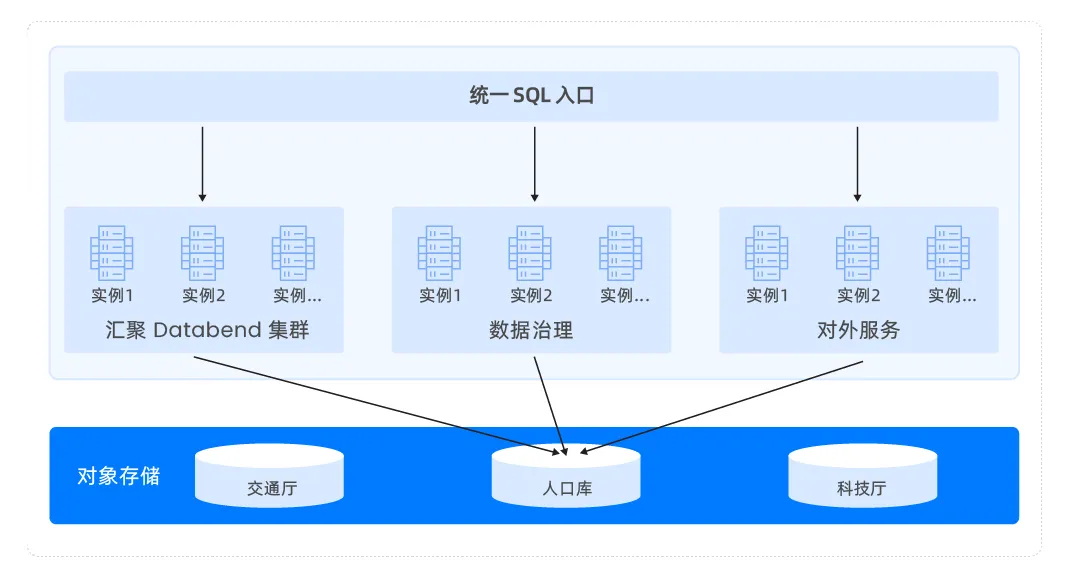
基于 Databend 构建的湖建的湖仓方案,实现了 Databend 统一SQL入口,实现了:
- 实现一份数据多业务集群同时访问,隔离计算的同时减少数据搬家;
- 同时 Databend 针对大数据交易所各生态厅多租户物理隔离问题定开发了内置数集市场,从根本上实现一份数据可以在多个租户间共享;
- 利用混闪的对象存储替代每台机器上的本地盘,实现存储分离后,可以针对存储和计算独立扩容,解决原来存储比空间要求比较大问题。另外磁盘故障更换对外无感知;
- 平台基础运维从原来多个产品、多个组件(超过 50 个)的情况,变为只有一个 Databend 产品,仅需两个进程(databend-meta,databend-query),可实现分钟级的平台计算资源扩容及收缩;
- 平台升级都可以秒级完成,对外基本无感知,大大提高了平台的稳定性;
- 数据入库环节,借助于 Databend 在公有云上打磨的方案,利用对象存储替换 Kafka 作为暂存区,简化了从外部 ETL 到内部 ELT 的流程,极大提升了数据接入能力;
- 利用 Databend 同一业务多集群架构实现湖仓平台直接对外服务,从根本上解决数据搬家;
- 借助于 Databend 云原生及存储分离的理念实现对资源的更加有效的管控,精细扩容及管理;
- 借助于 Databend 利用 Rust 研发,内存安全,完美的跑在各种信创 Linux 及 Arm CPU 下面。 基于 Databend 架构实现湖仓一体化,大大简化数据接入及使用,原来的周级任务排布到现在的基本 30 分钟左右可以实现一个业务的上线及对外服务。在省级数据只采一次项目中,实现1个月从0到1的省级民生项目建设。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式湖仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
👨💻 Databend Cloud:databend.cn
📖 Databend 文档:docs.databend.cn
💻 Wechat:Databend
✨ GitHub:github.com/databendlab…
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


