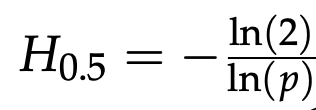很多人认为,Scaling Law 正在面临收益递减,因此继续扩大计算规模训练模型的做法正在被质疑。最近的观察给出了不一样的结论。研究发现,哪怕模型在「单步任务」上的准确率提升越来越慢,这些小小的进步叠加起来,也能让模型完成的任务长度实现「指数级增长」,而这一点可能在现实中更有经济价值。

如果继续扩大计算规模,边际收益却在递减,企业继续真金白银投入更大模型的训练是否还是一个合理的选择?大概从去年开始,AI 领域就在争论这一问题。
最近,有篇论文给出了一个有意思的观点:虽然 scaling law 显示 LLM 在测试损失等指标上存在收益递减,但模型在现实世界的价值往往源于一个智能体能够完成任务的长度。从这个角度来看, 更大的模型非但没有收益递减,反而能将单步准确率的微小提升复合放大,在任务完成长度上实现指数级跃升。

论文标题:The Illusion of Diminishing Returns: Measuring Long Horizon Execution in LLMs
论文链接:https://arxiv.org/pdf/2509.09677
代码链接:https://github.com/long-horizon-execution/measuring-execution
数据集链接:https://huggingface.co/datasets/arvindh75/Long-Horizon-Execution
这篇论文来自剑桥大学等机构。论文指出,长期以来,完成长程任务一直是深度学习的致命弱点。自动驾驶 demo 很炫酷,但要真正上路跑长途,用了十多年才实现。AI 能生成惊艳的图片,但拍一段连贯、一致的长视频至今仍是难题。现在企业都想要 AI 帮忙处理整个项目,而不只是回答零散问题。但这里有个核心疑问:我们该如何衡量 LLM 能可靠执行多少步的工作?
LLM 在简单长任务上的失败被认为是推理能力的根本缺陷。尽管 LLM 在复杂推理基准测试上有了巨大改进,依然有论文声称思考模型只是给出了「思考的幻觉」(arXiv:2506.06941),因为当任务变得更长时,它们最终会失败。
这些结果在社区中引发了很多争论。但本文作者认为,我们可以通过解耦推理或智能体任务中规划(planning)和执行(execution)的需求来解决这个问题。
规划涉及决定检索什么信息或使用什么工具以及使用顺序,而执行就是让规划变成现实。在《思考的幻觉》论文中,LLM 显然知道规划,因为它最初正确地执行了许多步骤。本文研究者认为,最终的失败在于执行 —— 随着任务变长,模型在执行规划时更容易犯错。 尽管人们非常关注 LLM 的规划能力,但执行仍然是一个研究不足的挑战。随着 LLM 开始用于长推理和智能体任务,这一方向变得越来越重要。
在这篇论文中,作者在受控环境中测量了 LLM 的长程执行能力。他们通过显式提供所需的知识和规划来隔离 LLM 的执行能力。通过控制轮数和每轮的步骤数(它们共同构成任务长度),他们揭示了关于 LLM 长程任务执行能力的见解:
1、Scaling 是否存在收益递减?
作者观察到,虽然单步准确率的提升幅度在减小,但准确率的微小提升可以复合放大,进而导致模型能够完成的任务长度呈指数级增长。
过去大家觉得,scaling 模型大小之所以会有用,是因为这会提高模型存储参数化知识或搜索规划的能力。
然而,作者在实验中发现, 在显式提供了所需的知识和规划后,scaling 模型大小仍能显著提高模型成功执行的轮次数量。 这说明 scaling 模型的价值不仅体现在能让模型记住更多知识或更会寻找问题解答上。
2、Self-Conditioning 效应
人们可能会认为,长任务中的失败仅仅是由于小而恒定的每步错误率不断累积造成的。然而,作者发现,随着任务的推进,每步错误率本身会上升。这与人类形成了对比,人类在执行任务时通常会通过练习而进步。
作者推测,由于模型训练的很大一部分是根据上下文预测最可能的下一个 token,因此 让模型以自身容易出错的历史为条件会增加未来出错的可能性 。他们通过控制展示给模型的历史中的错误率来对此进行测试。随着历史中的错误率升高,他们观察到后续步骤的准确率急剧下降,这验证了模型会进行 self-condition 设定。
作者表明,除了先前已发现的长上下文问题外,self-conditioning 设定还会导致模型在长程任务中的性能下降,而且与长上下文问题不同的是,这种性能下降并不会通过增大模型规模而得到缓解。
3、思考的影响
作者发现 近期的思考模型不会受到先前错误的影响 ,能够修正 self-conditioning 限制。此外,顺序测试时计算量(sequential test time compute)的显著提升了模型在单轮对话中可完成任务的长度。在没有思维链(CoT)的情况下,像 DeepSeek V3 这样的前沿大语言模型甚至连两步执行都无法完成,而其具备思考能力的版本 R1 则能执行 200 步,这凸显了行动前进行推理的重要性。
作者对前沿思考模型进行了基准测试,发现 GPT-5 的思考版本(代号 Horizon)能够执行超过 1000 步,远超紧随其后的竞争对手 —— 能执行 432 步的 Claude-4-Sonnet。
LLM 能力的「参差不齐」既令人着迷又让人困惑。与传统机器不同,大语言模型在执行重复性任务时更容易出现故障。因此,作者认为,长任务中的执行失败不应被误解为缺乏推理或规划能力。他们发现,通过扩大模型规模和增加顺序测试时间的计算量,模型长程执行能力会得到显著提升。如果一个模型能够完成的任务长度表明其经济价值,那么持续投入以增加计算量可能是值得的,即便短任务基准测试给人一种进展放缓的错觉。
这篇论文让很多人感觉深受启发,还有人提出我们应该设计更多针对模型执行深度方面的基准测试,以更好地衡量模型 scaling 所带来的收益。


以下是论文的详细内容。
论文方法详解
在论文中,作者详细介绍了他们的每一个结论是怎么得出来的。
虽然单步准确率收益递减,但 scaling 仍有价值
作者首先分析了模型的单步准确率与其预测范围长度之间的关系。为了得出数学关系,他们做出了两个类似于 LeCun (2023) 的简化假设。第一,他们假设模型的步准确率在任务过程中保持恒定。第二,他们假设模型不会自我修正,这意味着任何单一错误都会导致任务失败。他们仅在此次分析中做这样的假设,该分析能提供有用的直觉。他们的实证分析则更进一步,还研究了 LLM 在实际情况中如何在长程任务执行时不表现出稳定的步骤准确率,以及它们可能如何纠正错误。
命题 1:假设步骤准确率 p 恒定且无自校正,模型达到成功率 s 时的任务长度 H 由下式给出:

作者在图 2 中绘制了 s=0.5 时的这一增长函数。注意,当步骤准确率超过 70% 后,步骤准确率的微小提升会带来比指数级更快的任务长度改善。这一推导表明,即使在通常包含短任务的问答基准测试中,准确率的提升似乎放缓,但从数学角度而言,人们仍可期待在更长的任务上取得显著收益。
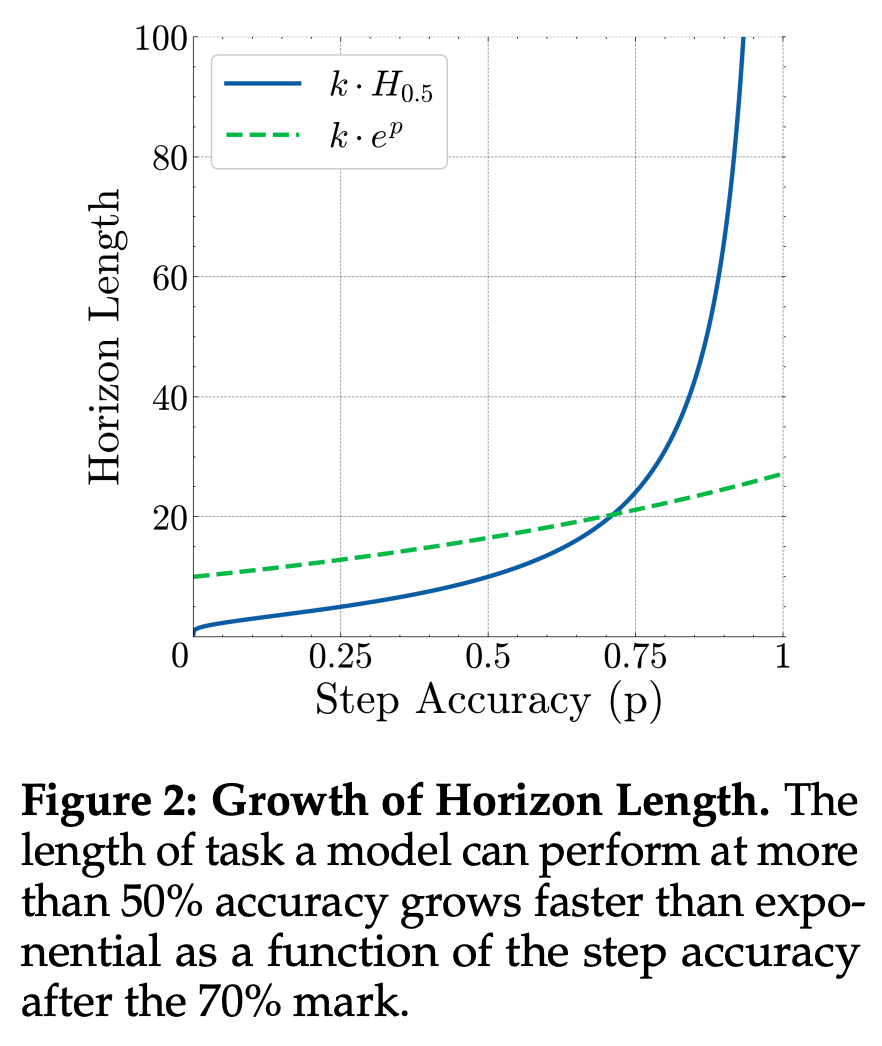
例如,在软件工程任务中,Kwa et al. (2025) 通过实证观察发现,前沿模型在 s=0.5 时的可完成任务长度正呈指数级增长,每 7 个月翻一番。利用上面的结果,作者在图 1 中展示出,即使在步骤精确度的回报递减机制下,任务长度的这种指数级增长也会发生。如果设定 s=0.5,就会得到