
本文的第一作者曾敏来自 vivo AI Lab,主要研究方向为大语言模型、强化学习、agent。
监督微调(SFT)和强化学习(RL)微调是大模型后训练常见的两种手段。通过强化学习微调大模型在众多 NLP 场景都取得了较好的进展,但是在文本分类场景,强化学习未取得较大的进展,其表现往往不如监督学习。
SFT 和 RL 在训练的过程中都存在各自的特点:SFT 直接对着答案「死记硬背」,简单且有效,收敛速度快,但是泛化能力不行。而 RL 通过探索来获得答案,泛化能力强。但强化学习只会一味地探索,而不学习答案,学习速度缓慢,可能出现长期无法得到收敛甚至最后出现训练不稳定的现象。
为了解决这些难题,最近, vivo AI Lab 算法团队 提出了一种新的大模型后训练框架 GTA,该方法可以综合发挥出 SFT 的优点和 RL 的优点,成功解决了文本分类场景中 RL 收敛速度慢的问题。该论文已被 AI 顶级学术会议之一的 EMNLP 2025 录用。

论文标题:GTA: Supervised-Guided Reinforcement Learning for Text Classification with Large Language Models
论文地址: https://arxiv.org/abs/2509.12108
作者邮箱:zengmin325@163.com / zengmin.ai@vivo.com
方法:把 SFT 和 RL 拼接成效率更高的后训练范式
论文提出了 Guess–Think–Answer(GTA)框架,将监督信号与强化学习整合到单阶段训练流程,以同时获得 SFT 的高效收敛与 RL 的性能上限。核心设计思路是把分类模型的输出分成三个阶段,并且把监督损失与强化学习的奖励机制结合起来训练这些阶段的不同部分。输出的三个阶段如下:

Guess
模型首先给出一个初始猜测,这一步用传统的交叉熵损失(cross-entropy loss)来计算初始猜测和标签的损失。这部分是基于监督学习,以快速给模型一个容易收敛的信号。
Think
在完成初始的猜测之后,模型接下来开始思考输入的问题与猜测的答案之间的关联,并且对答案进行进一步的分析。考虑猜测是正确的或者不是正确的,分析输入中的线索或特征等。这部分是为了让模型能够「反省」(reflect)猜测,从而在后面生成更好或修正的最终答案。
Answer
模型最终生成的答案,结合前两个阶段的信息生成。这个答案(以及整个 GTA 框架的格式结构)会由强化学习的奖励来引导优化。也就是说,不只是最终分类任务的正确性,还有中间思考阶段对最终答案的辅助或整体的结构格式也可能受到 RL 奖励值的影响。
最终总的损失是监督损失和强化学习损失 / 目标函数的共同作用。在猜测答案的引导下,强化学习探索答案的效率和收敛速度得到了进一步提升,从而提高性能的上限。

处理梯度冲突
为了防止不同优化目标可能带来的梯度冲突现象,该过程使用了特定位置的 loss mask 和梯度冲突检测。
loss mask : 在计算 guess 部分交叉熵损失的时候,对于 guess 部分以外的内容进行 mask,而计算 RL 损失的时候,对 guess 部分的内容进行 mask,通过这种方式使得监督信号和 RL 优化目标之间不会相互干扰。
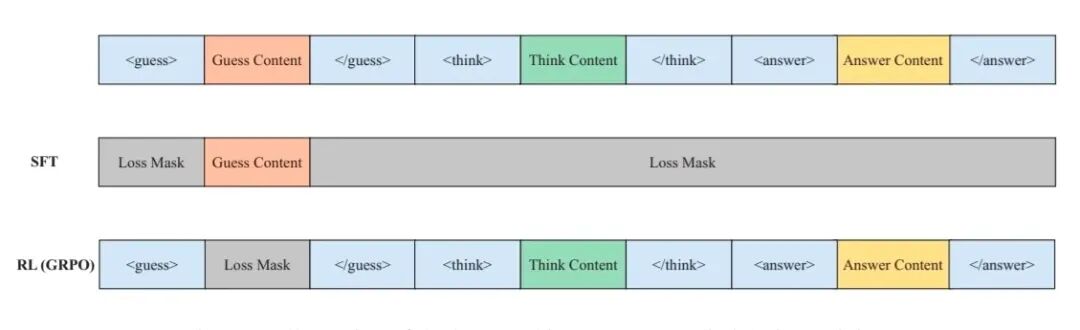
梯度冲突检测 : 作者参考现有的研究,通过反向传播时的梯度的余弦相似度来检测监督信号和 RL 信号的梯度是否发生冲突,这样可以更稳定地融合两种训练信号。
实验结果
作者在多台多机多卡的 L40s 上基于 qwen2.5(3B)、qwen3(3B)、Llama(3B)等三个尺寸相对较小的模型上进行了分布式训练。选择了四个常见的文本分类数据集,分别是 SST-5、Amazon、Emotion、BBC News 数据集,每个数据集都包含了多个类别,它们覆盖的领域主要包括情感分析、商品评价、情绪 / 情感类别识别,以及新闻 / 话题分类等。
如图所示,作者在实验过程中与 GRPO、SFT 进行了对比,从实验结果可以发现 GRPO 在分类任务上的效果并不理想,而 GTA 在分类任务展示了比 SFT 和 GRPO 更好的性能。

作者跟踪训练过程中的奖励值变化曲线和在测试集任务上的准确性评估曲线,来观察训练过程中的收敛速度。从图中可以发现,训练到 500–1000 step 即超过 GRPO(step 的计算包含了重要性采样数据重复利用的次数),即使将训练时长继续延长至 10000 step,GRPO 仍未追上 GTA。这表明 GTA 在 guess 部分的监督信号的引导下,收敛速度远高于 GRPO。

此外,作者也验证了在分类任务上,带思考过程和不带思考过程的准确率。如图所示,作者在这些数据集上进行了测试,带有思考过程的推理可以获得更高的准确率。相比 SFT,作者提出的 GTA 方法,无需额外的人工标注推理过程,即可在训练过程中自发地引入思考。

作者在推理的时候发现两个现象:尽管猜测答案可以加快 RL 的收敛速度,但是模型不会盲目选择猜测的答案作为最终答案。从图中 case A 可以看到,模型首先输出了一个错误的猜测,然后在思考过程中基于猜测的答案和已有的答案进行分析和判断,最终成功地得出了正确答案。而从 case B 中可以看到,当生成了一个标签列表以外的猜测答案时,模型在思考过程中会纠正这个问题,并得出最终的正确答案。

后续计划
本文仅在文本分类任务上进行了验证,从原理上来分析,该方法不仅适用于文本分类任务,还有可能适用于更多的 NLP 场景,作者计划未来探索更多的场景。此外,结合监督微调和强化学习微调可能带来更大的显存开销,作者在本文主要选择小模型上进行实验,未来将会探索更大的模型。
未来展望
SFT 和 RL 的结合正在受到更多的关注,近期的讨论都集中在如何把两种范式的优势合并,以获得更好的性能(如通义 CHORD 和上海人工智能实验室的 LUFFY)。GTA 是在后训练方向上的一种新的实践。SFT 和 RL 的结合有望成为未来一种新的后训练范式。
]article_adlist–>
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

