
<p><span><span><span>在近日举行的具身智能技术专题分享会上,北京人形机器人创新中心的研究员伍堃博士带来了一场内容丰富、干货满满的技术分享。作为来自雪城大学的PhD,伍博士专注于具身智能领域的研究,包括强化学习、模仿学习以及大规模数据集构建和</span>VLA 模型训练。本次分享系统性地介绍了团队从数据采集到模型训练的全链路创新工作。
突破数据瓶颈:构建大规模多模态数据集
伍博士首先指出当前具身智能领域面临的核心挑战——数据局限性。与互联网级别的海量文本和图像数据相比,机器人操作数据的规模要小得多,通常只有几万条轨迹,且采集成本高昂。现有的开源数据集以国外来源为主,如OpenX系列,虽然整合了多个实验室的资源,但存在标准不统一、任务简单、场景单一等问题,且大多局限于单臂机器人操作,与人类双手协同操作的灵活性相去甚远。
针对这些痛点,北京人形机器人创新中心联合北京大学和北京智源研究院推出了RoboMIND数据集。该数据集目前包含10万条高质量轨迹,涵盖479个多样化任务和96类物品,涉及单臂机械臂(如Franka、UR)、双臂机器人以及人形机器人(如天工机器人)等多种本体,末端执行器包括夹爪和灵巧手两种类型。
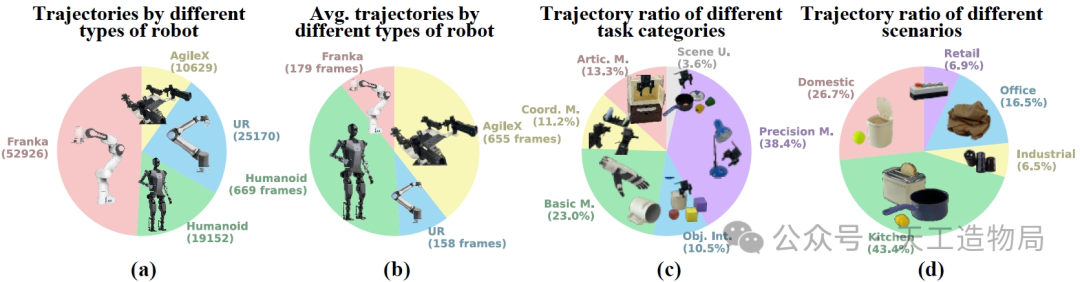
值得注意的是,该数据集具有显著的多样性特征:不仅覆盖厨房、家居、商超、办公室和工业五大场景,还包含抓取放置、精细操作、铰链物品操作、双臂协同等不同难度的任务类型。团队还提供了细粒度的标注信息,采用大模型自动划分任务片段并生成语言指令,再经由人工质检修正,为VLA训练提供了宝贵的数据资产。
创新技术方案:三阶段训练范式攻克跨本体难题
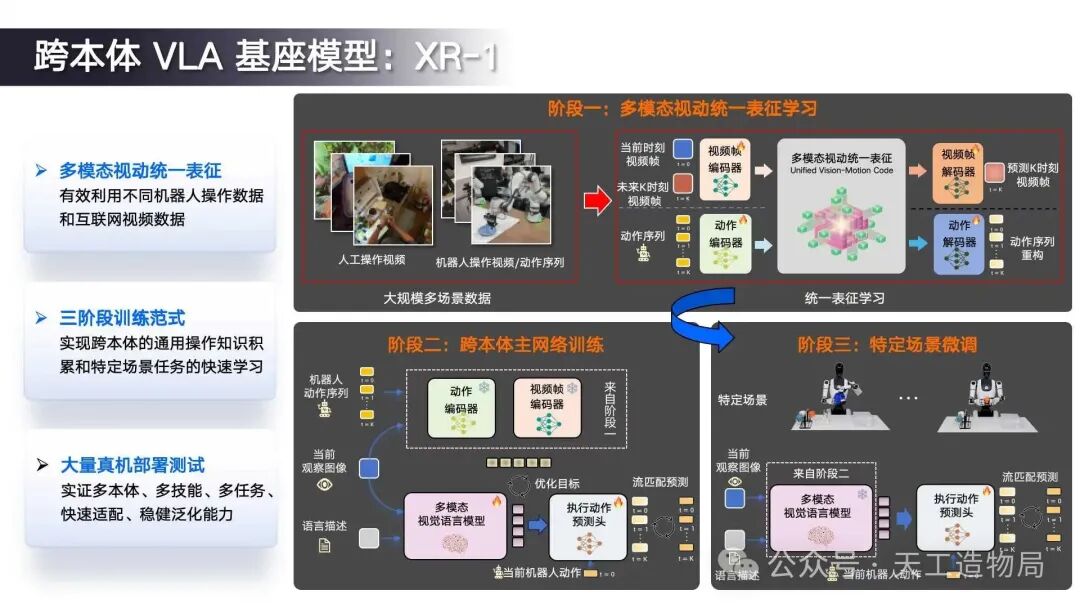
基于高质量数据集,团队提出了创新的XR-1跨本体VLA模型。伍博士详细介绍了其核心的三阶段训练范式,该方案有效解决了动作预测困难和泛化能力弱等关键问题。
第一阶段采用多模态视动统一表征学习,通过双流VAE自编码器将视觉动态特征和机器人动作特征映射到同一隐空间。视频分支输入当前帧和未来帧,学习视觉动态表征;动作分支输入连续的动作序列,学习机器人运动模式。这种自监督学习方式能够统一不同机器人操作数据与人类操作视频的表征,显著提升特征的平滑度和泛化性能。
第二阶段接入具体VLA模型实例(如pi0或轻量级Switch VLA),利用大规模机器人数据进行预训练。在此阶段,模型同时优化两个目标:阶段一获得的隐变量辅助损失和原始数据集的底层动作预测损失,从而更好地利用大规模数据提升模型性能。
第三阶段则针对特定机器人或任务进行微调,进一步优化模型在具体应用场景中的表现。
实验验证:显著提升多项性能指标
在实验验证方面,XR-1模型表现出色。团队在天工、Franka和UR三种机器人平台上各选取5个任务进行测试,结果显示相比现有主流VLA模型,XR-1平均带来50-63%的相对性能提升。
特别令人印象深刻的是模型的少样本迁移能力。在每个任务仅使用20条样本的情况下进行多任务训练,XR-1的成功率显著高于单任务训练的ACT、DP等模型,这得益于大规模数据预训练和统一表征学习带来的强大泛化能力和快速学习能力。
模型在泛化性测试中也表现优异:在背景干扰(不同桌布)、物体位置变化、新增干扰物等多种挑战性场景下,都能保持稳定的任务完成能力。这些实验充分验证了团队提出的方法在跨本体、跨任务、跨场景方面的优势。

未来展望:开源计划与发展路线图
伍堃博士透露,团队计划在2024年Q4开源RoboMIND v2版本,这将是一个包含约30万条轨迹的大规模数据集,新增移动双臂操作、触觉信息等丰富模态数据,并配套提供数字孪生仿真资产。
在应用前景方面,伍博士分享了具身智能技术发展的三阶段路线图:第一阶段聚焦结构化/半结构化工业与危险场景,支持巡检、搬运、分拣等任务;第二阶段拓展到商业服务场景,如酒店收纳整理等应用;最终目标是进入家庭场景,这需要模型具备极强的泛化能力以适应多样化的环境。
在数据场地建设方面,创新中心正在建设超过6000平方米的真实场景数据基地,涵盖10类以上场景、100余台各类机械臂,年数据生产能力达千万条级别。目前已与30余家客户开展合作,共同推动具身智能技术的落地应用。
本次分享会全面展示了北京人形机器人创新中心在具身智能领域从数据采集到模型训练的全链条技术创新。随着数据集的不断丰富和模型的持续优化,具身智能技术有望在更多场景中实现规模化应用。
资源下载
- RoboMIND数据集下载: https://huggingface.co/datasets/x-humanoid-robomind/RoboMIND
- 仿真资产ArtVIP下载: https://huggingface.co/datasets/x-humanoid-robomind/ArtVIP
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


