<!-- 相关专题top end-->
<!-- 期货推广begin -->
<!-- 期货推广end -->
<!-- 秒拍begin -->
<!-- 秒拍end -->
<!-- 视频播放器start -->
<!-- 视频播放器end -->
<!-- 行情图begin -->
<!-- 行情图end -->
<p>(来源:<span id="stock_sh601375"><a href="https://finance.sina.com.cn/realstock/company/sh601375/nc.shtml" class="keyword" target="_blank" data-sudaclick="content_marketkeywords_p">中原证券</a></span>研究所)
]article_adlist–>
投资要点:
DeepSeek在年初发布了R1以后,受到了各界普遍关注。后续来看,DeepSeek并没有如期发布更先进的模型R2,而是在进行更多小版本的更新换代。结合每个阶段的发展重点,我们将其划分为3个主要的发展阶段。
阶段一:性能提升。 DeepSeek在3月推出的V3-0324和5月推出的R1-0528,通过后训练实现了模型能力的提升,弥补了和头部模型之间的差距。
阶段二:实现混合推理架构、Agent能力提升、与国产芯片协同优化。 从8月以后,DeepSeek也顺应了海外混合推理架构和Agent能力提升的大趋势,推出了V3.1和V3.1-Terminus,Agent能力有了较大提升,思考效率也有提升。V3.1采用UE8M0 FP8缩放格式训练,针对即将发布的下一代国产芯片设计,实现国产大模型和国产芯片协同设计的优化,对国产化芯片的应用起到积极的推动作用。
阶段三:提效降价,国产适配加速。 9月发布的V3.2-Exp,基于V3.1-Terminus构建,引入了新的注意力机制DSA,在保持模型性能的稳定的同时,在训练推理效率方面有了较大的提升,带来了模型较大幅度的降价。考虑到当前大模型之间能力差距在缩小,成本的下降意味着模型具有更好的性价比和可推广性,也将促进应用端实现更多功能的落地。DeepSeek新兴AI编程语言选用TileLang这个新兴AI编程语言,可以实现对不同硬件平台的支撑,极大地改善了国产卡目前所面对的CUDA带来的生态壁垒问题,为国产大模型软硬件生态建立起到了极大的推动作用。发布的当天,国产芯片华为昇腾和寒武纪 同步宣布完成对V3.2-Exp的零日适配,成为国产AI产业从“单点突破”迈向“系统协同”的又一个标志性事件。
风险提示: 国际形势变化。

报告正文
DeepSeek在年初发布了R1以后,受到了各界普遍关注。后续来看,DeepSeek并没有如期发布更先进的模型R2,而是在进行更多小版本的更新换代。结合每个阶段的发展重点,我们将其划分为3个主要的发展阶段。
1. 阶段一:性能提升
DeepSeek在3月推出的V3-0324和5月推出的R1-0528,还是以基础模型DeepSeek-V3-Base为基座,通过后训练实现了模型能力的提升,弥补了和头部模型之间的差距。
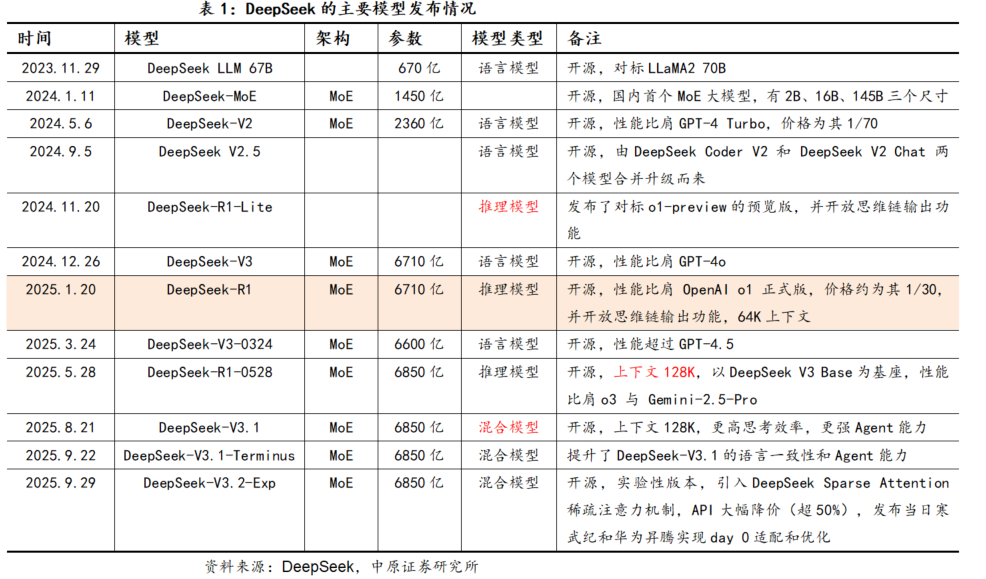
2. 阶段二:实现混合推理架构、Agent能力提升、与国产芯片协同优化
从8月以后,DeepSeek也顺应了海外混合推理架构和Agent能力提升的大趋势,推出了V3.1和V3.1-Terminus。这次升级中,DeepSeek的基座模型DeepSeek-V3.1-Base在DeepSeek-V3-Base基础上做了大规模外扩训练,Agent能力有了较大提升,思考效率也有提升。
8月21日,Deep在发布V3.1的同时,也宣布了在国产芯片适配方面的新进展。 V3.1采用UE8M0 FP8缩放格式训练,为对即将发布的下一代国产芯片设计。
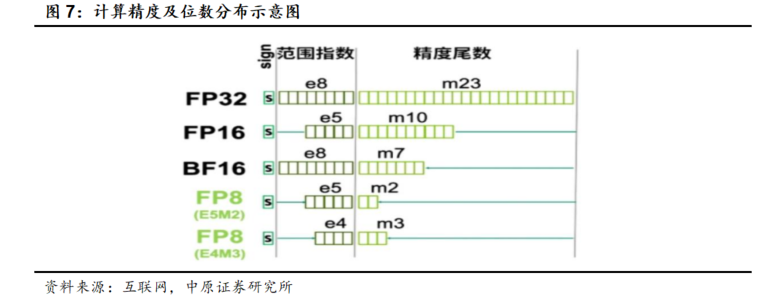
此前,国内芯片企业仅有较少支持了FP8数据格式,多数芯片仅能支持FP16格式。FP8虽然可以提升计算速度和降低存储需求,但是由于计算精度不高,容易损失数据信息,所以V3以前的大模型训练中多会选用BF16或FP32/TF32精度进行数据计算和存储。DeepSeek是首个在开源超大规模大模型中成功落地FP8混合精度训练的公司,推动了FP8技术的规模化应用,也极大地提升了市场对H20等支持FP8格式芯片的需求。
UE8M0 FP8是对FP8格式的深度优化。该格式仅表示非负数(U代表Unisigned,无符号),尾数位为0(M0,尾数位为0),8个比特全部用来表示指数(E8,指数位占8位),Scale通过对数据进行分块缩放,保持其能够在FP8表示的范围内。UE8M0 FP8作为FP8格式的变体,通过减少数据存储和传输的损耗,能最大限度利用硬件计算能力,弥补国产芯片在HBM等高速内存带宽方面的不足,从而 实现国产大模型和国产芯片协同设计的优化,对于国产化芯片的应用起到积极的推动作用。
3. 阶段三:提效降价,国产适配加速
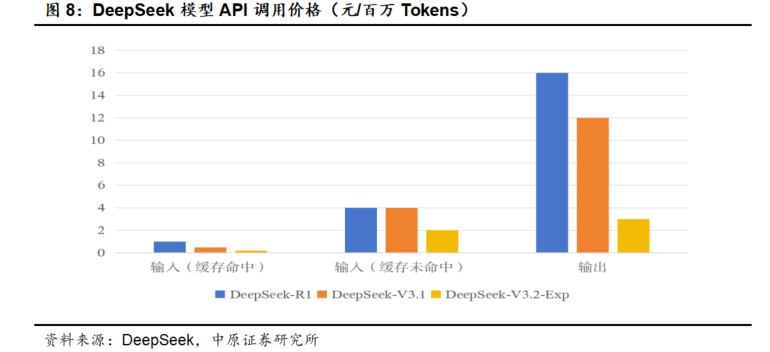
9月发布的V3.2-Exp,基于V3.1-Terminus构建,引入了新的注意力机制DSA,在保持模型性能的稳定的同时,在训练推理效率方面有了较大的提升,带来了模型较大幅度的降价。
对比R1来看,V3.2-Exp的输入缓存命中时价格为R1的20%(0.2元/百万Tokens),输入缓存未命中时价格为R1的50%(2元/百万Tokens),输出价格为R1的19%(3元/百万Tokens),降幅最为明显。
考虑到当前大模型之间能力差距在缩小,成本的下降意味着模型具有更好的性价比和可推广性,也将促进应用端实现更多功能的落地。
在国产适配方面进度明显加快。在V3.2-Exp发布的当天,国产芯片华为昇腾和寒武纪同步宣布完成对V3.2-Exp的零日适配。这是继V3.1采用UE8M0 FP8实现国产大模型和芯片协同设计的优化以后, 国产AI产业从“单点突破”迈向“系统协同”的又一个标志性事件。
同时值得注意的是DeepSeek还同时开源TileLang和CUDA两个版本的算子。TileLang是一种采用类Python语法的领域专用语言(DSL),于2025年1月由北大计算机学院杨智团队开源,旨在实现硬件调度与开发者算法逻辑的解耦,从而降低GPU编程的技术门槛,同时通过分层设计来实现不同技术背景开发者,从简单上手到深度优化的不同需求。由于TileLang可以实现对不同硬件平台的支撑,极大地改善了国产卡目前所面对的CUDA带来的生态壁垒问题。
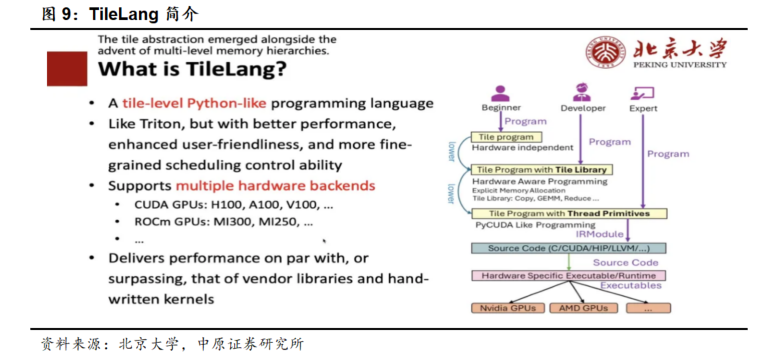
DeepSeek选用TileLang这个新兴AI编程语言,再次体现了其强大的创新精神,同时为国产大模型软硬件生态建立起到了极大的推动作用。
4. 风险提示
国际形势变化。
]article_adlist–>
证券分析师承诺:
本报告署名分析师具有中国证券业协会授予的证券分析师执业资格,本人任职符合监管机构相关合规要求。本人基于认真审慎的职业态度、专业严谨的研究方法与分析逻辑,独立、客观的制作本报告。本报告准确的反映了本人的研究观点,本人对报告内容和观点负责,保证报告信息来源合法合规。
重要声明:
本报告中的信息均来源于已公开的资料,本公司对这些信息的准确性及完整性不作任何保证,也不保证所含的信息不会发生任何变更。本报告中的推测、预测、评估、建议均为报告发布日的判断,本报告中的证券或投资标的价格、价值及投资带来的收益可能会波动,过往的业绩表现也不应当作为未来证券或投资标的表现的依据和担保。报告中的信息或所表达的意见并不构成所述证券买卖的出价或征价。本报告所含观点和建议并未考虑投资者的具体投资目标、财务状况以及特殊需求,任何时候不应视为对特定投资者关于特定证券或投资标的的推荐。
本报告具有专业性,仅供专业投资者和合格投资者参考。根据《证券期货投资者适当性管理办法》相关规定,本报告作为资讯类服务属于低风险(R1)等级,普通投资者应在投资顾问指导下谨慎使用。
本报告版权归本公司所有,未经本公司书面授权,任何机构、个人不得刊载、转发本报告或本报告任何部分,不得以任何侵犯本公司版权的其他方式使用。未经授权的刊载、转发,本公司不承担任何刊载、转发责任。获得本公司书面授权的刊载、转发、引用,须在本公司允许的范围内使用,并注明报告出处、发布人、发布日期,提示使用本报告的风险。
若本公司客户(以下简称“该客户”)向第三方发送本报告,则由该客户独自为其发送行为负责,提醒通过该种途径获得本报告的投资者注意,本公司不对通过该种途径获得本报告所引起的任何损失承担任何责任。
]article_adlist–>


