
生成式 AI 的浪潮赋予了机器无尽的创造力,我们已亲眼见证它在文字与图像世界 “点石成金” 的魔力。然而,当这股浪潮涌向更复杂的三维空间,挑战也随之升级。过去的 3D 生成 AI 如孩童堆积木,成果粗糙模糊;如今,它渴望成长为一名 “数字建筑师”,去建造结构精巧、可被编辑改造的虚拟世界。
为了实现这一目标,一种流行的方法是让 AI 学习定义 “内外” 的边界来隐式地塑造物体。这种方法虽能生成外形平滑的物体,但其成果好比一座 “固化” 的雕塑 —— 一个不可分割的静态外壳,很难像玩乐高一样拆解重组。对于艺术家而言,这座雕塑的表面覆盖着一张杂乱的 “渔网”(无序三角网格),而非规整的 “布料”,任何微调都如同对整片网进行重新编织,极其困难,难以融入专业的创作流程。
受到 以上启 发 ,我们不再满足于生成杂乱的网格,而是渴望一种更原生、更结构化、更符合设计师与工程师直觉的表征方式 —— 代码。如何让模型像程序员一样,用逻辑和参数构建三维世界?如何让生成的物体不仅形似,更能被理解、被编辑、被二次创作?带着这些思考,我们团队推出了 M eshC oder 。它是一条探索 3D 程序化生成的新路径,其核心思想是训练一个强大的多模态模型,直接将三维输入(如点云)翻译成结构化、可执行的 Blender Python 代码。
我们工作的亮点在于,MeshCoder 生成的不是一个 “死” 的模型,而是一套 “活” 的程序。它具有以下鲜明优势:
1. 分零部件生成 :如下视频所示,MeshCoder 能理解物体的语义结构,将椅子、桌子等自动分解为椅背、椅腿、桌面等独立部件进行代码生成,逻辑清晰。
2. 拓 扑良好的四 边面 :如下图所示,MeshCoder 生成的代码直接构建出高质量的四边面(Quad Mesh)网格,这对于后续的编辑,展 UV 上材质至关重要。

下图是使用传统常用的 Marching Cube 算法从分界面中提取网格的结果,可以看到得到的是杂乱无序的三角面网格。与这些网格相比,上图中 MeshCoder 得到的 Mesh 具有规整的四边面。

3. 易于理解和编辑 :如下图所示,MeshCoder 生成的 Python 代码具备高可读性,用户可以通过修改参数(如尺寸、位置)或函数调用,轻松实现对三维模型的编辑。
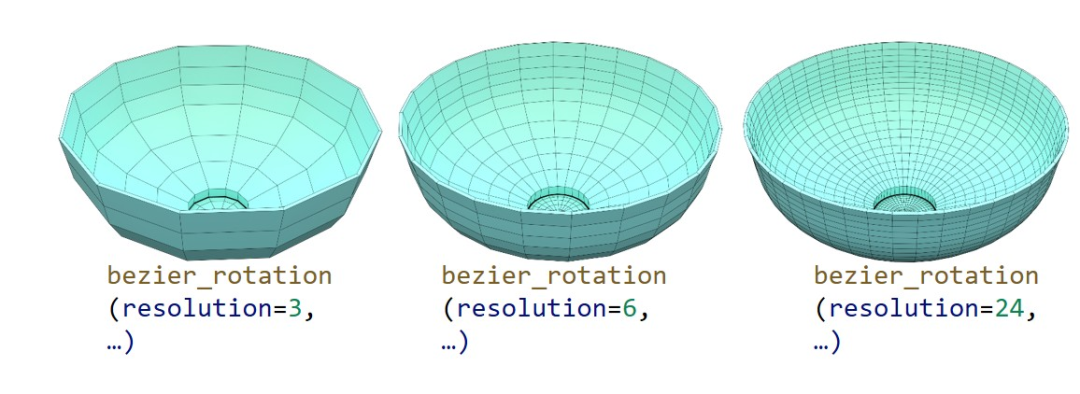
4. 可控的网格密度 :如下图所示,通过调整代码中的分辨率等参数,用户可以自由控制生成网格的精细程度,在细节与性能之间找到平衡。
我们相信,这只是探索的开始。我们选择将 MeshCoder 开源,衷心期待它能引发更多有价值的讨论,并希望能与社区的研究者一起,继续推动三维生成技术的演进。

论文链接:https://huggingface.co/papers/2508.14879
项目网站:https://daibingquan.github.io/MeshCoder
GitHub 链接:https://github.com/InternRobotics/MeshCoder
模型链接:https://huggingface.co/InternRobotics/MeshCoder
数据集链接:https://huggingface.co/datasets/InternRobotics/MeshCoderDataset
我们是如何做到的?
MeshCoder 的实现路径清晰,其核心是一个强大的代码库与一套创新的数据构建流程。
第一步:构建零部件数据集并训练零件代码推理模型
万丈高楼平地起,我们首先需要让模型具备理解基础几何的能力。
专属工具:开发 Blender Python API
MeshCoder 的基石是我们为 Blender 定制开发的一套简洁且功能强大的 Python API。(Blender,作为一款开源且功能强大的三维计算机图形软件,为我们提供了坚实的程序化建模环境。)这套 API 封装了从创建基础图元到执行复杂布尔运算、阵列等一系列高级建模操作,让用简洁的代码构建复杂几何体成为可能。
海量数据:构建千万 级零部件数据 集
我们利用这套强大的 API,通过参数化随机采样的方式,程序化地生成了海量的、由简单到复杂的几何零部件,最终构建了一个千万级别、图文并茂的 “零部件代码” 配对数据集。下图是我们零部件数据集的一些样例。

模型设计与训练:从点云到代 码的初代模型
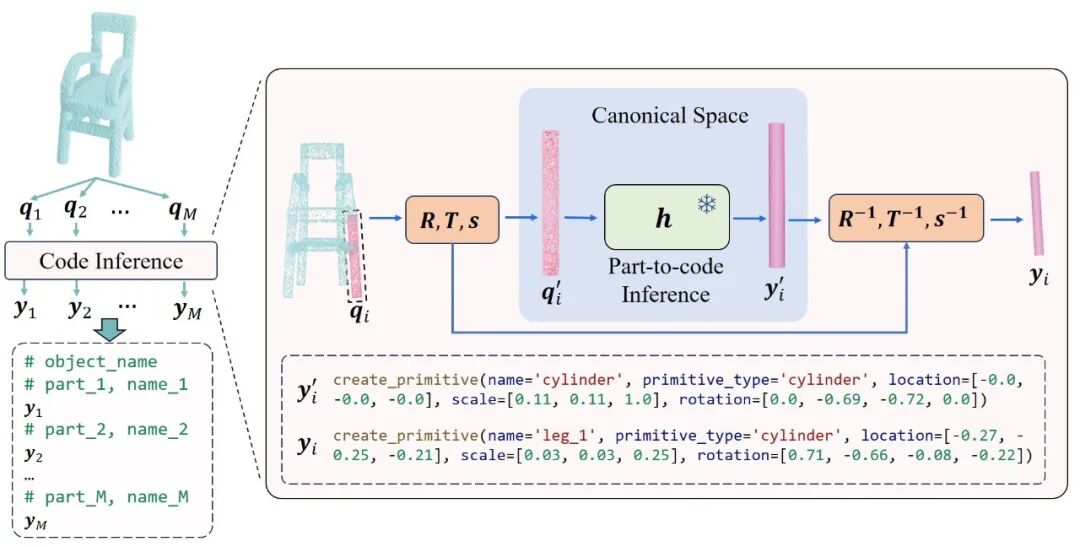
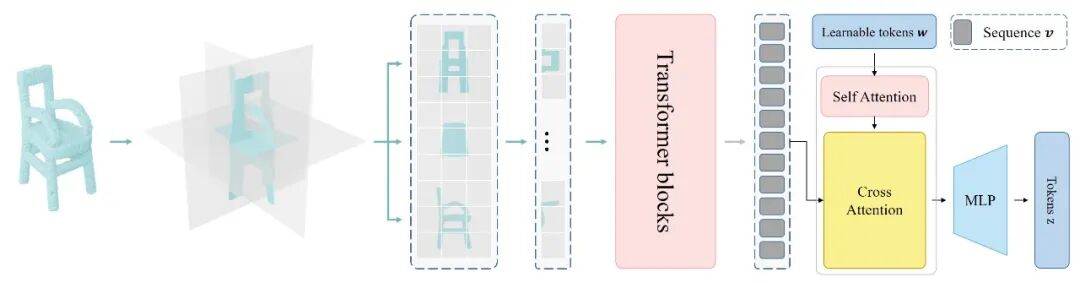
基于这个庞大的零部件数据集,我们训练了一个强大的零件代码推理模型。该模型的核心设计在于:首先通过一个形状编码器,从输入的零部件点云中抽取出固定长度的词元(Token)特征;然后,一个大型语言模型(LLM)会接收这些特征,并自回归地生成能够重建该零部件的结构化代码。此步骤完成后,我们的初代模型就具备了将任意单个部件的点云精准翻译为 Blender 代码的能力。模型的架构可以参见第二步的图片。
第二步:构建物体数据集并训练最终物体代码推理模型
在初代模型掌握了 “识部件、懂代码” 的技能后,我们利用它以及规则来 “教会” 最终模型如何理解和搭建完整的复杂物体。
数据升级: 构建百万级 “物体 – 代码 ” 数据集
高质量的数据是训练强大模型的燃料。我们首先利用 Infinigen Indoor 生成模型,生成了一个百万级别的、可被拆分为零部件的复杂物体数据集。接着,我们 调用第一步训练好的初代模型 ,为每一个物体的每一个零部件自动生成其对应的代码。最后,通过精心设计的规则,我们将所有部件的代码与其在物体中的原始位置信息相结合,“组装” 成一段完整的、带有丰富语义信息的物体级代码。下图以椅子为例展示了这个过程。
最终训练:得到可重建物体的 MeshCoder
在这个百万规模的 “物体 – 代码” 大规模数据集上,我们训练出了最终的 MeshCoder 模型。通过学习这些完整的物体代码,MeshCoder 不仅继承了对基础部件的理解,更学会了物体不同部件间的空间与语义关系,使其最终具备了从整体上理解复杂物体并生成完整、结构化代码的强大能力。下图是 MeshCoder 从物体点云推理出代码的 pipeline。
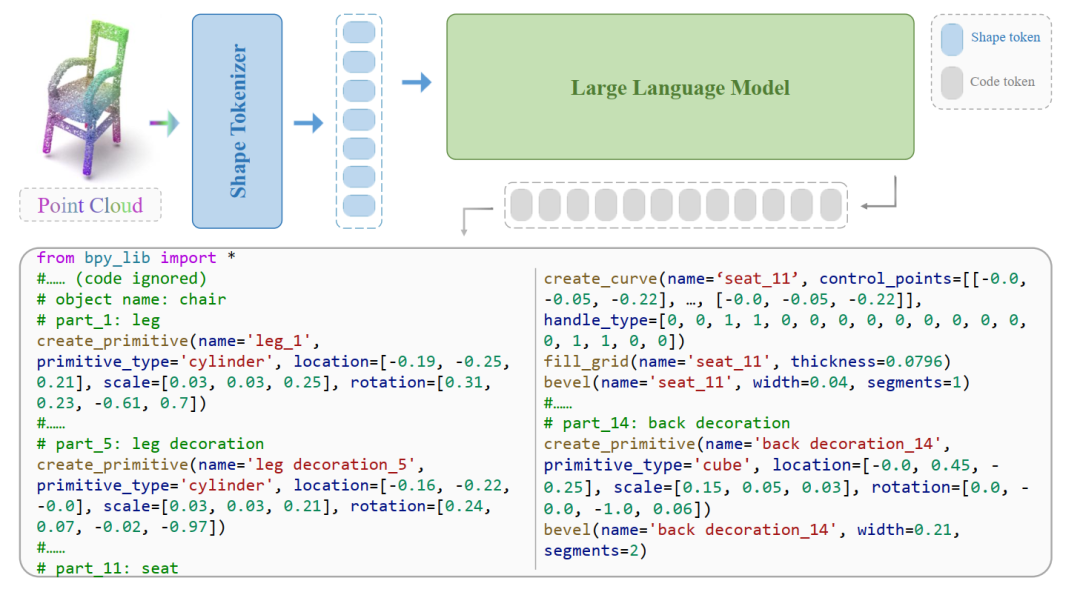
下图是形状编码器 (Shape Tokenizer) 的网络结构。
强大的重建、编辑与理解能力
MeshCoder 的真正实力,不仅在于创新的理念,更在于坚实的实验数据。我们在多个维度上对其进行了严格的测试,结果证明了其卓越的性能。
一、高保真重建:精度大幅领先
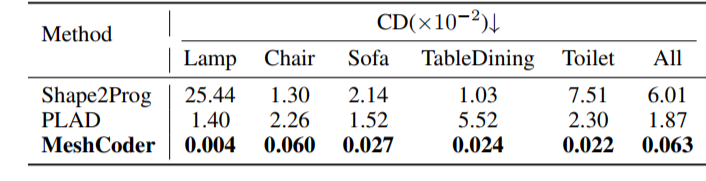
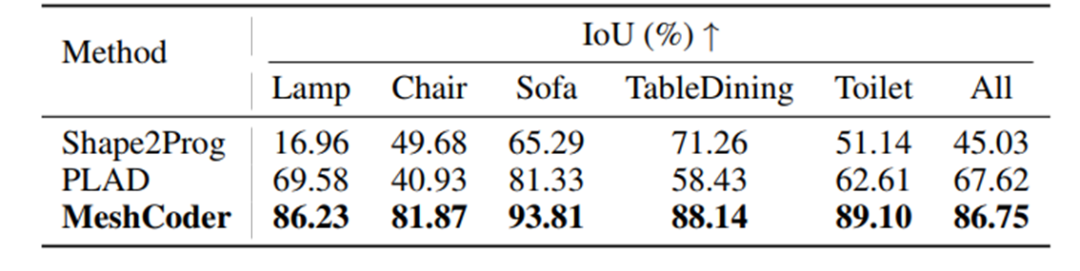
我们将 MeshCoder 与当前的两种 Shape-to-Code 方法(Shape2Prog 和 PLAD)在 Infinigen Indoor 数据集上进行了比较。该数据集涵盖了从椅子、台灯到浴缸、马桶等 41 个常见室内物体类别,极具挑战性。
在精度上超越了基准方法 :我们使用 “Chamfer 距离 (CD)” 和 “交并比 (IoU)” 这两个核心指标来衡量重建的准确度。数据显示,MeshCoder 在几乎所有类别上都取得了数量级的领先。例如,在 “椅子 (Chair)” 类别中,我们的 CD 误差仅为 0.060 (越小越好),远低于 PLAD 的 2.26 和 Shape2Prog 的 1.30。而在整体平均 IoU(越大越好)上,MeshCoder 达到了的 86.75% ,而两个对比方法分别只有 67.62% 和 45.03%。
能够还原复杂结构 :从以下对比图可以直观地看到,对于门上的扇叶、窗户的格栅、沙发的扶手等复杂结构,传统方法往往会产生模糊、粘连甚至错误的几何形状,而 MeshCoder 能够精准地重建出每一个独立的部件和清晰的边界,效果与原始三维模型(Ground Truth)高度一致。


二、代码化编辑:打开创造力的窗口
代码化编辑是 MeshCoder 最重要的能力之一。我们将 3D 模型变成了可读、可改的程序代码,赋予了用户前所未有的控制自由。这不仅仅是简单的参数调整,而是涵盖了几何与拓扑的深度编辑:
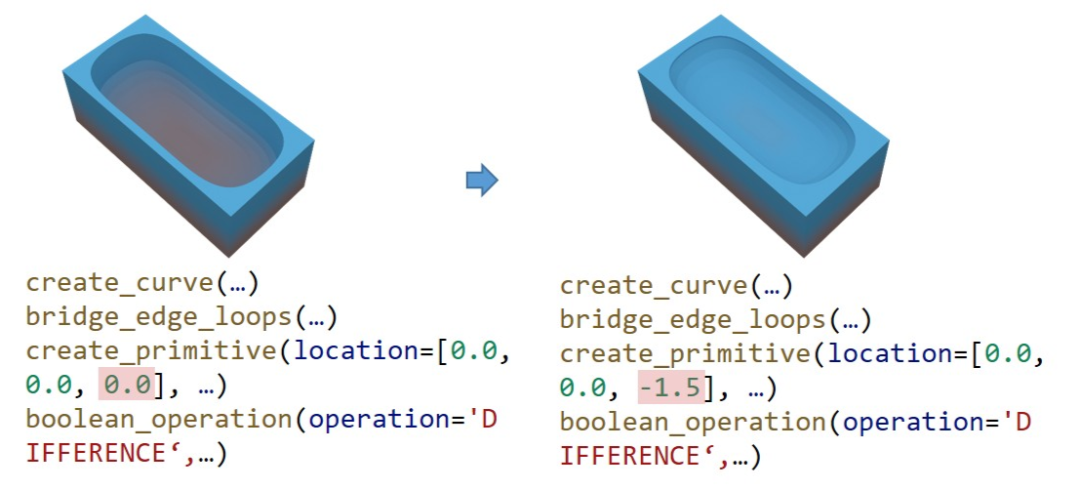
几何编辑(改变形状) :想象一下,想把一张方桌变成圆桌,您需要做什么?在传统流程中,这可能需要复杂的建模操作。而在 MeshCoder 中,如下图所示,您只需在生成的代码里,将创建桌面的函数 create_primitive 的 primitive_type 参数从 ‘cube’ 改为 ‘cylinder’ 即可。

拓扑编辑(改变布线) :需要一个更精细或更粗糙的模型?没问题。通过修改代码中的 resolution 参数,您可以轻松控制生成网格的密度。从低分辨率的快速原型,到高分辨率的精细模型,如下图所示, 通过改动一个数字的方式,我们就可以让 3D 资产适应不同场景的需求,在性能与精度之间找到平衡。

三、赋能三维理解:利于大模型理解形状
MeshCoder 生成的代码不仅仅是指令,它本身就是一种富含语义的结构化知识。当我们将这些代码以及对使用部 Blender Python API 的文档 “喂” 给像 GPT-4 这样的大型语言模型时,奇妙的事情发生了:
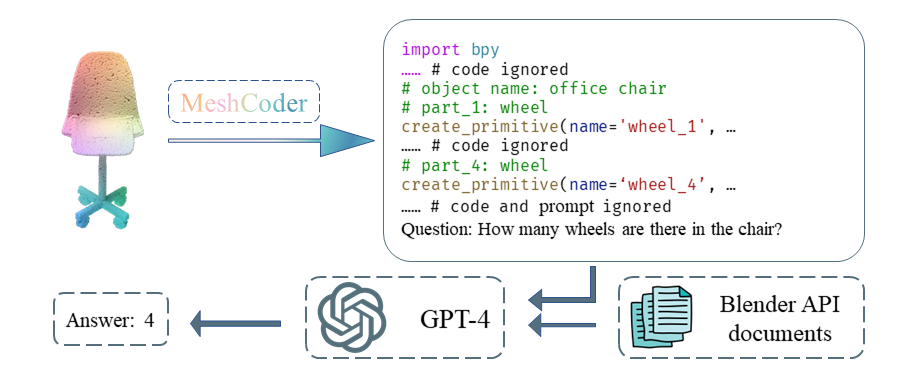
GPT-4 看懂了 3D 模型 :如下图所示,我们向 GPT-4 展示了一段由 MeshCoder 生成的办公椅代码以及对应代码功能的描述,然后用自然语言提问:“这把椅子有几个轮子?” GPT-4 通过分析代码中 part_1: wheel 等注释和 create_primitive (name=’wheel_1′, …) 等函数,准确地回答出:“4 个”。
实现复杂的结构推理 :如下图所示,我们进一步提问,关于洗碗机的内部结构。GPT-4 同样通过阅读代码,清晰地总结出:“这是一个洗碗机,主体由多个立方体构成,内部有用于放置碗碟的架子,架子由矩形和圆柱体阵列构成……”。并且,代码在推断物体的尺寸上是有明显的优势的。我们分别将洗碗机的代码和图片输入到 GPT-4 中,让 GPT-4 给定洗碗机的高度来推测洗碗机的宽度时。我们发现,GPT-4 很难只从图片中推断得到准确的尺寸,但是当有代码作为输入时,GPT-4 可以轻松根据代码中的 scale 参数来判断洗碗机的宽度。



这个实验有力地证明,MeshCoder 搭建了一座桥梁,将物体的形状信息以及尺寸信息提取成有语义的描述提取到代码中, 极大的帮助了大语言模型理解三维世界,通过阅读结构化代码来 “理解” 三维物体的组成、部件关系乃至功能属性 ,为 AI 的 3D 认知能力开辟了激动人心的新方向。
局限性与未来展望
MeshCoder 是我们对 3D 程序化生成模型的一次深刻探索。它证明了,通过代码化的方式来表征和生成 3D 世界是一条充满潜力且极具价值的道路。当然,这只是探索的开始。我们坦诚地认识到,作为一个对新范式的初步探索,MeshCoder 在展现出巨大潜力的同时,也存在一些挑战。其中最主要的是,训练集的多样性与数量仍然不足, 当面对与我们训练数据分布差异较大的物体时,模型的重建效果会打折扣,泛化能力有待进一步提升 。
因此,我们的下一步工作重心将是 采集更多样化的数据,持续扩充数据集的广度与深度 ,以提升模型的泛化能力与鲁棒性。我们相信,坦诚地面对这些挑战,是推动领域前进的第一步。MeshCoder 的开源是团队为此付出的努力,也希望能成为社区进一步研究的基石。我们期待与全球的研究者和开发者交流与合作,共同推动 3D 生成技术向前发展。
]article_adlist–>
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

