
<p>作者:路锦(小蘭)</p> 背景:Android 应用崩溃的挑战
在移动应用的世界里,稳定性是用户体验的基石。任何异常都可能导致用户失望、给出差评,并最终卸载应用。对于开发者而言,快速识别、定位和修复这些问题至关重要。正如线上应用崩溃了,我们收到的却往往只是一个无情的”已停止运行”提示。尤其面对 Native 崩溃和代码混淆,堆栈信息如同一本”天书”,让问题定位变得异常困难。本文将系统性地拆解 Android 崩溃捕获的底层原理与核心技术难点,并提供一套统一的框架设计思路,旨在点亮线上崩溃的”盲区”,实现从捕获到精准归因的闭环。
崩溃采集的技术原理与方案调研
要捕获崩溃,我们首先需要理解 Android 系统中两类主要崩溃的底层触发机制。
2.1 Java/Kotlin 崩溃采集原理
Java 和 Kotlin 代码都运行在 ART (Android Runtime) 上,当代码中抛出一个异常(如 NullPointerException)而没有被任何 try-catch 块捕获时,这个异常会沿着调用栈一路向上传递。如果最终抵达线程的顶部仍未被处理,ART 就会终止该线程。在终止前,ART 会调用一个可供开发者设置的回调接口——Thread.UncaughtExceptionHandler。
这正是我们捕获 Java 崩溃的入口。通过调用 Thread.setDefaultUncaughtExceptionHandler(),我们可以注册一个全局处理器。当任何线程发生未捕获异常时,我们的处理器便会接管,从而获得在进程完全死亡前的宝贵时机,用以记录崩溃现场的关键信息。
2.2 Native 崩溃原理:深入信号处理与现场捕获
Native 崩溃发生在 C/C++ 代码层,它不受 ART 虚拟机管理,因此 UncaughtExceptionHandler 对其无能为力。Native 崩溃的本质是 CPU 执行了非法指令,进而被操作系统内核检测到。内核会向对应的进程发送一个 Linux 信号 (Signal) 来通知这一事件,这是一种内核与进程之间进行异步通信的机制。
常见致命信号详解
SIGSEGV(Segmentation Fault):段错误。这是最常见的 Native 崩溃原因,本质是程序试图访问一块它无权访问的内存。例如:解引用一个 NULL 指针、访问已释放对象的内存(Use-After-Free)、数组越界、试图写入只读内存段等。SIGILL(Illegal Instruction):非法指令。当 CPU 的指令指针指向一个无效或包含损坏数据的地址时,CPU 无法识别将要执行的指令,便会触发此信号。例如:函数指针错误导致跳转到非代码区、栈被破坏导致返回地址错误等。SIGABRT(Abort):程序异常终止。这通常是程序”主动”选择的崩溃,一般由调用abort()函数触发。在 C/C++ 中,很多断言库(assert)在断言失败后会调用abort(),表明程序进入了一个绝对不应存在的状态。SIGFPE(Floating-Point Exception):浮点数异常。例如:整数除以零、浮点数上溢或下溢等。
捕获流程四部曲
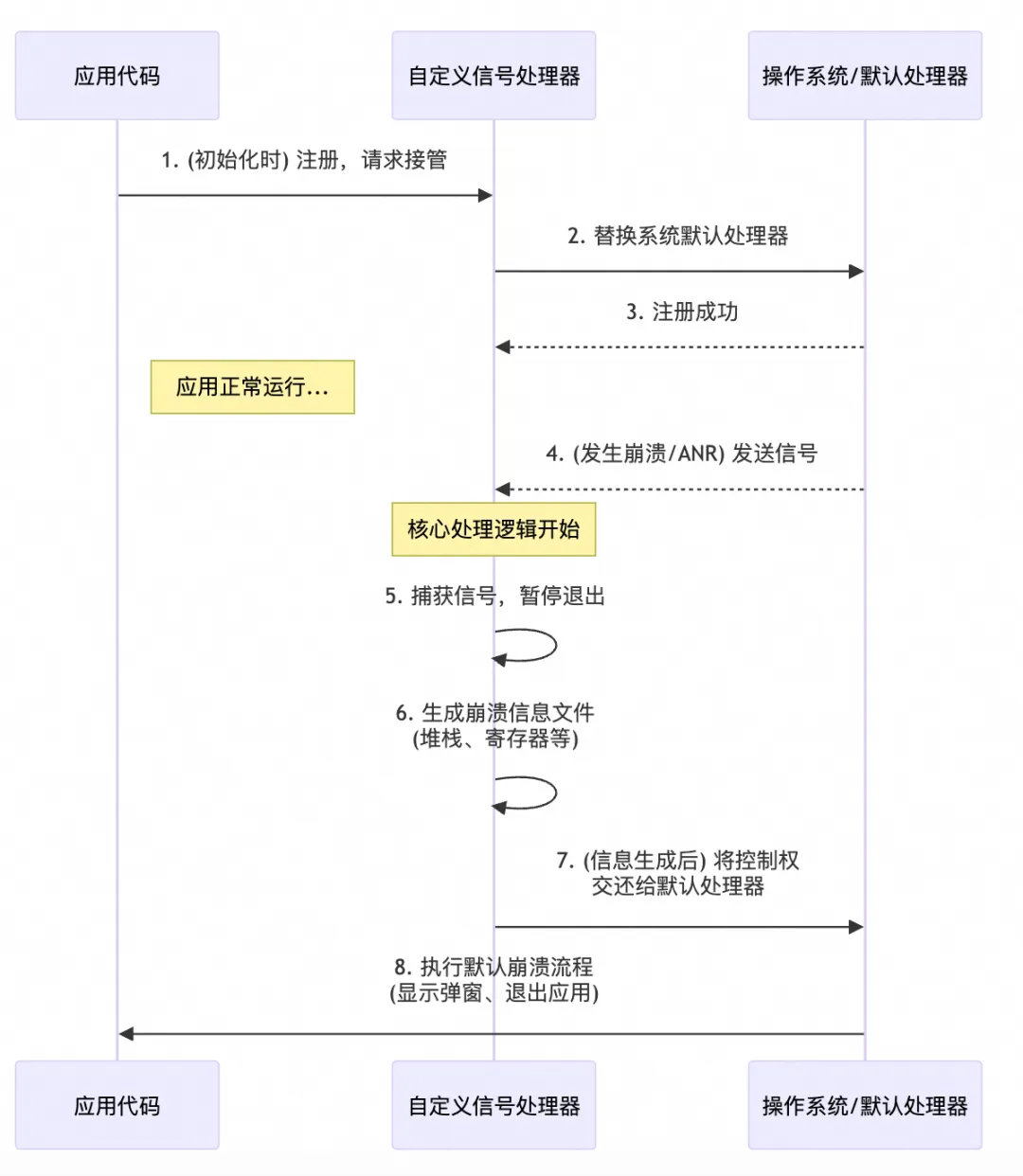
捕获这些信号并还原现场,是一个精细且严谨的过程:
-
注册处理器 (
sigaction):这是捕获流程的第一步。我们使用sigaction()系统调用来为我们关心的信号(如SIGSEGV)注册一个自定义的回调函数。相比于老旧的signal()函数,sigaction提供了更丰富的功能,特别是通过设置SA_SIGINFO标志,可以让我们的回调函数接收到一个包含详细上下文的siginfo_t结构体,其中包括了导致崩溃的具体内存地址 (si_addr) 等宝贵信息。 -
安全第一 :
async-signal-safe环境: 信号处理器函数在一个非常特殊且严苛的环境中执行。在这个环境中,我们不能假定全局数据结构是完好无损的,也不能调用绝大多数标准库函数(如malloc, free, printf, strcpy),因为它们不是”异步信号安全”的,调用它们极易导致二次崩溃或死锁。我们能做的,只有调用少数被明确标记为”安全”的函数(如write, open, read)。 -
堆栈回溯 (Stack Unwinding):为了得到函数调用链,我们需要在信号处理器中进行堆栈回溯。这是一个通过分析当前线程的栈指针(SP)、帧指针(FP)以及栈上的返回地址,来逐层还原函数调用关系的过程。
libunwind等库被广泛用于此目的。然而,在 Native 崩溃场景下,栈本身可能已经被破坏,这使得实时回溯的成功率并非 100%。 -
生成报告 (Minidump):正因为实时回溯的不可靠性,业界最佳实践(如 Google Breakpad)并非在信号处理器中直接进行复杂的堆栈回溯。更可靠的做法是:在信号处理器这个”安全环境”中,只做最少、最核心的操作——即收集所有线程的寄存器上下文、原始的堆栈内存片段、已加载的模块列表等信息,并将它们”打包”成一个结构化的 Minidump 文件。这个过程不涉及复杂的逻辑,失败风险低。真正的堆栈回溯和符号化分析,则被推迟到服务端,在更安全、资源更充裕的环境中离线进行。
2.3 业界方案调研
基于以上原理,业界涌现了众多优秀的开源及商业化方案。它们本质上都是对上述原理的工程化封装。
- Google Breakpad/Crashpad:它们是 Native 崩溃捕获的”黄金标准”,提供了从信号捕获、Minidump 生成到后台解析的全套工具链。它们是许多商业方案的技术基石,但自行集成和后台搭建成本较高。
- Firebase Crashlytics & Sentry:这类商业化平台(SaaS)提供了”SDK + 后台”的一站式服务。它们封装了底层的捕获逻辑,并提供了强大的后台用于报告聚合、符号化解析和统计分析,极大地降低了开发者的使用门槛。
- xCrash:这是一个功能强大的开源库,不仅支持 Native 和 Java 崩溃,还对各种复杂场景下的堆栈回溯做了深度优化,信息采集能力非常出色。

经过对比分析,本文选择 Google Breakpad 作为 Native 崩溃采集的核心技术。Breakpad 采用业界标准的 Minidump 格式,这一格式已被 Chrome、Firefox 等全球主流产品广泛采用,技术成熟。从能力覆盖角度看,Breakpad 在 Native 崩溃捕获、多架构支持、跨平台兼容等核心场景上表现完整,配套的符号化工具链(如 dump_syms、minidump_stackwalk)也十分成熟。虽然 Breakpad 专注于 Native 层面,但 Java 崩溃可通过上述 UncaughtExceptionHandler 机制补齐,整体能力覆盖性满足崩溃采集的要求。
核心技术难点解析
实现一个可靠的崩溃采集方案,需要克服以下三大技术难点。
难点一:捕获时机与信息保存的可靠性
崩溃发生时,整个进程已处于极不稳定的濒死状态。此时执行复杂操作(如网络请求)风险极高。我们必须确保信息记录的过程足够快且绝对可靠。因此,”同步写入、延迟上报”是最佳策略。即在捕获到崩溃的瞬间,以最快的同步方式将信息写入本地文件,然后等到应用下一次正常启动时,再从容地读取文件并上报到服务器。
难点二:Native 崩溃的”黑盒”特性
相比于 Java 崩溃,Native 崩溃现场更易遭到破坏。非法的内存操作可能已污染了堆栈,导致传统的堆栈回溯方法失效。因此,简单地记录几个寄存器值是远远不够的。我们需要的是一个包含线程、寄存器、堆栈内存、已加载模块等信息的完整”现场快照”。这正是 Breakpad 提出的 Minidump(小型转储)概念的价值所在。
难点三:堆栈的”天书”——混淆与符号化
为了安全和包体大小,线上代码通常经过了混淆(ProGuard/R8)。这会导致崩溃堆栈中的类名和方法名变成无意义的 a, b, c,如同天书。对于 Native 代码,发布的是不含符号信息的二进制文件,其堆栈也是一串无意义的内存地址。因此,符号化 (Symbolication)是必不可少的一环。我们必须在编译时生成并保留对应的符号表文件(Java 的 mapping.txt,Native 的 .so 文件),在服务端利用这些文件将”天书”翻译回可读的、有意义的堆栈信息。
Android 应用崩溃采集及堆栈解析实践
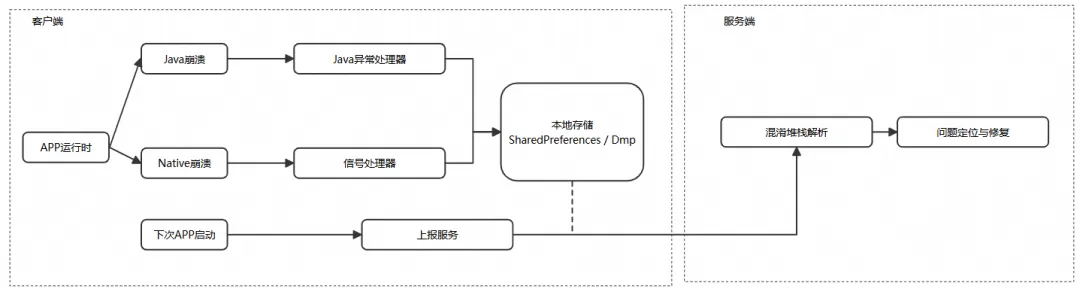
为了全面应对这些挑战,我们设计了一个统一的异常采集方案,遵循”捕获-持久化-上报-解析”的生命周期。无论是 Java 还是 Native 崩溃,客户端的核心任务都是可靠地将现场信息保存到本地。真正的解析和分析工作则交由服务端完成。
4.1 Java/Kotlin 崩溃处理
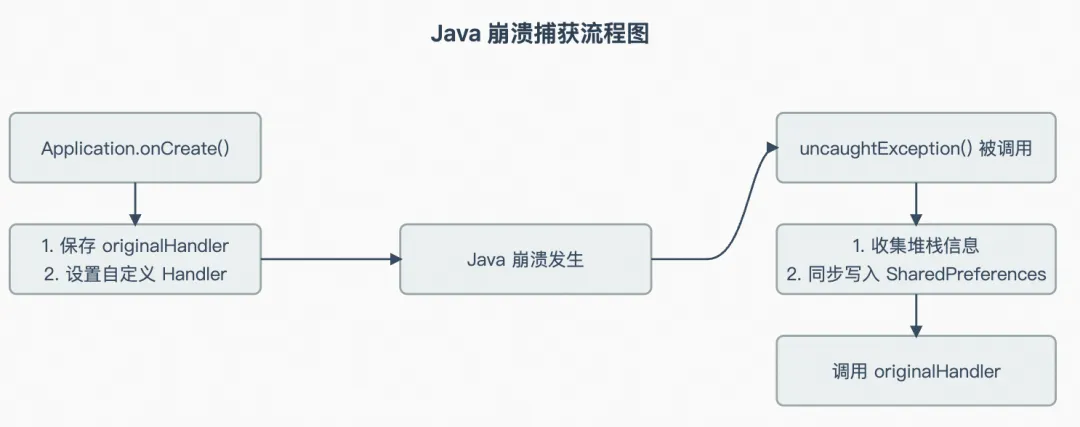
我们使用 Thread.setDefaultUncaughtExceptionHandler 来捕获 Java/Kotlin 的异常。这是一个回调接口,无论是 Java 还是 Kotlin,其编译后的字节码均由 ART 执行。当抛出未捕获异常时,ART 会触发当前线程的异常分发机制,最终调用注册的 uncaughtException 方法。因此 Thread.setDefaultUncaughtExceptionHandler 能够实现全局 Java/Kotlin 异常捕获。
首先需要设置一个全局的未捕获异常处理器来捕获 Java 崩溃,通过实现Thread.setDefaultUncaughtExceptionHandler 的 uncaughtException 方法实现一个处理器,我们可以将自己实现的 handler 设置为所有线程的默认处理器。这就给了我们在应用彻底崩溃前的最后一刻”力挽狂澜”的机会——记录下导致崩溃的元凶。需要注意我们要保留原始的处理器:originalHandler。
当崩溃发生时,该处理器会收集异常及堆栈关键信息,最终将其同步持久化到 SharedPreferences。由于进程即将终止,当前的步骤必须保证同步完成,因此我们持久化写缓存也使用同步提交 (editor.commit()) ,异步的 apply() 可能无法确保成功持久化。关键的异常信息例如:
- 时间戳 (Timestamp):崩溃发生的精确时间。
- 异常类型 (Exception Type) :是
NullPointerException还是IndexOutOfBoundsException等。 - 异常信息 (Exception Message):异常对象中包含的描述性信息。
- 堆栈轨迹 (Stack Trace):这是最重要的部分,它告诉我们崩溃发生在哪个类的哪一行代码。
- 线程信息 (Thread Name):崩溃发生在主线程还是某个后台线程。
“下次启动时上报”是核心策略。它避免了在应用崩溃时不稳定的网络环境中尝试上报数据,大大提高了成功率。我们在 start() 方法中调用此检查。这个方法可以在后台线程中执行,防止阻塞应用主线程。
@Override
public void uncaughtException(Thread thread, Throwable throwable) {
try {
// 核心难点1:收集崩溃信息
CrashData crashData = collectCrashData(thread, throwable);
// 核心难点2:保证濒死前数据能被同步、可靠地保存
saveCrashData(crashData);
} finally {
// 核心难点3:将控制权交还,确保系统默认行为(如弹窗)执行
if (originalHandler != null) {
originalHandler.uncaughtException(thread, throwable);
}
}
}
private void saveCrashData(CrashData data) {
// 使用 SharedPreferences 的同步 commit() 方法
prefs.edit().putString("last_crash", data.toJson()).commit();
}
4.2 Native 崩溃处理
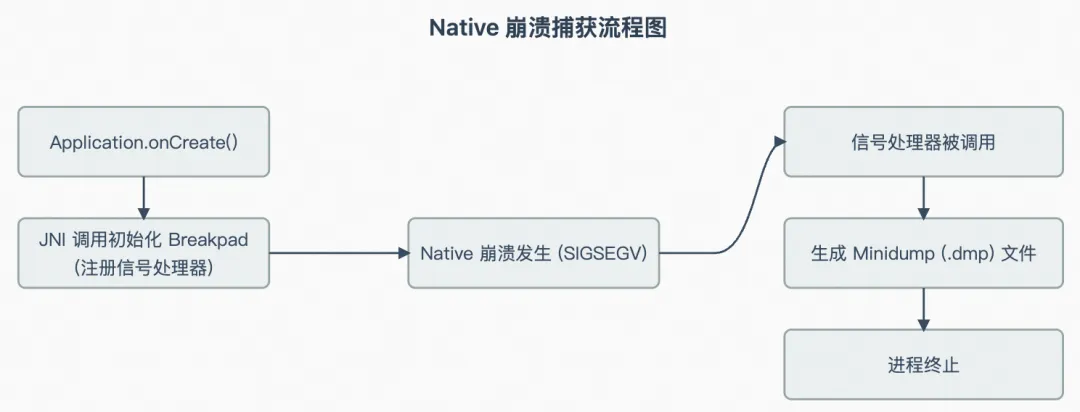
对于 Native 崩溃,我们集成了一个基于 Breakpad 的解决方案。在启动时加载一个 Native 库,该库为常见的崩溃信号设置了信号处理器。
1. 初始化:在 App 启动时,我们初始化 Native 库,并为其提供一个专用的目录来写入崩溃转储文件(crash dump)。
2. 崩溃发生 :当 Native 崩溃发生时,信号处理器会捕获它,并将一个 .dmp (minidump) 文件写入指定目录。
3. 下次启动时处理 :在下一次 App 启动时,我们的框架会检查此目录中是否有任何 .dmp 文件。如果找到,它会调用一个 Native 方法来解析 minidump,提取堆栈信息和其他相关信息。解析后的数据随后被上报到我们的后端,并且转储文件被删除。
public void start() {
// 核心难点1:尽早初始化 Native 层的信号处理器
NativeBridge.initialize(crashDir.getAbsolutePath());
// 核心难点2:在下次启动时,异步检查并处理上次崩溃留下的产物
new Thread(this::processExistingDumps).start();
}
private void processExistingDumps() {
// 遍历指定目录下的 .dmp 文件
File[] dumpFiles = crashDir.listFiles();
for (File dumpFile : dumpFiles) {
// 此处无需解析,直接将原始 .dmp 文件上报
reportToServer(dumpFile);
dumpFile.delete();
}
}
// JNI 桥接,是 Java 层与 C++ 层通信的唯一途径
static class NativeBridge {
// 加载实现了信号捕获和 minidump 写入的 so 库
static { System.loadLibrary("crash-handler"); }
// JNI 方法,通知 C++ 层开始工作
public static native void initialize(String dumpPath);
}
转储文件中我们能获取到的异常信息有很多,使用时我们通常需要关注以下的关键信息:
1. 异常信息 (Exception Information)
- 异常流 (Exception Stream):
- 崩溃线程 ID (Thread ID):明确指出是哪一个线程引发了这次崩溃。
- 崩溃信号(Signal),例如 SIGSEGV(段错误) 和 SIGILL (非法指令)。
- 异常地址 (Exception Address):异常发生时,CPU 指令指针(Program Counter)所在的内存地址。这直接指向了导致崩溃的那一行机器码。
相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


