
<blockquote> 在分布式环境下,分区对性能的影响不可小觑。本文深度、详尽的讲解 Apache Doris 自动分区设计思考,并就多线程复杂并发场景下所面临的挑战,一一剖析 Doris 自动分区设计时的应对策略。
在分布式系统中,复杂并发场景下的数据一致性与流程正确性始终是设计与实现中的核心挑战。Apache Doris 的自动分区功能正是在这一背景下应运而生。然此项技术的实现并非一蹴而就,我们面临多个层面的并发问题,包括 BE 与 FE 之间的元数据竞争、OlapTableSink 与数据发送线程的状态同步等。通过拆解与简化问题,我们设计了串行化分区创建、双重检查线程退出及基于”锚点分区”的引用计数机制等解决方案,逐步构建出一个在分布式、多线程和非对称角色环境下依然能保持正确性与高性能的并发模型。
自动分区的实现
在 Apache Doris 这样的大规模数据仓库中,分区对性能影响较大。Apache Doris 早已支持自动分区 (Auto Partition) 功能,可在数据导入时自动创建数据所对应的分区,节省了人工操作及维护成本。那么,自动分区功能如何实现的呢?在这之前,需要先了解 Doris 及数据导入的过程。
数据导入流程
FE(负责元数据管理和查询规划) 对 SQL 生成对应的查询计划并发送给 BE 执行,第二步:BE(负责数据存储和计算执行)在执行完查询部分并得到结果以后正式进入导入阶段:
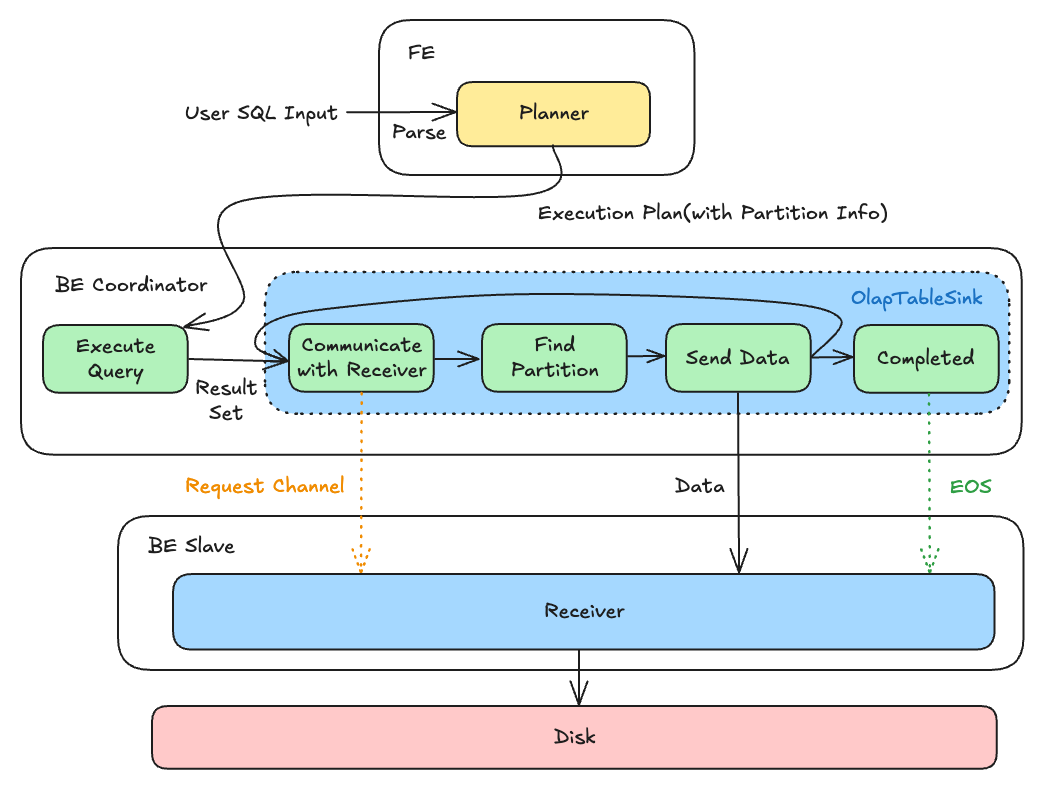
- 根据 FE 下发的分区信息及对应位置,建立和下游 BE 的通道
- 对于每个到达的 Block,给每一行数据找到对应的分区与分桶
- 下发数据
- 重复步骤 2、3 直到处理完最后一个 Block
- 确认数据发送完成,发送结束标记,接收端落盘形成 rowset
自动分区设计
Doris 作为分布式的数据库,在自动分区中面临的核心矛盾为:作为”大脑”的 FE 负责规划并创建分区,但具体导入哪些数据,却要等到”手脚”的 BE 执行时(OlapTableSink)才能确定。这种信息差导致无法在规划阶段提前创建正确分区。
因此在自动分区设计中,在 OlapTableSink 时插入一个新步骤——实时向 FE 申请所需分区,并重新与下游 BE 协商,以建立新的数据写入通道。因此,导入流程变为以下:

- FE 下发的初始分区信息会触发 OlapTableSink 与下游建立首次连接(Init Open)。
- 每个数据块(Block)的到达都可能因创建新分区而触发增量连接(Incremental Open),以打通新的数据通道。
- 最终,在所有数据块发送完毕后,发出关闭请求。
由于发送数据是重 IO 操作,必须使用单独的线程进行处理,并不在 OlapTableSink 的当前线程当中。由此带来的复杂性我们将在后文分析。
如何应对多线程复杂并发
在实际的使用场景中,Doris 常常要对大规模数据并行处理,流程要比上述复杂百倍。在并发处理中,一个查询计划由多个 Fragment(查询计划的部分切片)构成,而每个 Fragment 会克隆出多个 Instance(执行实例),因此,系统中可能同时存在大量互不感知的 OlapTableSink 实例。
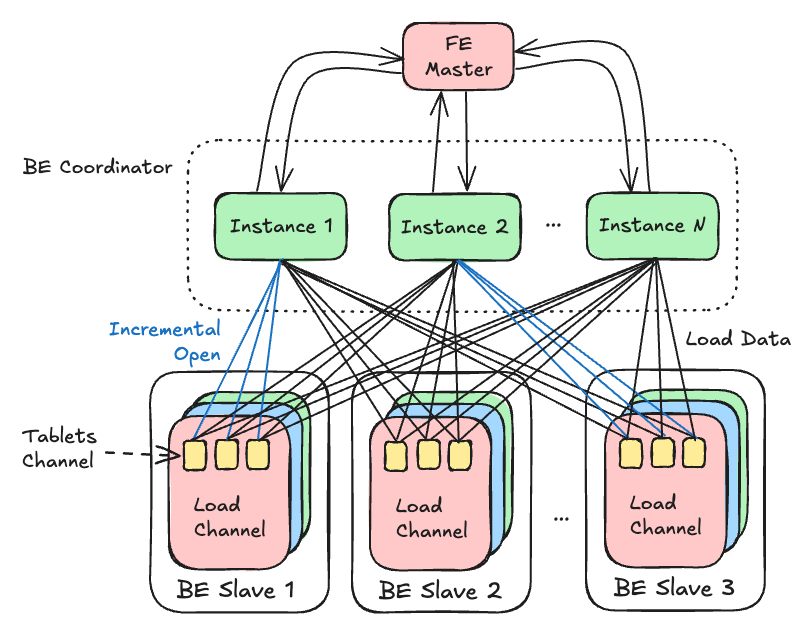
其中每条线都代表一对线程之间的 RPC 交互:
- BE 需要发送无对应分区的数据给 FE 以获取新创建的分区,FE 会返回新创建的分区信息
- 对于新创建的分区,Coordinator 需要告知接收端(incremental open),以正确准备数据写入通道
- 在 incremental open 的同时,可能有数据从 Coordinator 发送到 Slave 进行写入
问题拆解
面对复杂并发的首要原则是拆解:将无直接关联的交互逻辑分离,若各自能独立正确运行,且彼此间的影响可控,则整体流程的正确性便得以保障。
例如,FE 创建分区后向 BE 广播元数据的过程便可被忽略。这是因为分区创建的 RPC 是同步的,它保证了当 Instance 通过 Incremental Open 打开下游通道时,对应的元数据早已在接收端准备就绪。
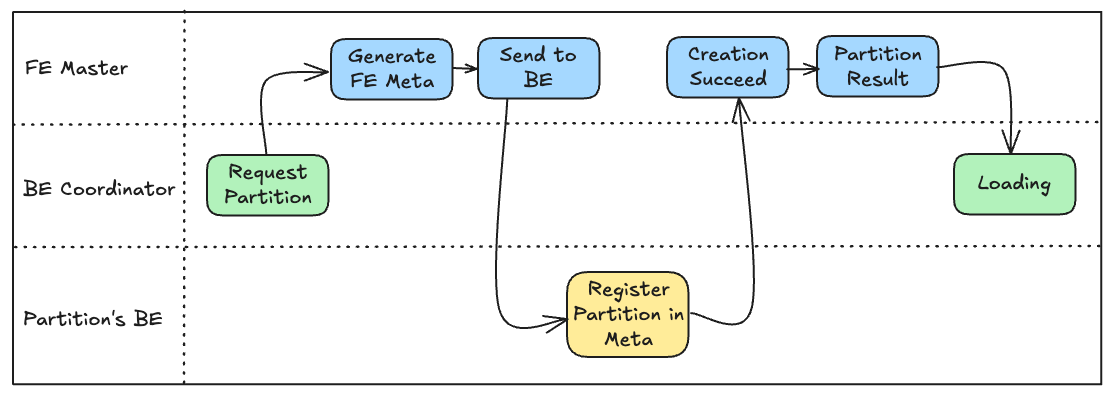
那么需要关注的交互仅有以下几个:
- BE 与 FE 之间的通信
- BE OlapTableSink 与数据发送线程之间的冲突
- 数据发送端(BE Coordinator)与接收端(BE Slave)之间的通信
应对策略
BE 与 FE
首先看 BE 与 FE 之间。这里的并发来源是,不同的 BE Instance 都可能向 FE Master 请求分区创建。那么:
- 不同 Instance 之间有相同的数据怎么办?
- 如果同时/先后请求了相同的分区创建怎么办?
由于 BE 的 Instance 之间不互相通信,所以必然存在以下情况:不同 Instance 之间因为相同的数据,重复向 FE 请求创建相同的分区。我们要让这些 Instance 之间广播新分区信息来避免重复请求吗?答案是否定的。原因是这样打破了 Doris 用以保持极高稳定性的一贯原则:BE 线程之间的交互只在极特定的统一渠道发生,例如通过 Data Queue 传递数据 Block。如果执行线程之间经常互相交互,锁的开销将会极大拉低性能,并且引入极难排查的隐藏问题。
在 FE 端,我们可以简单加锁将不同的分区创建请求串行化 。其原因是,相比于 BE 需要实际处理海量数据,分区元数据的个数是相对较少的,这些请求的处理也相对较轻,直接加锁串行化不会带来很大的性能问题,好处却是显而易见的:对元数据的操作不产生竞态,对于之前的重复请求,我们直接返回已经创建过的分区信息即可。这样不同 Instance 之间重复请求的问题也迎刃而解。

OlapTableSink 与数据发送线程
这里的核心问题在于——数据发送线程什么时候停止?
对于普通表的导入来说,它会检查所有 NodeChannel 都已停止(由 close 操作标记),这是很清晰的过程。但在自动分区场景下,事情有了很大不同:我们有可能压根不会打开任何 NodeChannel,此时像是普通导入中可以关闭的时刻,但它之后仍有可能通过 incremental open 打开新的,所以不能草率地决定关闭。
因此我们需要把两种情况分开讨论:
- 如果发现有 NodeChannel,那么是否为自动分区导入没有区别:我们等候所有 Channel 停止 即可。由于导致 Channel 停止的 eos 标记是所有 Block 写入之后的 close 阶段才会产生的,因此即使为自动分区导入,之后也一定不会再有新的 incremental open;
- 如果当前没有 NodeChannel,那么我们等待 close 操作被触发以后(不会再 Incremental open 了),即可停止数据发送线程。
如何确保没有运行中的 Channel 呢?你不能在 close 之后再去确认这一点,原因是存在如下的并发可能:
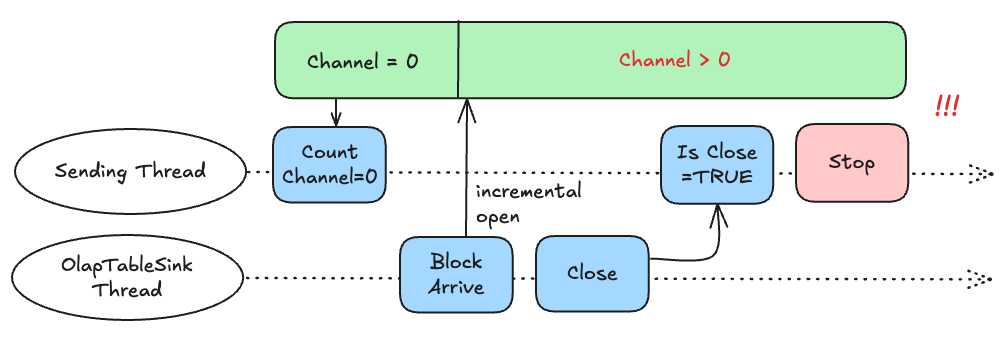
当我们先计算过现存 Channel 数,然后根据 close 标记误以为可以停止发送数据时,殊不知此时已经有了新的 Block 正在等待发送。这个后果是极其严重的——**导入会顺利完成,但数据悄悄丢失了。**因此判定导入可以停止的 Channel 记数,必须在检查 Closed 标记之后。——这就是我们所说的,”当一个数据处理逻辑由串行变为并发,由于参与者之间的不同状态交联,简单的情况会陡然变得复杂”。处理并发时必须想清楚所有可能的相互顺序。
简化以后的代码如下,具体细节可见于注释:
while (true) {
// During incremental_open, the data of the channel may be temporarily
// inaccurate, no check should be performed at this time.
std::unique_lock<std::mutex> l(_stop_check_channel);
int running_channels_num = 0;
int opened_nodes = 0;
bool is_closed = _try_close; // MUST BEFORE counting of opened_nodes
for (const auto& index_channel : _channels) {
index_channel->for_each_node_channel([&running_channels_num,
this](const std::shared_ptr<VNodeChannel>& ch) {
running_channels_num +=
ch->try_send_and_fetch_status(_state, this->_send_batch_thread_pool_token);
});
opened_nodes += index_channel->num_node_channels();
}
if (opened_nodes != 0 && running_channels_num == 0 || opened_nodes == 0 && is_closed) {
return;
}
bthread_usleep(sleep_time);
}
发送端与接收端
这里的核心问题是,我们怎样知道导入结束了?
在以往的模型中,由于 OlapTableSink 的所有 Instance 都直接由 FE 规划产生且不带修改,因此他们掌握的下游分区分布都是一致的。对于每个下游接收端来说,它的上游也一定是 OlapTableSink 所在 Fragment 的全体 Instance 。那么可以通过一个引用计数 来解决这个问题:上游会在 open 时顺便告知 Instance 数,导入结束时必然是每个 Instance 都完成了 close 操作。那么接收端只需要以此作为计数,等待 Instance 个 close 消息即可结束导入并落盘。
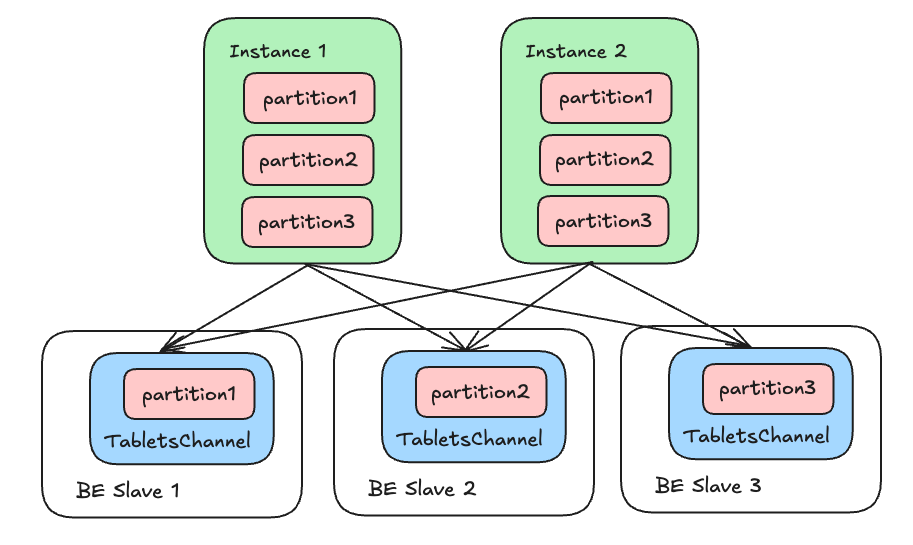
但到了 Auto Partition 的导入场景,事情则大不相同:由于各个 Instance 的数据不同,新增分区的过程使得他们与下游的连接数量也可能不同,且这个数字是无法提前获知的。例如:
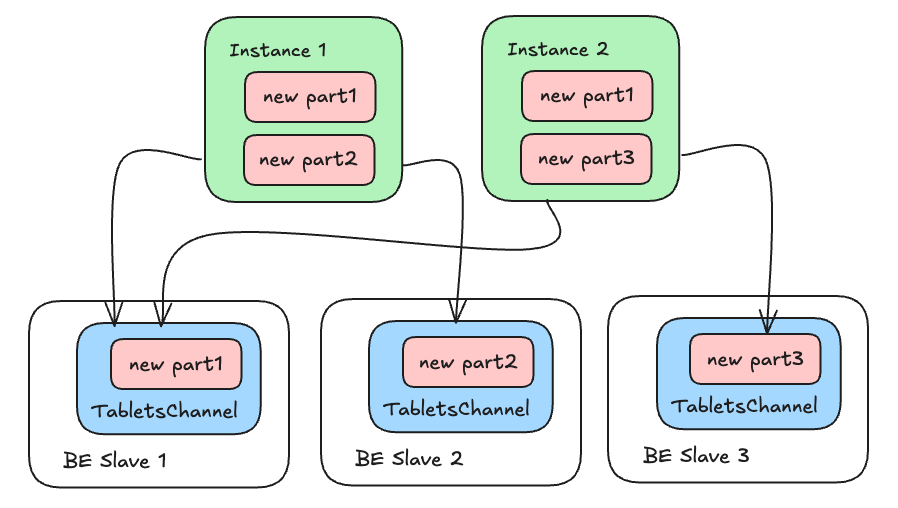
假设上图中的分区全部为导入过程中创建的,则下游引用计数并不相同,且当引用计数归零时,下游并不能确保数据接收完毕。例如图中 BE Slave 1,假设 Instance 1、2 的导入均已完成,则某一时刻引用计数会减小至 0。但此时若上游有一 Instance 3,它有可能在 1 和 2 导入完成后再行 incremental open 并导入数据。因此即使计数归 0,我们仍无法关闭下游通道。
这里我们分为两个具体场景来看:
- 导入前已有部分分区,此时下游 BE 有两种可能
- 有已知分区位于当前 Slave BE
- 没有任何分区位于当前 Slave BE
- 空表导入,无任何分区
对于接收端 1.a。 的情况,同普通表导入一样,导入前已知的分区一定是所有上游 Instance 共同知晓的,所以接收端可以采用以前相同的引用计数方式 。即使接收到了 incremental open 请求,也只是打开一些新的分区 DeltaWriter,不会改变它们的预期的发送端数量——等于 OlapTableSink Instance 总数。
对于接收端 1.b。 的情况,也就是上文提到的,我们通过当前 Slave BE 的信息,是无法判断什么时候该完成导入的。只能从其他角度想办法。
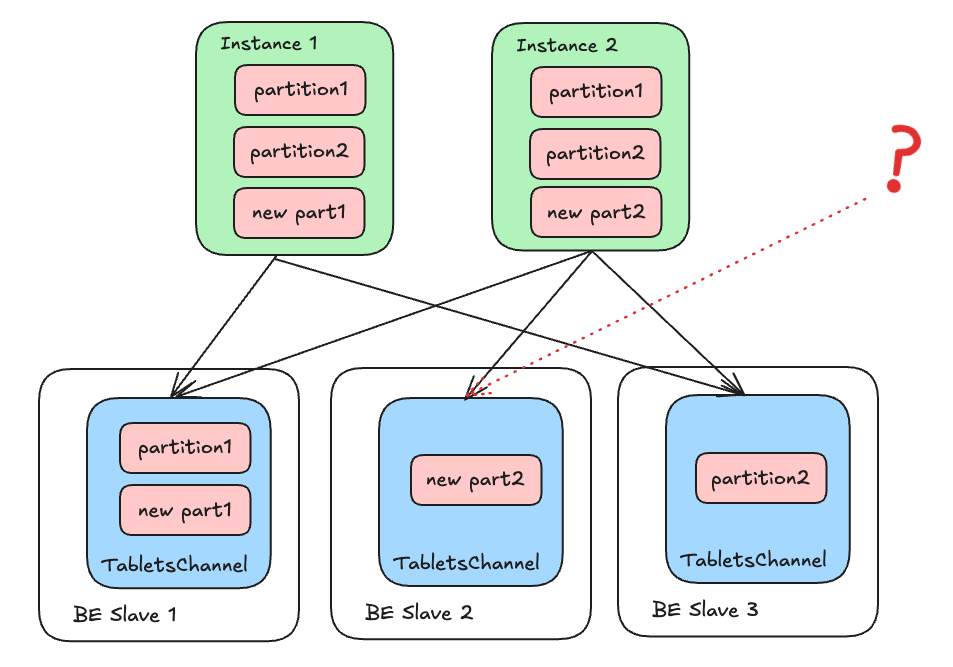
现在让我们看看发送端的操作:如果我们一次性关闭所有 Channel,对于上图中的 BE Slave 2 (也就是情况 1.b。),由于引用计数归 0 时无法判断是否会有其他 Instance 的 incremental open 可能发生。无法结束导入。
但注意到一点:无论有多少 Instance,他们都必然感知 Partition 1 和 2 (称之为 Init Partition)。相应地,Slave 1 和 3 的引用计数必然与 Instance 总数相匹配。如果 Slave 1 和 3 close 完成了,那么所有上游必然已经触发了 close。此时再去 close 那些只有 New Partition 的下游 BE,就不必再担心之后可能有 incremental open 的问题了。 下游 BE 在此时接收到 close 信号,就清楚的知道上游数据均已分发完成,引用计数归 0 时可以直接结束导入。
换句话说,这些 Init Partition 带来的接收端 TabletsChannel 被当做锚点,用以确保上游 Instance 已完成 close 操作。

再来看场景 2,它看起来是最为特殊的情况——这里没有任何 Init Partition 可以作为锚点使用,似乎之前的设计完全失效了。但在软件设计当中,如果相似的问题已经有了良好的解决方案,通过一点小的变换产生一样的场景,应用那些已有的方案往往是不错的选择。我们只需要在 FE 规划发现这种情况时,下发一个不会有任何数据命中的占位分区 (Dummy Partition) ,即可把问题转换到与场景 1 完全一致。而场景 1 刚刚已经被我们完美解决过了。
写在最后
在解决了自动分区各个维度的并发挑战后,我们有必要跳出具体实现,审视其中蕴含的更具普适性的设计哲学与并发范式。这些范式不仅适用于 Doris,也对其他分布式系统的并发设计具有参考价值。
锚点
在并发,尤其是分布式并发当中,如何在线程之间构建同步往往比较困难。当系统里的一切都是动态的时候,协调就无从谈起。这时,最有效的办法就是通过所有参与者的共同信息设定一个不变的参照物。
- 实践案例 :在”发送端与接收端”的结束设计中,由于连接数量同时存在增、减的情况,我们无法判定关闭的时机。通过”Init Partition 关闭必然意味着上游全部结束导入”的规律,成功使用 Init Partition 所在的下游 BE 当做”锚点”来协调整个关闭过程。空表导入的问题看似复杂,也通过引入 Dummy Partition 归约到已知情形一并解决。
- 一般规律 :当系统缺乏同步时,找到一个稳定的、所有参与者都认可的状态锚点,可以将复杂的动态协调问题简化为成熟的静态处理逻辑。这体现了通过引入确定性来约束不确定性的核心思想。
状态机
对于存在复杂状态流转的核心组件,将其生命周期管理建模为一个状态机,并通过一个不可逆的临界状态作为”关门信号”,可以有效解决”何时停止”的难题。
- 实践案例 :数据发送线程的生命周期管理。
_try_close就是一个关键的临界状态。一旦进入此状态,系统便承诺”不再产生新的任务”,这使得线程可以在动态环境中安全地判断完成条件。 - 一般规律:在消费者-生产者或管理者-工作者的模型中,一个明确的、不可逆的终止信号,配合信号发出后对任务队列的最终原子快照,是解决动态任务集合下优雅退出的通用解法。
并发隔离
将并发控制约束在系统架构的特定层级,避免将其扩散到所有组件之间,是保证系统整体可维护性与性能的基石。
- 实践案例:拒绝让 BE 的各个 Instance 直接交流新分区信息,而是将分区创建的交汇集中到 FE 进行串行化处理。这确保了 BE 层高吞吐数据处理的纯粹性,将元数据的一致性这个”低频但关键”的问题隔离在 FE 层解决。
- 在系统的不同层级采用不同的并发策略。数据平面追求吞吐,采用无锁或分片等高并发设计;控制平面追求强一致与正确性,可采用更保守的同步原语。避免让高频执行路径承担复杂的协调任务。
冗余与幂等
在分布式系统中,与其试图消除所有冗余操作,不如承认并接受冗余的必然性,转而将重点放在如何让这些操作具备幂等性,使整个系统对重复请求保持稳定。
- 实践案例:不同 BE Instance 重复请求创建同一分区。我们并未试图阻止重复请求,而是在 FE 端通过加锁串行化并结合幂等处理——直接返回已创建的分区信息——来优雅地解决。
- 面向冗余设计,而非面向完美设计。 在消息传递不可靠、组件视角不一致的分布式环境下,幂等性是将系统从”可能重复”的困境中解放出来的关键设计。
Apache Doris 自动分区的并发实践揭示了一个核心启示:应对复杂并发,并非要设计一个包罗万象的复杂模型,而恰恰在于通过精妙的分解与转化,将未知问题映射到已知领域。
未来,我们将继续在自动分区的智能化等方面进行更进一步的提升,例如通过引入表达式分区、合并动态分区等新设计,进一步把 Doris 用户从复杂的 DDL 运维当中解放出来。我们也相信,本文中所阐述的设计思路与实现方法,能够为其他分布式系统在面对类似并发问题时提供有益的参考与启发。
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


