
近年来,以 Veo、Sora 为代表的视频生成模型展现出惊人的合成能力,能够生成高度逼真且时序连贯的动态画面。这类模型在视觉内容生成上的进步,表明其内部可能隐含了对世界结构与规律的理解。更令人关注的是,Google 的最新研究指出,诸如 Veo 3 等模型正在逐步显现出超越单纯合成的 “涌现特性”,包括感知、建模和推理等更高层次能力。
这催生出一个与语言模型 “思维链”(Chain-of-Thought, CoT)相对应的新概念 ——Chain-of-Frame(CoF)。其核心思想是:模型通过逐帧生成视频,以连贯的视觉推演方式逐步解决问题。然而,一个关键疑问仍未解决:这些模型是否真正具备零样本推理(Zero-Shot Reasoning)的能力?抑或它们只是在模仿训练数据中出现过的表面模式?
为探究这一问题,来自香港中文大学、北京大学、东北大学的研究团队进行了系统性研究,对 Veo 3 等模型的零样本推理潜力进行了深入评估,并提出了涵盖空间、几何、物理、时间等 12 个推理维度的综合测试基准 ——MME-CoF。

论文题目:Are Video Models Ready as Zero-Shot Reasoners? An Empirical Study with the MME-CoF Benchmark
论文链接:https://arxiv.org/pdf/2510.26802v1
项目主页:https://video-cof.github.io/
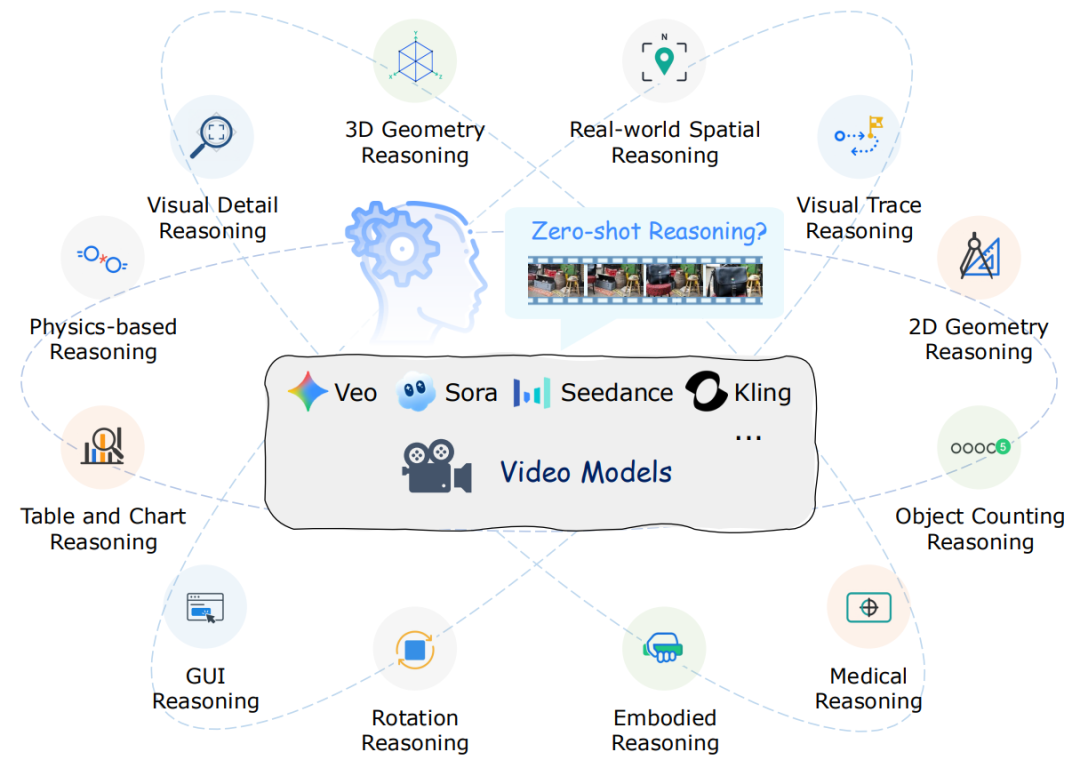
什么是 Chain-of-Frame(CoF)推理?
“帧链推理” 可以视作语言中 “思维链”(CoT)的视觉类比:
CoT 通过逐步生成文字展现推理路径。
CoF 则通过逐帧生成画面,使场景在视觉上不断演化,从而体现推演过程。
深入分析:12 项推理挑战
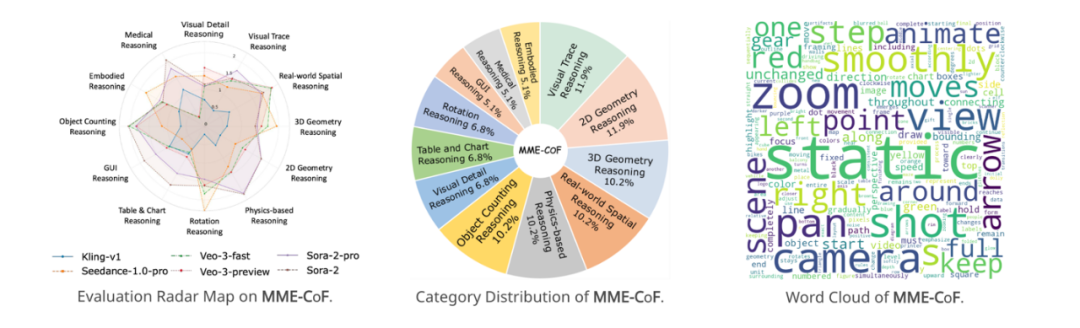
为全面揭示视频模型的推理潜力,研究团队设计了 12 个维度的测试任务,对 Veo 3 进行了系统的实证分析。以下选取其中三个典型维度进行说明(其余部分可参阅原论文)。
1. 真实世界空间推理(Real-World Spatial Reasoning)

任务: 评估模型在多视角自然场景中保持空间一致性的能力,包括视角变化、方位对齐与参考系稳定性。
发现: 能较好处理简单场景下的空间布局与视角切换,局部场景保持合理的空间关系与方向一致。
局限: 在复杂视角变化或深度理解任务中表现不稳,常出现空间错位、视角漂移或方向混乱,难以维持全局坐标一致性。
2. 3D 几何推理(3D Geometry Reasoning)

任务: 评估模型在三维几何变换任务中的结构理解与连续性表现,如物体折叠、旋转与立体重构。
发现: 在单步、简单几何变换中可生成结构完整且视觉连贯的结果,具备初步的三维形态理解能力。
局限: 多步或组合性变换中常出现结构错位、自交或崩塌,无法维持几何一致与物理合理性,整体三维推理仍脆弱。
3. 2D 几何推理(2D Geometry Reasoning)

任务: 评估模型在平面几何构造与图形操作任务中的准确性与约束保持能力,如点连线、形状移动和构图顺序理解。
发现: 在简单几何连接任务中可识别并正确绘制基本关系,呈现初步几何构造能力。
局限: 易优先生成视觉上美观的图形而非严格几何符合,常出现连线顺序错误、形状变形或持续绘制超出任务范围,缺乏稳定的几何约束意识。
其他六个推理维度概览
除上述三项外,其余九个维度同样揭示了 Veo 3 的限制:
视觉细节推理(Visual Detail Reasoning):对被遮挡或微小目标的识别不稳,生成内容易偏离任务要求。
视觉追踪推理(Visual Trace Reasoning):长时序依赖和规则驱动的动作链容易中断,因果一致性不足。
物理推理(Physics-Based Reasoning):未能准确遵循能量、力学等物理规律,仅表现为视觉层面的 “模拟”。
旋转推理(Rotation Reasoning):小角度旋转可近似实现,大角度下结构崩坏。
图表推理(Table & Chart Reasoning):可模仿局部视觉模式,但缺乏对数值关系的真实理解。
物体计数(Object Counting Reasoning):在静态场景下表现良好,但动态环境中常出现漏数或重复。
GUI 推理(GUI Reasoning):能生成点击或拖动动作,但对操作目的与逻辑缺乏认知。
具身推理(Embodied Reasoning):能识别物体位置与动作,但不遵守环境规则,偶有 “作弊式” 生成。
医学推理(Medical Reasoning):在放大或观察局部细节时具备表面能力,但无法保持影像逻辑一致,易出现结构性错误。
MME-CoF:首个视频推理基准
研究团队基于上述实证研究整理了 MME-CoF 基准,以标准化方式评估视频模型的推理潜能。其主要特征包括:
首个系统量化视频模型推理能力的框架;
覆盖 12 个维度、59 个精心设计任务;
提示式设计创新:将抽象推理任务(如物理、几何、计数)转化为可视化视频生成挑战,迫使模型通过 “帧链推理” 展现过程性思考。
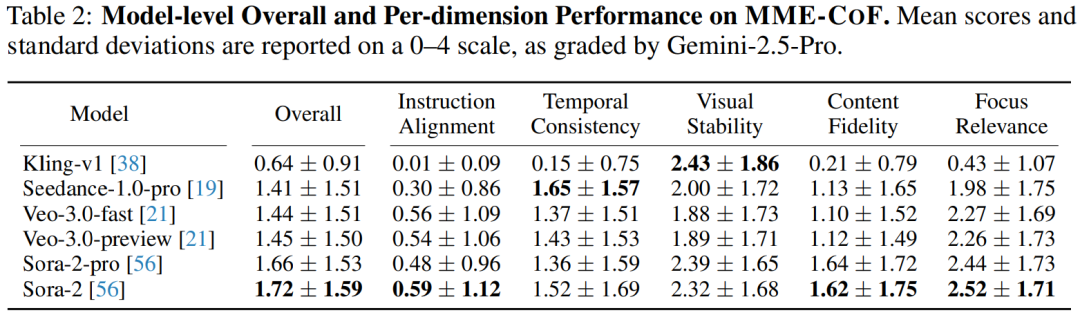
下表展示了多种视频生成模型在 MME-CoF 基准上的评测结果,评分由 Gemini-2.5-Pro 完成,量表范围为 0–4。研究团队从五个维度进行评估。整体来看,各模型的平均得分普遍低于 2 分。
结论:推理还是表演?
综合 Veo 3 的实证分析,基于对众多视频模型的定量评估结果,研究者得出以下结论:
1. 尚不具备独立的零样本推理能力 —— 模型主要依赖数据模式,而非逻辑推演。
2. 强生成 ≠ 强推理 —— 其表现更多来自模式记忆与视觉一致性,而非概念理解。
3. 注重表象而非因果 —— 模型生成的结果往往 “看起来对”,但逻辑上并不成立。
4. 未来仍具潜力 —— 可作为视觉推理系统的有力补充模块,与逻辑模型协同构建更完整的多模态智能体系。
总体而言,这项研究为学界提供了清晰系统的实证分析和评估框架,揭示了视频生成模型在从 “生成” 迈向 “推理”、实现真正的 “通用视觉模型” 的过程中尚需跨越的关键鸿沟。
]article_adlist–>
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

