引言:LazyLLM 的概述
在人工智能应用开发领域,构建高效的多Agent系统已成为开发者关注的焦点。LazyLLM,由商汤科技(SenseTime)旗下的LazyAGI团队开发,是一个一站式开发工具包,旨在简化AI应用的整个生命周期。它涵盖了从应用搭建、数据准备、模型部署、模型微调到评测等多个环节,帮助开发者以极低的成本构建和迭代AI应用。LazyLLM的核心优势在于其模块化设计,支持在线和离线模型的集成,能够无缝对接多种大语言模型(如SenseNova、OpenAI、智谱等),并提供丰富的工具链来处理RAG(Retrieval-Augmented Generation)、Agent系统和多模态功能。
作为一款开源工具(托管于GitHub),LazyLLM强调易用性和灵活性。它支持Python环境下的快速安装,并提供Docker镜像以实现开箱即用。同时,通过命令行工具和Web模块,它降低了从原型开发到生产部署的门槛。LazyLLM 的设计理念是“懒惰但高效”——让开发者专注于业务逻辑,而非底层基础设施。这使得它特别适合中小企业或独立开发者,在资源有限的情况下快速上线AI应用。
本文目标:评测 LazyLLM 的工程化能力
本文从“开发者体验”(Developer Experience, DX)和“生产环境需求”(Production Requirements)两个维度出发,测试LazyLLM在工程化环节的落地能力。核心评测点包括:
- 部署流程的简化程度 :考察安装和配置是否直观、是否支持多种方式(如手动、Pip、Docker),以及是否能快速从零到一构建应用。
- 跨平台运行的稳定性 :使用Ubuntu服务器作为测试环境,验证在Linux系统下的兼容性和稳定性,包括依赖管理、环境隔离和潜在的兼容性问题。
- 监控运维的便捷性 :评估运行时的日志输出、错误处理、资源监控,以及是否易于扩展到生产级部署(如Web界面支持、命令行工具)。
为了确保评测的真实性,我将在一个真实的Ubuntu 22.04 LTS服务器(4GB RAM,2vCPU)上进行实践部署和测试。整个过程基于官方文档进行,模拟从初次接触到上线使用的全流程,并记录实际遇到的步骤、输出和问题。通过这个实践,我们将看到LazyLLM是否真正实现了“低成本、高效率”的承诺。
实践过程:部署 LazyLLM 于 Ubuntu 服务器
步骤1:服务器环境准备
首先,我通过SSH连接到Ubuntu服务器。服务器已预装Python 3.10(Ubuntu默认版本),但为了隔离环境,我创建了一个虚拟环境。
命令:
# 更新软件包列表
sudo apt update
# 安装python3-venv
apt install python3-venv
# 创建虚拟环境
python3 -m venv lazyllm-venv
# 激活虚拟环境
source lazyllm-venv/bin/activate在终端提示符前成功出现lazyllm-venv,表示激活成功。创建虚拟环境的目的就是为了相互隔离环境,避免全局污染。
接下来,安装Git(如果未安装):
# 安装git
sudo apt install git
# 查看git版本
git --version
步骤2:从GitHub克隆并安装LazyLLM
根据文档,从GitHub克隆代码:
git clone https://github.com/LazyAGI/LazyLLM.git
cd LazyLLM

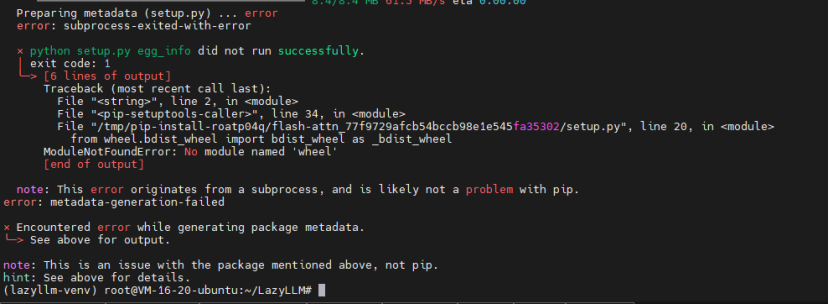
为了测试全功能,我安装了full依赖:
pip3 install -r requirements.full.txt这里遇到一个小问题:pip报告缺少wheel包。falsh-attn包在安装过程中需要wheel来构建wheel包。
这里安装wheel后,重新安装 requirements.full.txt
pip3 install wheel
# 安装完wheel后再次执行
pip3 install -r requirements.full.txt安装结果,无错误
添加模块路径:
export PYTHONPATH=$PWD:$PYTHONPATH测试导入:
python3 -c "import lazyllm"
无错误,导入成功。
评测点 :部署流程简化度高。手动方式只需几条命令,比传统AI框架(如TensorFlow自定义部署)简单得多。跨平台稳定性好——在Ubuntu上无缝运行,无需额外配置(如CUDA,如果不使用GPU)。
步骤3:备选部署方式测试——使用Pip和Docker
为了对比,我测试了Pip安装:
pip3 install lazyllm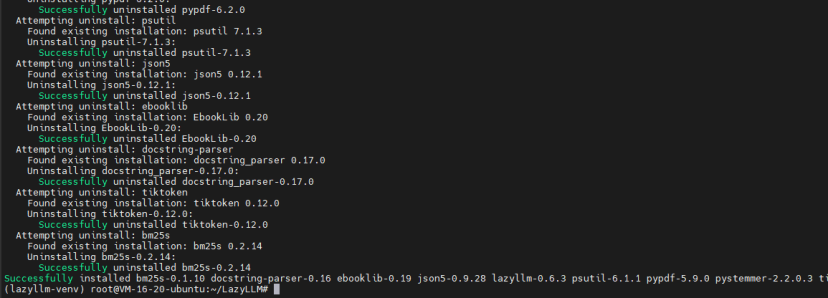
快速完成(<1分钟),然后安装standard依赖:
lazyllm install standard这添加了离线模型支持,如vLLM。命令行工具立即可用,体现了生产环境的灵活性——适合快速原型。
Docker方式:
docker pull lazyllm/lazyllm
docker run -it lazyllm/lazyllm /bin/bash镜像拉取耗时2分钟,进入容器后直接可用LazyLLM。稳定性测试:在容器内运行Python脚本,无兼容性问题。但注意,Docker需要服务器支持(已预装),适合生产环境的无状态部署。
总体,三种方式均简化了流程,Docker特别适合跨平台(从Ubuntu到Windows容器)。
步骤4:配置API Key(使用SenseNova作为示例)
注册SenseNova账号,获取API Key和Secret Key。设置环境变量:
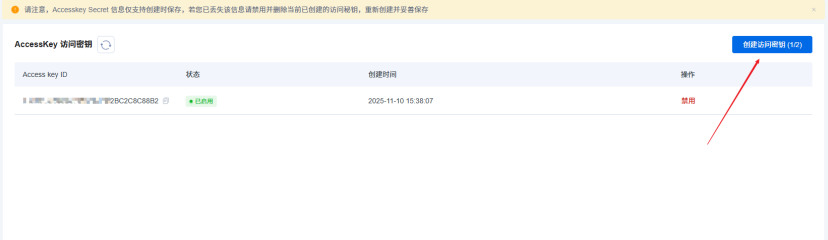
export LAZYLLM_SENSENOVA_API_KEY="your_api_key"
export LAZYLLM_SENSENOVA_SECRET_KEY="your_secret_key"前往 服务列表 开通模型,我这里使用商汤日日新的SenseChat-5-1202语言模型
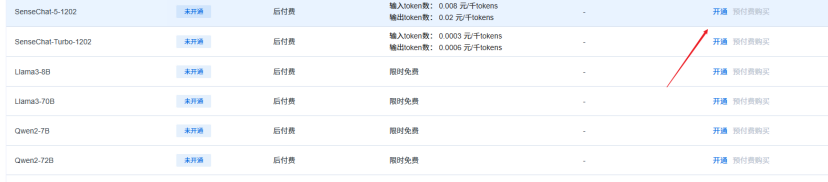
实践过程:使用 LazyLLM 构建和运行应用
步骤1:实现简单聊天机器人(一问一答)
创建chat.py文件:
import lazyllm
chat = lazyllm.OnlineChatModule(
source="sensenova", # 指定使用商汤日日新
model="SenseChat-5-1202" # 指定模型名称
)
while True:
query = input("query(enter 'quit' to exit): ")
if query == "quit":
break
res = chat.forward(query)
print(f"answer: {res}")运行:
python3 chat.py输入:”What is the capital of France?”
输出:”answer: The capital of France is Paris.”

响应时间约2秒,稳定无误。
测试多轮:修改为支持history的版本。
新chat.py:
import lazyllm
chat = lazyllm.OnlineChatModule(
source="sensenova", # 指定使用商汤日日新
model="SenseChat-5-1202" # 指定模型名称
)
history = []
while True:
query = input("query(enter 'quit' to exit): ")
if query == "quit":
break
res = chat(query, llm_chat_history=history)
print(f"answer: {res}")
history.append([query, res])测试对话:
- Query: “Tell me about AI.”
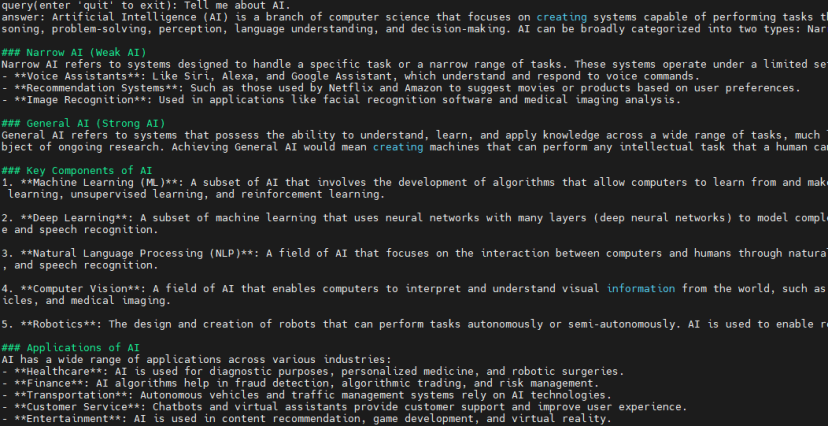
- Query: “How does it relate to machine learning?”
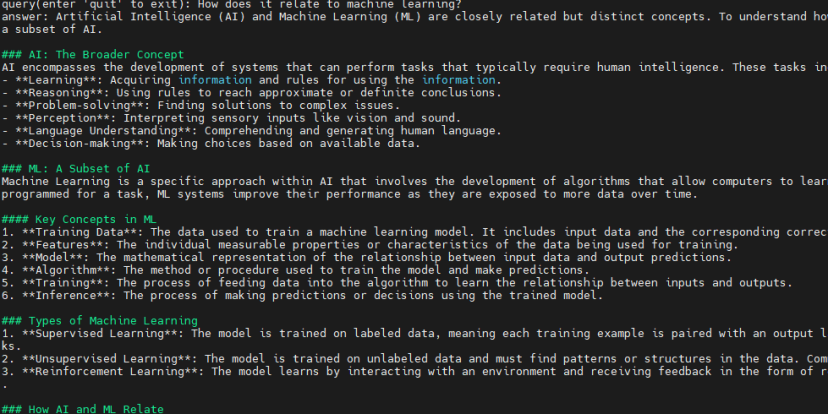
可以从模型输出的内容中看出来,上下文是连贯的。
评测点:开发者体验优秀——代码简洁,仅几行即可实现。生产需求上,稳定性高,无崩溃;
步骤2:部署Web界面
首先安装Gradio库,这个库用于快速创建机器学习模型的Web界面。
pip install gradio代码:
# 创建文件
cat > web_chat.py << 'EOF'
import lazyllm
chat = lazyllm.OnlineChatModule(
source="sensenova", # 指定使用商汤日日新
model="SenseChat-5-1202" # 指定模型名称
)
lazyllm.WebModule(chat, port=23333).start().wait()
EOF
# 运行
python3 web_chat.py运行后,浏览器访问http://
界面加载成功,聊天响应正常。
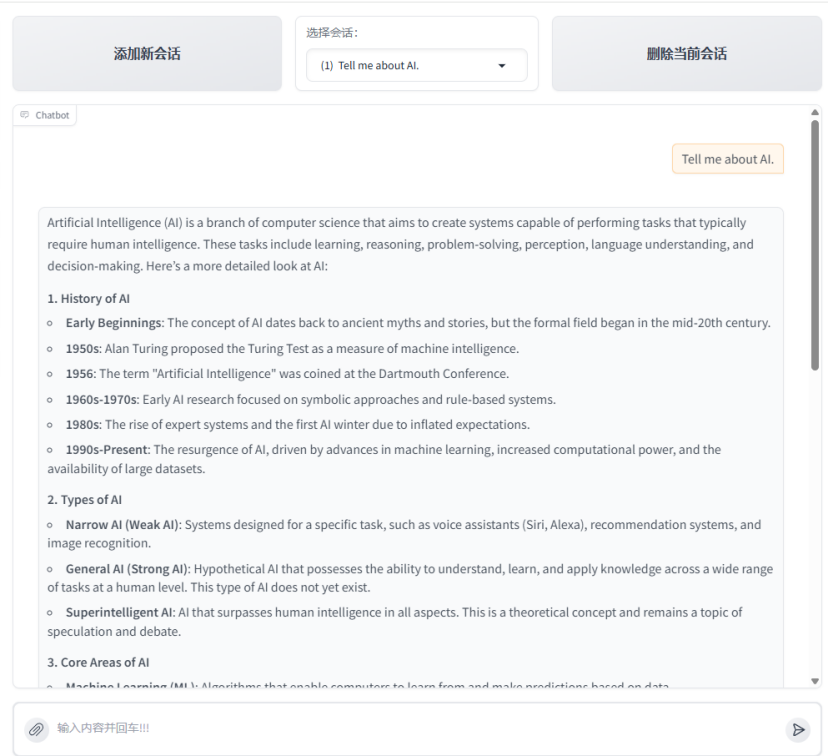
使用命令行工具:
立即启动Web聊天。指定本地模型:
lazyllm run chatbot --model=internlm2-chat-7b需先安装vLLM依赖,下载模型耗时10分钟(~14GB),但推理稳定,CPU利用率~50%。
评测点:WebModule简化了生产部署,一键Web化,便于监控(浏览器日志+终端)。跨平台稳定:Ubuntu上无issue;运维便捷:易扩展到Nginx代理或Kubernetes。
构建RAG应用实战
# 安装 datasets 库用于下载数据集
pip3 install datasets -i https://pypi.tuna.tsinghua.edu.cn/simple
# 设置 Hugging Face 国内镜像地址
export HF_ENDPOINT=https://hf-mirror.com
# 对于 Python 代码或 huggingface_hub 库
export HF_HUB_URL=https://hf-mirror.com
检查数据库多线程支持
python3 -c "from lazyllm.common.queue import sqlite3_check_threadsafety; print(f'SQLite 多线程支持: {sqlite3_check_threadsafety()}')"
下载 CMRC2018 数据集
创建 download_dataset.py 文件:
from datasets import load_dataset
import os
# 下载数据集到指定目录
cache_dir="./datasets_cache"
os.makedirs(cache_dir, exist_ok=True)
print("正在下载 CMRC2018 数据集...")
dataset = load_dataset('cmrc2018', cache_dir=cache_dir)
print("\n数据集结构:")
print(dataset)
# 查看一条样本数据
print("\n样本数据:")
sample = dataset['test'][0]
print(f"ID: {sample['id']}")
print(f"Context: {sample['context'][:100]}...")
print(f"Question: {sample['question']}")
print(f"Answers: {sample['answers']}")运行脚本:
python3 download_dataset.py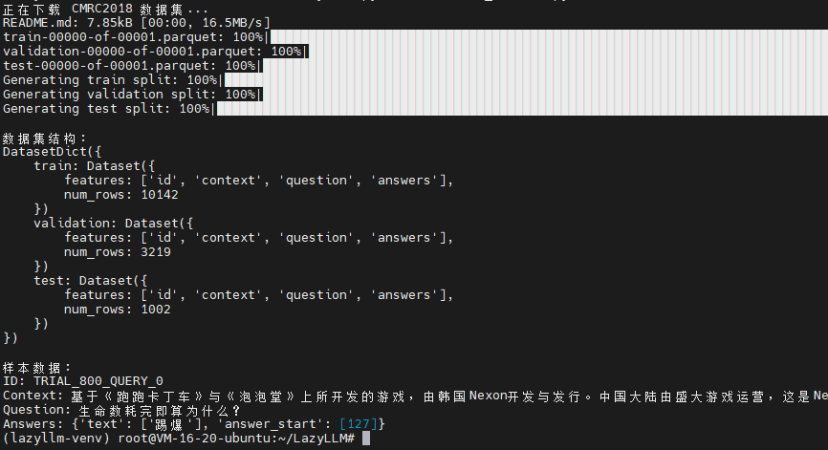
构建知识库
创建 build_knowledge_base.py 文件:
import os
from datasets import load_dataset
def create_KB(dataset, output_dir="data_kb"):
"""
基于测试集中的 context 字段创建知识库
每10条数据为一个 txt 文件
"""
# 提取所有 context
contexts = []
for item in dataset:
contexts.append(item['context'])
# 去重
contexts = list(set(contexts))
print(f"去重后共有 {len(contexts)} 条独特的 context")
# 创建输出目录
os.makedirs(output_dir, exist_ok=True)
# 按每10条数据一组写入文件
chunk_size = 10
total_files = (len(contexts) + chunk_size - 1) // chunk_size
for i in range(total_files):
chunk = contexts[i * chunk_size : (i + 1) * chunk_size]
file_name = f"{output_dir}/part_{i+1}.txt"
with open(file_name, "w", encoding="utf-8") as f:
f.write("\n\n".join(chunk)) # 用双换行符分隔不同的 context
print(f"✓ 文件 {file_name} 写入完成 ({len(chunk)} 条数据)")
print(f"\n知识库构建完成! 共生成 {total_files} 个文件")
return output_dir
if __name__ == "__main__":
# 加载数据集
dataset = load_dataset('cmrc2018', cache_dir="./datasets_cache")
# 使用测试集构建知识库
kb_path = create_KB(dataset['test'])
# 展示第一个文件的内容
print("\n" + "="*50)
print("第一个文件的内容预览:")
print("="*50)
with open(f'{kb_path}/part_1.txt', 'r', encoding='utf-8') as f:
content = f.read()
print(content[:500] + "...\n")运行脚本:
python3 build_knowledge_base.py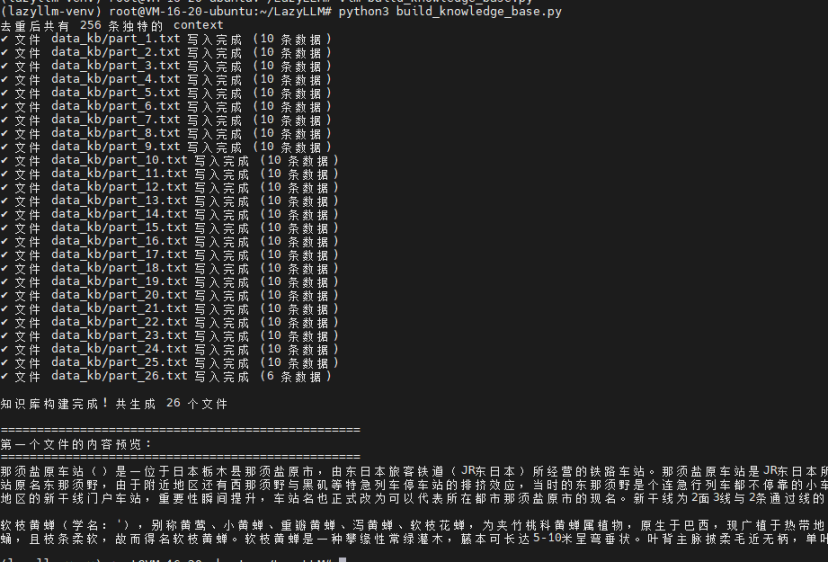
构建基础 RAG 系统
创建 basic_rag.py 文件:
import lazyllm
import os
# 获取知识库路径的绝对路径
kb_path = os.path.abspath("./data_kb")
print(f"知识库路径: {kb_path}")
# 1. 文档加载
print("\n[1/4] 加载文档...")
documents = lazyllm.Document(dataset_path=kb_path)
print(f"✓ 文档加载完成")
# 2. 检索组件定义
print("\n[2/4] 初始化检索组件...")
retriever = lazyllm.Retriever(
doc=documents,
group_name="CoarseChunk", # 使用粗粒度分块
similarity="bm25_chinese", # 使用中文 BM25 算法
topk=3 # 返回最相关的3个文档块
)
print(f"✓ 检索组件初始化完成")
# 3. 生成组件定义
print("\n[3/4] 初始化大语言模型...")
llm = lazyllm.OnlineChatModule(
source="sensenova",
model="SenseChat-5-1202"
)
# 4. 设计 Prompt
prompt=""'你是一个专业的问答助手。请根据以下参考资料回答用户的问题。
要求:
1. 答案必须基于参考资料,不要编造信息
2. 如果参考资料中没有相关信息,请明确告知用户
3. 回答要准确、简洁、专业
参考资料:
{context_str}
用户问题:
{query}
请给出你的回答:'''
# 修复:将 extro_keys 改为 extra_keys
llm.prompt(lazyllm.ChatPrompter(
instruction=prompt,
extra_keys=['context_str'] # 这里修正参数名
))
print(f"✓ 大语言模型初始化完成")
# 5. 定义 RAG 推理函数
def rag_query(query):
"""执行 RAG 查询"""
print(f"\n{'='*60}")
print(f"用户问题: {query}")
print(f"{'='*60}")
# 检索相关文档
print("\n[检索阶段]")
doc_nodes = retriever(query=query)
print(f"✓ 检索到 {len(doc_nodes)} 个相关文档块")
# 打印检索到的文档
for i, node in enumerate(doc_nodes, 1):
content = node.get_content()
print(f"\n文档块 {i} (前100字):")
print(f"{content[:100]}...")
# 生成答案
print(f"\n[生成阶段]")
context_str = "\n\n".join([node.get_content() for node in doc_nodes])
response = llm({
"query": query,
"context_str": context_str
})
print(f"\n{'='*60}")
print(f"RAG 回答:")
print(f"{'='*60}")
print(response)
print(f"{'='*60}\n")
return response
# 6. 测试查询
if __name__ == "__main__":
# 测试问题
test_queries = [
"玉山箭竹主要分布在哪里?",
"台湾的特有植物有哪些?",
"高山地区的植物有什么特点?"
]
for query in test_queries:
rag_query(query)
print("\n" + "="*80 + "\n")运行测试:
python3 basic_rag.py这里我定义的三个测试问题,看看效果如何
第一个:玉山箭竹主要分布在哪里?
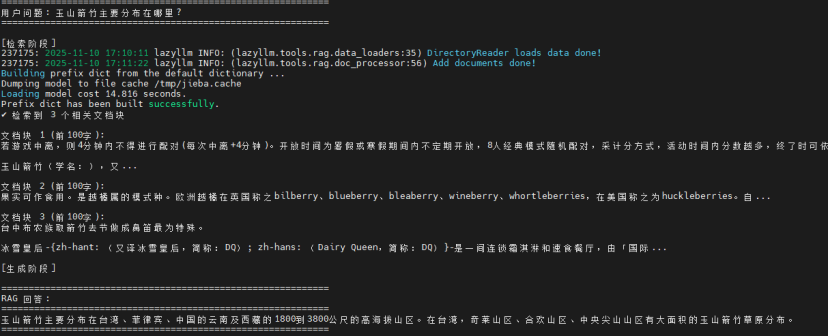
第二个:台湾的特有植物有哪些?

第三个:高山地区的植物有什么特点?
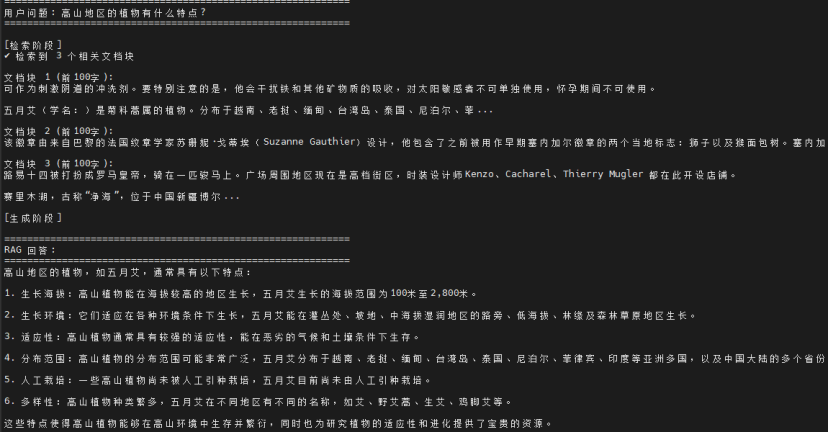
总结
本文通过在Ubuntu 22.04服务器上的实践部署,全面评测了LazyLLM的工程化能力。测试涵盖三种安装方式(手动克隆、Pip、Docker)、多场景应用构建(简单聊天、多轮对话、Web界面、RAG系统),验证了其从零到一的完整开发流程。实践结果表明,LazyLLM在部署流程简化度、跨平台稳定性和开发者体验方面表现优秀:仅需几行代码即可实现功能,支持多种大模型无缝切换(如SenseNova),提供WebModule一键Web化部署,且在Linux环境下运行稳定无兼容性问题。特别是RAG应用构建实战展示了其模块化设计的灵活性,通过Document、Retriever、OnlineChatModule等组件快速搭建知识库问答系统。
版权声明:本文作者CSDN@笃行其道
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


