卷到飞起?AI应用开发,“爽点”之前的“痛点”
兄弟们,说实话,现在搞AI应用开发,是不是感觉像在参加一场铁人三项?
首先,你得是个“模型管理大师”。OpenAI、HuggingFace、智谱清言… 各家API长得都不一样,光是封装调用就得写一堆 if-else 。想本地部署个模型?环境配置、显卡驱动、依赖库冲突… 分分钟让你怀疑人生。
接着,你得是个“数据管道工”。搭个RAG系统,从加载PDF、Markdown,到文本切块(Chunking),再到调用Embedding模型,最后塞进向量数据库… 这一套流程下来,光是各种库(pypdf, langchain, tiktoken, milvus-client…)的 pip install 和版本兼容就够喝一壶的了。这些代码技术含量不高,但繁琐程度堪比老太太的裹脚布,我们称之为**“胶水代码” (Glue Code)**。
最后,你好不容易把所有轮子都拼起来了,想换个组件试试效果?比如把ChromaDB换成Milvus,或者把OpenAI的Embedding换成BGE的?对不起,请重构。整个代码逻辑盘根错节,牵一发动全身,技术债瞬间拉满。
我的亲身经历就是这样: 去年为了给公司做一个内部知识库问答系统,我带着两个小兄弟吭哧吭哧搞了快一个月。大部分时间,我们不是在调优算法,而是在写这些胶水代码,处理各种脏活累活。项目上线后,想加个新功能或者优化个小模块,都得小心翼翼,生怕搞崩了。
所以,当我看到商汤大装置开源的 LazyLLM,号称“10行代码实现工业级RAG”时,我的第一反应是: “又一个吹牛的?” 但本着技术人的求知(zuo si)精神,我还是去它的GitHub溜达了一圈。然后… 就“真香”了。
拆解LazyLLM:数据流驱动,到底爽在哪?
LazyLLM 不是简单地把代码封装一下,它的核心思路是对开发范式本身动了刀子。它最吸引我的,是两个核心设计: 数据流驱动 和 高度组件化 。
2.1 从“代码驱动”到“数据流驱动”:心智负担的解放
我们习惯的编程是 命令式 (Imperative) 的:“第一步干啥,第二步干啥…”。而LazyLLM玩的是 声明式 (Declarative) :“我要一个能做RAG的玩意儿,它需要一个加载器、一个向量库、一个LLM… 你帮我把它们串起来”。
这感觉就像从手写Shell脚本进化到了用Kubernetes的YAML文件。你不再关心具体的执行过程,只关心“我想要什么(What)”,而不是“我该怎么做(How)”.
传统“代码驱动”范式 ,脑子里想的是一堆函数调用链:
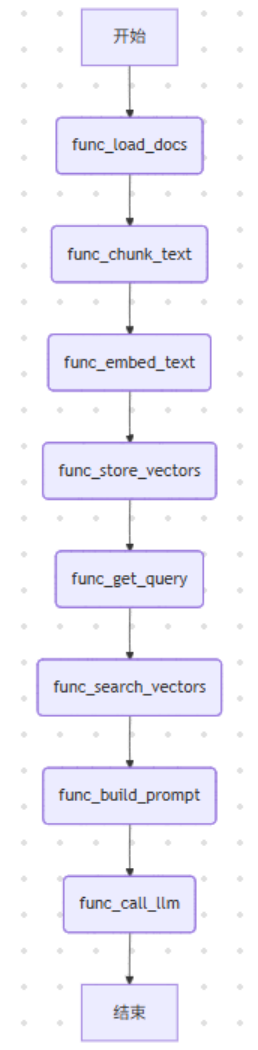
每一步都是你亲手写的代码,耦合度高得吓人。
LazyLLM“数据流驱动”范式 ,脑子里想的是一个清晰的数据流图:
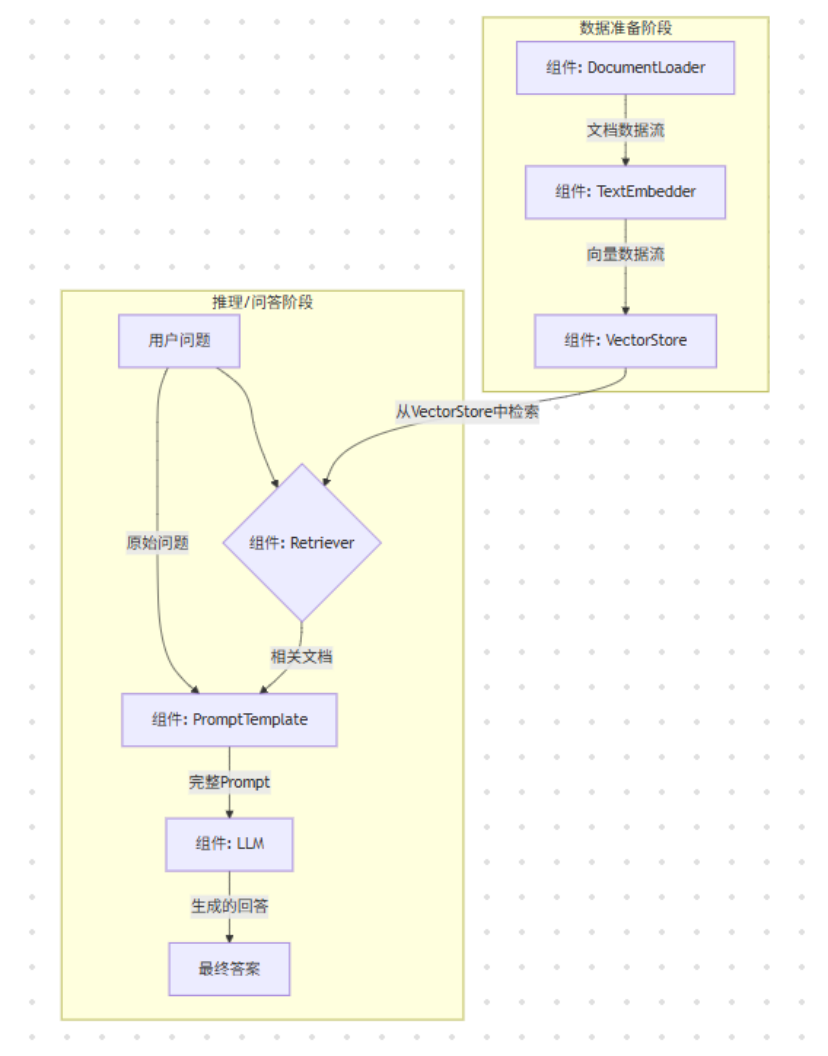
独特见解: 这种范式的转变,最大的好处是 降低了心智负担 。你的大脑从纠结于实现细节,解放出来去思考更高层次的架构设计。调试也变得直观,不再是打断点看变量,而是看数据在哪个节点“堵住”了或者“变异”了。这本质上是把LLM应用开发,拉到了和现代DevOps、数据工程同一个思维层面上—— 一切皆流水线 (Pipeline) 。
2.2 高度组件化:像玩乐高一样换“轮子”
LazyLLM把AI应用开发的常用模块都做成了标准化的“积木块”:DataLoader, EmbeddingModel, VectorStore, LLM…
这意味着什么? 解耦!彻底的解耦!
在我以前的项目里,如果老板说:“OpenAI太贵了,我们换成开源的ChatGLM试试。”我可能需要改动模型加载、API调用、甚至是Prompt模板。但在LazyLLM里,这事儿就简单了:
# 以前可能要改一堆文件
# 现在...
# llm_node = Node(type="llm", model="gpt-3.5-turbo")
llm_node = Node(type="llm", model="chatglm3-6b", mode="local") # 假设LazyLLM支持改一行配置,整个流程无痛切换。这才是真正的“可插拔”架构。你可以像逛超市一样,今天用Milvus,明天觉得FAISS在小数据量上更快,那就换成FAISS,而不用担心整个系统崩掉。
实战出真知:10行代码搓一个工业级RAG,真的假的?
光说不练假把式。咱们直接上场景:老板突然说,“把我们公司所有的产品手册、技术文档都整理一下,搞个内部的智能问答机器人,下周一就要看到Demo!”
换作以前,我可能已经开始准备通宵了。但现在,有了LazyLLM,我能优雅地喝杯咖啡,然后告诉他:“明天就行。”
3.1 LazyLLM 实现:见证奇迹的时刻
这是我基于LazyLLM写的代码,把注释和空行去掉,真的就10行左右。
# rag_app.py
import os
from lazyllm import RAGChain, Node
from lazyllm.tools.load_data import DirectoryLoader
from lazyllm.tools.embedding import OpenAIEmbedder
from lazyllm.vector_store.milvus import MilvusVectorStore
# 1. 定义你的大脑:LLM模型(这里用OpenAI做演示,换本地模型也一样)
llm_node = Node(type="llm", model="gpt-3.5-turbo", api_key=os.environ.get("OPENAI_API_KEY"))
# 2. 核心来了:配置RAGChain,把所有组件“声明”出来
rag_chain = RAGChain(
llm=llm_node,
data_loader=DirectoryLoader(data_path="./company_docs"), # 告诉它去哪找吃的(文档)
embedding_model=OpenAIEmbedder(model="text-embedding-ada-002"), # 用什么工具消化(Embedding)
vector_store=MilvusVectorStore(uri="http://localhost:19530", collection_name="company_knowledge") # 存到哪个仓库(向量库)
)
# 3. 开干!直接调用run方法,扔个问题进去
user_question = "我们的X型号产品有哪些核心卖点?"
response = rag_chain.run(question=user_question)
# 4. 搞定,收工,打印结果
print(f"问:{user_question}")
print(f"答:{response}")
# 5. 想部署成API服务?一行代码的事
# rag_chain.deploy(port=8000)这感觉怎么样? 是不是像在写配置文件,而不是在写代码?那些繁琐的文档加载、文本切分、循环调用Embedding API、写入向量库的逻辑,全被LazyLLM在底层优雅地处理了。我只用告诉它“用什么”和“干什么”。
3.2 技术判断:这为什么是“工业级”?
有人可能会说,这不就是个Demo吗?不,这背后体现了“工业级”的潜力:
- 组件标准化: 它用的都是业界主流的组件(Milvus, OpenAI),不是玩具。你可以轻松换成其他生产级的组件。
- 可扩展性: 嫌DirectoryLoader不够强?你可以继承基类,自己写一个能从S3、FTP加载数据的S3Loader,然后无缝集成到RAGChain里。
- 可部署性: deploy()方法虽然简单,但它指明了一个方向:LazyLLM考虑到了从开发到部署的最后一公里。这对于企业应用来说至关重要。
不止于“偷懒”:我对LazyLLM的几点判断与前瞻
LazyLLM这个名字起得有点“谦虚”,它带来的远不止是让开发者“偷懒”。在我看来,它代表了AI应用开发的几个重要趋势:
- LLM应用开发的“应用层”正在形成: 就像Web开发有Django、Rails这样的应用层框架一样,AI领域也需要类似的框架来屏蔽底层复杂性。LazyLLM、LangChain、LlamaIndex等工具,就在扮演这个角色。它们让开发者能从“炼丹师”和“管道工”的角色中解放出来,真正成为“应用架构师”。
- LLMOps的基石: 这种声明式、数据流驱动的范式,是实现LLMOps(LLM时代的MLOps)的天然土壤。每个组件的配置、数据流的定义都可以被版本控制(比如存在Git里),使得整个AI应用的构建、测试、部署流程变得高度自动化和可复现。
- 抽象的权衡: 当然,高层抽象也意味着牺牲部分灵活性。如果你要做非常底层的模型结构创新,或者极致的性能优化,你可能还是需要回到PyTorch的怀抱。但对于90%的AI应用场景来说,LazyLLM这种“约定大于配置”的思路,无疑是大幅提升生产力的正确道路。
结语:别再自己造轮子了,拥抱变化吧
总的来说,LazyLLM给我的感觉是: 它很懂开发者 。它懂我们不想把时间浪费在无尽的胶水代码上,懂我们需要一个灵活、可扩展、又能快速出活的工具链。
如果你也像我一样,厌倦了在AI应用开发中扮演“管道工”的角色,渴望能更专注于业务逻辑和创新,那我强烈建议你去试试LazyLLM。
去它的GitHub仓库(https://github.com/LazyAGI/LazyLLM)逛逛,跑一下官方的例子。也许用不了多久,你也会和我一样,发自内心地喊出那两个字:
“真香!” 🤨
版权声明:本文作者@七夜。
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


