
<blockquote> 小米早在 2019 年便引入 Apache Doris 作为 OLAP 分析型数据库之一,经过五年的技术沉淀,已形成以 Doris 为核心的分析体系,并基于 2.1 版本异步物化视图、3.0 版本湖仓一体与存算分离等核心能力优化数据架构。本文将详细介绍小米数据中台基于 Apache Doris 3.0 的查询链路优化、性能提升、资源管理、自动化运维、可观测等一系列应用实践。
小米集团成立于 2010 年,是一家以智能手机、智能硬件和 IoT 平台为核心的全球领先科技企业,业务遍及全球 100 多个国家和地区。小米构建了全球最大的消费类 IoT 物联网平台,同时持续推进“手机×AIoT”战略。旗下产品涵盖智能手机、电视、笔记本、可穿戴设备及生态链智能产品,并投资孵化众多智能科技企业。
Apache Doris 在小米内部应用广泛,业务涵盖汽车、手机领域(包括手机系统应用与硬件制造)、互联网、线上线下销售与服务、底层平台以及新业务等多个领域,支撑着多样化的数据分析需求。目前,Doris 集群数量超过 40 个,管理数据规模数 PB,日均查询量达到 5000 万次,资源规模在近一年内增长约 80%,展现出快速发展的态势。

小米数据中台 OLAP 发展与挑战
01 架构演变历程
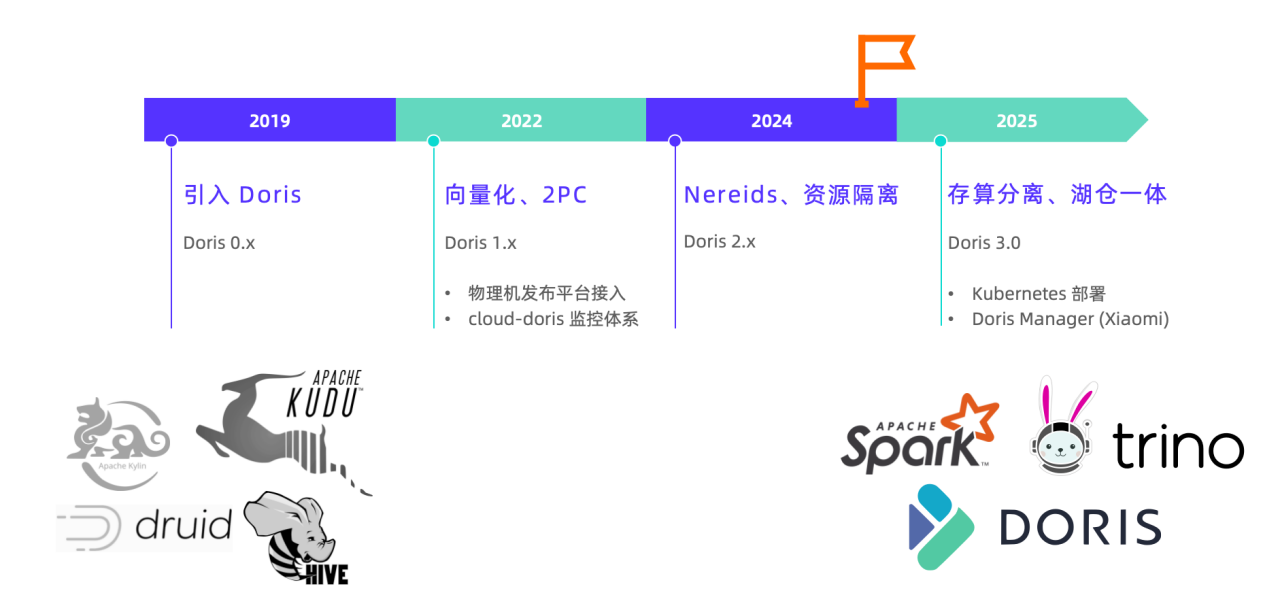
早期小米技术栈复杂多样,数据湖体系与 OLAP 引擎众多。自 2019 年在小米内部投入应用以来,Apache Doris 逐渐从中脱颖而出,发展成为小米数据架构的核心引擎。
一方面,Apache Doris 整合了内部复杂的 OLAP 分析体系,统一承载起原本由多系统分散提供的查询能力;另一方面,Doris 凭借出色的查询性能与良好的生态兼容,配合 Trino、Spark、Iceberg、Paimon 等完成了从外仓到湖仓一体架构的关键升级。
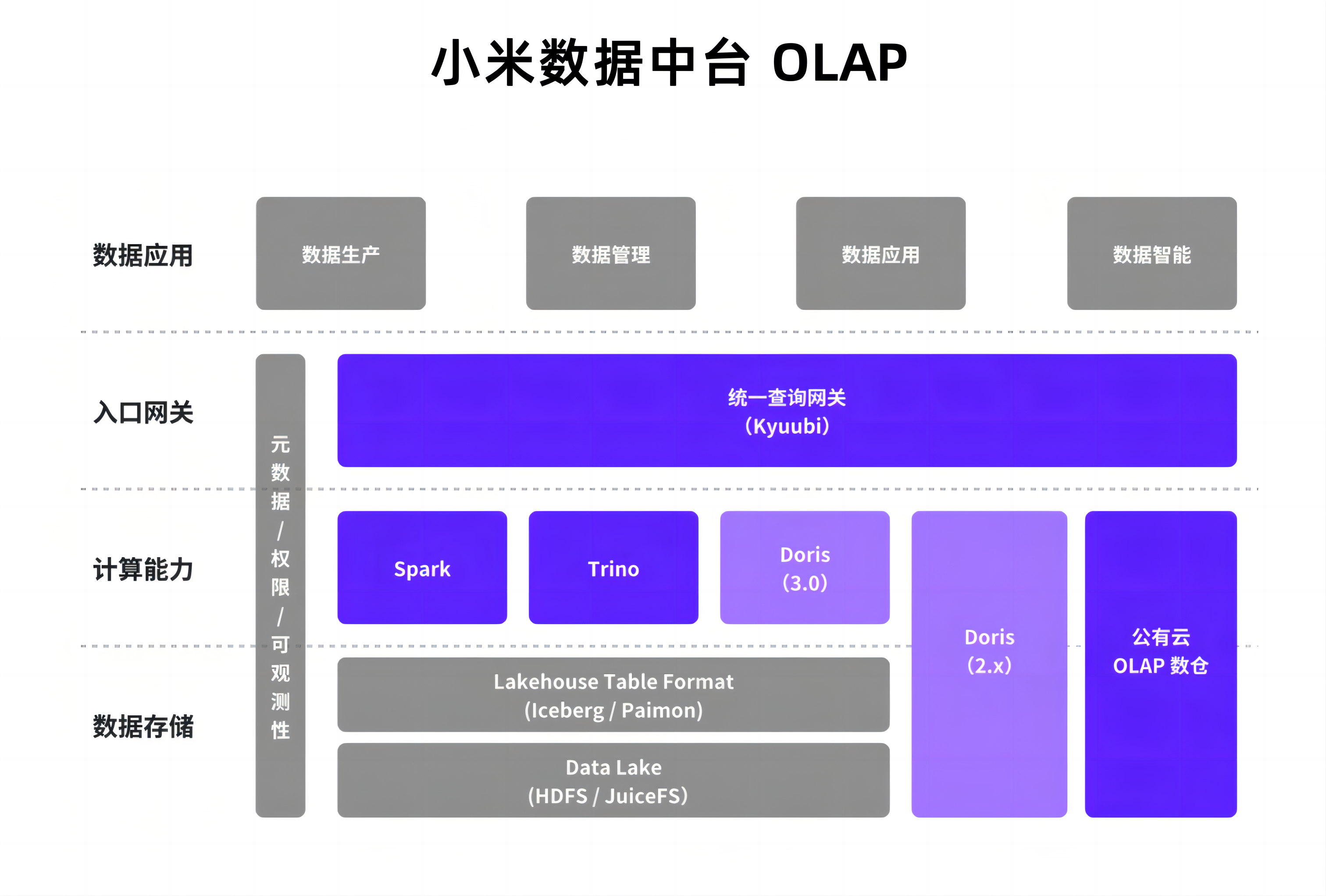
2022 年起,Doris 在小米内部已形成了较为成熟的应用体系:依托内部发布平台,在物理机上实现集群的自动化部署与运维;同时接入内部监控体系,全面保障 Doris 集群的可观测性与稳定性。
2025 年,我们正式引入了湖仓一体与存算分离能力成熟的 Doris 3.0 稳定版本,与 2.1 版本并行运行,并针对 Doris 3.0 在管理层面进行了重大调整:引入集群编排系统,并基于 Doris Manager 自主开发了集群管理系统,提供更全面、标准化的运维与可观测性方案。
02 外仓面临的挑战
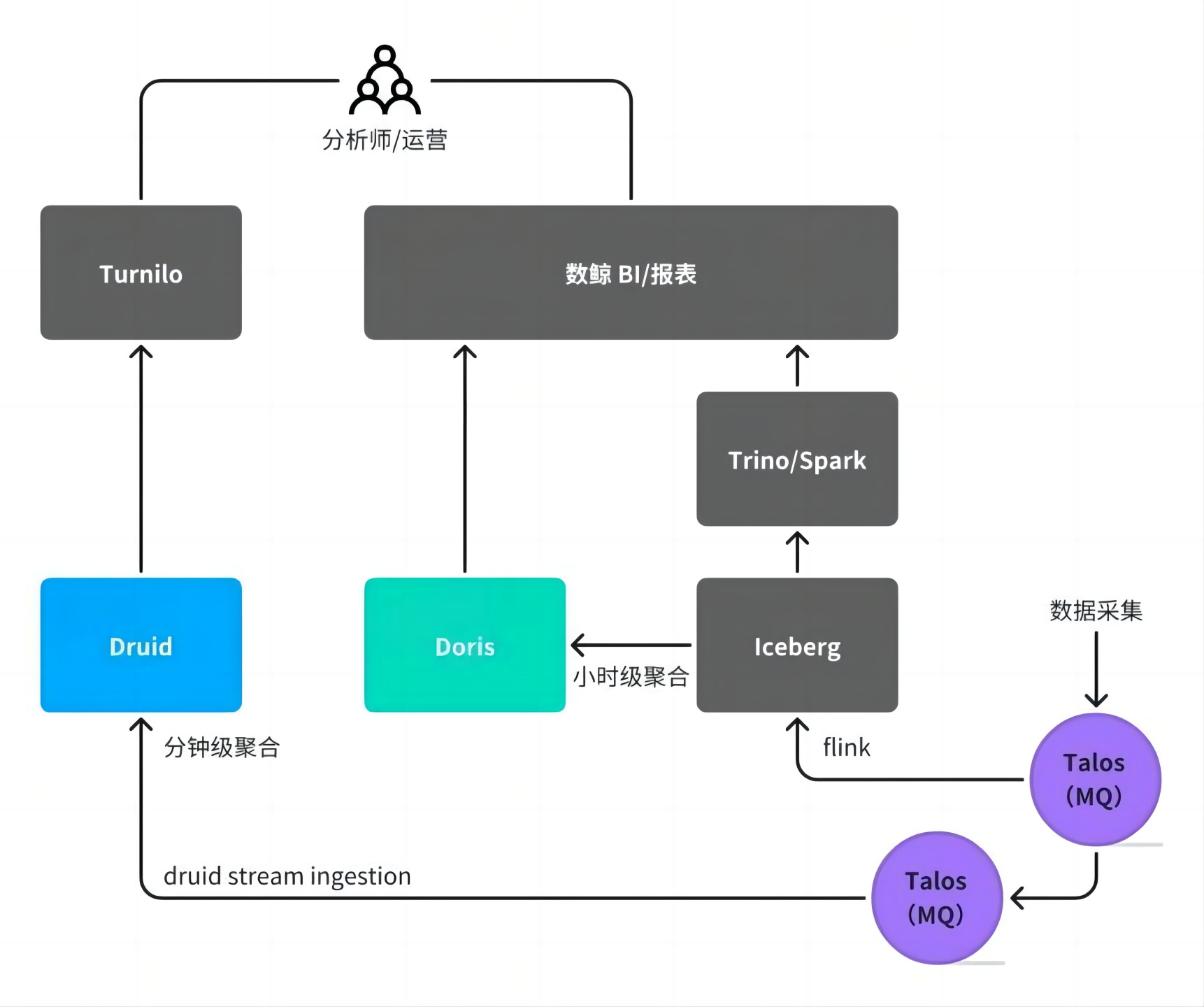
小米早期 OLAP 体系中,离线数仓视为“内仓”,而 OLAP 服务则归为“外仓”,内外仓的数据流动依赖 Flink 或 Spark 等数据集成工具。团队主要负责 Doris 集群的部署与日常运维,在此过程中,我们遇到了诸多来自用户和自身的痛点问题,下面将结合业务场景介绍。
跨系统数据集成
数据通过 Flink 或 Spark 从离线的内仓抽取至 Doris,形成跨系统数据流动。这种模式带来一系列挑战:
- 数据冗余:同一份数据在多个系统中存储,增加成本;
- 口径不一致:不同系统处理逻辑差异导致结果偏差;
- 排查困难:当 BI 看板数据出现差异时,需跨多个系统定位问题;
- 开发负担重:业务方需自行维护 ETL 链路和多套查询接口。
以广告业务为例,其数据链路涉及多个存储系统(如 Iceberg、Druid)和同步任务,分析师需根据查询粒度选择不同系统,心智负担显著。对开发侧而言,需针对不同数据链路进行定制化开发,同时在多个系统上重复建设数据看板,导致开发工作重复、周期长,整体投入成本较高。
存算一体架构局限
1、高可用容灾
2023 年海外机房火灾事件暴露了存算一体架构的脆弱性,虽然数据最终恢复,但也促使团队重新审视数据高可用策略。针对 Doris 2.x 的高可用方案,团队曾评估两种路径:
- 主从复制(CCR):依赖较新版本支持,缺乏生产验证,主备切换复杂,客户端需双连,恢复时间长;
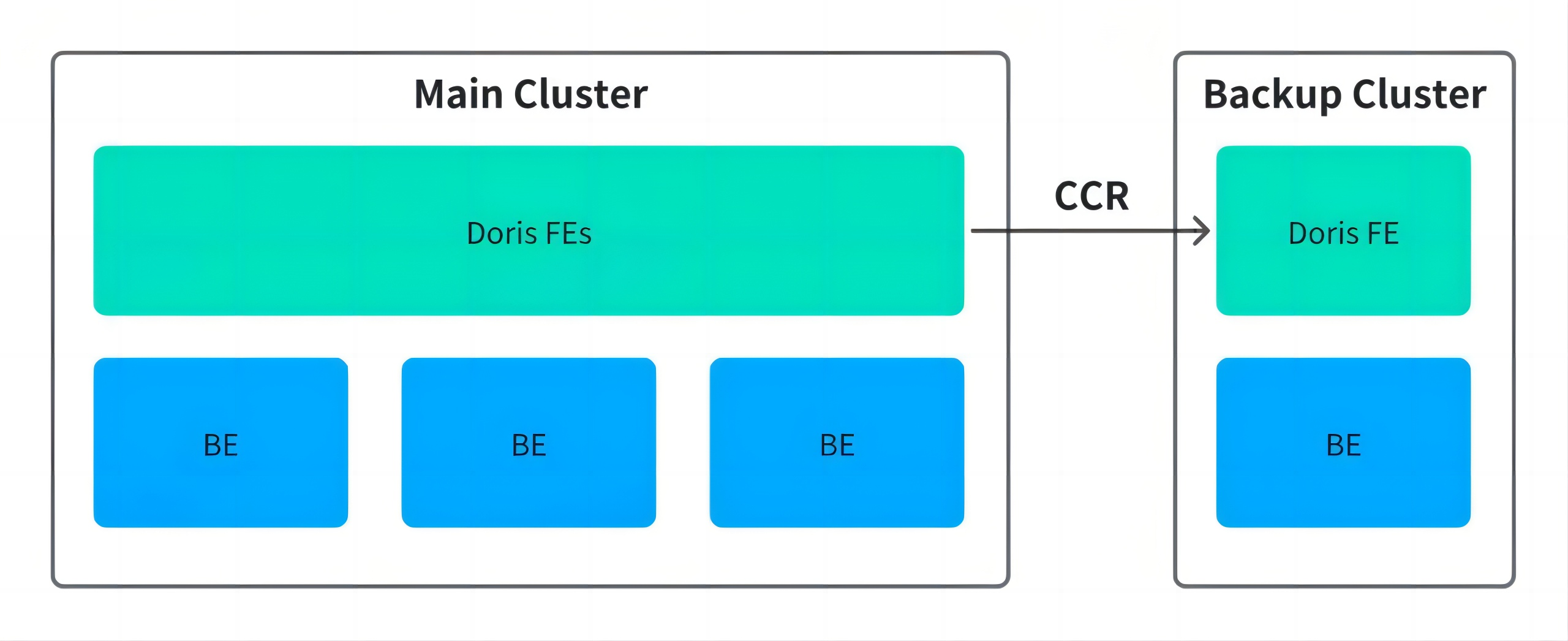
- 跨可用区副本分布:通过 Resource Group 将副本分散至不同机房,虽可避免单点故障,但跨机房读写带来性能损耗。
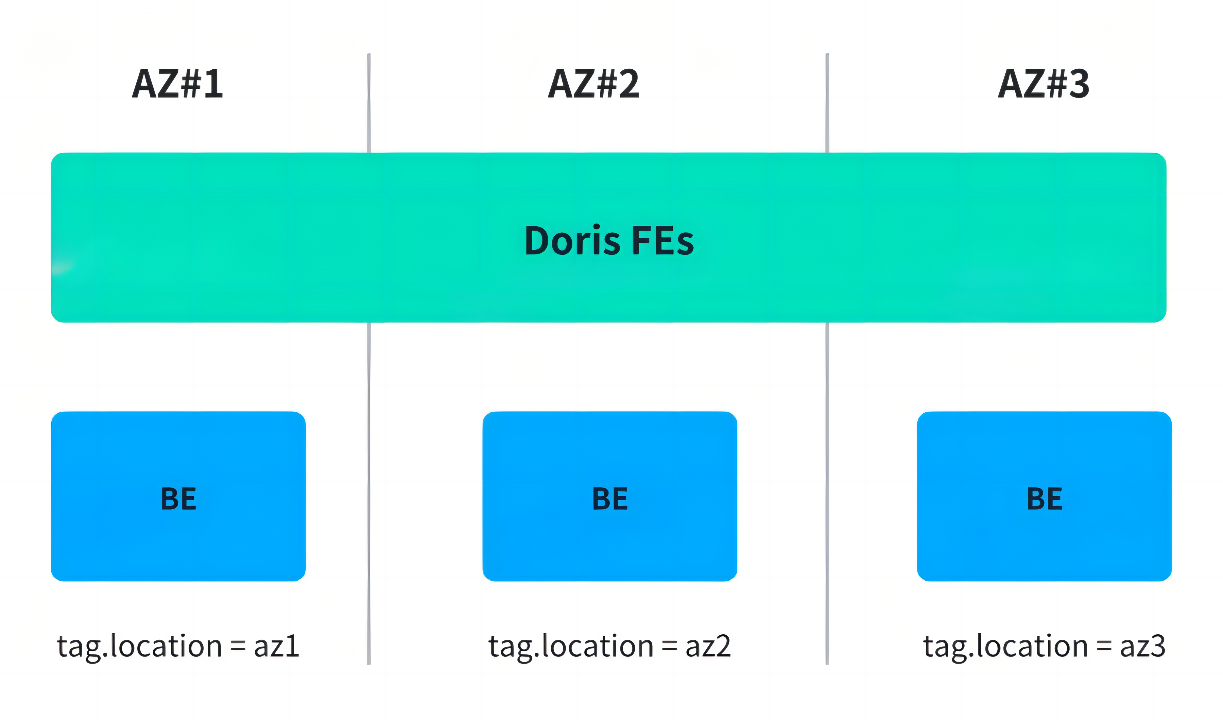
最终采用后者作为临时方案,但仍未根本解决成本与可用性之间的矛盾。
2、资源利用率低
物理机部署模式下,构建一个高可用 Doris 集群需要 3 FE + 3 BE,对于中小规模业务而言,此配置远超实际需求,导致资源浪费严重。若为每个小业务独立建集群,将导致集群数量激增,运维压力剧增;若采用共享集群,则面临资源争抢、隔离困难、计费模糊等问题。
直到 Apache Doris 3.0 发布后引入存算分离版本,高可用容灾与资源弹性问题得到解决,下个章节将详细展开介绍。

集群运维效率低
原有基于物理机的手动部署流程,从申请资源到集群上线通常耗时一周以上。面对快速增长的业务需求,该模式已无法满足敏捷交付要求。
Apache Doris 3.0 应用实践与突破
基于上述挑战,Doris 2.0 及早期版本在湖仓一体、存算分离、集群自动化运维等方面仍有不足,而 3.0 存算分离版本带来了诸多升级,经过一段时间的验证,团队规划出 3.0 版本与早期版本并行的升级架构,并在 3.0 版本的基础上对架构设计与使用模式进行了显著优化。
01 Doris 3.0 核心优势
首先是 3.0 存算分离的部署模式,其主要依赖计算组进行资源隔离通过将计算层与存储层解耦,BE 节点实现无状态化,依托底层 Kubernetes 支持,可以实现快速弹性伸缩以满足不同体量用户的需求。
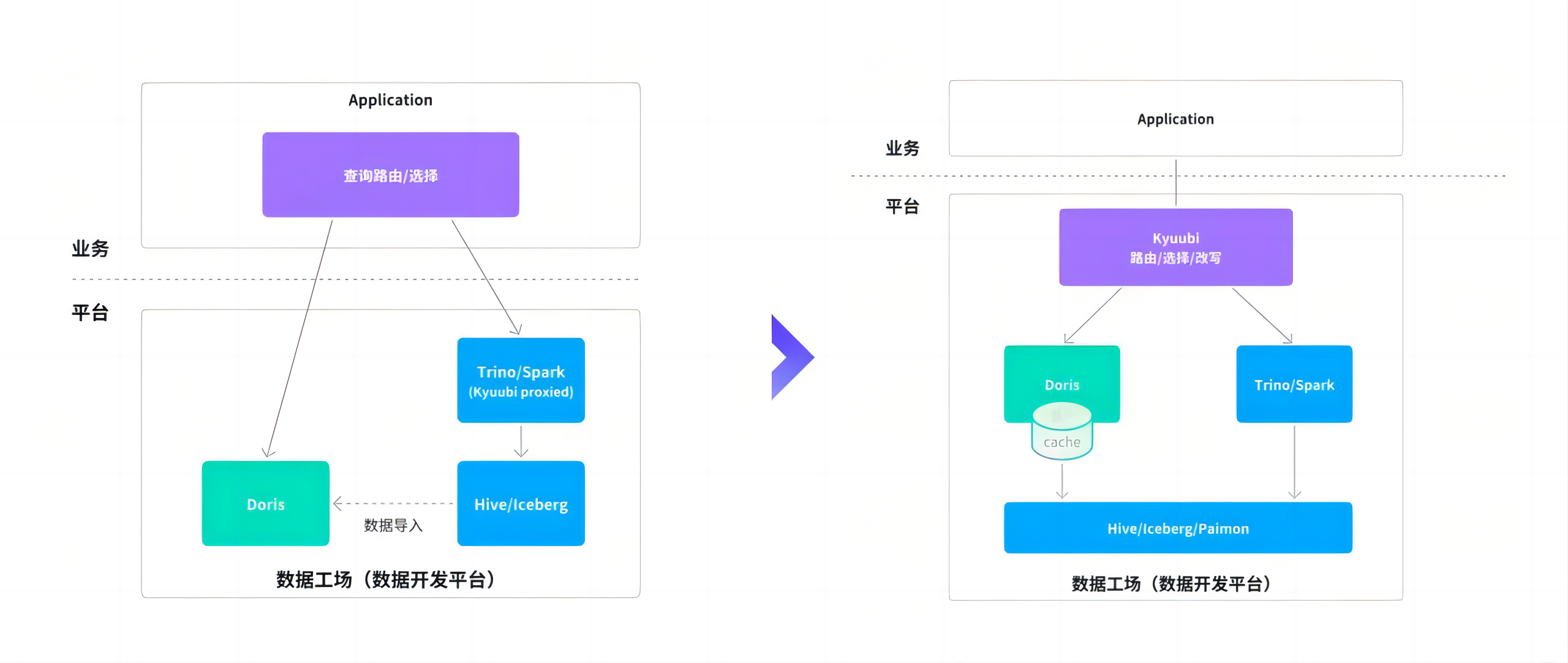
同时,Doris 原生支持湖仓查询能力,在存算分离模式下,能够直接访问外部数据湖,有效打通数据孤岛。这一特性不仅显著简化了传统数据链路,也减少了因多层复制带来的数据冗余,真正推动湖仓一体架构的落地实践。
基于此,数据开发平台的整体架构发生变化:Doris 不再局限于传统“外仓”的角色,而是向上演进为统一的查询引擎层,与底层 Iceberg、Paimon 等湖仓格式解耦,直接进行联邦查询,同时利用自身的数据缓存、物化视图等能力对热点数据进行加速,兼顾灵活性与高性能。
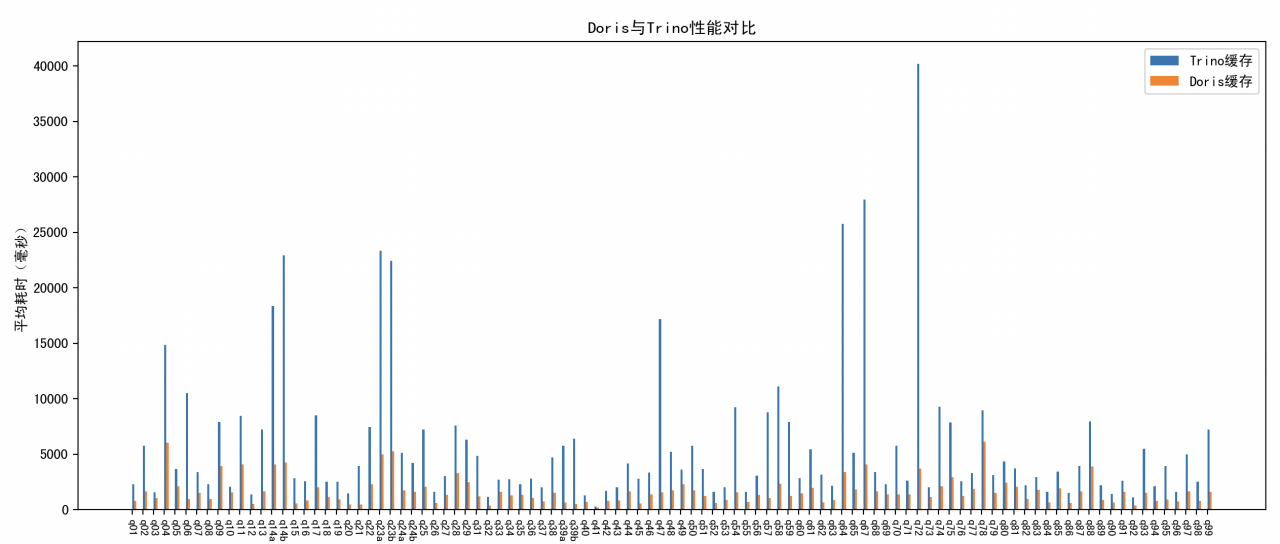
Doris vs Trino 湖仓分析能力对比:全面领先
在 TPC-DS 1TB 标准测试中,Doris 对比 Trino 在整体查询性能上展现出全面领先的优势。无论是复杂多表关联、聚合分析,还是高并发场景下的响应效率,Doris 均表现出更优的执行速度和资源利用率,平均查询耗时明显更低,尤其适用于对查询性能要求较高的实时分析场景。
- TPC-DS 1T 测试:Doris 对比 Trino 全面领先
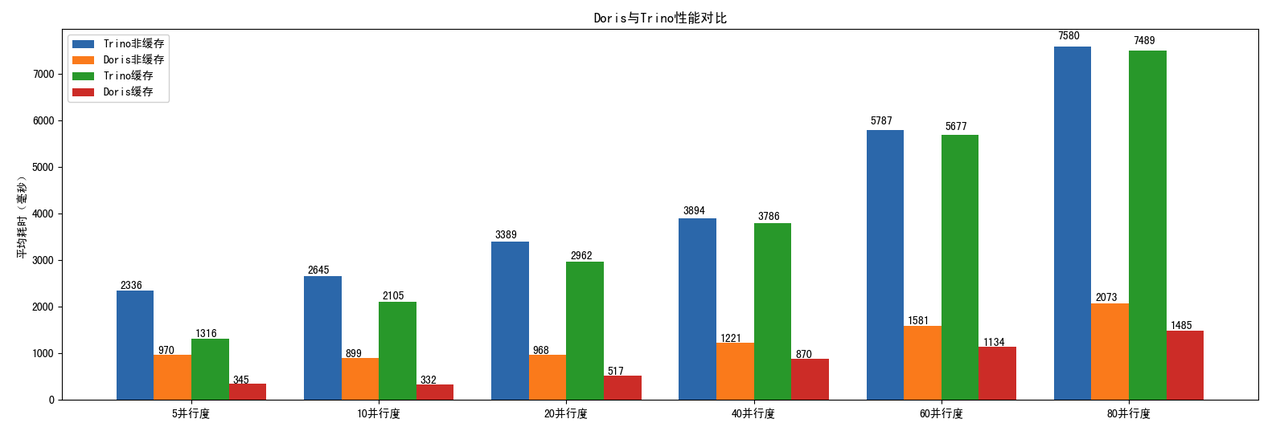
在小米内部的数据查询场景,涵盖多表关联、聚合计算、过滤下推等常见操作的实际业务查询中,Doris 对比 Trino 的数据湖查询效率高 3~5 倍。
- 内部数据查询场景:Doris 对比 Trino 数据湖查询效率高 3~5 倍
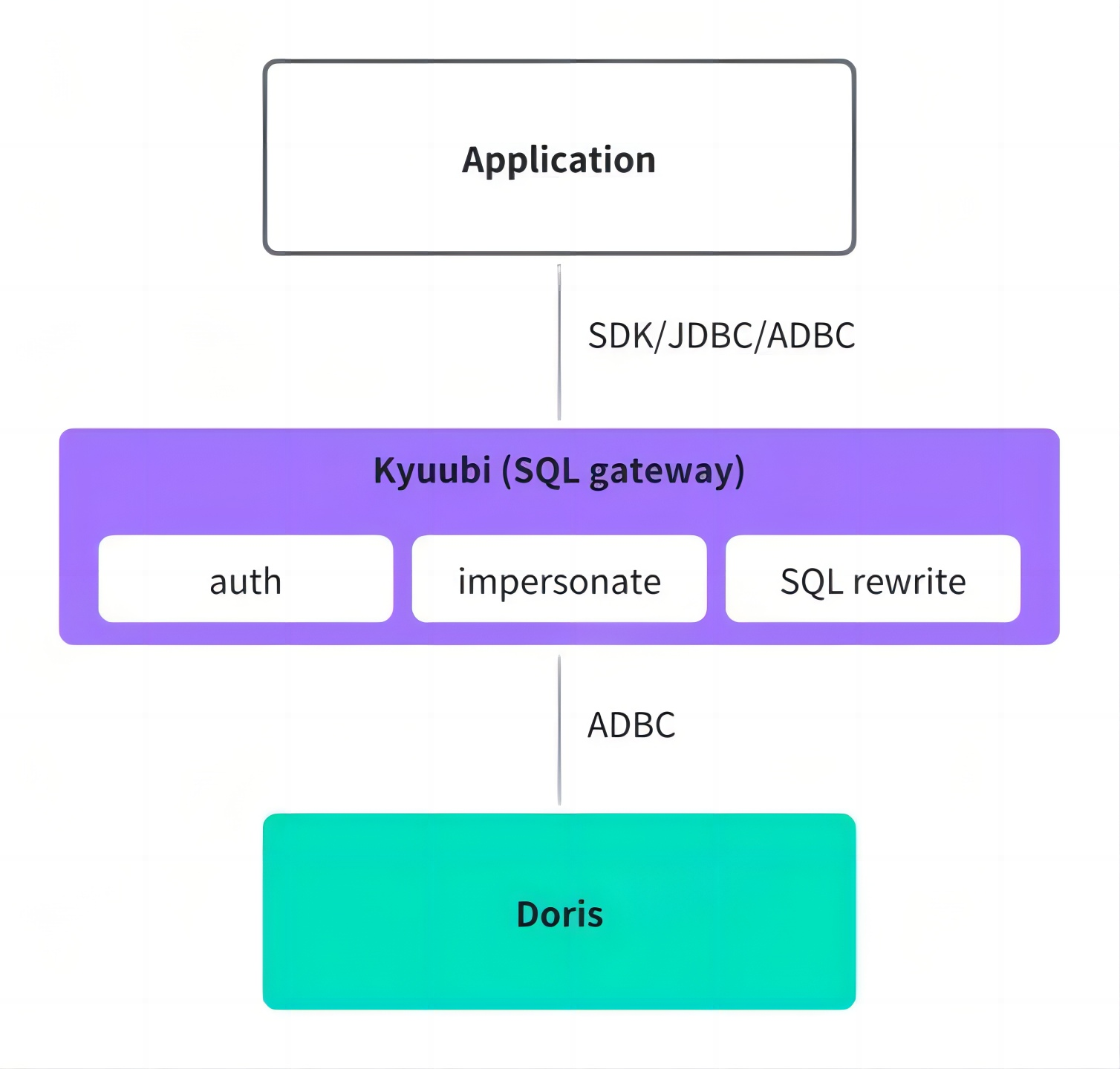
02 统一查询网关
- 统一认证鉴权:在连接层,将不同引擎的权限和认证体系统一提升到网关层,用户通过网关统一查询,无需担心引擎权限问题。
- SQL 改写:利用 Doris 的 SQL 改写能力,将其提升到网关层,帮助用户在不同引擎间平滑切换,避免因 SQL 语句不兼容导致出错。
- 连接协议优化:采用 Arrow Flight SQL 传输协议和 ADBC 连接方式,传输效率较 JDBC 高 10 倍以上,真实业务场景查询耗时减少 36%,Kyuubi 实例内存用量减少 50%,代理层服务的管理效率显著提升。
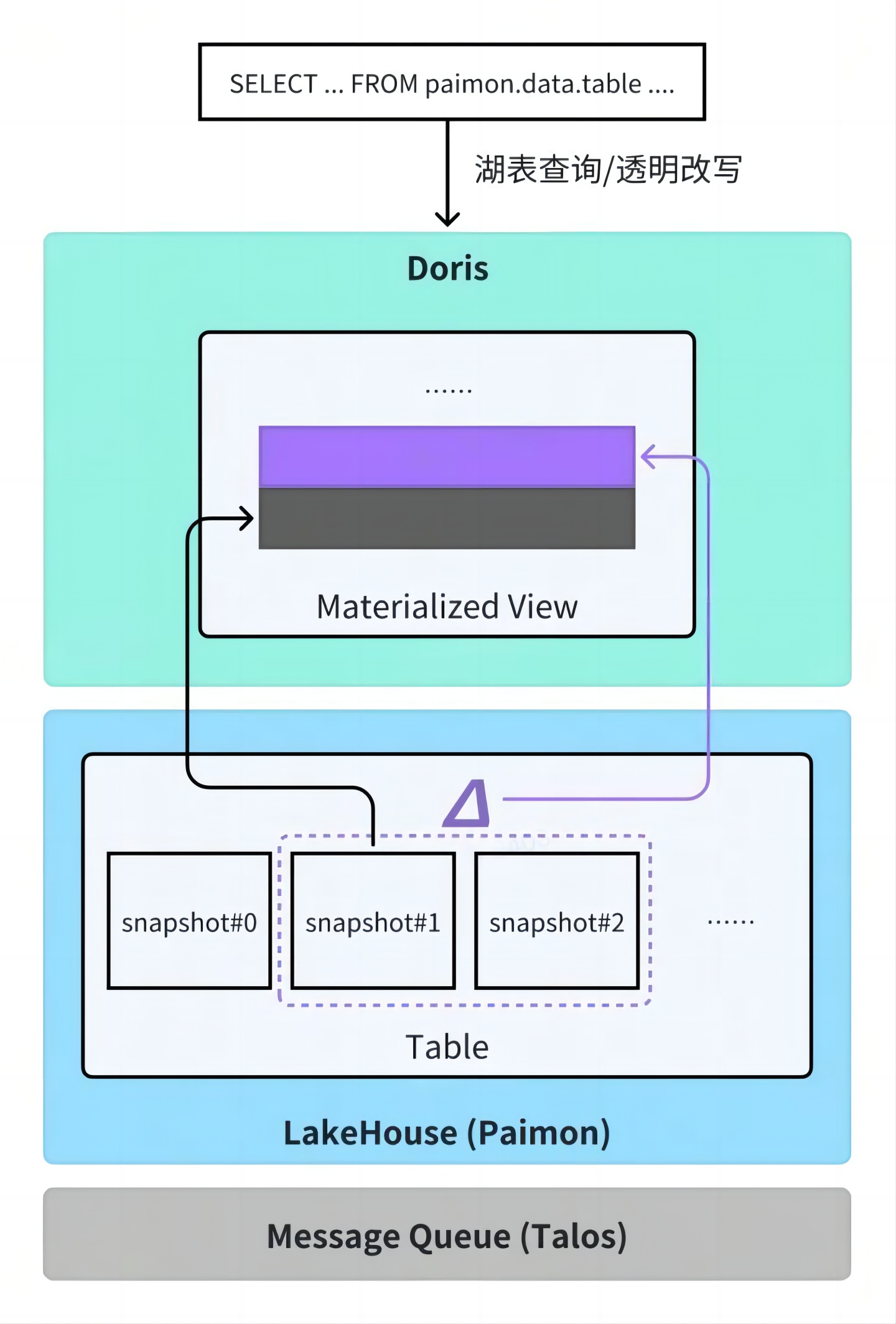
03 数据链路:物化视图上卷代替导入任务
以广告业务场景为例,面对分钟级明细数据聚合查询较慢的问题,常见方案是将原始明细数据聚合成小时级数据,定期导入 Doris 以提升查询性能。这一过程需开发和维护复杂的调度任务,运维成本较高。
自 Doris 2.1 版本引入异步物化视图能力后,只需在 Doris 中声明物化视图定义,系统即可自动完成从外部数据湖(如 Iceberg)增量同步、数据聚合、更新调度等全过程,无需额外开发 ETL 链路,也无需关注底层执行细节,显著降低了开发与运维负担。同时,Doris 支持物化视图改写能力,用户仍可使用原有 SQL 查询原始表,系统会自动识别并将其透明改写为对应的物化视图,实现查询加速。目前该功能基于增量方式实现,主要支持仅追加场景,更新场景仍处于研发状态。
异步物化视图能力的建表语句示例如下:
CREATE MATERIALIZED VIEW mv
BUILD DEFERRED
REFRESH INCREMENTAL
ON COMMIT
PARTITION BY (date)
DISTRIBUTED BY RANDOM BUCKETS 4
PROPERTIES ('replication_num' = '3')
AS
SELECT
date,
k1+1 AS k2,
SUM(a1) AS a2
FROM
paimon.data.table
WHERE date >= 20250222
GROUP BY 1, 2;
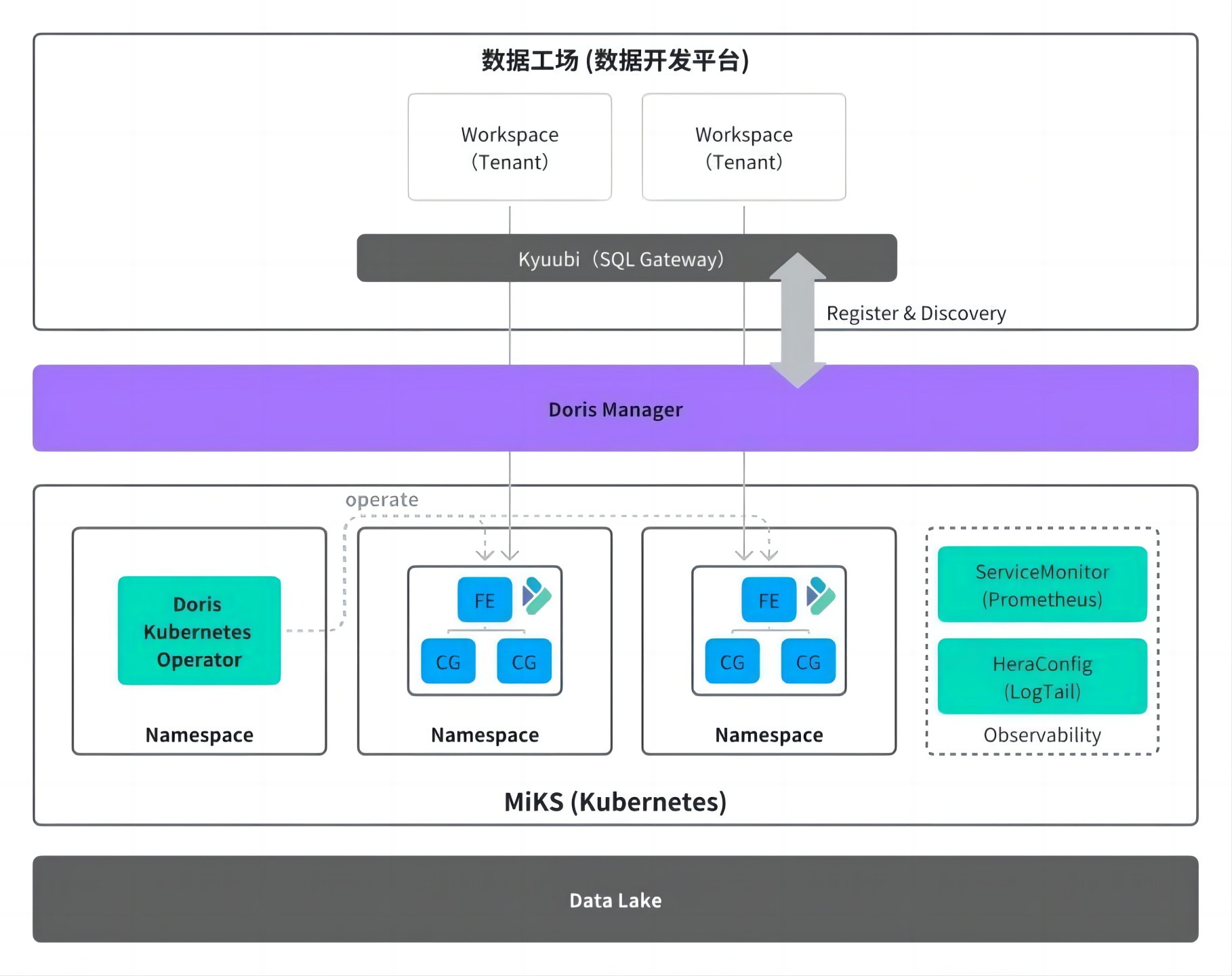
04 自助化、精细化的资源管理
为了优化资源管理与运维流程,我们自研了精细的 Doris Manager 集群管理服务,将用户的运维需求转化为自助操作,依托社区开源的 Doris Operator 在 Kubernetes 平台自动完成资源申请与释放,实现快速的集群变更。用户直接通过平台提交资源申请,无需等待平台申请机器、初始化、发布和上线等步骤,以集群扩容为例,交付周期从原先的约一周大幅缩短至分钟级,显著提升了运维响应速度与效率。
同时,通过 Doris Manager 集群自动化注册与发现能力,新集群创建的同时向元数据中心注册 Catalog,可自动被查询网关识别并接入统一访问入口,用户无需额外配置即可通过网关发起 Doris 查询,进一步优化了使用体验。
接入 Kubernetes 后,资源调度更加精细化,最小调度粒度从物理机级别转变为机器核心、内存大小、磁盘容量等维度,能够根据不同业务需求灵活调配资源,提高资源利用率,满足多样化的业务场景。
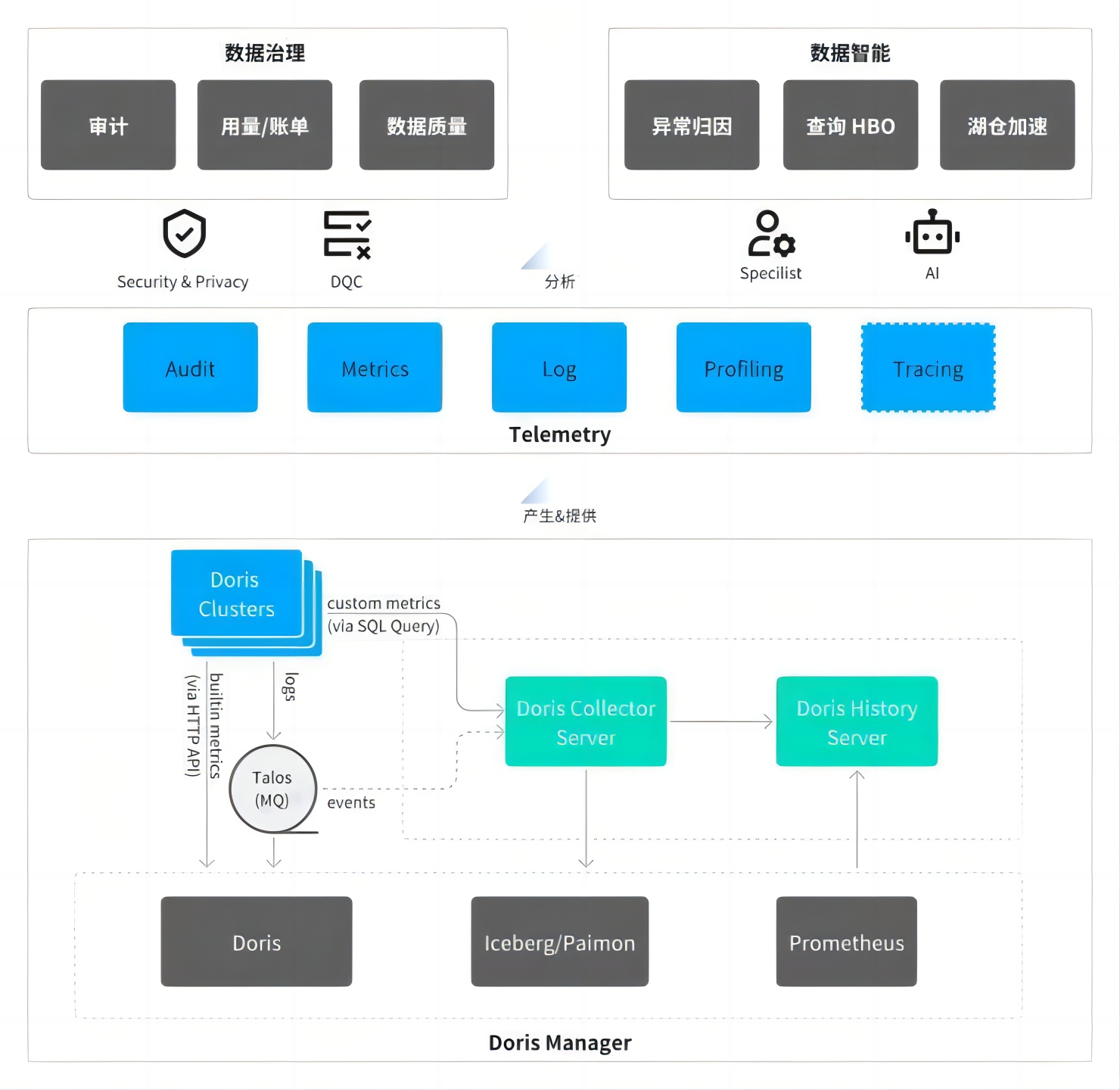
05 更完善的数据采集与可观测性
在集群可观测性方面,基于 Kubernetes 的标准化组件,参照 OpenTelemetry 的规范对 Doris 的监控体系进行全面升级。通过 Prometheus 的 ServiceMonitor 机制采集 Doris 各组件的性能指标,为用户提供全面、细粒度性能监控数据。
在日志采集方面,采用自研的 Hera(log tail 组件)实现高效采集,同时,借鉴社区的日志检索场景实践,将 Doris 作为 OpenTelemetry 的存储后端:Doris 自身运行产生的日志经采集后,最终回流并存储至 Doris 内部表中,形成“日志产生-采集-存储-查询”的闭环。

与之前仅支持基础指标采集的 Falcon 体系相比,Hera 架构覆盖了审计日志、监控指标、运行日志、Profiling 结果以及正在完善的分布式 tracing 信息,提供更加全面的综合诊断能力。
后续规划
感谢 Doris 社区始终保持高效的版本迭代节奏与稳定性打磨,后续我们将基于以下几方面展开工作:
- 完成 Doris 版本收敛工作:将核心功能并线至 2.1 和 3.0 版本,并统一工具链版本依赖以减少环境差异,最终实现开发迭代效率的显著提升,为后续功能迭代奠定高效基础。
- 围绕湖仓一体能力进行深度优化:重点提升湖仓支持的完整性与稳定性,推动 Doris 存算分离架构的大规模落地,同时完善增量计算能力的覆盖范围,以满足复杂场景下的实时数据处理需求。
- 拓展新场景与 AI 融合方向:孵化日志、Tracing 等数据存储能力,通过 AI for Doris 提升运维管理效率,并探索 Doris for AI 的反向赋能能力,构建数据平台与智能技术的双向协同生态。
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


