从走路、跳舞到后空翻,动作模仿教会了机器人「怎么动」,而到端盘子、分拣水果、热食物等复杂操作时,机器人不能只模仿,更要识别复杂环境,理解「为什么做」的任务意图,再转化为「动手这么做」的连贯操作。
人类的行动,一般都依托于上下文和意图,核心就在于推理。对机器人而言,尽管大规模互联网数据让GPT、DeepSeek等AI具备了不错的推理能力,但让AI在真实物理世界里通过推理“准确动起来”,特别是处理多步骤长时序任务、模糊指令、未见过情景时,依然挑战重重。
主流视觉-语言-动作VLA模型依赖”轨迹记忆”,通过海量数据学习”看到A+听到B→做C”的映射。这种方式在标准场景表现尚可,但在开放环境中会暴露三大缺陷:抽象概念失效,比如理解”可乐”,却不懂什么是”补充能量的饮料”;环境泛化困难,如白桌训练、到木桌失效;长时序任务崩溃,比如微波炉加热需多步连贯操作,一步出错则全盘皆输。
AI机器人公司星尘智能提出端到端全身VLA模型——Lumo-1,旨在让机器人心手合一,想清楚就干活,借助具身化VLM、跨本体联合训练、推理-动作真机训练、以及强化学习校准对齐等方式,配合绳驱机器人S1的高质量真机训练,将大模型“心智”转化为全身到手的丝滑操作。
项目页面:www.astribot.com/research/Lumo1
技术报告:https://arxiv.org/pdf/2512.08580
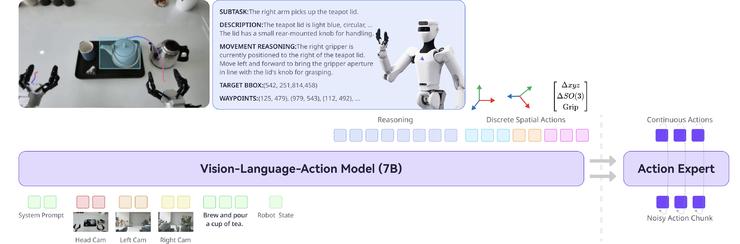
Lumo-1展现了强大的操作智能与泛化能力,在多步骤长时序、精细灵巧操作、可泛化抓取放置等三大类核心操作任务中,全部超越了π0、π0.5等先进模型,尤其在未见过的物体、场景和指令等分布外情况(Out of Distribution,简称OOD),以及抽象、模糊、需扩展推理的指令中,优势更为明显。
从”背菜谱”到”懂烹饪”
人类执行复杂任务时不只是调用”动作库”,而是实时进行多层次推理——理解抽象语义、拆解子任务、感知空间关系、规划运动路径。让机器人像人一样推理,就更能像人一样行动。
“教会机器人思考推理,与喂饱它数据一样重要。Lumo-1的三阶段训练架构:从具身化VLM,到跨本体联合训练,再到推理-动作真机训练,最后用强化学习实现推理与动作的校准与对齐。
如同从”背诵菜谱”到”理解烹饪原理”,机器人开始拥有了”做决定”的能力。
Lumo-1展现了强大的操作智能与泛化能力,在多步骤长时序、精细灵巧操作、可泛化抓取放置等三大类核心机器人任务中,全部超越了π0、π0.5等先进模型,尤其在未见过的物体、场景和指令等分布外情况(Out of Distribution,简称OOD),以及抽象、模糊、需扩展推理的指令中,优势更为明显。
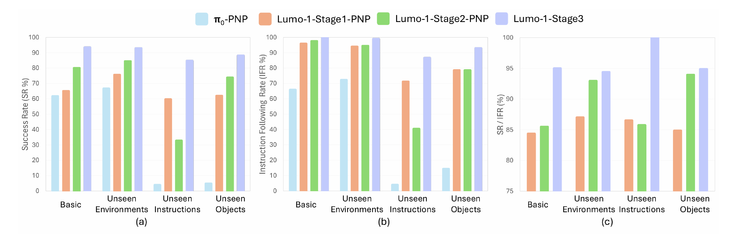
通用抓取放置测试结果
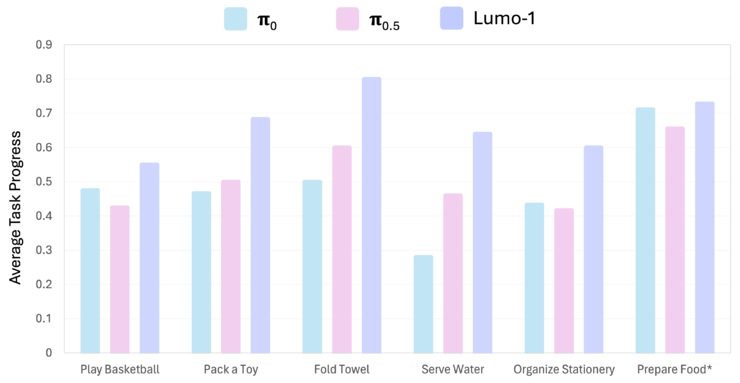
长时序与灵巧操作任务对比结果
三阶训练 VLM认知转化为VLA智能
Lumo-1 的训练不是堆规模,而是精心设计的「智力迁移」过程。
阶段 1:具身化 VLM(Embodied VLM)。在精选的视觉-语言数据上持续预训练,让模型具备空间理解、规划、轨迹推断等「具身语义」。在 7 个经典具身推理基准中大部分超过 RoboBrain-7B、Robix-7B 等专用模型。
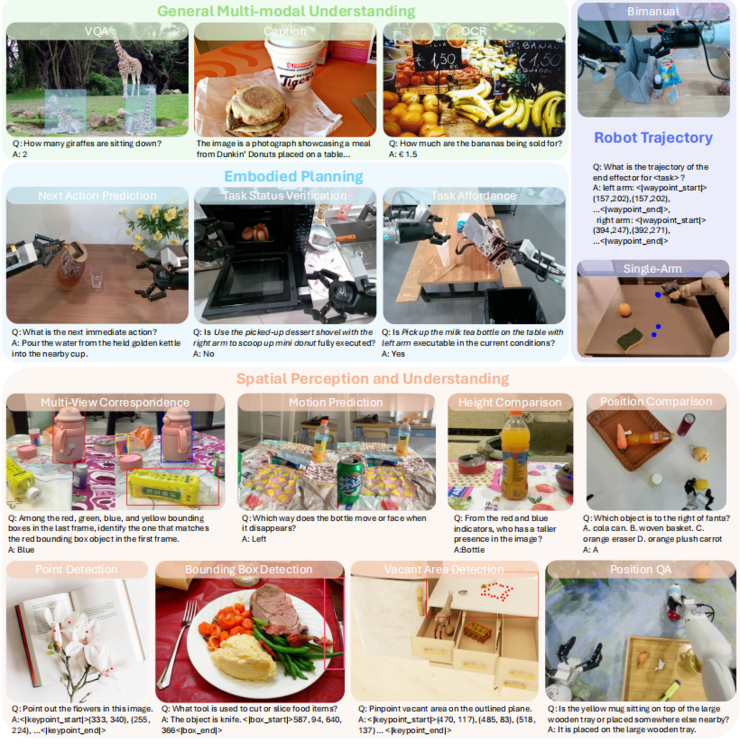
精选数据集旨在不损伤预训练VLM的通用多模态理解与推理能力前提下,强化核心具身推理能力。
阶段 2:跨本体联合训练。融合跨机器人、多视角轨迹、VLM数据上联合训练,强化了指令跟随、物体定位与空间推理能力,使模型开始理解「动作是什么,与指令和观测是什么关系」。
阶段 3:真机推理-动作训练(S1轨迹)。利用绳驱机器人 Astribot S1 高度仿人的示教轨迹,进行带推理过程的动作训练,让模型习得真实世界可执行的动作模式,比如:怎么用双手协同处理物体、如何执行长序列操作、如何将推理一步步落实为轨迹等。

Astribot S1机器人上收集的样本任务。这些任务涵盖了广泛的日常活动,采集自不同的物体、光照条件及环境场景。每项任务均涉及复杂、长时序行为,可自然分解为多个子任务,包含多样化的基础动作单元,例如清扫、削皮、倾倒、刷洗、折叠、按压和旋转等
最后加入强化学习推理-行动对齐(RL Alignment),校准对齐高级推理与低级动作之间的误差,设计了视觉、动作与推理一致、动作执行、推理格式等多维度的奖励信号,通过基于GRPO的学习方案鼓励模型选择更准确、连贯、符合物理规则的动作。实验表明,该方案使模型在任务成功率、动作合理性与泛化能力上显著超越模仿专家示范的原始表现。
三大技术拆解:层层递进的”推理-动作”引擎
动作空间建模:从”高频噪声”到”关键路径”
在 Lumo-1 里,通过动作空间建模SAT(Spatial Action Tokenizer),机器人将动作轨迹转化为可复用、组合的「动作单词库」,能像写句子一样组合动作,或者复用、解释和预测动作。技术上,SAT将连续动作轨迹压缩成最短路径点,并把旋转/平移的增量动作聚类成紧凑token等,在保持动作空间意义时,减少数据收集引入的无关噪音,比FAST与分桶方法等更紧凑和稳定。
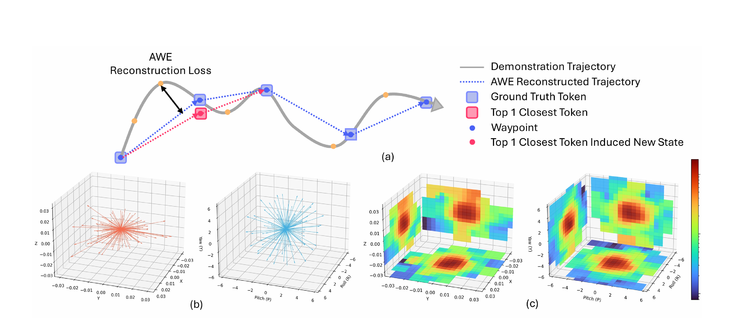
结构化推理:让机器人拥有”常识与思考能力”
Lumo-1将推理拆解为两个维度:文字推理与视觉推理。
模型进行多种形式的具身文本推理:
(1)抽象概念推理整合视觉观测和指令以推断隐含语义(”低热量”→排除可乐);
(2)子任务推理旨在推断到达最终目标的最优中间步骤(微波炉加热→开门→取物→放入→关门→旋钮→取出);
(3)视觉观测描述强调对显著场景特征和可操作物体的准确识别和分析;
(4)运动推理包括对夹爪空间关系的文字推断,以及运动方向的阐述。
然后再进一步执行视觉推理,以实现基于感知的推断和运动估计。
通过结构化推理(Structured Reasoning),机器人大脑不再死记轨迹,而是形成解释动作的结构化推理链,从执行动作到「执行想法」,使「为什么这样做」先于「怎么做」。最终,它把视觉理解映射为路径点预测,让 2D 预测自然落到 3D 控制上,实现更有目的性、情境化的动作生成。
在S1真机部署中,这种能力展现得淋漓尽致。让机器人”把代表爱情的花放进花瓶”,S1能理解玫瑰代表的文化隐喻;当指令换成”把KFC里的东西放进蓝色容器”,它能推理出炸鸡、汉堡等关联物品。在”把画海洋的工具放进绿盘子”这种任务中,S1也能准确找到蓝色的画笔。
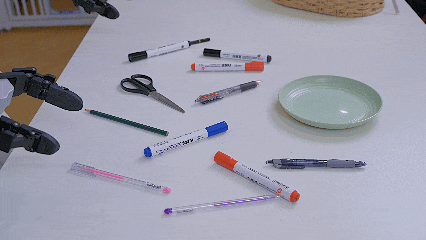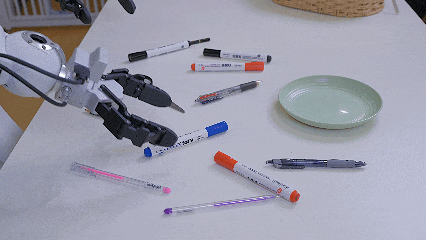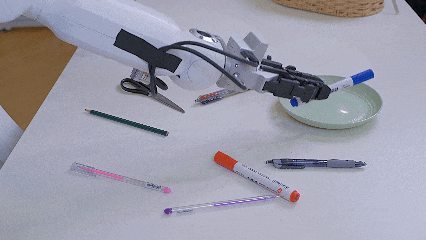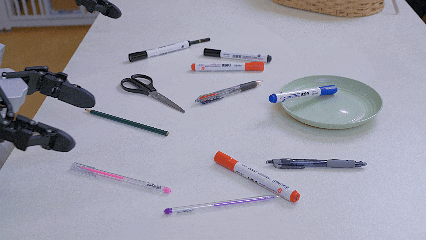
把可以画海洋的文具放到绿盘子里
强化学习推理-行动对齐(RL Alignment)
推理很强 ≠ 执行一定成功。Lumo-1 在最后加入强化学习推理-行动对齐(RL Alignment),校准对齐高级推理与低级动作之间的误差,在真实轨迹中反馈迭代,通过视觉、动作与推理一致、动作执行、推理格式等多维度GRPO风格奖励信号,鼓励模型选择更准确、连贯、符合物理规则的动作。
成果与影响
Scaling Law验证
团队采用数据受限扩展定律验证训练策略。结果显示:在固定模型规模下,数据多样性(场景、物体、指令的覆盖面)对泛化能力的影响远超数据重复次数。这为行业指明方向——除了堆数据量,也可以抓数据质量。
技术成果:全面超越主流基线
Lumo-1在7个多模态基准测试中的6个优于backbone模型Qwen2.5-VL-7B,并超越专门的具身模型RoboBrain-7B和Robix-7B。更关键的是,融入动作学习后,模型的核心多模态感知和推理能力未受损——这证明”推理”与”动作”并非零和博弈。
在真实环境验证中,S1展现出惊人的泛化能力:面对不同高度的容器,自动调整手臂姿态;菜单从印刷体换成手写体,仍能精准识别食材配对(肠仔意面、胡萝卜牛腩等)。
]article_adlist–>
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

