
<h1>一、引言</h1> 随着互联网技术的飞速发展,现代系统面临着前所未有的并发压力和可用性要求。从电商秒杀到社交媒体直播,从金融交易到物联网设备接入,系统需要处理百万级甚至千万级的并发请求,同时保证99.999%的可用性。在这种背景下,Go语言凭借其独特的设计哲学和技术特性,成为了构建高并发高可用系统的首选语言之一。
Go语言自2009年诞生以来,就以 “并发性能优异、开发效率高、部署简单”等特点受到开发者的青睐 。其核心优势包括:轻量级协程(Goroutine)、高效的调度器、原生支持并发编程、高性能网络库等。 这些特性使得Go语言在处理高并发场景时具有天然优势。
本文将通过五个典型的高并发高可用场景,深入分析传统架构面临的问题矛盾点,并详细阐述Go语言的解决方案,包括核心技术、代码实现和理论知识支撑,展示Go语言在构建高并发高可用系统中的强大能力。
二、场景1:微服务高并发通信(gRPC)
场景描述
在现代微服务架构中,服务间通信是系统的核心组成部分。随着服务数量的增加和业务复杂度的提升,服务间通信的性能和可靠性直接影响到整个系统的吞吐量和响应时间。 例如,一个电商系统可能包含用户服务、商品服务、订单服务、支付服务等数十个微服务,这些服务之间需要进行大量的数据交互。当系统面临高峰期(如大促活动)时,服务间通信的并发量可能达到每秒数万次甚至数十万次。
问题矛盾点
传统微服务架构中,服务间通信常面临以下几大矛盾:
- 同步阻塞I/O vs 高并发需求: 传统HTTP/1.1协议采用同步阻塞模型,每个请求需要占用一个线程。当QPS达到数万级时,线程池资源迅速耗尽(如Java的Tomcat默认200线程),导致请求堆积、延迟飙升。虽然可以通过增加线程数来缓解,但线程的创建和上下文切换开销巨大,系统性能会急剧下降。
- 序列化/反序列化开销大: JSON/XML等文本协议在数据量大时,序列化和反序列化耗时显著增加,成为性能瓶颈。例如,对于包含复杂结构的数据,JSON序列化可能比二进制协议慢5-10倍,同时数据体积也会大30%-50%,增加了网络传输开销。
- 服务治理复杂度高: 随着服务数量的增加,服务发现、负载均衡、熔断降级等服务治理功能变得越来越复杂。传统的HTTP客户端(如Java的RestTemplate)缺乏对这些功能的原生支持,需要依赖额外的框架(如Spring Cloud),增加了系统的复杂性和学习成本。
- 跨语言兼容性差: 在多语言环境下,不同服务可能使用不同的编程语言开发,传统的HTTP+JSON方案虽然通用性强,但在类型安全和接口一致性方面存在问题,容易导致服务间调用错误。
Go解决方案核心技术
gRPC + Protocol Buffers
gRPC是Google开源的高性能RPC框架,基于HTTP/2协议和Protocol Buffers序列化协议,为微服务通信提供了高效、可靠的解决方案。Go语言原生支持gRPC,通过google.golang.org/grpc包可以轻松实现gRPC服务端和客户端。
HTTP/2多路复用
HTTP/2协议支持单连接多路复用,允许在一个TCP连接上同时传输多个请求和响应。这意味着可以通过一个连接处理成百上千个并发请求,避免了传统HTTP/1.1协议中”连接数爆炸”的问题。Go的net/http2库原生支持HTTP/2协议,配合Goroutine调度,可以轻松处理百万级并发连接。
Protocol Buffers序列化
Protocol Buffers是一种高效的二进制序列化协议,相比JSON/XML具有以下优势:
- 体积小: 二进制格式,相比JSON节省30%-50%的带宽
- 解析速度快: 使用预编译的代码生成器,解析速度比JSON快5-10倍
- 类型安全: 强类型定义,编译时检查,避免运行时错误
- 跨语言兼容: 支持多种编程语言,包括Go、Java、Python、C++等
Goroutine池化与复用
虽然Goroutine的创建开销比线程低很多,但在极高并发场景下(如每秒数十万请求),频繁创建和销毁Goroutine仍然会带来一定的性能开销。Go语言提供了sync.Pool包,可以实现Goroutine的复用,减少调度开销。
代码实现
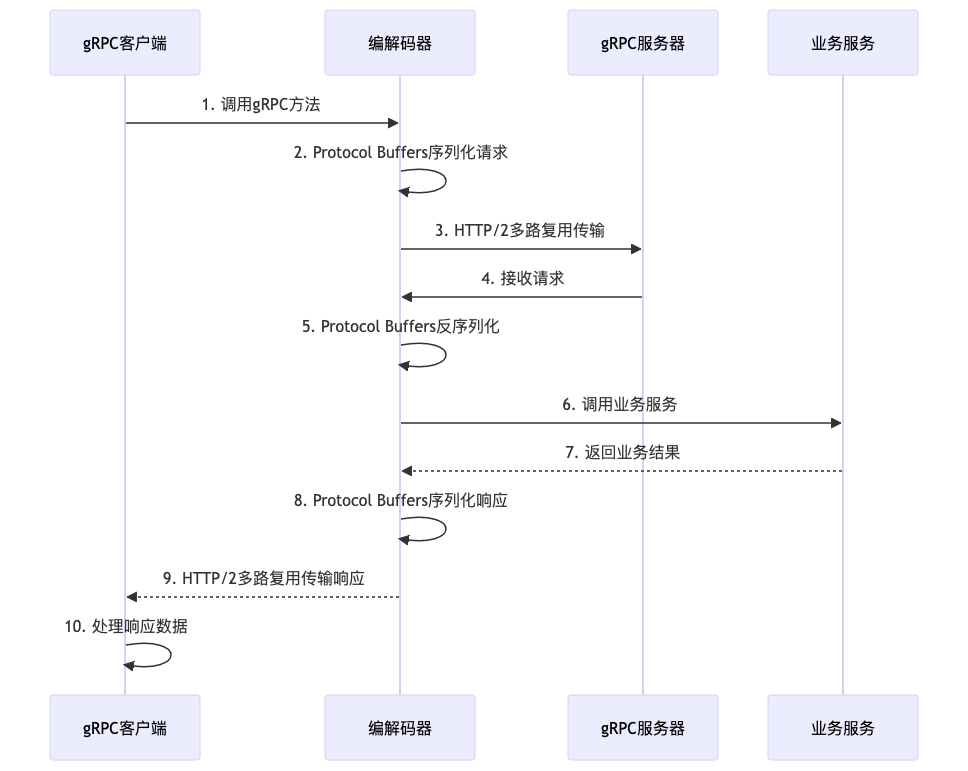
gRPC服务定义
// service.proto
syntax = "proto3";
package example;
// 定义服务
service UserService {
// 定义方法
rpc GetUser(GetUserRequest) returns (GetUserResponse) {}
}
// 请求消息
message GetUserRequest {
int64 user_id = 1;
}
// 响应消息
message GetUserResponse {
int64 user_id = 1;
string username = 2;
string email = 3;
}
gRPC服务端实现
// 定义服务结构体
type server struct {
pb.UnimplementedUserServiceServer
}
// 实现GetUser方法
func (s *server) GetUser(ctx context.Context, in *pb.GetUserRequest) (*pb.GetUserResponse, error) {
// 模拟数据库查询
user := &pb.GetUserResponse{
UserId: in.UserId,
Username: fmt.Sprintf("user_%d", in.UserId),
Email: fmt.Sprintf("user_%d@example.com", in.UserId),
}
return user, nil
}
func main() {
// 监听端口
listener, err := net.Listen("tcp", ":50051")
if err != nil {
log.Fatalf("failed to listen: %v", err)
}
// 创建gRPC服务器
s := grpc.NewServer(
grpc.MaxConcurrentStreams(1000), // 设置最大并发流数
grpc.InitialWindowSize(65536), // 设置初始窗口大小
)
// 注册服务
pb.RegisterUserServiceServer(s, &server{})
// 注册反射服务
reflection.Register(s)
// 启动服务器
log.Printf("server listening at %v", listener.Addr())
if err := s.Serve(listener); err != nil {
log.Fatalf("failed to serve: %v", err)
}
}
gRPC客户端实现
func main() {
// 连接服务器
conn, err := grpc.Dial(":50051",
grpc.WithTransportCredentials(insecure.NewCredentials()),
grpc.WithBlock(),
grpc.WithTimeout(5*time.Second),
grpc.WithDefaultCallOptions(grpc.MaxCallRecvMsgSize(1024*1024)), // 设置最大接收消息大小
)
if err != nil {
log.Fatalf("did not connect: %v", err)
}
defer conn.Close()
// 创建客户端
c := pb.NewUserServiceClient(conn)
// 调用GetUser方法
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
defer cancel()
// 批量请求示例
for i := 0; i < 100; i++ {
go func(userID int64) {
resp, err := c.GetUser(ctx, &pb.GetUserRequest{UserId: userID})
if err != nil {
log.Printf("could not get user: %v", err)
return
}
log.Printf("User: %d, %s, %s", resp.UserId, resp.Username, resp.Email)
}(int64(i))
}
// 等待所有请求完成
time.Sleep(2 * time.Second)
}
理论知识支撑
Reactor模式
gRPC服务器使用Reactor模式监听连接事件,将I/O操作异步化。Reactor模式的核心思想是将事件监听和事件处理分离,通过一个或多个线程监听事件,当事件发生时,将事件分发给对应的处理器处理。Go语言的gRPC实现基于epoll/kqueue等事件驱动机制,配合Goroutine调度,实现了高效的事件处理。
零拷贝技术
Go的Protocol Buffers库直接操作字节切片,避免了不必要的内存分配和拷贝。在序列化和反序列化过程中,库会直接将数据写入预分配的缓冲区,或者从缓冲区中直接读取数据,减少了内存拷贝次数,提高了性能。
Hertz-Burst理论
Hertz-Burst理论是指系统在处理突发流量时,需要在延迟和吞吐量之间进行权衡。gRPC通过连接池和限流算法(如令牌桶),可以平衡瞬时流量高峰与系统吞吐量,避免系统因突发流量而崩溃。
服务网格集成
gRPC可以与服务网格(如Istio、Linkerd)无缝集成,实现高级服务治理功能,如流量管理、安全认证、可观察性等。服务网格通过透明代理的方式,将服务治理逻辑从应用代码中分离出来,降低了开发复杂度。
三、场景2:实时消息推送(WebSocket)
场景描述
实时消息推送是现代Web应用的重要功能之一,广泛应用于社交媒体、在线聊天、实时监控、协同办公等场景。例如,社交媒体平台需要实时推送新消息、点赞通知;在线游戏需要实时同步玩家状态;金融交易系统需要实时推送行情数据。这些场景对消息推送的实时性、可靠性和并发能力要求极高。
问题矛盾点
传统的HTTP轮询方案在实时消息推送场景下面临以下几大矛盾:
- 长轮询资源浪费: 客户端通过定期发起HTTP请求来获取新消息,即使没有新消息,服务器也需要处理这些请求。在大规模用户场景下,这会导致服务器资源利用率不足5%,造成严重的资源浪费。
- 消息延迟不可控: HTTP请求-响应模型无法保证实时性,消息延迟取决于轮询间隔。如果轮询间隔过短,会增加服务器负担;如果轮询间隔过长,会导致消息延迟增加,极端情况下延迟可达秒级。
- 连接数限制: Nginx等反向代理默认限制单个IP的并发连接数(如1024),大规模用户场景下需要频繁扩容,增加了运维成本。
- 协议开销大: HTTP协议包含大量的头部信息,每个请求和响应都需要传输这些头部,增加了网络带宽开销。
- 状态管理复杂: 服务器需要维护每个客户端的连接状态和消息队列,传统的HTTP无状态模型难以处理。
Go解决方案核心技术
WebSocket长连接 + Goroutine复用
WebSocket是一种全双工通信协议,允许服务器和客户端之间建立持久连接,实现双向实时通信。Go语言提供了net/http/websocket包,原生支持WebSocket协议,可以轻松实现WebSocket服务端和客户端。
单协程处理多连接
Go语言的select语句可以同时监听多个通道和I/O操作,这使得单个Goroutine可以处理多个WebSocket连接的读写事件。通过这种方式,可以避免为每个连接创建独立的Goroutine,减少内存占用和调度开销。
批量消息推送
使用sync.Map维护客户端连接池,将相同频道的客户端分组管理。当有新消息需要推送时,可以批量获取该频道的所有客户端,然后并发推送消息,减少网络I/O次数。
异步写入缓冲
利用bufio.Writer的缓冲机制,合并小数据包,降低系统调用频率。同时,使用非阻塞写入方式,避免因单个客户端连接缓慢而影响其他客户端。
代码实现
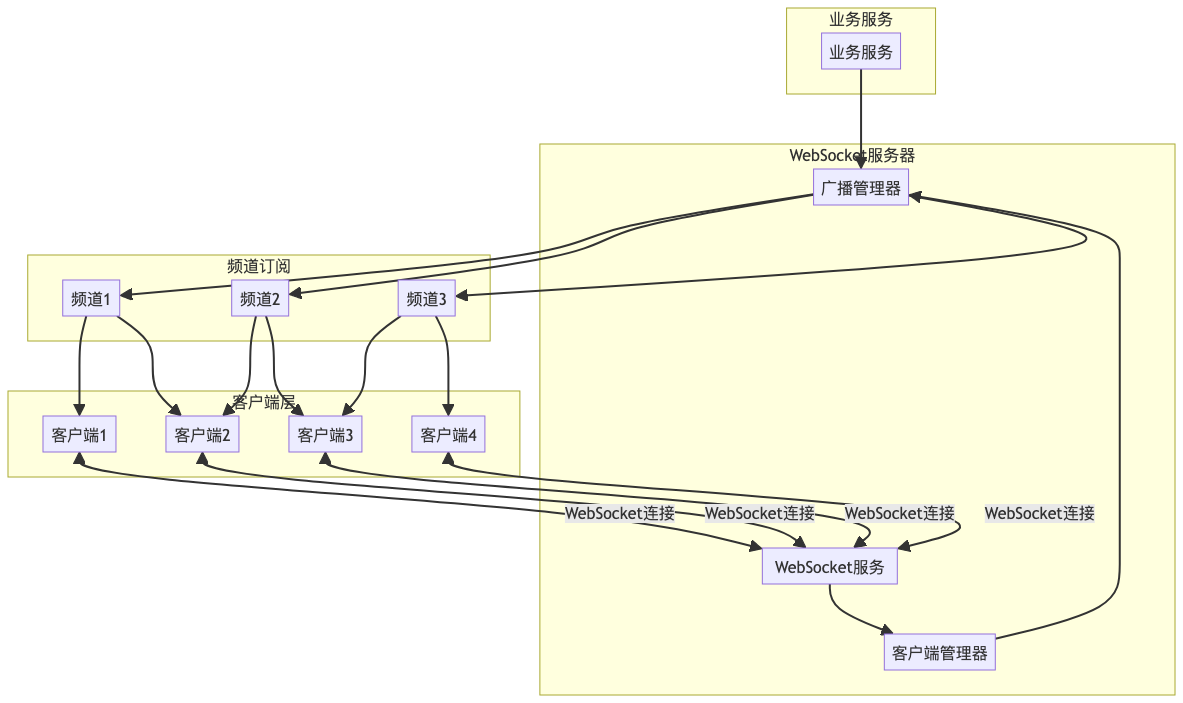
WebSocket服务端实现
// 客户端管理器运行
func (manager *ClientManager) run() {
for {
select {
case client := <-manager.register:
// 注册新客户端
manager.mu.Lock()
manager.clients[client] = true
manager.mu.Unlock()
log.Printf("Client connected: %s", client.userID)
case client := <-manager.unregister:
// 注销客户端
if _, ok := manager.clients[client]; ok {
close(client.send)
manager.mu.Lock()
delete(manager.clients, client)
// 从所有频道中移除客户端
client.mu.RLock()
for channel := range client.channels {
if _, ok := manager.channels[channel]; ok {
delete(manager.channels[channel], client)
// 如果频道为空,删除频道
if len(manager.channels[channel]) == 0 {
delete(manager.channels, channel)
}
}
}
client.mu.RUnlock()
manager.mu.Unlock()
log.Printf("Client disconnected: %s", client.userID)
}
case message := <-manager.broadcast:
// 广播消息到指定频道
manager.mu.RLock()
if clients, ok := manager.channels[message.Channel]; ok {
for client := range clients {
select {
case client.send <- message.Content:
default:
// 如果客户端发送缓冲区满,关闭连接
close(client.send)
delete(manager.clients, client)
// 从所有频道中移除客户端
client.mu.RLock()
for channel := range client.channels {
if _, ok := manager.channels[channel]; ok {
delete(manager.channels[channel], client)
if len(manager.channels[channel]) == 0 {
delete(manager.channels, channel)
}
}
}
client.mu.RUnlock()
}
}
}
manager.mu.RUnlock()
}
}
}
// 客户端读写协程
func (c *Client) readPump(manager *ClientManager) {
defer func() {
manager.unregister <- c
c.conn.Close()
}()
// 设置读取超时
c.conn.SetReadDeadline(time.Now().Add(60 * time.Second))
c.conn.SetPongHandler(func(string) error {
// 重置读取超时
c.conn.SetReadDeadline(time.Now().Add(60 * time.Second))
return nil
})
for {
_, message, err := c.conn.ReadMessage()
if err != nil {
if websocket.IsUnexpectedCloseError(err, websocket.CloseGoingAway, websocket.CloseAbnormalClosure) {
log.Printf("error: %v", err)
}
break
}
// 解析消息
var msg Message
if err := json.Unmarshal(message, &msg); err != nil {
log.Printf("error parsing message: %v", err)
continue
}
msg.UserID = c.userID
// 处理不同类型的消息
switch msg.Type {
case "subscribe":
// 订阅频道
c.mu.Lock()
c.channels[msg.Channel] = true
c.mu.Unlock()
manager.mu.Lock()
if _, ok := manager.channels[msg.Channel]; !ok {
manager.channels[msg.Channel] = make(map[*Client]bool)
}
manager.channels[msg.Channel][c] = true
manager.mu.Unlock()
log.Printf("Client %s subscribed to channel %s", c.userID, msg.Channel)
case "unsubscribe":
// 取消订阅
c.mu.Lock()
delete(c.channels, msg.Channel)
c.mu.Unlock()
manager.mu.Lock()
if clients, ok := manager.channels[msg.Channel]; ok {
delete(clients, c)
// 如果频道为空,删除频道
if len(clients) == 0 {
delete(manager.channels, msg.Channel)
}
}
manager.mu.Unlock()
log.Printf("Client %s unsubscribed from channel %s", c.userID, msg.Channel)
case "message":
// 广播消息
if msg.Channel != "" {
manager.broadcast <- &msg
}
}
}
}
func (c *Client) writePump() {
// 设置写入缓冲
writer := bufio.NewWriter(c.conn.UnderlyingConn())
defer func() {
c.conn.Close()
}()
// 定时发送ping消息
ticker := time.NewTicker(30 * time.Second)
defer ticker.Stop()
for {
select {
case message, ok := <-c.send:
// 设置写入超时
c.conn.SetWriteDeadline(time.Now().Add(10 * time.Second))
if !ok {
// 发送关闭消息
c.conn.WriteMessage(websocket.CloseMessage, []byte{})
return
}
// 获取写入器
w, err := c.conn.NextWriter(websocket.TextMessage)
if err != nil {
return
}
// 写入消息
w.Write(message)
// 批量写入待发送消息
n := len(c.send)
for i := 0; i < n; i++ {
w.Write([]byte("\n"))
w.Write(<-c.send)
}
// 刷新缓冲区
if err := w.Close(); err != nil {
return
}
case <-ticker.C:
// 发送ping消息
c.conn.SetWriteDeadline(time.Now().Add(10 * time.Second))
if err := c.conn.WriteMessage(websocket.PingMessage, nil); err != nil {
return
}
}
}
}
WebSocket客户端实现
func main() {
// 解析命令行参数
userID := "client1"
if len(os.Args) > 1 {
userID = os.Args[1]
}
// 构建WebSocket URL
u := url.URL{
Scheme: "ws",
Host: "localhost:8080",
Path: "/ws",
}
q := u.Query()
q.Add("user_id", userID)
u.RawQuery = q.Encode()
log.Printf("Connecting to %s", u.String())
// 连接WebSocket服务器
conn, _, err := websocket.DefaultDialer.Dial(u.String(), nil)
if err != nil {
log.Fatal("dial:", err)
}
defer conn.Close()
// 上下文用于取消操作
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
// 处理中断信号
interrupt := make(chan os.Signal, 1)
signal.Notify(interrupt, os.Interrupt)
// 启动读取协程
go func() {
defer cancel()
for {
_, message, err := conn.ReadMessage()
if err != nil {
log.Println("read:", err)
return
}
log.Printf("Received: %s", message)
}
}()
// 发送订阅消息
subscribeMsg := Message{
Type: "subscribe",
Channel: "test",
}
subscribeData, err := json.Marshal(subscribeMsg)
if err != nil {
log.Fatal("marshal subscribe message:", err)
}
if err := conn.WriteMessage(websocket.TextMessage, subscribeData); err != nil {
log.Fatal("write subscribe message:", err)
}
// 定时发送消息
ticker := time.NewTicker(5 * time.Second)
defer ticker.Stop()
for {
select {
case <-ticker.C:
// 发送测试消息
testMsg := Message{
Type: "message",
Channel: "test",
Content: json.RawMessage(`{"text":"Test message from ` + userID + `","time":"` + time.Now().Format(time.RFC3339) + `"}`),
}
testData, err := json.Marshal(testMsg)
if err != nil {
log.Println("marshal test message:", err)
continue
}
if err := conn.WriteMessage(websocket.TextMessage, testData); err != nil {
log.Println("write test message:", err)
return
}
case <-interrupt:
log.Println("interrupt")
// 发送关闭消息
if err := conn.WriteMessage(websocket.CloseMessage, websocket.FormatCloseMessage(websocket.CloseNormalClosure, "")); err != nil {
log.Println("write close:", err)
return
}
select {
case <-ctx.Done():
case <-time.After(time.Second):
}
return
case <-ctx.Done():
return
}
}
}
理论知识支撑
事件驱动模型
Go的WebSocket实现基于事件驱动模型,通过epoll/kqueue等系统调用监听I/O事件。当有新连接建立、数据到达或连接关闭时,系统会触发相应的事件,然后由Go运行时将事件分发给对应的处理函数。这种模型避免了传统的阻塞I/O模型中线程阻塞的问题,提高了系统的并发处理能力。
发布-订阅模式
发布-订阅模式是一种消息传递模式,其中发布者将消息发送到特定的频道,订阅者通过订阅频道来接收消息。在WebSocket场景中,发布-订阅模式可以实现消息的高效分发,支持多对多通信。Go语言的Channel和sync.Map为实现发布-订阅模式提供了高效的工具。
TCP粘包处理
在TCP通信中,由于TCP是流式协议,消息可能会被拆分为多个数据包,或者多个消息被合并为一个数据包,这就是TCP粘包问题。Go的WebSocket库内部已经处理了TCP粘包问题,通过消息头中的长度字段来确定消息边界,确保消息的完整性。
背压机制
背压机制是指当系统处理能力不足时,上游系统会感知到下游系统的压力,并调整发送速率,避免系统崩溃。在WebSocket实现中,我们使用带缓冲的Channel和非阻塞写入方式来实现背压机制。当客户端的发送缓冲区满时,服务器会停止向该客户端发送消息,避免内存溢出。
四、场景3:API网关限流与熔断
场景描述
API网关是微服务架构中的重要组件,负责请求路由、负载均衡、认证授权、限流熔断等功能。在高并发场景下,API网关需要处理大量的请求,同时保护后端服务不被过载。 例如,电商系统的API网关在大促期间可能需要处理每秒数十万的请求,此时限流和熔断机制就显得尤为重要。
问题矛盾点
传统的API网关限流方案面临以下几大挑战:
- 全局锁竞争: 基于Redis的分布式锁(如SETNX)在高并发下会产生大量竞争,QPS上限仅数千。这是因为所有请求都需要访问同一个Redis键,导致Redis成为性能瓶颈。
- 冷启动问题: 在系统启动初期,由于统计数据不足,限流算法可能会误判,导致正常请求被拒绝。例如,令牌桶算法在初始状态下没有令牌,需要一段时间才能积累足够的令牌。
- 固定阈值缺乏灵活性: 传统的限流方案通常使用固定的阈值,无法根据系统负载动态调整。在系统负载低时,固定阈值会浪费资源;在系统负载高时,固定阈值可能无法有效保护系统。
- 熔断机制不完善: 传统的熔断机制通常基于错误率或响应时间,但缺乏上下文信息,可能会导致误判。例如,当某个后端服务只是暂时延迟高时,熔断机制可能会错误地将其熔断,影响系统可用性。
- 分布式限流一致性问题: 在分布式环境下,多个API网关实例之间需要共享限流状态,确保全局限流的准确性。传统的基于Redis的方案存在一致性问题,可能导致实际请求数超过限流阈值。
Go解决方案核心技术
令牌桶算法 + 本地缓存
令牌桶算法是一种常用的限流算法,通过定期向桶中添加令牌,请求需要获取令牌才能执行。Go语言可以高效地实现令牌桶算法,结合本地缓存可以减少对Redis等外部存储的依赖,提高性能。
滑动窗口限流
滑动窗口限流是一种更精确的限流算法,通过维护一个滑动的时间窗口,统计窗口内的请求数。当请求数超过阈值时,拒绝新的请求。Go语言的原子操作和时间包为实现滑动窗口限流提供了高效的工具。
熔断降级机制
结合context.WithTimeout和信号量(semaphore),可以实现快速失败和熔断降级。当后端服务响应时间超过阈值或错误率过高时,自动熔断该服务,避免级联失败。
分布式限流协同
使用Redis等分布式存储实现多个API网关实例之间的限流状态共享,结合本地缓存减少对Redis的访问频率,提高性能。
代码实现
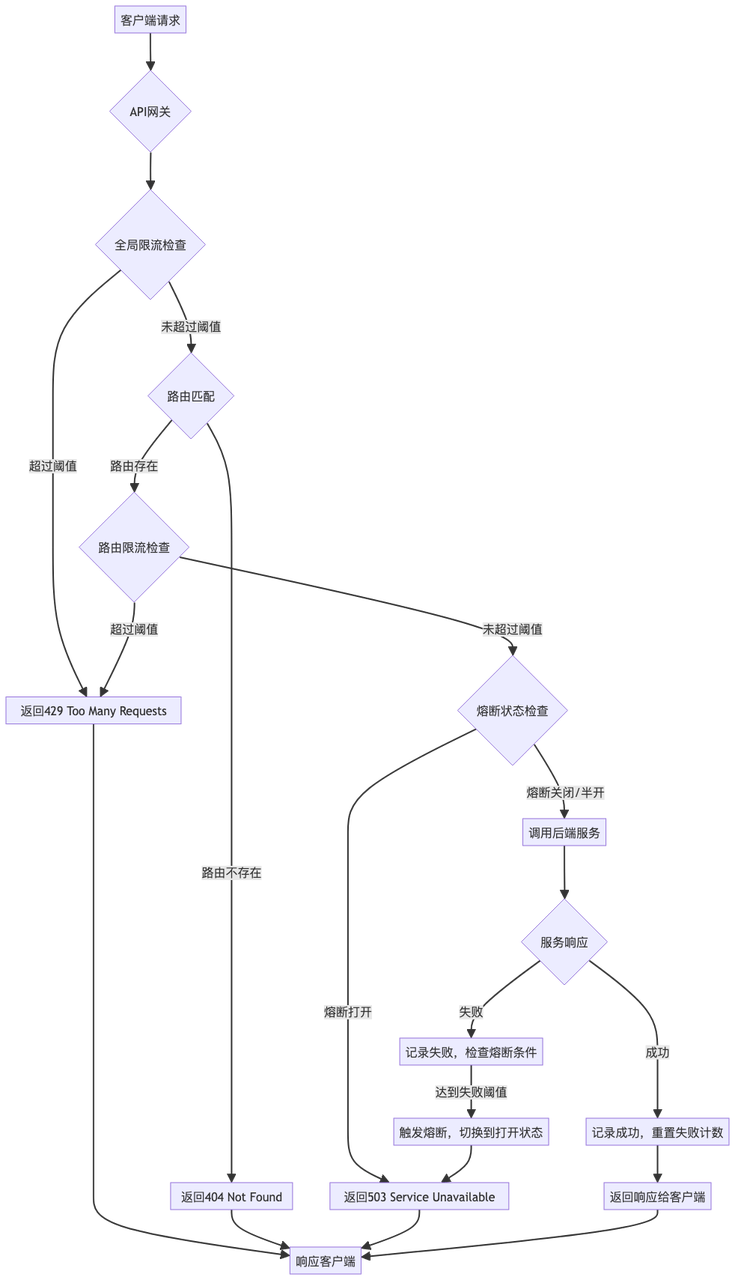
令牌桶限流实现
// NewTokenBucket 创建新的令牌桶
func NewTokenBucket(capacity int64, rate float64) *TokenBucket {
tb := &TokenBucket{
capacity: capacity,
rate: rate,
tokens: capacity, // 初始填满令牌
lastRefill: time.Now(),
stopRefill: make(chan struct{}),
}
// 启动令牌填充协程
tb.startRefill()
return tb
}
// startRefill 启动令牌填充协程
func (tb *TokenBucket) startRefill() {
// 计算填充间隔
interval := time.Duration(float64(time.Second) / tb.rate)
tb.refillTicker = time.NewTicker(interval)
go func() {
for {
select {
case <-tb.refillTicker.C:
tb.mu.Lock()
// 填充一个令牌
if tb.tokens < tb.capacity {
tb.tokens++
}
tb.mu.Unlock()
case <-tb.stopRefill:
tb.refillTicker.Stop()
return
}
}
}()
}
// Allow 检查是否允许请求
func (tb *TokenBucket) Allow() bool {
tb.mu.Lock()
defer tb.mu.Unlock()
if tb.tokens > 0 {
tb.tokens--
return true
}
return false
}
// AllowN 检查是否允许N个请求
func (tb *TokenBucket) AllowN(n int64) bool {
tb.mu.Lock()
defer tb.mu.Unlock()
if tb.tokens >= n {
tb.tokens -= n
return true
}
return false
}
// Close 关闭令牌桶,停止填充令牌
func (tb *TokenBucket) Close() {
close(tb.stopRefill)
}
滑动窗口限流实现
// NewSlidingWindow 创建新的滑动窗口
func NewSlidingWindow(windowSize time.Duration, splitCount int, threshold int64) *SlidingWindow {
if splitCount <= 0 {
splitCount = 10 // 默认分割为10个子窗口
}
return &SlidingWindow{
windowSize: windowSize,
splitCount: splitCount,
threshold: threshold,
segments: make([]int64, splitCount),
currentIdx: 0,
lastUpdate: time.Now(),
segmentSize: windowSize / time.Duration(splitCount),
}
}
// updateSegments 更新子窗口计数
func (sw *SlidingWindow) updateSegments() {
now := time.Now()
duration := now.Sub(sw.lastUpdate)
// 如果时间间隔小于子窗口大小,不需要更新
if duration < sw.segmentSize {
return
}
// 计算需要更新的子窗口数量
segmentsToUpdate := int(duration / sw.segmentSize)
if segmentsToUpdate > sw.splitCount {
segmentsToUpdate = sw.splitCount
}
// 重置需要更新的子窗口
for i := 0; i < segmentsToUpdate; i++ {
sw.currentIdx = (sw.currentIdx + 1) % sw.splitCount
sw.segments[sw.currentIdx] = 0
}
// 更新上次更新时间
sw.lastUpdate = now
}
// Allow 检查是否允许请求
func (sw *SlidingWindow) Allow() bool {
sw.mu.Lock()
defer sw.mu.Unlock()
// 更新子窗口计数
sw.updateSegments()
// 计算当前窗口内的请求数
total := int64(0)
for _, count := range sw.segments {
total += count
}
// 检查是否超过阈值
if total >= sw.threshold {
return false
}
// 增加当前子窗口计数
sw.segments[sw.currentIdx]++
return true
}
// GetCurrentCount 获取当前窗口内的请求数
func (sw *SlidingWindow) GetCurrentCount() int64 {
sw.mu.RLock()
defer sw.mu.RUnlock()
// 更新子窗口计数
sw.updateSegments()
// 计算当前窗口内的请求数
total := int64(0)
for _, count := range sw.segments {
total += count
}
return total
}
熔断降级实现
// NewCircuitBreaker 创建新的熔断器
func NewCircuitBreaker(failureThreshold, successThreshold int64, timeout time.Duration) *CircuitBreaker {
return &CircuitBreaker{
state: StateClosed,
failureThreshold: failureThreshold,
successThreshold: successThreshold,
timeout: timeout,
stateChanged: make(chan State, 1),
}
}
// Execute 执行函数,带熔断保护
func (cb *CircuitBreaker) Execute(fn func() error) error {
// 检查熔断状态
if !cb.allowRequest() {
return errors.New("circuit breaker is open")
}
// 执行函数
err := fn()
// 记录执行结果
if err != nil {
cb.recordFailure()
} else {
cb.recordSuccess()
}
return err
}
// allowRequest 检查是否允许请求
func (cb *CircuitBreaker) allowRequest() bool {
cb.mu.Lock()
defer cb.mu.Unlock()
now := time.Now()
switch cb.state {
case StateClosed:
// 关闭状态,允许请求
return true
case StateOpen:
// 打开状态,检查是否超时
if now.Sub(cb.lastFailure) >= cb.timeout {
// 超时,切换到半开状态
cb.setState(StateHalfOpen)
return true
}
// 未超时,拒绝请求
return false
case StateHalfOpen:
// 半开状态,允许请求
return true
default:
return true
}
}
// recordFailure 记录失败
func (cb *CircuitBreaker) recordFailure() {
cb.mu.Lock()
defer cb.mu.Unlock()
switch cb.state {
case StateClosed:
// 关闭状态,增加失败计数
cb.failureCount++
cb.lastFailure = time.Now()
// 检查是否达到失败阈值
if cb.failureCount >= cb.failureThreshold {
cb.setState(StateOpen)
}
case StateHalfOpen:
// 半开状态,失败后切换到打开状态
cb.setState(StateOpen)
case StateOpen:
// 打开状态,更新上次失败时间
cb.lastFailure = time.Now()
}
}
// recordSuccess 记录成功
func (cb *CircuitBreaker) recordSuccess() {
cb.mu.Lock()
defer cb.mu.Unlock()
switch cb.state {
case StateClosed:
// 关闭状态,重置失败计数
cb.failureCount = 0
case StateHalfOpen:
// 半开状态,增加成功计数
cb.successCount++
// 检查是否达到成功阈值
if cb.successCount >= cb.successThreshold {
cb.setState(StateClosed)
}
case StateOpen:
// 打开状态,不处理
}
}
// setState 设置状态
func (cb *CircuitBreaker) setState(state State) {
if cb.state != state {
cb.state = state
// 重置计数
switch state {
case StateClosed:
cb.failureCount = 0
cb.successCount = 0
case StateOpen:
cb.failureCount = 0
cb.successCount = 0
case StateHalfOpen:
cb.successCount = 0
}
// 通知状态变化
select {
case cb.stateChanged <- state:
default:
// 通道已满,丢弃
}
}
}
// GetState 获取当前状态
func (cb *CircuitBreaker) GetState() State {
cb.mu.Lock()
defer cb.mu.Unlock()
return cb.state
}
// StateChanged 返回状态变化通知通道
func (cb *CircuitBreaker) StateChanged() <-chan State {
return cb.stateChanged
}
API网关集成示例
// NewAPIGateway 创建新的API网关
func NewAPIGateway() *APIGateway {
return &APIGateway{
routes: make(map[string]http.Handler),
globalLimiter: NewTokenBucket(1000, 1000), // 全局限流:1000 QPS
}
}
// RegisterRoute 注册路由
func (gw *APIGateway) RegisterRoute(path string, handler http.Handler, rateLimit int64) {
gw.routes[path] = handler
// 为路由创建限流桶
gw.limiters.Store(path, NewTokenBucket(rateLimit, float64(rateLimit)))
// 为路由创建熔断器
gw.circuitBreakers.Store(path, NewCircuitBreaker(5, 3, 30*time.Second))
}
// ServeHTTP 实现http.Handler接口
func (gw *APIGateway) ServeHTTP(w http.ResponseWriter, r *http.Request) {
// 检查全局限流
if !gw.globalLimiter.Allow() {
http.Error(w, "Too Many Requests (Global)", http.StatusTooManyRequests)
return
}
// 获取路由处理器
handler, ok := gw.routes[r.URL.Path]
if !ok {
http.Error(w, "Not Found", http.StatusNotFound)
return
}
// 获取路由限流桶
limiter, ok := gw.limiters.Load(r.URL.Path)
if !ok {
http.Error(w, "Internal Server Error", http.StatusInternalServerError)
return
}
// 检查路由限流
if !limiter.(*TokenBucket).Allow() {
http.Error(w, "Too Many Requests (Route)", http.StatusTooManyRequests)
return
}
// 获取路由熔断器
cb, ok := gw.circuitBreakers.Load(r.URL.Path)
if !ok {
http.Error(w, "Internal Server Error", http.StatusInternalServerError)
return
}
// 使用熔断器执行请求
err := cb.(*CircuitBreaker).Execute(func() error {
// 执行实际的请求处理
handler.ServeHTTP(w, r)
return nil
})
if err != nil {
http.Error(w, fmt.Sprintf("Service Unavailable: %v", err), http.StatusServiceUnavailable)
return
}
}
理论知识支撑
漏桶算法 vs 令牌桶算法
漏桶算法和令牌桶算法是两种常用的限流算法,它们的区别在于:
- 漏桶算法: 请求以固定速率处理,无论请求速率如何变化,处理速率始终保持不变。这种算法适合于对处理速率有严格要求的场景,但无法处理突发流量。
- 令牌桶算法: 令牌以固定速率生成,请求需要获取令牌才能执行。这种算法允许一定程度的突发流量,适合于大多数场景。
Go语言通过原子操作和协程调度,可以高效地实现令牌桶算法,支持百万级QPS的限流。
滑动窗口统计
滑动窗口统计是一种更精确的限流算法,通过维护一个滑动的时间窗口,统计窗口内的请求数。与固定时间窗口相比,滑动窗口可以避免固定时间窗口的临界问题(如最后一秒集中请求),提高限流精度。
在实现滑动窗口时,我们将时间窗口分割为多个子窗口,每个子窗口维护一个计数。当时间滑动时,旧的子窗口计数会被重置,新的子窗口计数会被更新。这种实现方式可以在保证精度的同时,降低计算复杂度。
Hystrix熔断机制
Hystrix是Netflix开源的熔断框架,用于防止分布式系统中的级联失败。Hystrix的核心思想是:当某个服务出现故障时,快速失败,避免将故障传播到其他服务。
Go语言的context包和semaphore包为实现熔断机制提供了高效的工具。通过context.WithTimeout可以设置请求超时时间,当请求超时或失败次数达到阈值时,自动触发熔断。
分布式限流一致性
在分布式环境下,多个API网关实例之间需要共享限流状态,确保全局限流的准确性。常用的分布式限流方案包括:
- 基于Redis的分布式限流: 使用Redis的原子操作(如INCR、EXPIRE)实现分布式限流
- 基于Etcd的分布式限流: 使用Etcd的分布式锁和键值存储实现分布式限流
- 基于Sentinel的分布式限流: 使用Sentinel的集群限流功能实现分布式限流
在实现分布式限时,需要权衡一致性和性能。强一致性方案(如基于Redis的分布式锁)性能较低,而最终一致性方案(如基于Redis的滑动窗口)性能较高,但可能存在一定的误差。
五、场景4:分布式任务队列(Redis Stream)
场景描述
分布式任务队列是现代系统中的重要组件,用于处理异步任务、批量处理和后台作业。 例如,电商系统的订单处理、物流跟踪、数据分析等都可以通过分布式任务队列来实现。在高并发场景下,分布式任务队列需要处理大量的任务,同时保证任务的可靠性和顺序性。
问题矛盾点
传统的分布式任务队列(如RabbitMQ、Kafka)在高并发场景下面临以下几大痛点:
- 消息可靠性不足: 网络分区或消费者崩溃时,消息可能丢失(AT LEAST ONCE语义难以保证)。例如,RabbitMQ在默认配置下,如果消费者在处理消息时崩溃,消息会被重新投递,但可能导致消息重复处理。
- 扩展性受限: 分区数固定,无法动态扩容,高峰期吞吐量瓶颈明显。例如,Kafka的分区数在创建主题时固定,无法动态增加,限制了系统的扩展性。
- 运维复杂度高: 需要部署和维护多个组件(如ZooKeeper、Broker、Consumer),增加了运维成本。例如,RabbitMQ需要部署多个Broker节点和Cluster,Kafka需要部署ZooKeeper集群和Broker集群。
- 延迟不可控: 在高负载场景下,消息延迟可能会显著增加。例如,Kafka在高峰期可能会出现消息堆积,导致延迟达到分钟级。
- 顺序性保证困难: 在分布式环境下,保证消息的顺序性是一个复杂的问题。例如,RabbitMQ的队列可以保证消息的顺序性,但在多个消费者的情况下,顺序性难以保证。
Go解决方案核心技术
Redis Stream + Consumer Group
Redis Stream是Redis 5.0引入的新数据类型,专为消息队列设计,支持持久化、消费者组、消息确认等功能。Go语言通过github.com/go-redis/redis/v8包可以轻松实现Redis Stream的生产者和消费者。
持久化存储
Redis Stream将所有消息持久化到磁盘,即使Redis重启,消息也不会丢失。这确保了消息的可靠性,支持AT LEAST ONCE语义。
消费者组机制
消费者组是Redis Stream的核心特性,它允许多个消费者组成一个组,共同消费一个Stream的消息。消费者组内的消息分配采用轮询方式,每个消息只会被组内的一个消费者消费。同时,消费者组支持消息确认机制,只有当消费者确认消息处理完成后,消息才会从组内移除。
消息ID与顺序性
每个消息都有一个唯一的ID,格式为时间戳-序列号。消息ID是单调递增的,确保了消息的顺序性。消费者可以通过消息ID来定位和消费消息,支持从任意位置开始消费。
代码实现
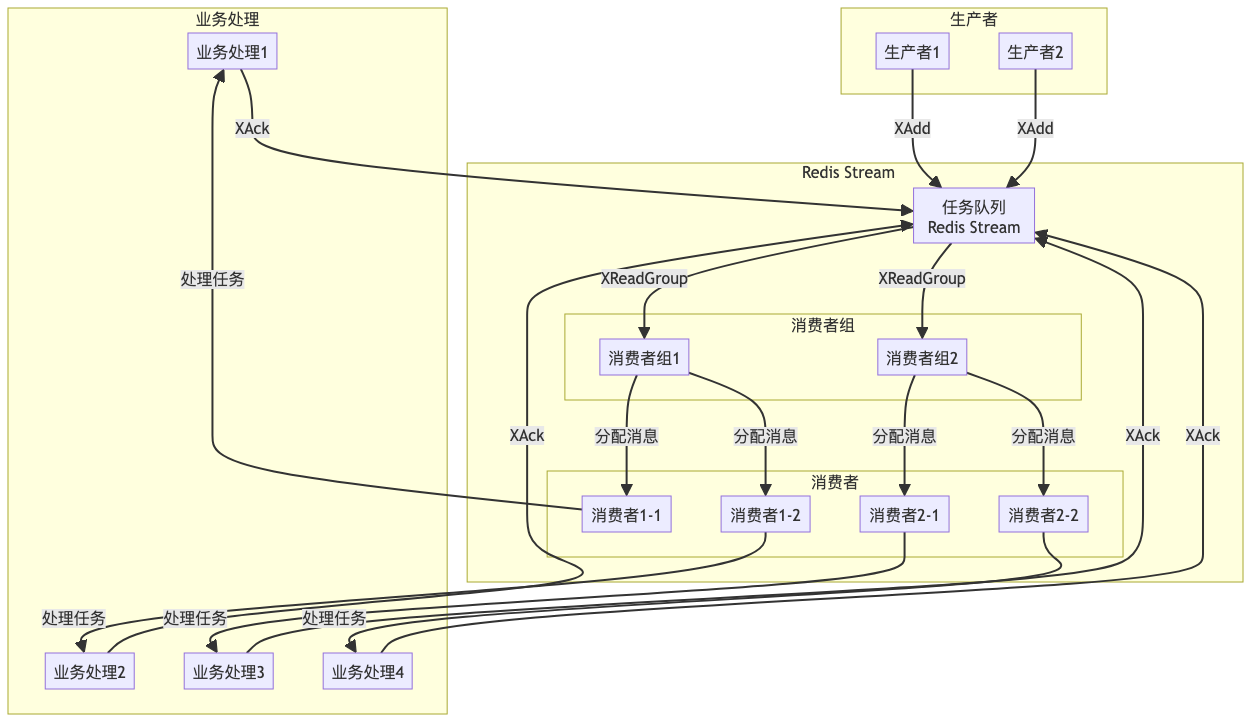
Redis Stream生产者实现
// NewRedisProducer 创建新的Redis Stream生产者
func NewRedisProducer(client *redis.Client, stream string) *RedisProducer {
return &RedisProducer{
client: client,
stream: stream,
}
}
// Produce 生产任务
func (p *RedisProducer) Produce(ctx context.Context, task *Task) (string, error) {
// 序列化任务
payload, err := json.Marshal(task)
if err != nil {
return "", err
}
// 发布任务到Redis Stream
msgID, err := p.client.XAdd(ctx, &redis.XAddArgs{
Stream: p.stream,
Values: map[string]interface{}{
"task": string(payload),
},
MaxLen: 10000, // 保留最新的10000条消息
Approx: true, // 近似截断,提高性能
}).Result()
if err != nil {
return "", err
}
return msgID, nil
}
Redis Stream消费者实现
// Start 启动消费者
func (c *RedisConsumer) Start(ctx context.Context, wg *sync.WaitGroup) error {
defer wg.Done()
// 创建消费者组(如果不存在)
_, err := c.client.XGroupCreateMkStream(ctx, c.stream, c.group, "$").Result()
if err != nil && err != redis.Nil {
// 如果错误不是"消费者组已存在",则返回错误
return err
}
log.Printf("Consumer %s started, group: %s, stream: %s", c.name, c.group, c.stream)
// 持续消费消息
for {
select {
case <-ctx.Done():
// 上下文取消,停止消费
log.Printf("Consumer %s stopped", c.name)
return nil
default:
// 消费消息
err := c.consume(ctx)
if err != nil {
log.Printf("Error consuming messages: %v", err)
// 短暂休眠后重试
time.Sleep(1 * time.Second)
}
}
}
}
// consume 消费消息
func (c *RedisConsumer) consume(ctx context.Context) error {
// 从Redis Stream读取消息
msgs, err := c.client.XReadGroup(ctx, &redis.XReadGroupArgs{
Group: c.group,
Consumer: c.name,
Streams: []string{c.stream, " > "}, // " > " 表示从最新消息开始消费
Count: int64(c.batchSize), // 批量读取消息
Block: c.blockTimeout, // 阻塞时间
}).Result()
if err != nil {
return err
}
// 处理每条消息
for _, msgStream := range msgs {
for _, msg := range msgStream.Messages {
// 解析任务
var task Task
taskData, ok := msg.Values["task"].(string)
if !ok {
log.Printf("Invalid task data: %v", msg.Values["task"])
// 确认消息,避免消息堆积
c.client.XAck(ctx, c.stream, c.group, msg.ID)
continue
}
if err := json.Unmarshal([]byte(taskData), &task); err != nil {
log.Printf("Failed to unmarshal task: %v", err)
// 确认消息,避免消息堆积
c.client.XAck(ctx, c.stream, c.group, msg.ID)
continue
}
// 处理任务
log.Printf("Consumer %s processing task: %s, message ID: %s", c.name, task.ID, msg.ID)
if err := c.processor(ctx, &task); err != nil {
log.Printf("Failed to process task %s: %v", task.ID, err)
// 不确认消息,让其他消费者重试
continue
}
// 确认消息处理完成
if err := c.client.XAck(ctx, c.stream, c.group, msg.ID).Err(); err != nil {
log.Printf("Failed to acknowledge task %s: %v", task.ID, err)
continue
}
log.Printf("Consumer %s processed task: %s, message ID: %s", c.name, task.ID, msg.ID)
}
}
return nil
}
// 示例任务处理器
func taskProcessor(ctx context.Context, task *Task) error {
// 模拟任务处理
time.Sleep(100 * time.Millisecond)
log.Printf("Processed task: %s, type: %s, payload: %s", task.ID, task.Type, task.Payload)
return nil
}
理论知识支撑
发布-订阅模式
发布-订阅模式是一种消息传递模式,其中发布者将消息发送到特定的主题,订阅者通过订阅主题来接收消息。Redis Stream实现了发布-订阅模式,同时支持持久化和消费者组功能。
消费组机制
消费者组机制是Redis Stream的核心特性,它允许多个消费者组成一个组,共同消费一个Stream的消息。消费者组内的消息分配采用轮询方式,每个消息只会被组内的一个消费者消费。这种机制可以实现负载均衡和高可用性。
CAP理论取舍
CAP理论指出,在分布式系统中,一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)三者不可兼得。 Redis Stream在设计上牺牲了部分分区容错性(P),换取了强一致性(C)和可用性(A)。当发生网络分区时,Redis Stream可能会出现暂时的不可用,但一旦分区恢复,系统会自动恢复一致性。
幂等性设计
在分布式系统中,消息可能会被重复投递,因此任务处理器需要支持幂等性。幂等性是指多次执行同一个操作,结果与执行一次相同。常用的幂等性设计方案包括:
- 使用唯一ID: 为每个任务分配一个唯一ID,处理器通过检查ID是否已处理来避免重复处理
- 状态机设计: 将任务处理设计为状态机,只有在特定状态下才能执行操作
- 分布式锁: 使用分布式锁确保同一任务同一时间只能被一个处理器处理
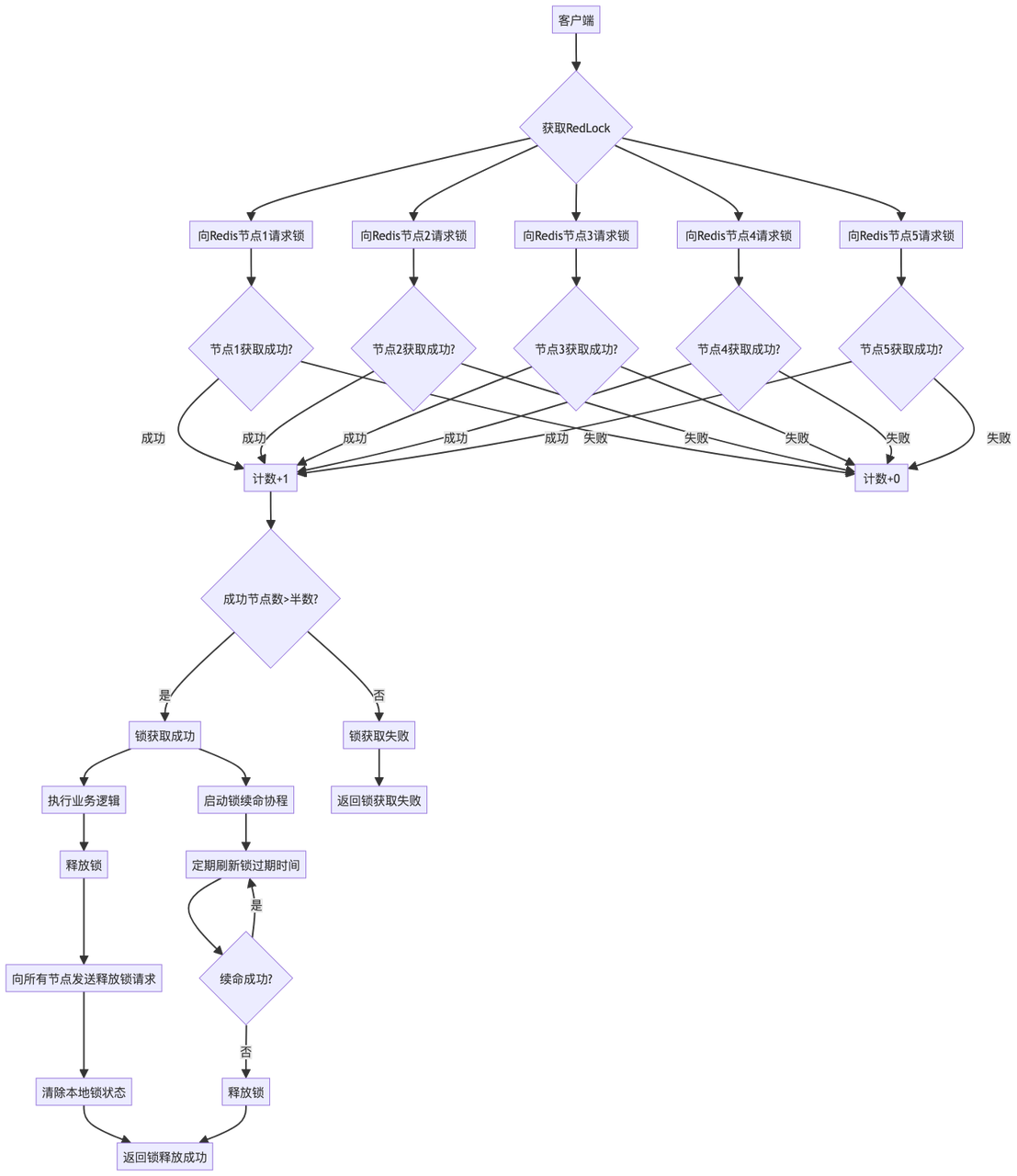
六、场景5:分布式锁(Redis RedLock)
场景描述
分布式锁是分布式系统中的重要组件,用于解决多个进程或服务之间的资源竞争问题。例如,在电商系统中,多个服务实例需要同时访问同一个商品库存,此时就需要使用分布式锁来确保库存操作的原子性。在高并发场景下,分布式锁需要具备高性能、高可用性和安全性。
问题矛盾点
传统的分布式锁方案(如基于Redis的SETNX)在高并发场景下面临以下几大风险:
- 时钟回拨问题: 服务器时间跳跃导致锁过期,引发并发冲突。例如,当一个客户端获取锁后,服务器时钟发生回拨,导致锁提前过期,此时其他客户端可以获取到同一个锁,引发并发问题。
- 脑裂现象: 集群模式下,部分节点认为锁已释放,实际仍有持有者。例如,在Redis主从架构中,当主节点宕机时,从节点升级为主节点,但主节点上的锁信息可能还未同步到从节点,此时其他客户端可以获取到同一个锁。
- 性能瓶颈: 单实例Redis QPS上限约5万,大规模集群场景下锁竞争加剧。当多个客户端同时请求同一个锁时,会导致Redis成为性能瓶颈。
- 死锁风险: 当客户端获取锁后崩溃,锁可能永远不会释放。虽然可以通过设置过期时间来避免,但如果任务执行时间超过锁的过期时间,仍然可能导致并发冲突。
- 锁粒度问题: 传统分布式锁通常是粗粒度的,无法实现细粒度的资源控制。例如,当多个客户端需要访问同一资源的不同部分时,传统分布式锁会导致资源竞争加剧,降低系统吞吐量。
Go解决方案核心技术
Redis RedLock算法
RedLock是Redis官方推荐的分布式锁算法,通过在多个独立的Redis节点上获取锁,确保在大多数节点成功获取锁时才认为锁获取成功。Go语言可以高效地实现RedLock算法,结合github.com/go-redis/redis/v8包可以轻松与Redis集群交互。
多节点锁获取
RedLock算法的核心思想是:客户端需要在多个独立的Redis节点上获取锁,只有当在超过半数的节点上成功获取锁时,才认为锁获取成功。 这种设计可以避免单点故障和脑裂问题,提高锁的可靠性。
锁续命机制
通过定时器定期刷新锁的过期时间,确保在任务执行期间锁不会过期。这种机制可以解决锁过期时间与任务执行时间不匹配的问题,避免并发冲突。
细粒度锁控制
使用Redis的哈希结构实现细粒度的锁控制,允许客户端只锁定资源的特定部分,提高系统的并发处理能力。
代码实现
RedLock算法实现
// Lock 获取分布式锁
func (rl *RedLock) Lock(ctx context.Context, key string) (bool, error) {
// 生成随机锁值
value := rl.generateRandomValue()
// 计算锁的过期时间
expireAt := time.Now().Add(rl.ttl).UnixNano() / int64(time.Millisecond)
// 重试获取锁
for i := 0; i < rl.retryCount; i++ {
// 在多个Redis节点上获取锁
successCount := 0
for _, client := range rl.clients {
success, err := rl.tryLock(ctx, client, key, value, rl.ttl)
if err != nil {
continue
}
if success {
successCount++
}
}
// 检查是否在大多数节点上成功获取锁
if successCount > len(rl.clients)/2 {
// 计算实际过期时间(考虑时钟漂移)
actualExpireAt := expireAt - rl.clockDrift
if actualExpireAt > time.Now().UnixNano()/int64(time.Millisecond) {
// 成功获取锁,记录锁信息
rl.mu.Lock()
rl.lockedKeys[key] = true
rl.lockValues[key] = value
rl.mu.Unlock()
// 启动锁续命协程
go rl.extendLock(ctx, key, value)
return true, nil
}
}
// 短暂休眠后重试
time.Sleep(rl.retryDelay)
}
return false, nil
}
// tryLock 在单个Redis节点上尝试获取锁
func (rl *RedLock) tryLock(ctx context.Context, client *redis.Client, key, value string, ttl time.Duration) (bool, error) {
// 使用SETNX命令获取锁
success, err := client.SetNX(ctx, key, value, ttl).Result()
if err != nil {
return false, err
}
return success, nil
}
// extendLock 锁续命
func (rl *RedLock) extendLock(ctx context.Context, key, value string) {
// 续命间隔为TTL的1/3
extendInterval := rl.ttl / 3
ticker := time.NewTicker(extendInterval)
defer ticker.Stop()
for {
select {
case <-ctx.Done():
// 上下文取消,停止续命
return
case <-ticker.C:
// 检查锁是否已释放
rl.mu.Lock()
if !rl.lockedKeys[key] {
rl.mu.Unlock()
return
}
rl.mu.Unlock()
// 续命锁
successCount := 0
for _, client := range rl.clients {
// 只有当锁值匹配时才续命
script := `
if redis.call("GET", KEYS[1]) == ARGV[1] then
return redis.call("PEXPIRE", KEYS[1], ARGV[2])
else
return 0
end
`
success, err := client.Eval(ctx, script, []string{key}, value, rl.ttl.Milliseconds()).Int()
if err != nil {
continue
}
if success == 1 {
successCount++
}
}
// 检查是否在大多数节点上成功续命
if successCount <= len(rl.clients)/2 {
// 续命失败,释放锁
rl.Unlock(ctx, key)
return
}
}
}
}
// Unlock 释放分布式锁
func (rl *RedLock) Unlock(ctx context.Context, key string) error {
// 检查锁是否已获取
rl.mu.Lock()
value, ok := rl.lockValues[key]
if !ok || !rl.lockedKeys[key] {
rl.mu.Unlock()
return nil
}
// 清除锁信息
delete(rl.lockedKeys, key)
delete(rl.lockValues, key)
rl.mu.Unlock()
// 在所有Redis节点上释放锁
for _, client := range rl.clients {
// 只有当锁值匹配时才释放
script := `
if redis.call("GET", KEYS[1]) == ARGV[1] then
return redis.call("DEL", KEYS[1])
else
return 0
end
`
_, err := client.Eval(ctx, script, []string{key}, value).Int()
if err != nil {
return err
}
}
return nil
}
理论知识支撑
Fencing Token
Fencing Token是一种防止旧客户端继续操作的机制。每次获取锁时,生成一个唯一递增的Token,客户端在执行操作时需要携带这个Token。服务端通过检查Token的有效性来确保只有最新获取锁的客户端才能执行操作。
Quorum算法
Quorum算法是指在分布式系统中,只有当超过半数的节点同意某个操作时,才认为该操作有效。RedLock算法基于Quorum算法,要求在超过半数的Redis节点上成功获取锁才认为锁获取成功,避免了脑裂问题。
时钟回拨防御
时钟回拨是指服务器时钟突然向后跳跃,导致锁提前过期。RedLock算法通过记录锁创建时的物理时间戳,并在检查锁有效性时考虑时钟漂移,来防御时钟回拨问题。
细粒度锁设计
细粒度锁是指将锁的粒度细化到资源的特定部分,而不是整个资源。例如,当多个客户端需要访问同一商品的不同SKU库存时,可以使用细粒度锁只锁定特定SKU的库存,而不是整个商品的库存。这种设计可以提高系统的并发处理能力。
七、结论:Go语言的核心竞争力
通过上述五个典型场景的分析,我们可以看出Go语言在构建高并发高可用系统方面具有显著的优势。这些优势主要体现在以下几个方面:
- 极致并发模型
Go语言的Goroutine和Channel是其并发模型的核心,Goroutine的调度开销比线程低100倍,适合百万级并发场景。Goroutine的创建和销毁开销极小,内存占用仅为2KB左右,而线程的内存占用通常为MB级别。此外,Go语言的调度器采用M:N模型,将多个Goroutine映射到少数几个OS线程上,减少了OS线程的上下文切换开销。
- 高性能网络库
Go语言的标准库(如net/http、net/grpc)基于epoll/kqueue等事件驱动机制实现,支持零拷贝I/O,延迟可控制在1ms内。这些网络库已经过广泛的生产验证,在高并发场景下表现优异。此外,Go语言的网络库支持多路复用和异步I/O,能够高效地处理大量并发连接。
- 内存安全与原子操作
Go语言通过垃圾回收机制和类型系统确保内存安全,避免了常见的内存错误(如缓冲区溢出、野指针)。同时,Go语言的sync/atomic包提供了高效的原子操作,支持无锁编程,避免了数据竞争问题。这些特性使得Go语言在高并发场景下具有良好的稳定性和可靠性。
- 简洁的并发编程模型
Go语言的并发编程模型非常简洁,通过Goroutine和Channel可以轻松实现复杂的并发逻辑。与传统的线程+锁模型相比,Go语言的并发编程模型更加安全、高效和易用。例如,通过select语句可以同时监听多个Channel,实现非阻塞的I/O操作;通过sync.WaitGroup可以轻松实现多个Goroutine的同步。
- 丰富的生态系统
Go语言拥有丰富的生态系统,从微服务框架(如Kratos、Gin)到分布式存储(如Etcd、TiKV),从消息队列(如NATS、NSQ)到监控系统(如Prometheus、Grafana),形成了完整的高可用解决方案栈。这些开源项目已经过广泛的生产验证,能够帮助开发者快速构建高并发高可用系统。
- 编译型语言的高性能
Go语言是一种编译型语言,编译后生成的二进制文件可以直接运行,无需解释器。与解释型语言(如Python、JavaScript)相比,Go语言具有更高的执行效率。此外,Go语言的编译器优化做得非常好,能够生成高效的机器码,进一步提高了系统的性能。
- 强大的标准库
Go语言的标准库非常强大,提供了丰富的功能,包括网络通信、并发控制、加密解密、文件操作等。这些标准库经过精心设计和优化,具有良好的性能和可靠性。开发者可以直接使用标准库构建复杂的系统,无需依赖大量的第三方库,减少了依赖管理的复杂度。
八、总结
Go语言凭借其独特的设计哲学和技术特性,成为了构建高并发高可用系统的首选语言之一。通过上述五个典型场景的分析,我们可以看出Go语言在处理微服务通信、实时消息推送、API网关限流与熔断、分布式任务队列和分布式锁等场景时具有显著的优势。
Go语言的核心竞争力在于其极致的并发模型、高性能的网络库、内存安全与原子操作、简洁的并发编程模型、丰富的生态系统、编译型语言的高性能以及强大的标准库。这些特性使得Go语言在高并发高可用系统中表现优异,能够帮助开发者快速构建可靠、高效的分布式系统。
随着互联网技术的不断发展,高并发高可用系统的需求将越来越普遍。Go语言作为一种专为并发设计的编程语言,必将在未来的分布式系统中发挥越来越重要的作用。
往期回顾
1.项目性能优化实践:深入FMP算法原理探索|得物技术
2.Dragonboat统一存储LogDB实现分析|得物技术
3.从数字到版面:得物数据产品里数字格式化的那些事
4.RN与hawk碰撞的火花之C++异常捕获|得物技术
5.大模型如何革新搜索相关性?智能升级让搜索更”懂你”|得物技术
文 /悟
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


