
<p>今天主要看SeaTunnel自研的数据同步引擎,叫Zeta。 首先,如果使用的是zeta引擎,那么第一步一定是运行bin/seatunnel-cluster.sh脚本,这个脚本就是启动zeta的服务端的。</p> 打开seatunnel-cluster.sh看看,可以看到其实是去启动seatunnel-core/seatunnel-starter/src/main/java/org/apache/seatunnel/core/starter/seatunnel/SeaTunnelServer.java中的main()方法
这个就是zeta的核心启动方法了。
如下方代码所示:
public class SeaTunnelServer {
public static void main(String[] args) throws CommandException {
ServerCommandArgs serverCommandArgs =
CommandLineUtils.parse(
args,
new ServerCommandArgs(),
EngineType.SEATUNNEL.getStarterShellName(),
acceptUnknownOptions: true
);
SeaTunnel.run(serverCommandArgs.buildCommand());
}
}
其实应该先看看ServerCommandArgs类,该类会基于命令参数拼装启动类,方法入口为serverCommandArgs.buildCommand()
@EqualsAndHashCode(callSuper = true)
@Data
public class ServerCommandArgs extends CommandArgs {
@Parameter(
names = {"-cn", "--cluster"},
description = "The name of cluster"
)
private String clusterName;
@Parameter(
names = {"-d", "--daemon"},
description = "The cluster daemon mode"
)
private boolean daemonMode = false;
@Parameter(
names = {"-r", "--role"},
description =
"The cluster node role, default is master_and_worker, " +
"support master, worker, master_and_worker"
)
private String clusterRole;
@Override
public Command<?> buildCommand() {
return new ServerExecuteCommand(this);
}
}
接着SeaTunnel.run()会启动SeaTunnelServer,启动流程如下:
共分为以下步骤:
1)校验当前环境 2)加载SeaTunnel配置 3)设置节点角色,包含Master、Worker、Master_And_Worker 4)创建Hazelcast实例,用于集群发现、注册、分布式数据管理等
@Override
public void execute() {
// Validate environment
checkEnvironment();
// Load SeaTunnel configuration
SeaTunnelConfig seaTunnelConfig = ConfigProvider.locateAndGetSeaTunnelConfig();
String clusterRole = this.serverCommandArgs.getClusterRole();
// Set node role
if (StringUtils.isNotBlank(clusterRole)) {
if (EngineConfig.ClusterRole.MASTER.toString().equalsIgnoreCase(clusterRole)) {
seaTunnelConfig.getEngineConfig().setClusterRole(EngineConfig.ClusterRole.MASTER);
} else if (EngineConfig.ClusterRole.WORKER.toString().equalsIgnoreCase(clusterRole)) {
seaTunnelConfig.getEngineConfig().setClusterRole(EngineConfig.ClusterRole.WORKER);
// In Hazelcast lite node, it will not store IMap data.
seaTunnelConfig.getHazelcastConfig().setLiteMember(true);
} else {
throw new SeaTunnelEngineException("Not supported cluster role: " + clusterRole);
}
} else {
seaTunnelConfig.getEngineConfig().setClusterRole(EngineConfig.ClusterRole.MASTER_AND_WORKER);
}
// Create Hazelcast instance for cluster discovery, registration, and distributed data management
SeaTunnelServerStarter.createHazelcastInstance(seaTunnelConfig, Thread.currentThread().getName());
}
节点角色说明:
- Master 节点:
- 核心职责:负责集群的作业调度、状态管理及资源协调。Master 节点运行 CoordinatorService 服务,处理作业的逻辑计划(LogicalDAG)到物理计划(PhysicalDAG)的转换,并生成执行计划。此外,它还管理检查点(Checkpoint)机制和作业监控指标。
- 高可用性:采用 Active/Standby 模式,同一时间仅有一个 Active Master,其余为 Standby。当 Active Master 故障时,会触发选举新 Master,确保集群持续运行。
- 数据存储:通过内置的分布式内存网格(如 Hazelcast IMap)存储作业状态和元数据,无需依赖外部系统(如 ZooKeeper)。在分离部署模式下,所有状态数据仅存储在 Master 节点,避免 Worker 节点负载影响数据稳定性。
- Worker 节点:
- 核心职责:执行具体的数据处理任务。Worker 节点运行 TaskExecutionService 和 SlotService,前者提供任务运行时环境,后者管理节点的资源分配(如 CPU 核心数)。
- 动态资源分配:通过 SlotService 实现资源的动态划分,支持按任务并行度动态调整资源,提升资源利用率。
- 无状态设计:Worker 节点不存储作业状态数据,仅负责计算。在容错场景下,Worker 故障后任务会被重新调度到其他节点,依赖 Master 存储的状态恢复。
- 混合角色节点(旧架构):
- 在早期版本中,节点角色未严格分离,同一节点可同时作为 Master 和 Worker(称为 master_and_worker 模式)。此架构下,节点既参与调度又执行任务,但在高负载场景下可能导致容错效率问题(如主节点故障引发连锁负载压力)。
- 新架构优化:2.3.6 版本后推荐分离部署模式,彻底解耦 Master 与 Worker 角色,提升集群稳定性和扩展性。
接着回到上面的创建Hazelcast实例:
如下所示,核心代码为:HazelcastInstanceFactory.newHazelcastInstance方法,该方法表示创建了Hazelcast实例;
private static HazelcastInstanceImpl initializeHazelcastInstance(
@NonNull SeaTunnelConfig seaTunnelConfig, String customInstanceName) {
// Set the default async executor for Hazelcast InvocationFuture
ConcurrencyUtil.setDefaultAsyncExecutor(CompletableFuture.EXECUTOR);
// Check whether to enable metrics reporting
boolean condition = checkTelemetryConfig(seaTunnelConfig);
String instanceName = customInstanceName != null
? customInstanceName
: HazelcastInstanceFactory.createInstanceName(seaTunnelConfig.getHazelcastConfig());
// Create Hazelcast instance
HazelcastInstanceImpl original = ((HazelcastInstanceProxy)
HazelcastInstanceFactory.newHazelcastInstance(
seaTunnelConfig.getHazelcastConfig(),
instanceName,
new SeaTunnelNodeContext(seaTunnelConfig)))
.getOriginal();
// Initialize telemetry instance
// Enable metrics reporting, including: JvmCollector, JobInfoDetail, ThreadPoolStatus, NodeMetrics, ClusterMetrics
if (condition) {
initTelemetryInstance(original.node);
}
return original;
}
其中,最重要的就是这句代码中的new SeaTunnelNodeContext(seaTunnelConfig),这里会返回一个SeaTunnelNodeContext类,这个类是继承自Hazelcast这个组件的DefaultNodeContext类。在Hazelcast启动的过程中,会去调用DefaultNodeContext类的实现类的createNodeExtension()方法,在这里其实也就是SeaTunnelNodeContext类的createNodeExtension()方法。这里不具体展开讲解Hazelcast类,大家可以去查一下其他Hazelcast资料。
然后我们接着分析在Hazelcast节点启动时会调用createNodeExtension方法
@Slf4j
public class SeaTunnelNodeContext extends DefaultNodeContext {
private final SeaTunnelConfig seaTunnelConfig;
public SeaTunnelNodeContext(@NonNull SeaTunnelConfig seaTunnelConfig) {
this.seaTunnelConfig = seaTunnelConfig;
}
@Override
public NodeExtension createNodeExtension(@NonNull Node node) {
return new org.apache.seatunnel.engine.server.NodeExtension(node, seaTunnelConfig);
}
}
这里跟踪进去,查看节点扩展的实现,这里初始化了Zeta引擎。
SeaTunnelServe类实现了一系列Hazelcast接口,用于监听集变更状态,包含:节点初始化、集群节点加入/移除,跟踪和管理分布式系统操作;
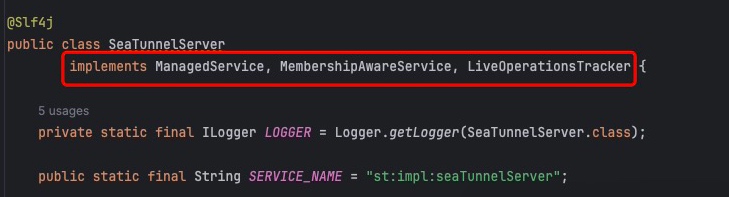
接下来依次分析各个操作:
1)节点初始化:
这个初始化方法为SeaTunnel服务器提供了完整的启动流程,确保了各个服务组件的正确初始化和配置;
核心方法包括: startMaster()方法和startWorker()方法
@Override
public void init(NodeEngine engine, Properties hzProperties) {
this.nodeEngine = (NodeEngineImpl) engine;
// TODO: Decide whether to run these methods on the master node based on deployment type
classLoaderService = new DefaultClassLoaderService(
seaTunnelConfig.getEngineConfig().isClassLoaderCacheMode(), nodeEngine);
// Handles event processing and forwarding
eventService = new EventService(nodeEngine);
// Start Master / Worker capabilities
if (EngineConfig.ClusterRole.MASTER_AND_WORKER.ordinal()
== seaTunnelConfig.getEngineConfig().getClusterRole().ordinal()) {
startWorker();
startMaster();
} else if (EngineConfig.ClusterRole.WORKER.ordinal()
== seaTunnelConfig.getEngineConfig().getClusterRole().ordinal()) {
startWorker();
} else {
startMaster();
}
// SeaTunnel health-check monitor
seaTunnelHealthMonitor = new SeaTunnelHealthMonitor(((NodeEngineImpl) engine).getNode());
// Task log management service
if (seaTunnelConfig.getEngineConfig().getTelemetryConfig() != null
&& seaTunnelConfig.getEngineConfig().getTelemetryConfig().getLogs() != null
&& seaTunnelConfig.getEngineConfig().getTelemetryConfig().getLogs().isEnabled()) {
taskLogManagerService = new TaskLogManagerService(
seaTunnelConfig.getEngineConfig().getTelemetryConfig().getLogs());
taskLogManagerService.initClean();
}
// Start Jetty service: provides HTTP REST API, Web UI, job management, monitoring endpoints, etc.
if (seaTunnelConfig.getEngineConfig().getHttpConfig().isEnabled()) {
jettyService = new JettyService(nodeEngine, seaTunnelConfig);
jettyService.createJettyServer();
}
// A trick to fix StatisticsDataReference cleaner thread class-loader leak.
// See https://issues.apache.org/jira/browse/HADOOP-19049
FileSystem.Statistics statistics = new FileSystem.Statistics("SeaTunnel");
}
首先是startMaster方法,主要初始化了协调器服务、检查点服务、监控服务;
各个服务职责如下:
-
协调器服务:负责作业调度管理、集群资源协同、任务分配、状态同步等;
-
检查点服务:检查点管理、数据一致性保证、故障恢复支持、状态保存和恢复等;
-
监控服务:定期打印执行信息、监控系统状态、性能指标收集;
private void startMaster() { // Initialize coordinator service coordinatorService = new CoordinatorService(nodeEngine, this, seaTunnelConfig.getEngineConfig());
// Initialize checkpoint service checkpointService = new CheckpointService(seaTunnelConfig.getEngineConfig().getCheckpointConfig()); // Initialize monitoring service monitorService = Executors.newSingleThreadScheduledExecutor(); monitorService.scheduleAtFixedRate( this::printExecutionInfo, 0, // initial delay seaTunnelConfig.getEngineConfig().getPrintExecutionInfoInterval(), TimeUnit.SECONDS);}
其次是startWorker方法,这里重点介绍TaskExecutionService服务,通过这个服务,SeaTunnel能够高效地执行各种数据处理任务,同时保证系统的稳定性和可靠性;
private void startWorker() {
// 1. Initialize task execution service
taskExecutionService = new TaskExecutionService(classLoaderService, nodeEngine, eventService);
// 2. Register metrics collector
nodeEngine.getMetricsRegistry().registerDynamicMetricsProvider(taskExecutionService);
// 3. Start task execution service
taskExecutionService.start();
// 4. Initialize slot service
getSlotService();
}
其实在SeaTunnelServer最核心的就是调用TaskExecutionService类的start()方法,基本流程如下图所示:
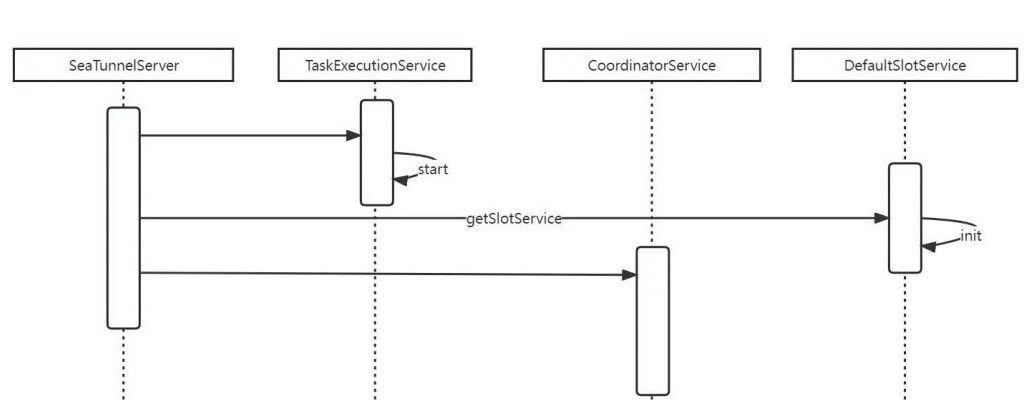
这里引用来自一篇官方文章的介绍文字:
- TaskExecutionService TaskExecutionService 是一个执行任务的服务,将在每个节点上运行一个实例。它从 JobMaster 接收 TaskGroup 并在其中运行 Task。并维护TaskID->TaskContext,对Task的具体操作都封装在TaskContext中。而Task内部持有OperationService,也就是说Task可以通过OperationService远程调用其他Task或JobMaster进行通信。
- CoordinatorService CoordinatorService是一个充当协调器的服务,它主要负责处理客户端提交的命令以及切换master后任务的恢复。客户端在提交任务时会找到master节点并将任务提交到CoordinatorService服务上,CoordinatorService会缓存任务信息并等待任务执行结束。当任务结束后再对任务进行归档处理。
- SlotService SlotService是slot管理服务,用于管理集群的可用Slot资源。SlotService运行在所有节点上并定期向master上报资源信息。
2)集群节点加入/移除:
memberAdded:处理集群成员加入事件
memberRemoved:处理集群成员离开事件
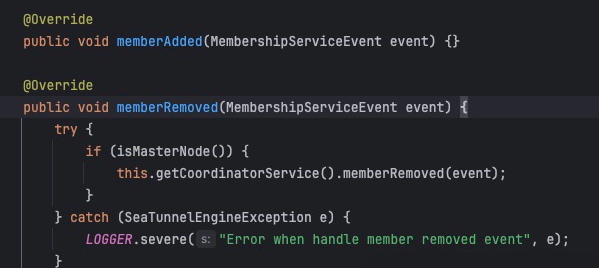
这里说明下问什么memberAdded是空实现:
a) 设计考虑:
成员加入是一个正常的事件,不需要特殊处理;
新成员加入时会自动进行初始化;
资源分配和任务调度是动态的;
b)实际原因:
新成员加入时,会通过其他机制(如SlotService)自动处理资源分配;
任务调度是动态的,不需要在成员加入时特别处理;
保持简单性,避免不必要的复杂性;
memberRemoved主要处理逻辑:只在主节点上处理成员移除事件,成员移除需要处理的关键问题:
a)资源回收:释放离开节点的资源、重新分配任务、清理相关状态;
b)任务重分配:重新分配离开节点的任务、确保任务继续执行、维护任务状态
c)状态维护:更新集群状态、维护成员列表、更新资源分配;
为什么需要memberRemoved:
a)可靠性考虑:节点离开可能影响任务执行、需要确保数据一致性、需要保证系统可用性;
b)资源管理:需要及时释放资源、需要重新分配任务、需要维护集群状态;
3)跟踪和管理分布式系统操作:
实现是空的,说明在当前版本没有特别需要跟踪的操作;
@Override
public void populate(LiveOperations liveOperations) {
// In SeaTunnelServer this implementation is empty,
// indicating the current version has no special operations to track.
}
最后,分享一个在本地Idea环境启动过程中的问题:
如下所示,官方默认配置为hdfs方式,由于本地缺少hdfs环境,因此会阻碍服务启动,调整为localfile本地即可启动。
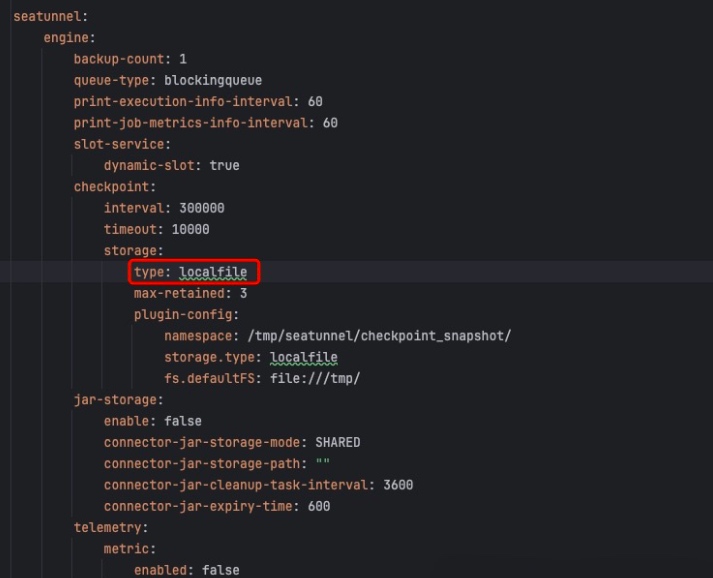
最后,访问localhost:8080即可查看服务状态: 
</div>相关推荐
- 「第三届开放原子大赛」获奖队伍专访来啦!企业篇
- 从本体论到落地实践:制造业数字化转型的核心逻辑与工具选择 | 葡萄城技术团队
- 轻松搞定Excel公式错误:SpreadJS让表格开发不再头疼 | 葡萄城技术团队
- vivo GPU容器与 AI 训练平台探索与实践
- SQLShift V6.0 发布!函数迁移&达梦适配一步到位!
- Oinone × AI Agent 落地指南:别让 AI Agent 负责“转账”:用神经-符号混合架构把它从 Demo 拉进生产
- 借助 Okta 和 NGINX Ingress Controller 实现 K8s OpenID Connect 身份验证
- 同样是低代码,为什么有人扩容有人烂尾?答案藏在交付体系里-拆解 Oinone 的交付底座


