来源:DeepTech深科技
在写作等开放性任务中,AI 能跳出现有信息框架,提出类似人类的、甚至人类没有想到的建议吗?
在以往的研究中,AI 聊天机器人与用户的对话一般是被动的事实性问答,即对已有信息进行相关澄清和梳理。尽管可直接通过指令让 AI 提出解决方案,但其并不承担创造性任务。
在近期的一项研究中,研究人员为 AI 输出创造性内容提供了一种可能的方案。美国南加州大学与微软公司、加州大学戴维斯分校团队合作,引入了一种主动信息收集的任务范式,通过强化学习训练大语言模型,即便面对不完整或模糊的提示,大语言模型也可以主动识别信息缺口。
并且,基于特定问题主动挖掘用户隐含的信息或知识,通过提升模型在复杂、开放性任务中的协作能力,来更好地完成任务,特别是在社会科学、商业等深层次的上下文推理任务中具有优势。
可以这样来理解:面试者需要通过面试官提出有启发性的问题以及互动,才能更好地展示自身价值, 让 AI 解读相对复杂文档的原理亦是如此 。
 图丨项目主要成员,从左至右依次是:杨珑颀、黄腾昊、周沛和陈斯昊(来源:该团队)
图丨项目主要成员,从左至右依次是:杨珑颀、黄腾昊、周沛和陈斯昊(来源:该团队)相关论文以《教会语言模型主动收集信息》(Teaching Language Models To Gather Information Proactively)为题,已经被 EMNLP-Findings 2025 接收 [1]。南加州大学博士生黄腾昊(目前在微软实习)是第一作者,微软公司资深研究科学家周沛和陈斯昊担任共同通讯作者。
 图丨相关论文(来源:EMNLP)
图丨相关论文(来源:EMNLP)为确保模拟的模糊性既真实又可学习,研究团队基于涵盖 25 个专业领域、1,000 多条数据的 DOLOMITES 数据集进行测试,并设计了掩盖关键信息并模拟真实的模糊性的机制。
据介绍,在强化学习的奖励设计中,研究人员希望奖励机制更专注于“提出创造性问题”这一行为本身,而非具体问题的内容。重点在于鼓励模型提出在已有数据中不存在的新问题,并以此作为强化奖励的依据。
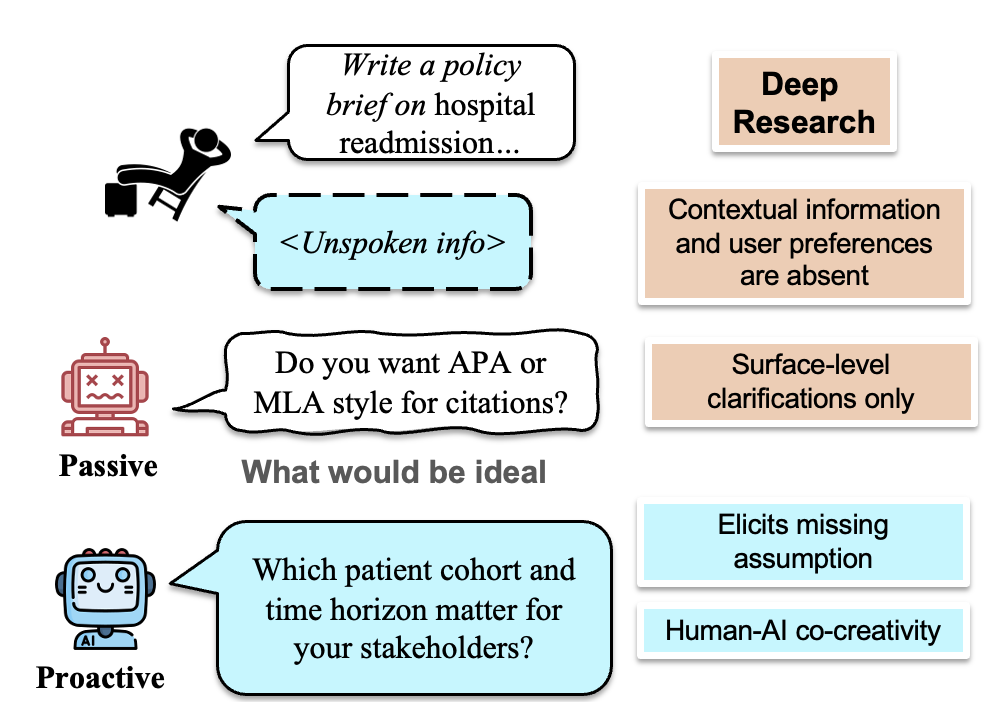 图丨主动澄清有助于实现最佳的大模型响应(来源:EMNLP)
图丨主动澄清有助于实现最佳的大模型响应(来源:EMNLP)陈斯昊指出,如果针对其中一个答案去做特定训练,并不会得到很好的泛化性。“我们的做法是将最终输出的评估作为奖励信号,相当于在机器学习时专门去学习怎样生成和人类标注出来的答案一样。最后,生成符合奖励模式的答案。”
研究人员将已有的数据转化成奖励信号,通过设计对话模拟引擎,把用来做监督学习的任务转变成对话形式。相当于两个 AI 之间通过互动的方式,一个 AI 提出澄清问题,另一个 AI 基于问题质量/回答有效性打分,进而获得奖励信号。
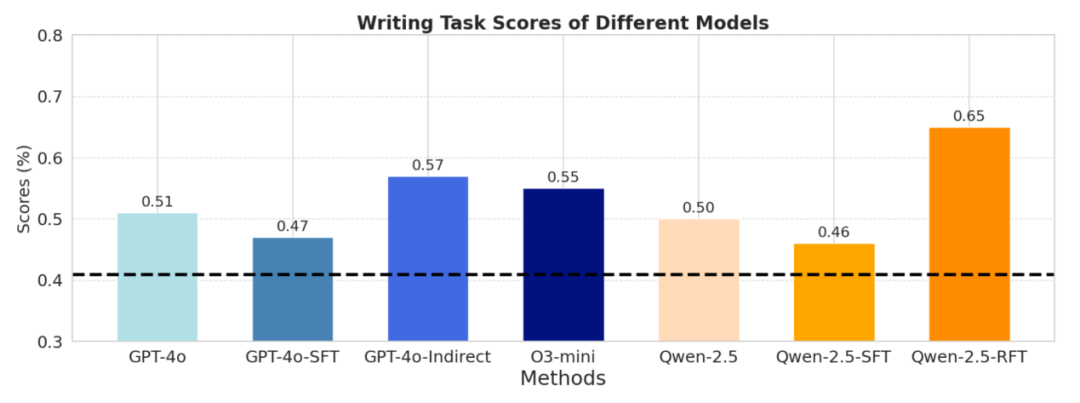 图丨评估框架下的实验结果(来源:EMNLP)
图丨评估框架下的实验结果(来源:EMNLP)研究结果显示,经过该方法微调的 Qwen-2.5-7B 模型,在自动评估指标上比基线模型 o3-mini 提高了 18%;而在人类评估中,基于该方法生成的澄清问题以及最终大纲分别获得 42% 和 28% 的偏好率。
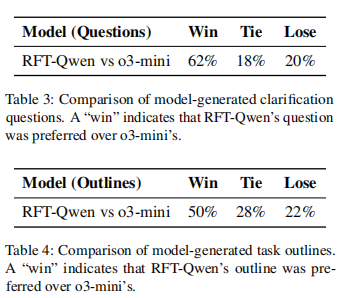 (来源:EMNLP)
(来源:EMNLP)该研究并不是简单地训练模型完成任务,而是通过奖励机制,让模型微调后提出建设性、启发性观点或前瞻性建议,进而展现出类人的系统性思考方式。
周沛对 DeepTech 解释道:“它具有很好的泛化性,相当于‘授人以鱼不如授人以渔’,即不是直接教 AI 该提什么问题、该给什么答案,而是教它主动发现信息缺口、提出创造性澄清问题的思考方式,从而靠自身的互动能力获得最优解。”
此外,基于该方法微调的模型不只是给出一个答案,它可能需要提出需要澄清问题,也有可能需要多核协作,甚至还可能需要质疑之前提出的假设是否有问题。
研究团队认为,这项研究本质上是在进行用户与 AI 之间的深度研究,通过对话同步上下文、缩小信息差。因为当 AI 和用户都更清楚最终输出的目标时,有利于后续的人机协作,从而创造性地完成更深度的任务。
这种主动信息收集的方法适用于开放性任务,例如包括文献综述和报告的写作任务,或布置画廊展览在内的场景。黄腾昊解释说道:“AI 本身可能在这些方面没有太多知识,需要和用户进行多轮对话和互动来获取新知识,再用这些新知识来解决新任务。”
此外,该方法还有可能推动人类和智能体互动的形式。例如,在 AI+教育场景应用中发挥作用,让 AI 在用户没有表达信息的情况下,主动引导学生向某个方向学习。
在人与 AI 互动中,补充信息差的方式有多种:一是让 AI 通过提出好问题来主动获取缺失信息;另一种是,在同步或非同步的场景下,模型可以通过给出提示协助获取其他信息。这也是研究团队未来将继续探索的方向之一。
参考资料:
1.https://arxiv.org/abs/2507.21389v1
运营/排版:何晨龙
]article_adlist–>
<!-- 非定向300*250按钮 17/09 wenjing begin --> <!-- 非定向300*250按钮 end -->
</div>

